即插即用系列 | CVPR InceptionNeXt:当 Inception 遇上 ConvNeXt,大核卷积的速度瓶颈被打破了吗?
论文名称:InceptionNeXt: When Inception Meets ConvNeXt
论文原文 (Paper):https://arxiv.org/abs/2303.16900
代码 (code):https://github.com/sail-sg/inceptionnext
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
本论文的完整复现代码(即插即用版)已更新至专栏
即插即用系列(代码实践) | CVPR InceptionNeXt:当 Inception 遇上 ConvNeXt,大核卷积的速度瓶颈被打破了吗?
目录
1. 核心思想
本文的核心论点是:现有的现代化 CNN(如 ConvNeXt)虽然通过大核深度卷积(Large-kernel Depthwise Conv)提升了感受野和性能,但由于高昂的内存访问成本(Memory Access Cost),其实际运行速度在高性能 GPU 上受到严重限制。为了解决这一“高 FLOPs 效率低吞吐量”的矛盾,作者借鉴经典的 Inception 思想,提出了 Inception Depthwise Convolution。该算子将大核卷积分解为四个并行的通道分支(小方核、水平带状核、垂直带状核、恒等映射),在保持大感受野的同时,极大地降低了计算复杂度和内存开销,从而构建了 InceptionNeXt,在 ImageNet-1K 上实现了比 ConvNeXt-T 快 1.6 倍的训练吞吐量,且精度更高。
2. 背景与动机
背景:大核卷积的“虚假”高效
在 Vision Transformer (ViT) 兴起后,ConvNeXt 等工作通过引入大卷积核(如 7 × 7 7\times7 7×7)成功让 CNN 重新获得了与 ViT 抗衡的性能。理论上,深度卷积(DWConv)的 FLOPs 很低,应当非常高效。然而,在 A100 等强大的计算设备上,ConvNeXt 的实际吞吐量远低于 ResNet-50。
关键问题:单纯增加卷积核尺寸(Kernel Size)虽然参数量增加不多,但会显著增加内存访问操作,导致计算受限于内存带宽(Memory-bound),而非计算能力。如何在保留大感受野(高性能)的同时,恢复 CNN 传统的推理速度优势?
动机图解分析
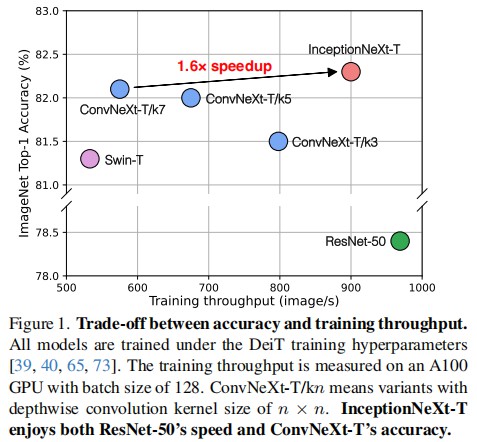
看图说话:
- 现有方法的局限性:请观察图中的蓝色圆点。ConvNeXt-T/k7(即标准版)虽然准确率较高(~82.1%),但其吞吐量仅为 575 images/s 左右。当我们简单地将卷积核缩小为 3 × 3 3\times3 3×3(ConvNeXt-T/k3)时,虽然速度提升到了 ~800 images/s,但准确率大幅下降。这说明在 ConvNeXt 框架下,速度与精度存在明显的矛盾。
- ResNet 的位置:右下角的绿色点 ResNet-50 速度极快(接近 1000 images/s),但精度已落后时代。
- 本文的目标:图右上角的红色点 InceptionNeXt-T 完美地结合了两者——它拥有接近 ResNet-50 的超高吞吐量,同时准确率甚至超过了 ConvNeXt-T。
- 结论:这证明了作者提出的“Inception 风格分解”策略成功打破了原有的大核速度瓶颈。
看图说话:
- 效率瓶颈:蓝色三角形显示,标准深度卷积的 FLOPs 随核大小呈二次方增长 ( k 2 k^2 k2)。
- 本文优势:红色圆形显示,本文提出的 Inception 深度卷积的 FLOPs 随核大小呈线性增长。这意味着我们可以使用更大的核(如 11, 13, 15)而不带来显著的计算负担。
3. 主要创新点
- Inception Depthwise Convolution:提出了一种新的空间混合算子,将昂贵的大核 DWConv 分解为几个并行的低成本分支(小核+带状核+Identity),有效降低了计算复杂度和内存访问成本。
- MetaNeXt Block:抽象出了一种通用的残差块结构 MetaNeXt,它是 MetaFormer 的简化版(合并了 Token Mixer 和 MLP 的残差连接),进一步提升了推理速度。
- 高性能与高效率的统一:构建了 InceptionNeXt 系列模型,在保持 SOTA 级别精度的同时,显著提升了现有大核 CNN 的实测吞吐量(Throughput),为未来架构设计提供了经济高效的 Baseline。
4. 方法细节
整体网络架构
InceptionNeXt 遵循了标准的四阶段金字塔结构(与 ResNet、ConvNeXt 一致):
- 输入 (Input):图像输入网络。
- Patch Embed / Downsampling:通过卷积层进行下采样,生成不同分辨率的特征图(Stride=4, 8, 16, 32)。
- MetaNeXt Blocks 堆叠:这是网络的主体。每个阶段包含多个堆叠的 MetaNeXt Block。
- 数据流: I n p u t → Inception DWConv → Norm → MLP → Residual Add → O u t p u t Input \rightarrow \text{Inception DWConv} \rightarrow \text{Norm} \rightarrow \text{MLP} \rightarrow \text{Residual Add} \rightarrow Output Input→Inception DWConv→Norm→MLP→Residual Add→Output。
- 注意:这里采用了一种简化的残差结构,即 Token Mixer 和 MLP 共享一个 Shortcut,这比 MetaFormer(两个 Shortcut)更高效。
- 输出 (Output):经过全局平均池化(GAP)和分类头输出结果。
核心创新模块详解:InceptionNeXt Block
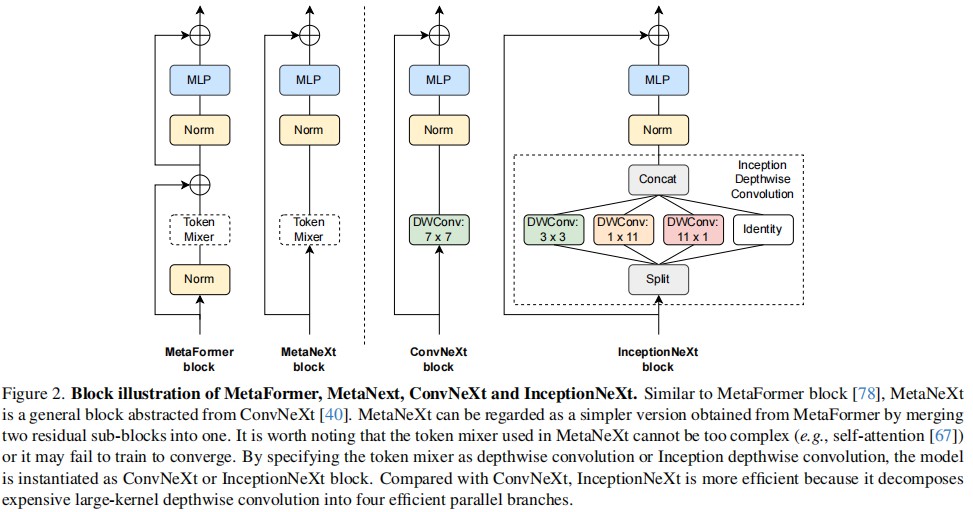
模块分析 (InceptionNeXt Block - 最右侧子图):
该模块的核心在于将 ConvNeXt Block 中的 7 × 7 7 \times 7 7×7 DWConv 替换为了 Inception Depthwise Convolution。让我们详细拆解这个“虚线框”内部的数据流:
-
输入分裂 (Channel Split):
假设输入特征图通道数为 C C C。首先沿通道维度将其切分为 4 个组。作者定义了一个“卷积分支比例”(Convolution branch ratio),默认为 1 / 8 1/8 1/8。这意味着并未对所有通道进行卷积处理。 -
并行分支处理 (Parallel Branches):
- 分支 1 (Small Square Kernel):处理部分通道。使用 3 × 3 3 \times 3 3×3 DWConv。目的:捕捉局部细节特征。
- 分支 2 (Horizontal Band Kernel):处理部分通道。使用 1 × 11 1 \times 11 1×11 DWConv。目的:捕捉水平方向的长距离依赖。
- 分支 3 (Vertical Band Kernel):处理部分通道。使用 11 × 1 11 \times 1 11×1 DWConv。目的:捕捉垂直方向的长距离依赖。
- 分支 4 (Identity Mapping):剩余的大部分通道不做任何卷积操作,直接通过。目的:保留原始信息,减少计算量(类似 ShuffleNet 的思想)。
-
特征拼接 (Concat):
将上述四个分支的输出在通道维度重新拼接回来,恢复为 C C C 通道。 -
后续处理:
拼接后的特征经过Norm(Batch Norm),进入MLP( 1 × 1 1\times1 1×1 Conv -> GELU -> 1 × 1 1\times1 1×1 Conv),最后与输入进行残差相加。
理念与机制总结
理念:“稀疏化与分解”。
作者认为并非所有通道都需要进行昂贵的大核卷积。
- 稀疏化:通过 Identity 分支,让一部分通道“休息”,这大大减少了内存访问。
- 分解:利用 Inception 的思想,将 k × k k \times k k×k 的大感受野分解为 k × 1 k \times 1 k×1 和 1 × k 1 \times k 1×k。这种分解将参数量和 FLOPs 从 O ( k 2 ) O(k^2) O(k2) 降低到了 O ( k ) O(k) O(k)。
- 协同: 3 × 3 3 \times 3 3×3 负责局部, 1 × 11 1 \times 11 1×11 和 11 × 1 11 \times 1 11×1 负责全局,Identity 负责特征复用。这种组合在理论上近似模拟了大核卷积的效果,但在硬件上却快得多。
图解总结
结合 Figure 1 的动机图和 Figure 2 的结构图:ConvNeXt 慢是因为 7 × 7 7\times7 7×7 DWConv 这种“致密”的大核算子不仅计算量大,更重要的是内存读写频繁。InceptionNeXt 通过 Figure 2 中的Split-Transform-Concat 机制,巧妙地绕过了这个瓶颈,用低成本的算子组合达到了图 1 右上角“又快又好”的效果。
5. 即插即用模块的作用
Inception Depthwise Convolution 是一个高度通用的算子,可以作为“即插即用”的模块替换现有的空间混合层:
- 替换大核卷积:在任何使用 7 × 7 7\times7 7×7 或更大卷积核的 CNN(如 ConvNeXt, RepLKNet)中,可以直接替换其 DWConv 层,以大幅降低 FLOPs 和提升推理速度,尤其是在移动端或边缘设备上。
- 轻量化模型设计:适用于对延迟敏感的场景(如自动驾驶、实时视频处理)。其 Identity 分支的设计类似于 GhostNet 或 ShuffleNet,非常适合作为移动端主干网络(Backbone)。
- Transformer 的替代:在 PoolFormer 或 MetaFormer 架构中,将其作为 Token Mixer,可以获得比 Pooling 更强的特征提取能力,同时比 Self-Attention 更快、更省显存。
6. 实验简单分析
- ImageNet 分类:
- InceptionNeXt-T 达到了 82.3% 的 Top-1 准确率,比 ConvNeXt-T 高 0.2%,同时训练吞吐量提升 1.6倍,推理吞吐量提升 1.2倍。
- 在相同的 FLOPs 下,InceptionNeXt 始终优于 Swin Transformer 和 ConvNeXt。
- 语义分割 (ADE20K):
- 作为 UperNet 的骨干网络,InceptionNeXt-T 达到了 47.9 mIoU,比 ConvNeXt-T 高出 1.2 mIoU,且 FPS 更高。这证明了其提取的特征不仅不仅适用于分类,在密集预测任务中也具有很强的鲁棒性。
- 消融实验:
- 去掉带状卷积(Band Kernels)会导致性能显著下降,证明了长距离依赖建模的重要性。
- 保留部分通道不做处理(Identity)是提升速度的关键,且对精度影响极小。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
7. 获取更多即插即用代码关注 【AI即插即用】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 24
24 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)