2026山东大学软件学院创新实训——IntelliHealth(二):后端架构重构与登录功能实现
本周我们团队在原有架构基础上进行了一次关键性的技术调整,重点解决药品数据复杂性带来的存储与扩展问题。同时,前端完成了基础登录功能的实现,项目开始逐步进入可运行状态。
一、核心决策:后端数据库由 MySQL → MongoDB
在前期设计中,我们采用的是 MySQL 作为数据存储方案。但在进一步细化“药物管理模块”和“禁忌分析模块”时,我们发现原方案存在明显限制:
问题分析:
1、药品信息结构不稳定
- 不同药品说明书字段差异较大
- OCR解析结果存在不确定性(字段缺失/格式不统一)
- 药物成分、用途描述具有非结构化特征
使用关系型数据库需要频繁改表结构,扩展性较差
2、禁忌分析数据复杂
- 药物之间是多对多关系
- 需要支持动态扩展(新增禁忌规则、来源数据)
表结构设计复杂,查询成本较高
3、用户药品存储具有“弱结构化”特点
- 同一用户可能存储多批次同一种药
- 不同药品字段可能不完全一致
解决方案:引入 MongoDB
经过讨论,我们将数据库整体调整为 MongoDB(文档型数据库),核心优势:
- 支持灵活JSON结构(适配OCR与多源数据)
- 更适合嵌套数据与复杂对象
- 方便后续接入AI生成数据(非固定结构)
二、当前数据结构设计
本周我们完成了核心数据模型的初步设计:
1. 药品库(drug_info)
{
"_id": "...",
"name": "布洛芬",
"barcode": "690xxx",
"ingredient": "...",
"usage": "...",
"source": "ocr"
}当本身数据库没有某药品,但用户药箱录入该药品时,会向用户请求扫描说明书,将该药品存入数据库,以保证数据库数据的完善性。source字段用于标记数据来源(OCR / 数据库 / 用户录入)
字段允许不完整,便于兼容真实场景
药物禁忌分析功能的数据来源于此
后续可扩展:剂型、分类标签等
2. 用户药箱(user_drug)
{
"userId": "...",
"drugId": "...",
"productionDate": "...",
"expireDate": "...",
"quantity": 10
}将“药品信息”与“用户库存”分离(解耦)
支持同一药品多批次管理
为后续“过期提醒”“库存管理”提供基础,请求用户输入生产日期,自动计算过期时间并储存
三、系统架构同步调整
数据库变更后,我们对整体架构进行了同步优化:
Android客户端
↓
Spring Boot后端
↓
MongoDB(文档数据库)
↓
AI服务(OCR / LLM / 图像识别)
更适合AI驱动系统
AI返回的数据通常是非结构化或半结构化,MongoDB可以直接存储,无需强制格式转换。
降低数据建模成本
避免频繁修改表结构,提高开发效率。
提高扩展性
为后续“药物禁忌知识库”“用户画像扩展字段”预留空间。
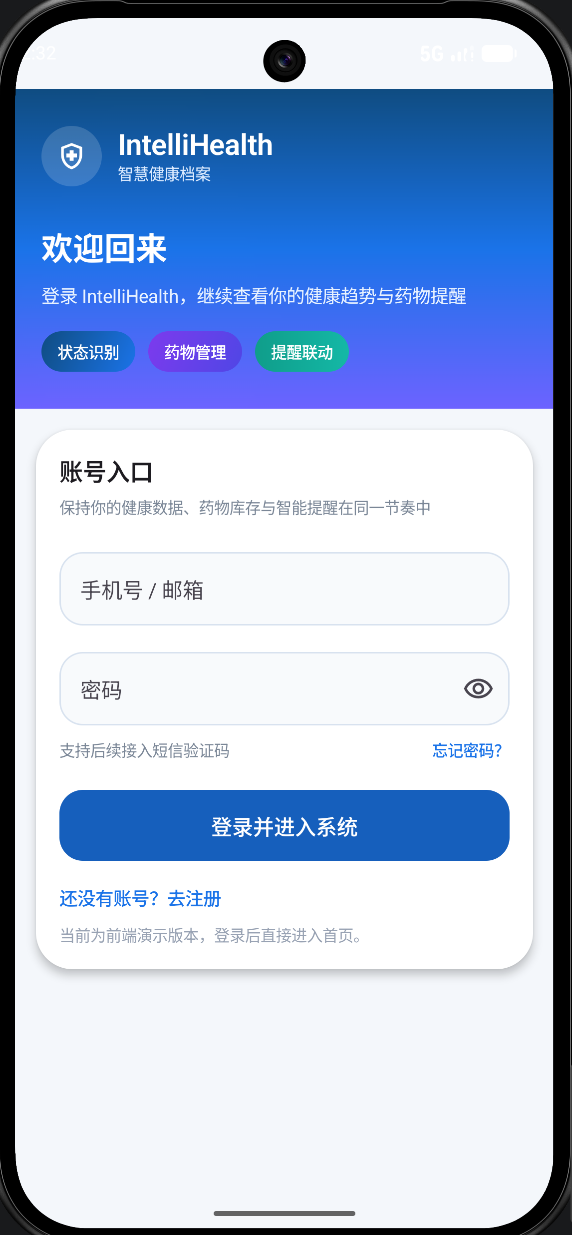
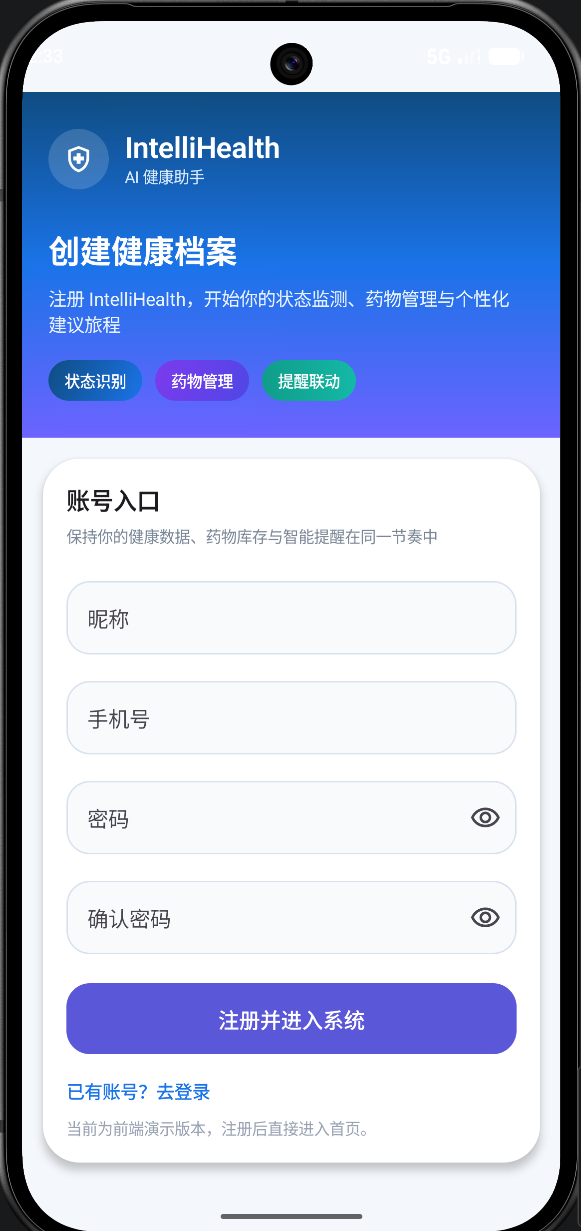
四、前端进展:登录功能完成
在功能开发方面,本周我们完成了:用户登录界面实现
包括:
- 登录页面UI搭建(Jetpack Compose)
- 用户输入(账号/密码)
- 基础交互逻辑(按钮点击、输入校验)
- 用户登录、注册
五、本周总结与思考
本周最大的进展并不是功能数量的增加,而是一次重要的架构方向修正:
从“传统结构化系统” → “面向AI与复杂数据的系统设计”
我们开始逐步意识到:
- 数据结构设计必须服务于业务复杂度
- AI系统不适合被强行约束在关系型结构中
- 架构调整越早,后期成本越低!!!
六、下周计划与总结
- MongoDB 接入与后端数据接口重构
- 药品OCR识别流程打通
- 用户药箱增删改查功能实现
- 初步搭建药物禁忌分析流程
本周我们完成了从“初步架构”到“面向实际问题优化架构”的关键转变,同时推进了前端基础功能开发。整体项目开始从设计阶段逐步迈向可运行与可扩展的工程阶段。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)