[具身智能-382]:系统架构:具身智能的感知系统的主要功能与对应的关键技术
·
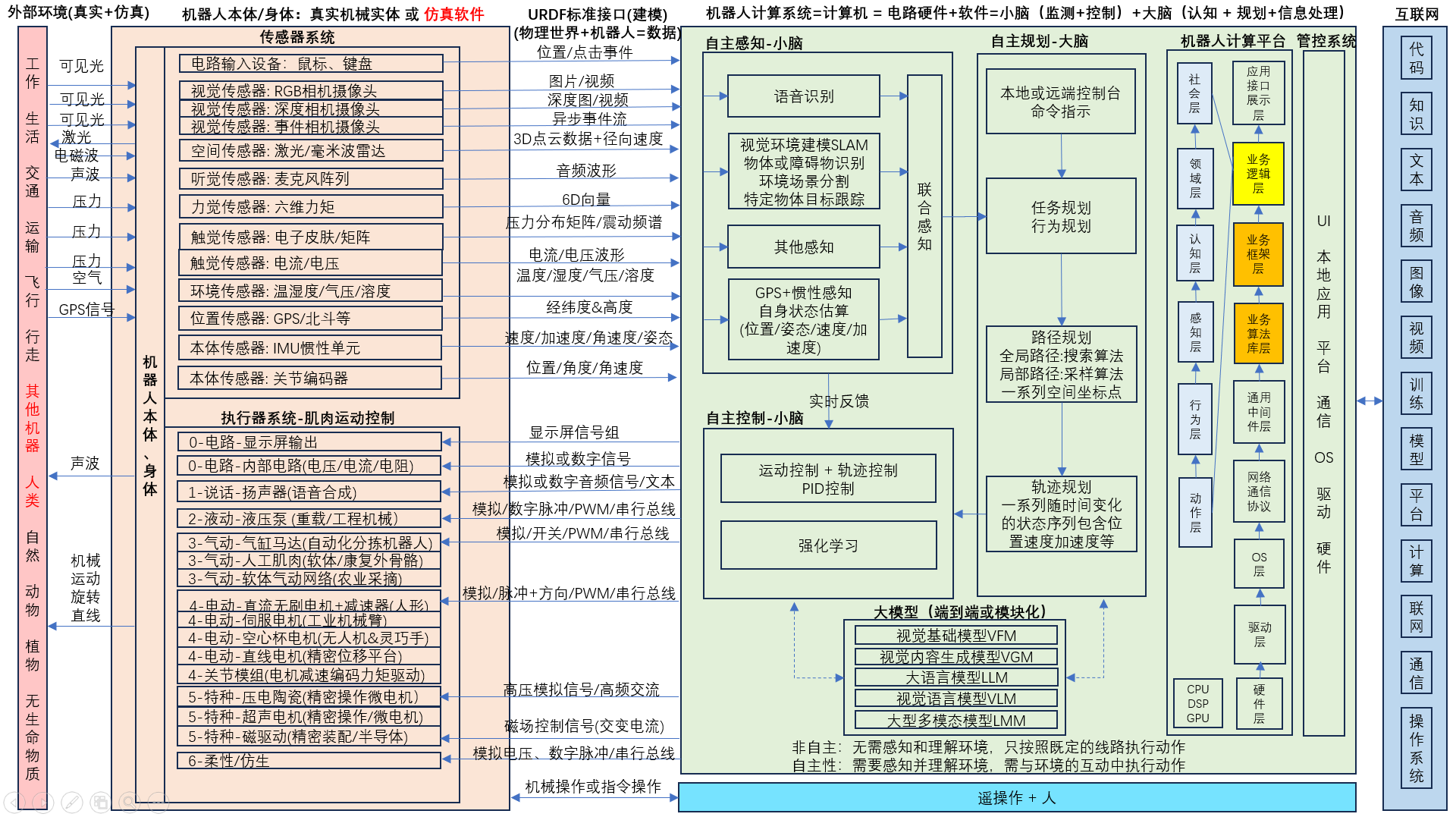
具身智能的感知系统作为连接物理世界与数字世界的“感官”与“前哨”,其核心使命是构建对环境的全面理解并实时监测自身状态,为智能体的自主决策与安全交互提供数据基础。这一系统并非简单的传感器堆叠,而是通过多模态融合技术将异构数据转化为统一、可靠的环境模型与自身状态估计。
一、环境感知与建模:构建数字孪生的基础
环境感知的目标是让智能体理解“我在哪里”以及“周围有什么”。这不仅需要几何信息,更需要语义信息。
1. 视觉感知与三维重建
- 功能:这是具身智能最主要的感知手段,用于识别物体、检测障碍物、理解场景布局。它模拟人类的视觉功能,获取环境的颜色、纹理和深度信息。
- 关键技术:
- RGB-D相机与深度估计:利用结构光、飞行时间法或双目立体视觉技术获取场景的深度信息,生成点云数据。
- 视觉SLAM:同步定位与地图构建技术,利用摄像头数据在未知环境中确定自身位置并构建环境地图(如ORB-SLAM3)。
- 三维重建:基于神经辐射场或高斯溅射技术,从二维图像中重建高保真的三维场景,为路径规划提供精细的几何模型。
2. 空间探测与避障
- 功能:弥补视觉在强光、黑暗或弱纹理环境下的不足,提供精确的距离测量,主要用于快速避障和全局定位。
- 关键技术:
- 激光雷达:通过发射激光束测量距离,生成高精度的二维或三维点云地图,是移动机器人导航的核心传感器。
- 毫米波雷达:具备穿透烟雾、灰尘的能力,且能直接测量物体速度,常用于动态环境下的障碍物检测。
3. 语义理解与场景解析
- 功能:赋予机器“常识”,使其不仅能看到障碍物,还能识别出这是“椅子”还是“人”,从而采取不同的交互策略。
- 关键技术:
- 视觉基础模型:利用在大规模数据上预训练的模型(如SAM分割一切模型),实现对开放词汇物体的零样本识别与分割。
- 视觉语言模型:将图像与文本对齐,使机器人能够理解自然语言指令中的视觉指代(如“去拿那个红色的杯子”)。
二、本体感知与状态估计:精准控制的前提
本体感知关注机器人“自己在哪里”以及“身体状态如何”,是实现高动态运动控制的基础。
1. 运动状态监测
- 功能:实时获取关节角度、角速度、加速度等信息,用于闭环控制。
- 关键技术:
- 编码器:安装在电机端,提供高分辨率的位置反馈。
- 惯性测量单元:集成加速度计和陀螺仪,用于估算机器人的躯干姿态、俯仰角和滚动角,对于双足人形机器人的平衡控制至关重要。
2. 力觉与触觉感知
- 功能:实现柔顺控制和精细操作,防止机器人损坏物体或自身。例如,在抓取鸡蛋或与人握手时,需要精确控制力度。
- 关键技术:
- 六维力/力矩传感器:通常安装在手腕或脚踝处,测量三个方向的力和力矩,用于阻抗控制。
- 电子皮肤:覆盖在机器人表面的柔性传感器阵列,提供接触位置、压力分布甚至温度的感知,赋予机器人类似人类的触觉。
三、多模态融合技术:从数据到信息
单一传感器往往存在局限性(如相机受光照影响,激光雷达缺乏纹理,IMU存在漂移)。具身智能的感知系统必须将上述所有数据融合,形成统一的世界观。
功能
- 提高感知的鲁棒性和准确性,消除单一传感器的噪声和盲区。
关键技术
- 卡尔曼滤波与扩展卡尔曼滤波:经典的数学方法,用于融合IMU、轮速计和GPS数据,进行状态估计。
- 图优化:在SLAM后端中,将不同传感器的约束构建成图结构进行全局优化,消除累积误差。
- 深度学习融合网络:端到端的神经网络,直接将相机图像、激光雷达点云和文本指令映射到动作空间或占据网格地图中。
总结
具身智能的感知系统是一个高度复杂的异构网络。它通过视觉基础模型/视觉语言模型赋予机器“智慧”,通过激光雷达/视觉SLAM赋予机器“空间感”,通过六维力传感器/电子皮肤赋予机器“触感”。这些技术的成熟度直接决定了具身智能能否从“预编程的自动化设备”进化为“具备自主行为能力的智能体”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)