【实战干货】RAG 知识库的“地基”:如何实现多格式文档的高质量向量化处理?
·
前言
在复刻 RAG(检索增强生成)系统的过程中,很多开发者会发现:即使模型再强,如果输入的“知识”本身是一团乱麻,AI 的回答也只会是南辕北辙。
真正决定系统上限的,是你对非结构化数据的处理能力。今天我们深入聊聊如何把 PDF、Markdown、甚至是扫描件变成 LLM 能够理解的“黄金数据”。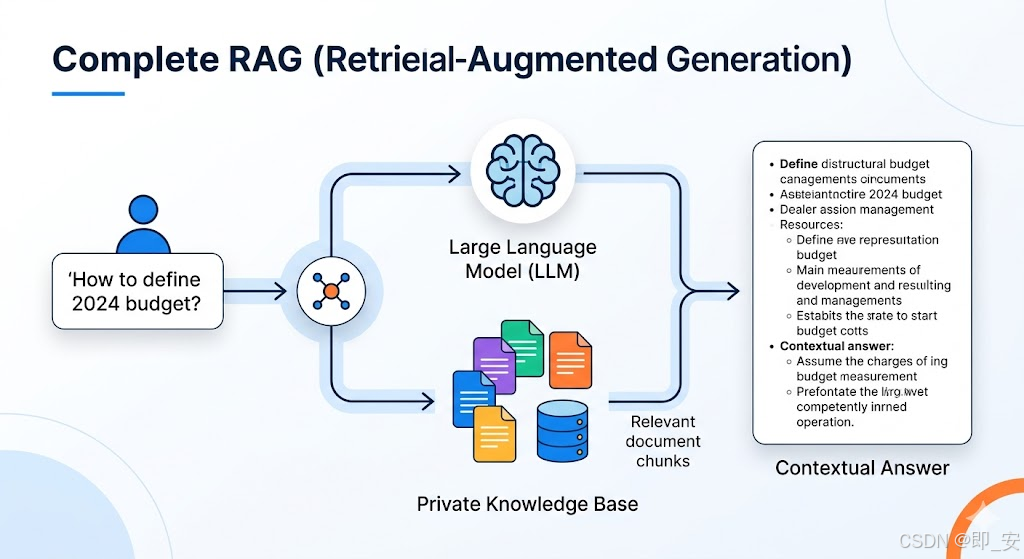
一、 复杂文档解析:绕不开的坑
企业内部数据通常不会乖乖地躺在纯文本里。常见的挑战包括:
- PDF 中的双栏排版:直接读取会导致左栏和右栏内容混在一起。
- 表格数据:传统的切分策略会将表格内容打碎,导致数据关联性丢失。
- 图片与公式:扫描件和技术文档中的 L a T e X LaTeX LaTeX 公式需要专门的处理流程。
加粗样式
二、 核心技术路径:从非结构化到向量化
要构建高质量知识库,你需要优化你的数据清洗 pipeline:
1. 智能版面分析(Layout Analysis)
利用 Unstructured 或 PaddleOCR 等工具,先识别文档的结构(标题、段落、列表、表格)。
2. 表格转换策略
将 PDF 中的表格提取出来,转换为 Markdown 格式。Markdown 能够很好地保留行列关系,方便 Embedding 模型捕捉特征。
3. 语义切分(Semantic Chunking)
舍弃固定长度切分。通过监测段落之间的余弦相似度变化,找到语义转折点进行切分,确保每一块内容都是一个完整的知识点。
三、 代码实战:高阶数据加载器
以下代码展示了如何使用 LangChain 结合高级解析器来处理复杂文档:
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 使用非结构化模式解析 PDF(支持多线程处理)
loader = UnstructuredPDFLoader(
"complex_enterprise_doc.pdf",
mode="elements", # 识别文档元素而非纯文本
strategy="fast"
)
docs = loader.load()
# 语义敏感的切分配置
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=100,
separators=["\n\n", "\n", "。", "!", "?"]
)
final_chunks = text_splitter.split_documents(docs)
# 打印切分后的第一条数据,检查元数据信息
print(f"Metadata: {final_chunks[0].metadata}")
四、 避坑经验谈
- Embedding 模型选型:不要盲目追求大参数量。在中文场景下,
BGE-M3或M3E系列模型在处理短文本对齐上表现极佳。 - 元数据注入(Metadata Enrichment):在切分后的文本块中手动注入文件名、页码、甚至章节标题。检索时,这些元数据能帮 LLM 快速定位来源。
- 持久化层选择:如果你是初学者,
FAISS是首选;如果是百万级以上的数据规模,请考虑使用Milvus或Zilliz以获得更好的检索性能。
五、 深入学习链接
如果你对 RAG 的全栈开发细节感兴趣,可以参考以下深度实践案例:
- 项目核心背景与原理图参考:CSDN 详细技术博客
- 工具推荐:LangChain、Unstructured.io、BGE Embedding 模型。
结语
RAG 不是简单的“搜索+生成”,而是一场关于数据工程的精耕细作。只有处理好地基般的文档数据,你的 AI 助手才能真正做到“言之有物,准确无误”。
关于 RAG 数据清洗,你有什么独门秘籍?欢迎在评论区交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)