Grafana Tempo介绍(分布式追踪后端系统,用于存储和查询追踪数据)OpenTelemetry、OTLP、无索引、TraceID查询、低成本、依赖对象存储、Exemplars
文章目录
一文读懂 Tempo:云原生时代的分布式追踪后端
在微服务架构中,请求往往会跨越多个服务节点执行,一次简单的用户操作可能涉及几十甚至上百次服务调用。如何理解一次请求的完整路径、定位性能瓶颈、排查故障,成为系统可观测性的核心问题。
这正是分布式追踪(Distributed Tracing) 的价值所在。
在众多追踪后端中,Grafana Tempo 以其极简架构、低成本存储和与 Grafana 深度集成而受到越来越多团队的青睐。
本文将带你全面了解 Tempo 的设计理念、核心特性以及实际应用方式。
一、什么是 Tempo?
Tempo 是由 Grafana Labs 开源的分布式追踪后端系统,用于存储和查询 trace 数据。
它的核心定位可以总结为一句话:
“一个专注于低成本、高可扩展的 trace 存储系统”
与传统追踪系统不同,Tempo 的设计目标非常明确:
- 不做复杂索引
- 不承担数据采集
- 专注存储 + 查询
二、Tempo 在可观测性体系中的位置
典型的可观测性三大支柱:
- Metrics(指标)
- Logs(日志)
- Traces(追踪)
Tempo 负责的是 Traces。
一个典型链路如下:
应用 → OpenTelemetry SDK → Collector → Tempo → Grafana
相关组件包括:
- OpenTelemetry:采集 trace 数据
- Tempo:存储 trace
- Grafana:可视化分析
三、Tempo 的核心设计理念
1. 无索引(Index-free)
Tempo 最大的特点就是:
❌ 不建立传统的 trace 索引
✅ 仅通过 TraceID 查询
为什么这么设计?
传统系统(如 Jaeger)依赖索引:
- 需要额外存储(如 Elasticsearch)
- 成本高
- 运维复杂
Tempo 选择另一条路:
- 不支持复杂查询(如按 tag 搜索)
- 只支持 TraceID 查询
- 极大降低成本
👉 代价换成本,是 Tempo 的核心哲学。
2. 对象存储优先
Tempo 将 trace 数据存储在对象存储中,例如:
- S3
- GCS
- MinIO
优点:
- 成本极低
- 无限扩展
- 无需维护数据库集群
3. 与 Metrics 强关联(Trace ↔ Metrics)
Tempo 并不支持复杂查询,那如何定位问题?
答案是:通过 Metrics 反查 Trace
典型流程:
- 在 Grafana 中发现某接口 latency 升高
- 点击指标中的 exemplar(示例)
- 跳转到对应 trace
👉 这依赖:
- Prometheus + exemplars
- TraceID 关联
4. 高压缩比
Tempo 使用高效压缩算法:
- 存储成本远低于 Jaeger / Zipkin
- 官方常见数据:成本降低 10 倍以上
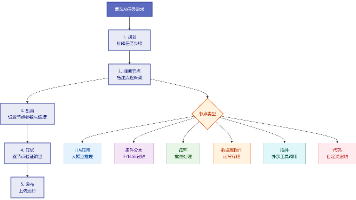
四、Tempo 架构解析
Tempo 架构遵循云原生设计,核心组件包括:
1. Distributor(分发器)
- 接收 trace 数据(OTLP / Jaeger / Zipkin)
- 做基础校验
- 转发给 ingester
2. Ingester(写入节点)
- 将 trace 写入内存
- 批量刷入对象存储
3. Compactor(压缩器)
- 合并小文件
- 优化存储结构
4. Querier(查询节点)
- 根据 TraceID 查询数据
5. Query Frontend(查询入口)
- 统一查询入口
- 做缓存和优化
五、Tempo 支持的协议
Tempo 支持多种 trace 数据接入方式:
- OTLP(推荐)
- Jaeger
- Zipkin
其中最推荐的是:
👉 基于 OpenTelemetry 的 OTLP
因为它是当前云原生标准。
六、Tempo 的优势
1. 极低成本
- 无索引
- 对象存储
- 高压缩
👉 特别适合:
- 大规模微服务
- 高 QPS 系统
2. 运维简单
相比 Jaeger:
| 方案 | 依赖 |
|---|---|
| Jaeger | Cassandra / Elasticsearch |
| Tempo | 对象存储 |
👉 几乎“无状态”
3. 与 Grafana 深度集成
在 Grafana 中:
- 原生支持 Tempo
- 一键查看 trace
- 与 metrics、logs 联动
4. 高扩展性
- 水平扩展
- 云原生部署(Kubernetes)
- 支持多租户
七、Tempo 的局限性
任何设计都有 trade-off,Tempo 也不例外:
1. 查询能力弱
不支持:
- 按标签查询
- 按服务过滤
- 复杂分析
👉 只能通过 TraceID 查询
2. 依赖指标系统
如果没有:
- Prometheus
- Exemplars
👉 很难定位 trace
3. 调试体验较弱(对新手)
相比 Jaeger UI:
- Tempo 更“极简”
- 需要理解可观测性体系
八、Tempo vs Jaeger
| 对比项 | Tempo | Jaeger |
|---|---|---|
| 存储 | 对象存储 | ES / Cassandra |
| 索引 | 无 | 有 |
| 查询能力 | 弱 | 强 |
| 成本 | 低 | 高 |
| 运维复杂度 | 低 | 高 |
| 推荐场景 | 大规模生产 | 调试 / 小规模 |
九、适用场景
Tempo 特别适合:
✅ 大规模微服务架构
✅ 对成本敏感的系统
✅ 已使用 Grafana + Prometheus
✅ 云原生(K8s)环境
不太适合:
❌ 需要复杂 trace 查询
❌ 没有 metrics 体系
❌ 初期调试阶段
十、最佳实践
1. 与 OpenTelemetry 搭配
推荐架构:
App → OpenTelemetry SDK → Collector → Tempo
2. 使用 Exemplars
实现:
- Metrics → Trace 跳转
- 快速定位问题
3. 合理设置采样率
- 生产:降低采样率(如 1%)
- 故障时:临时提高
4. 与日志系统联动
结合:
- Loki(日志)
- Tempo(追踪)
实现完整链路分析。
十一、总结
Tempo 的核心思想可以用一句话概括:
用“查询能力”换“极致成本与扩展性”
它并不是 Jaeger 的替代品,而是不同场景下的最优解:
- 想要强查询能力 → 选 Jaeger
- 想要低成本 + 高规模 → 选 Tempo

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)