Veo-Act:前沿视频模型能将通用机器人操作推进到什么程度?
26年4月来自清华大学的论文“Veo-Act: How Far Can Frontier Video Models Advance Generalizable Robot Manipulation?”。
视频生成模型发展迅速,并开始展现出对物理动力学的深刻理解。本文研究诸如 Veo-3 (来自谷歌Deep mind)之类的视频生成模型在多大程度上能够支持可泛化的机器人操作。首先研究一种零样本方法,其中 Veo-3 根据当前机器人观测数据预测未来的图像序列,而逆动力学模型 (IDM) 则恢复相应的机器人动作。IDM 仅使用随机播放数据进行训练,无需人工监督或专家演示。其核心思路是,如果视频模型能够在图像空间中生成物理上合理的未来运动,那么 IDM 可以将这些视觉轨迹转换为可执行的机器人动作。用高维灵巧机械手在仿真和现实世界中评估这种“Veo-3+IDM”方法。
由于前沿视频模型具有强大的泛化能力,Veo-3+IDM 能够持续生成近似正确的任务级轨迹。然而,其底层控制精度仍然不足以可靠地完成大多数任务。基于此观察,开发一个分层框架 Veo-Act,它使用 Veo-3 作为高层运动规划器,并使用 VLA 策略作为底层执行器,显著提现有最先进的视觉-语言-动作策略的指令跟踪性能。总体而言,结果表明,随着视频生成模型的不断改进,视频模型可以成为实现机器人泛化学习的重要组成部分。
如图1所示三种控制流程的比较。(a) VLA 是在 VLM 的基础上引入新的动作模式而改进的,但这种改进牺牲了一定的泛化能力。(b) “视频模型 + IDM” 泛化能力良好,但在底层控制方面精度不足。© Veo-Act 是一个分层流程,它能够自动在视频规划器和 VLA 之间切换,从而结合了两种方法的优势。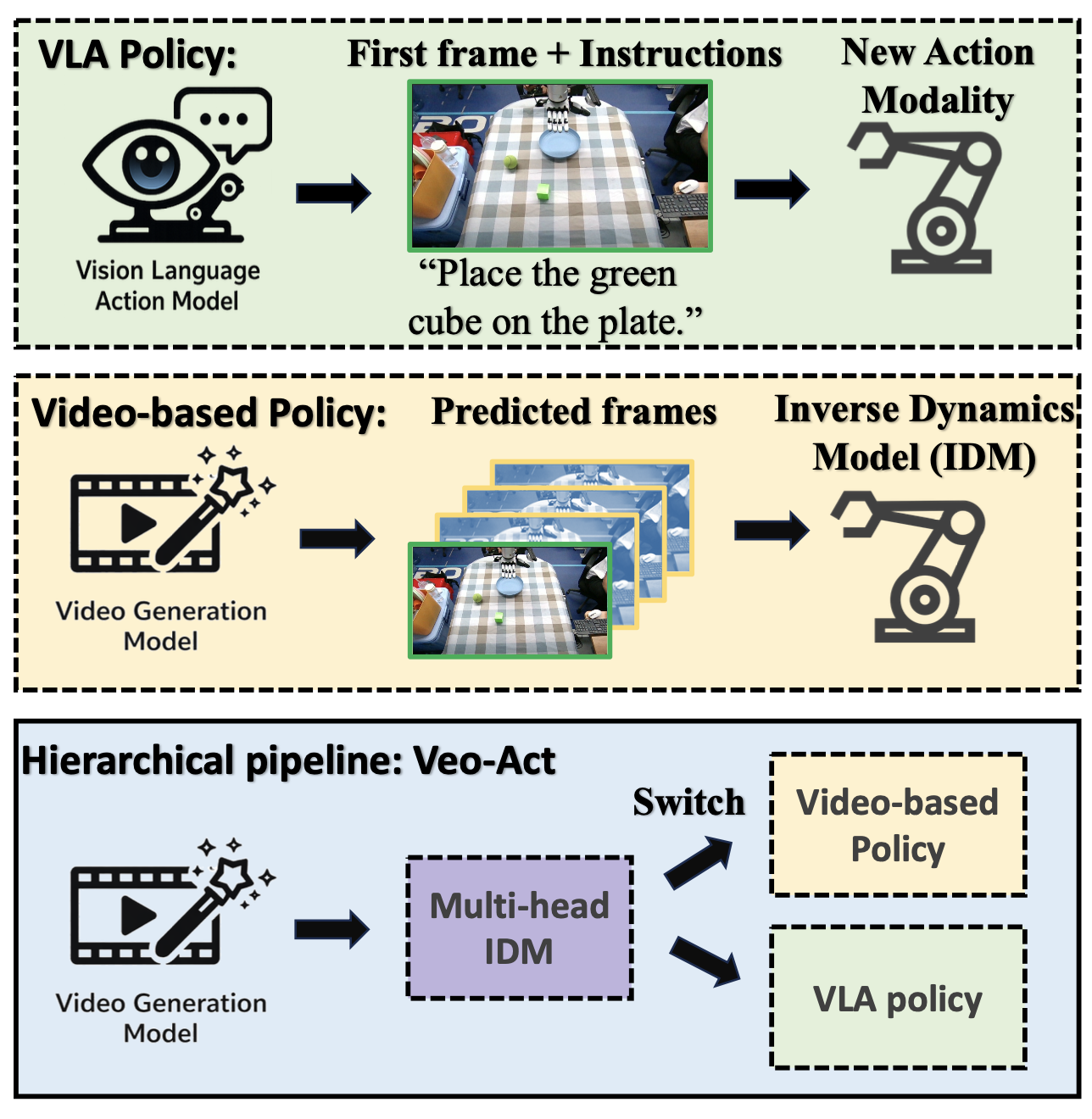
本文提出一种分层规划与控制框架,该框架结合谷歌DeepMind Veo3视频生成模型、多头逆动力学(IDM)模型和底层策略。其核心思想是:首先在图像空间中合成一条视觉上合理的未来轨迹,然后通过逆动力学将其转换为可执行的动作块,用于指令跟踪;最后,在监测学习的门控信号同时,逐步执行该动作块,以决定何时将控制权交给反应式底层策略,从而实现灵巧交互。与直接使用逆动力学模型相比,该分层规划框架能够在交互和指令跟踪之间更灵活地切换,使其更适合涉及复杂提示语义和灵巧操作的任务,如图2所示。

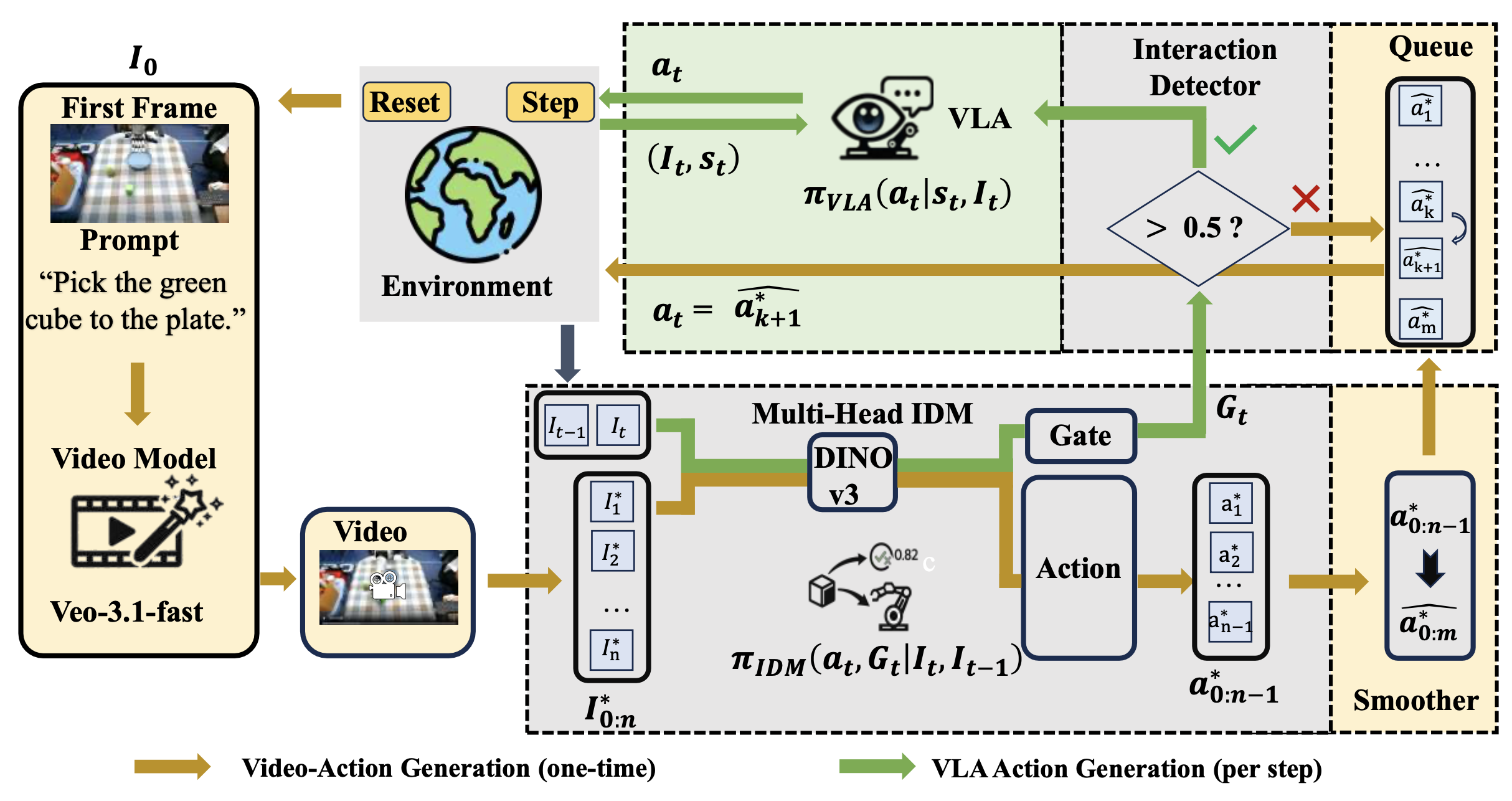
图3展示了整体流程和符号说明:
视频生成
给定初始观测图像 I_0 和任务指令或提示,调用视频生成模型生成任务完成视频,该视频描绘场景预期的未来演化过程。其将生成的视频表示为帧序列 I∗_0:n 。该视频提供图像空间中的高级运动先验信息。在实际应用中,通过以固定速率均匀采样或解码帧,将生成的视频转换为帧轨迹,并将得到的帧序列用作逆动力学的条件信号。
多头逆动力学模型 (IDM)
采用多头逆动力学模型,将图像转换映射到机器人动作,同时预测一个门值作为闭环交互检测器,以确定系统是否应从指令执行阶段切换到低级灵巧操作阶段。下图 4 展示多头 IDM 的完整架构。这里使用 DINOv3[38] 作为视觉编码器,因为它具有空间理解能力,适用于精确定位。在每个时间步 t,根据最近的视觉上下文和机器人状态构建 IDM 输入。最简单的形式是使用前一帧和当前帧 (I_t−1, I_t),并可选择性地将状态特征连接成 s_t。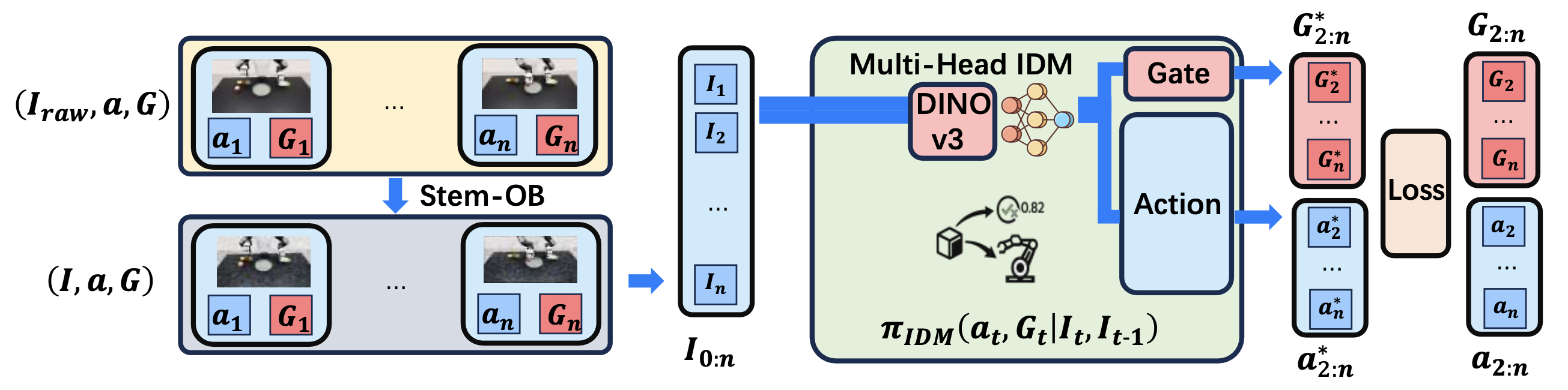
由于预测动作的幅度和分布与交互检测器的输出差异很大,IDM 具有两个 MLP 头,分别进行损失计算。动作头预测一个可执行的动作,该动作实现观测空间中的转换。交互检测器预测一个标量 G_t ∈ [0, 1],该标量指示当前情况是否应该由反应式底层策略处理。将IDM的输出总结为:
(a_t, G_t) = π_IDM(I_t−1, I_t, s_t),
其中π_IDM表示多头IDM。动作头通过对整个生成的帧轨迹I∗_0:n运行逆动力学来生成动作块a∗_0:n−1。另一方面,交互检测器在执行过程中使用真实观测数据进行在线评估。
该模型采用端到端训练。用 Huber 损失监督动作头,以确保机器人姿态的鲁棒回归;同时使用二元交叉熵损失监督交互检测器,以有效地对切换触发器进行分类。总损失 L 的公式为:
L = λ_actL_act(a_t, aˆ_t) + λ_gateL_gate(G_t, gˆ_t),
其中 λ_act 和 λ_gate 为平衡系数,a_t 为真实动作,G_t ∈ {0, 1} 为真实阶段标签。
动作平滑
直接预测的动作序列可能存在噪声或包含不合理的高频成分。因此,在执行前对预测的动作片段应用时间平滑器。
以滚动时域的方式执行平滑后的视频块。平滑模块可以通过移动平均滤波、基于样条插值或任何特定任务的约束感知滤波器来实现,同时保持接口不变。
分层规划与执行
生成视频并将其转换为动作块后,机器人进入逐步执行阶段。在每个环境步骤 t,控制器维护一个剩余规划划动作的队列 Q。
默认情况下,系统从指令执行阶段开始,弹出下一个规划动作并执行它
a_t = a ̄∗_k+1,
然后 k 递增。
并行地,在每个时间步,用实时观测数据,从 IDM 交互检测头计算一个门值 G_t。将其与阈值 τ(例如 τ = 0.5)进行比较,以确定是否启用底层策略与目标对象交互。如果 t 在短时间内保持在 τ 以上,则切换到底层策略;否则,继续消耗规划动作队列 Q。
启用底层策略后,它以当前图像和机器人状态作为输入,并输出反应动作
a_t = π_VLA(a_t | I_t, s_t),
并直接逐步控制灵巧操作。在此期间,仍然持续在线评估 G_t。一旦 G_t 持续低于 τ,就切换回规划动作队列 Q。
一个关键细节在于如何从底层控制返回后恢复规划片段。切换回来时,会剪掉交互检测门控值持续高于阈值区间内剩余的规划动作,并从预测门控值低于阈值的第一个片段恢复执行。这可以防止重复进入同一交互区域,并在生成的视频存在缺陷时提高稳定性。执行过程会在规划片段和响应式控制之间交替进行,直至终止。
变型
考虑上述分层执行的两种简化变型。
- 纯 IDM 执行:在纯 IDM 设置中,移除底层策略,并在整个回合中执行平滑后的动作块。具体来说,控制动作始终通过从规划队列中弹出来获得,
a_t = a ̄∗_k+1,
并且不执行基于门控的切换。此变型隔离视频先验和逆动力学映射的影响。
- 同步控制:在同步设置中,规划块和底层策略在执行期间都处于激活状态,但它们控制不同的动作子空间。具体来说,规划块始终控制手臂姿态分量(例如位置和旋转),而底层策略始终控制手或夹爪相关分量。这消除了离散切换,而是在每个时间步执行连续的分解控制。
实验装置
-
真实机器人和仿真环境:用一个配备12自由度灵巧手的7自由度机械臂和两个RGB摄像头:一个全局摄像头用于观察整个工作空间,一个腕部摄像头用于提供近距离操作视角。对于视频生成和IDM预测,仅使用全局摄像头作为输入,并将腕部摄像头用于切换后执行底层策略。为了实现大规模数据采集和真实评估,构建一个高保真度的IsaacLab仿真环境[31, 33, 34],该环境模拟了物理装置。
-
数据集:为了训练多头IDM,在仿真环境中采集了30万帧对样本。每个数据集包含100到200步的轨迹,其中机器人执行随机运动,并穿插抓取和释放动作。在每个步骤中,除了记录全局视角的相机图像外,还记录相应的 21 维单臂状态,该状态用于监督动作检测头。此外,还为每个步骤做标记(label)交互指示符(indicator):抓取步骤则标记为与目标 1 交互,非抓取步骤就标记为与目标 0 无交互。这些标签用于监督交互检测头。
为了提高鲁棒性,进一步使用 10 万个纯随机运动的仿真样本和 15 万个在物理平台上采集的真实世界样本来增强训练。虽然这些额外的样本仅用于动作预测,但它们增强了视觉表征并缩小了仿真与真实世界之间的差距。还通过对所有采集的轨迹应用 STEM-OB [23] 进行观测级噪声增强,进一步提高了跨域泛化能力。
- 评估设置:在灵巧操作任务中,视觉-语言-动作策略经常混淆语义相似的物体,过度依赖腕部摄像头的可见性,并且对物体位置的敏感性会降低其在分布偏移下的鲁棒性。为了揭示泛化差异,在仿真和真实机器人上设计了评估设置,以诱发 VLA 基线系统的语义或感知错误。
在所有设置中,都考虑一个物体放置任务,其中机器人被指示抓取指定的目标物体并将其放入指定的容器中。对于每种设置,在两种变型下将这些基线系统与 Veo-Act 进行比较:一种是消除混淆因素的控制条件,另一种是包含混淆因素的实验条件,以测试泛化能力。
a) 仿真设置:构建三种 VLA 基线系统容易出错的仿真设置:
- 腕部摄像头不可见。目标物体位于腕部摄像头视野之外,而另一个非目标物体则保持可见。对照组仅包含目标物体。
- 相似物体干扰项。两个颜色和形状相似的物体放置在相邻位置,且均在腕部摄像头的视野范围内,从而增加模糊性。对照组仅包含目标物体。
- 擦肩交互。在朝向目标的抓取轨迹上放置一个不同的干扰物体,这可能会导致意外接触或注意力转移。对照组移除擦肩干扰项。
b) 真实机器人设置:评估三种相应的真实机器人设置:
- 相似物体干扰项。与模拟设置相同,但物体在视觉上相似。
- 擦肩交互。与模拟设置相同,但在抓取路径上放置一个擦肩干扰项。
- 更丰富的语义。创建一个更复杂的场景,并发出需要更高层次语义基础的组合语言指令,例如从多个对象中选择唯一的水果,或者选择满足关系约束的实例。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)