双路CPU服务器训练模型数据加载导致某张GPU的 GPU-Util长时间很低的问题
服务器环境如下:
主板:华南街x10x99
CPU:E5 2696v4 22核心44线程 * 2块
GPU:NVIDIA 3080Ti 20GB * 4张
内存:SK海力士16GB DDR4 2133P ECC REG服务器内存条 2Rx4 * 8条
系统:Ubuntu 22.04
训练图像分类时遇到下面的问题: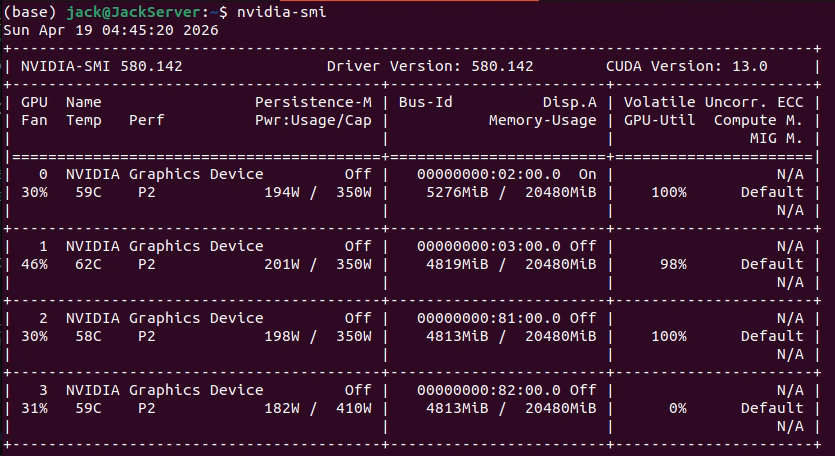
我只要运行train.py,那么某张卡就会一直占用率低长期低于10%,偶尔一瞬间就90%。当重新运行train.py时,随机某张卡低于10%,只要不结束train,就一直是那张卡长期低于10%。
1.把 NUM_WORKERS 从 4 提到 8 或 12,现象没有缓解。
2.试过: GPU_IDS 分别(0,1,2) 、(0,1,3) 、(1,2,3) 、 (0,1,2,3),GPU1经常为0%,其他GPU经常为100%; GPU_IDS 分别(0,1)、(1,2)、(1,3),GPU1经常100%,另一张GPU经常为60%。
观察到的情况就是,无论怎么组合GPU,始终会有一张卡会长时间GPU-Util比其他卡低,比如GPU_IDS=(0,2,3)时,GPU2就长时间比其他卡低,长时间只有60%。
3.将BATCH_SIZE从64调整到256,还是没用,那张卡始终低 util。
4.用 watch -n 0.5 nvidia-smi 我看了很久,一直很低util。
AI帮我分析:
补充的现象把范围缩得很小了。现在我更倾向于这不是“某张物理卡有问题”,而是“某个 `local_rank` 进程在这套框架里一直表现不同”,再叠加 GPU 拓扑/CPU 调度,把现象投射成“某张卡长期低 util”。
**现在最像的根因**
你给的多数组合里,低 util 的卡很像是 `GPU_IDS` 里的“第 2 张可见卡”,也就是 `local_rank=1` 对应的物理 GPU。
这点很关键,因为你的启动逻辑在 [distributed.py](E:/PythonProjects/ResearchFramework/utils/distributed.py) 里是:
- 先设置 `CUDA_VISIBLE_DEVICES=GPU_IDS`
- 再用 `torch.distributed.run`
- `local_rank=0/1/2/...` 映射到“可见设备列表”的第 1/2/3/... 张卡
所以如果低 util 跟“物理 GPU 编号”一起变,但经常落在“可见列表中的同一个位置”,那就说明问题更可能在某个 rank 进程,而不是硬件本身。
**我现在最怀疑的两件事**
1. 训练循环里每一步都在强制做 GPU 同步和 GPU→CPU 拷贝,放大了 rank 之间的细小抖动。
在 [classification_trainer.py](E:/PythonProjects/ResearchFramework/trainers/classification_trainer.py) 里,每个 step 都有:
- `loss.item()`
- `progress.set_postfix(...)`
- `meter.update(outputs, targets, ...)`
而 [classification_metrics.py](E:/PythonProjects/ResearchFramework/metrics/classification_metrics.py) 的 `update()` 里每步又做了:
- `targets.cpu()`
- `preds.cpu()`
- 如果启用了 `auc`,还会 `softmax(logits).cpu().numpy()`
这类操作都会把异步 CUDA 流“拉回 CPU 同步”。
DDP 下只要某个 rank 的 CPU 侧稍微更慢或更快,其他卡就会在同步点等它,于是就会出现你看到的“固定一张卡长期 util 明显偏低”。
2. rank 级别的 CPU/NUMA/PCIe 路径不一致。
你现在已经试过:
- 加 `num_workers`
- 加大 `batch_size`
- 换 GPU 组合
但现象仍然存在,这说明它不只是“喂数不够”。
更像是某个 rank 进程和它的 worker 在 CPU 核心、NUMA 节点、PCIe 路径上更特殊。这样一来,同一个 `local_rank` 会在一次运行里一直表现得不一样;重启后进程调度变了,低 util 的物理卡也就可能换。
**为什么你的现象很符合这个判断**
- 如果是某张显卡硬件问题,低 util 通常会固定在同一张物理卡。
- 你这里是“停掉重跑后,低 util 的卡可能换”,这更像 rank/process 调度问题。
- 你把 `NUM_WORKERS` 和 `BATCH_SIZE` 都加了,问题还在,说明不是单纯 DataLoader 吞吐不足。
- 你的框架里确实存在每步大量同步/CPU统计,这会非常容易把 rank 抖动放大。
**我建议先做的两个最有效验证**
1. 临时把训练阶段的 `meter.update(...)` 去掉,只保留纯训练,不做每步分类指标统计。
如果 util 立刻均衡很多,根因就基本坐实在训练期指标统计。
2. 在每个 rank 上打三类时间:
- `data_time`
- `forward_backward_time`
- `step_time`
如果总是同一个 `local_rank` 的 `step_time` 模式不同,就能进一步判断是:
- 数据侧慢
- CPU 侧同步慢
- 还是通信/拓扑慢
**我现在的判断排序**
1. 训练阶段每步 CPU 同步统计,是代码层面的第一嫌疑。
2. 某个 `local_rank` 的 CPU/NUMA/PCIe 绑定更差,是系统层面的第二嫌疑。
3. 纯显卡硬件问题,概率反而不高。
如果你愿意,我下一步直接帮你做两件事:
- 把训练阶段的指标统计改成“轻量版”,去掉每步 `cpu()/numpy()` 同步
- 给每个 rank 加 `data_time / compute_time / step_time` 诊断日志
这样基本一轮就能把原因钉死。
第2轮AI:
有用,这个硬件信息很关键。现在基本已经能下结论了:
不是 GPU3 算力有问题,也不是 DDP 把 GPU3 分到了更少/更轻的计算。
根因已经被日志定位出来了:`Rank 3` 的 **取数阶段长期变慢**,导致它对应的 GPU3 长时间空等,所以 `GPU-Util` 经常是 0%。
**直接证据**
你这几轮日志非常一致:
- `Rank 3`
- `data_time_avg ≈ 0.31 ~ 0.33s`
- `compute_time_avg ≈ 0.10 ~ 0.12s`
- `Rank 1/2`
- `data_time_avg ≈ 0.007 ~ 0.009s`
- `compute_time_avg ≈ 0.41 ~ 0.42s`
- `Rank 0`
- `data_time_avg ≈ 0.02s`
- `compute_time_avg ≈ 0.39 ~ 0.43s`
更关键的是:
- 所有 rank 的 `step_time_avg` 几乎一样,都是 `≈ 0.42s`
这说明:
1. `Rank 3` 每一步都在 **等数据**
2. 其他 rank 很快拿到数据,先开始算
3. 但 DDP 反向同步时又要等 `Rank 3`
4. 所以其他 rank 的“compute_time”被拉长了
5. `Rank 3` 自己反而“compute_time”更短,因为它晚到,不怎么等别人
这基本是铁证。
甚至可以看到一个很漂亮的对应关系:
- `Rank 3` 比 `Rank 1/2` 多出来的 `data_time` 大约 `0.31s`
- `Rank 1/2` 比 `Rank 3` 多出来的 `compute_time` 也大约 `0.31s`
这说明那 `0.31s` 就是大家在 DDP 同步里为 `Rank 3` 的慢取数买单。
**为什么双路 E5 + X99 很相关**
你的机器是双路 `E5-2696 v4`,典型 NUMA 结构。
而你的 GPU Bus-ID 也很像两组根复合体:
- `GPU0/1`: `02:00.0 / 03:00.0`
- `GPU2/3`: `81:00.0 / 82:00.0`
这通常意味着不同 GPU 挂在不同 CPU socket 下面。
你的问题现在不是 GPU 算力,而是 **某个 rank 进程及其 DataLoader workers 的 CPU/NUMA 调度不对称**。
在这种双路平台上,这很常见,尤其你现在还是:
- `ImageFolder`
- CIFAR100 拆成很多小图片
- PIL 解码
- 再从 `32x32` 放大到 `224x224`
这种数据流很吃 CPU 调度和小文件访问,一旦某个 rank 的 workers 被调度到“不理想的 socket / 核心组合”,就会长期慢。
**为什么这次是 GPU3**
因为这次慢的是 `Rank 3`。
而你这次 `GPU_IDS=[0,1,2,3]`,所以:
- `local_rank 0 -> GPU0`
- `local_rank 1 -> GPU1`
- `local_rank 2 -> GPU2`
- `local_rank 3 -> GPU3`
所以低 util 落在 GPU3,和日志完全对上。
**现在可以明确排除的方向**
基本可以先排除:
- 某张显卡坏了
- 某张显卡算力低
- 模型在某张卡上 batch 更小
- 梯度同步实现有 bug
- 训练阶段指标统计是主因
我前面帮你去掉每 step 的重同步是对的,但这次日志已经证明:
**主因还在 DataLoader / CPU / NUMA 侧**。
**我建议的下一步,优先级从高到低**
1. 查拓扑
- `nvidia-smi topo -m`
- `numactl --hardware`
- `lscpu | grep -i numa`
2. 查 4 个 rank 进程的 CPU 亲和性和 NUMA
- `taskset -cp 12397`
- `taskset -cp 12398`
- `taskset -cp 12399`
- `taskset -cp 12400`
- `numastat -p 12397`
- `numastat -p 12398`
- `numastat -p 12399`
- `numastat -p 12400`
3. 最有效的软件修复
- 按 `local_rank` 给每个 rank 绑定 CPU 核心/NUMA 节点
- 并让 DataLoader workers 继承这个绑定
4. 结构性修复
- CIFAR100 不要再走 `ImageFolder + 小 PNG`
- 直接用 `torchvision.datasets.CIFAR100`,或者做成 LMDB / 内存数据集
**最值得做的代码改动**
下一步我最建议直接帮你做这个:
- 在 `main.py` 里,在 `setup_distributed(cfg)` 之后、`build_dataloaders(cfg)` 之前,
按 `local_rank` 做 `os.sched_setaffinity(...)`
- 让每个 rank 固定在对应 socket 的 CPU 核心上
- DataLoader workers 会继承这个亲和性
这一步对你这种双路平台最有针对性。
如果你同意,我下一步就直接给你的框架加一版:
- `rank -> CPU cores` 绑定
- 可配置的 NUMA/亲和性日志
- 可选 `prefetch_factor` 配置项
第三轮AI:
这版已经加好了,改动在这四处:
- [config.py](E:/PythonProjects/ResearchFramework/config.py:36)
新增了 `PREFETCH_FACTOR`、`ENABLE_CPU_AFFINITY`、`ENABLE_NUMA_BINDING`、`LOG_AFFINITY`,并把它们挂到 `RuntimeConfig`。同时加了 `prefetch_factor >= 1` 的校验。
- [utils/distributed.py](E:/PythonProjects/ResearchFramework/utils/distributed.py:451)
新增了运行时亲和性逻辑:按 `local_rank -> 物理 GPU -> NUMA/CPU Affinity` 解析拓扑,把同一 NUMA 节点上的 CPU 核按 GPU 数量切开,再给当前 rank 绑定对应 CPU 集合;如果系统有 `libnuma`,也会顺带做 NUMA 绑定。这里还加了 `[Affinity][Rank ...]` 日志。
- [datasets/builder.py](E:/PythonProjects/ResearchFramework/datasets/builder.py:34)
给 `DataLoader` 加了 `worker_init_fn`,worker 会继承并重设同一套 CPU/NUMA 亲和性;同时支持可选 `prefetch_factor`。
- [main.py](E:/PythonProjects/ResearchFramework/main.py:87)
在构建 `DataLoader` 之前调用了 `configure_runtime_affinity()`,保证 rank 进程先绑核,后面 worker 才能继承。
这版的实际行为是:
- `GPU0/1` 会共享 NUMA0,但各自分到不同的 CPU 子集。
- `GPU2/3` 会共享 NUMA1,但各自分到不同的 CPU 子集。
- 日志里会出现类似:
- `[Affinity][Rank 3] local_rank=3 | gpu=3 | ... | numa_node=1 | cpu_cores=... | cpu_binding=applied | numa_binding=applied`
我这边做了 `py_compile`,语法通过了,但没有在你的 Linux 双路机器上实际跑 DDP。你下一步直接在服务器上重跑一次,把新的 `[Affinity][Rank ...]` 和后面的 `[Diag][Rank ...]` 一起贴给我,我就能判断这次绑核后 `Rank 3` 的 `data_time` 有没有被拉下来。
Codex已帮我解决,现在强得不行,训练速度提升明显:
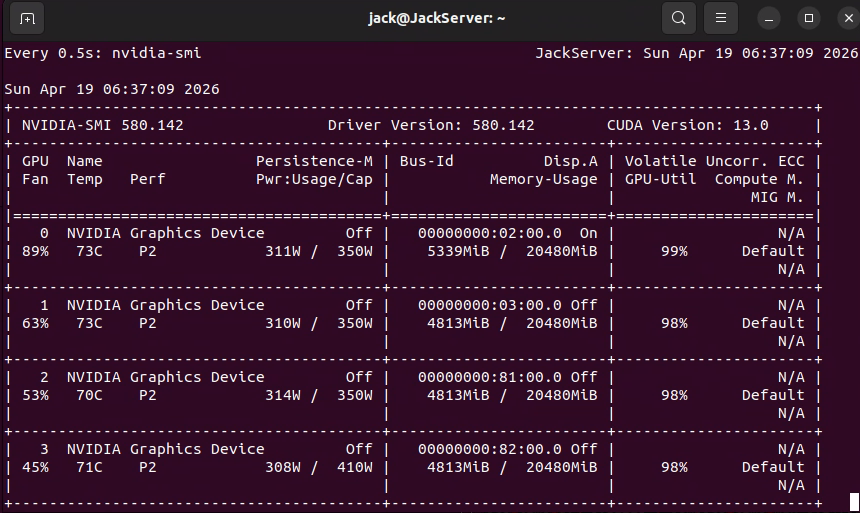
总结:原因是双路CPU导致数据加载混乱导致的
解决办法:
按 local_rank 给每个 rank 绑定 CPU 核心/NUMA 节点,并让 DataLoader workers 继承这个绑定
解决前:Train Epoch 11: 66%|██████▋ | 117/176 [00:50<00:18, 3.25it/s, loss=2.5449]
解决后:Train Epoch 11: 66%|██████▋ | 117/176 [00:16<00:04, 9.02it/s, loss=2.2641]
效果明显:1 Epoch(70s->20s, 3.25it/s->9.02it/s)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)