02. 从Transformer架构到训练全流程
摘要:本文系统梳理了大语言模型(LLM)的核心工作原理与训练流程。首先解析了Transformer架构的四大优势:并行计算、长距离依赖捕捉、可扩展性与灵活性,并介绍了从分词到内容生成的完整处理流程。接着详细阐述了大模型训练的三个阶段:通过自监督学习进行海量数据预训练,通过监督学习完成场景化微调,以及通过人类反馈强化学习实现价值观对齐。最后以电商智能客服机器人为例,完整演示了从通用模型到专业应用的训练全过程。同时回顾上节课核心内容:提示词工程通过角色设定、少样本提示、链式思考等技巧优化输入,激发模型潜力,为本文理解模型内部机制奠定基础。帮助读者建立从“使用模型”到“理解模型”的完整认知框架,为模型优化和应用开发提供理论支撑与实践参考
上节课知识回顾:提示词工程
上节课我们重点学习了提示词工程,掌握了通过以下技巧引导大模型输出高质量内容:
1. 角色设定:明确为模型分配角色(如“资深法律顾问”“编程助手”),限定输出边界与专业度。
2. 少样本提示:提供少量示例,引导模型理解任务格式与期望输出。
3. 链式思考:要求模型逐步拆解问题,展示推理过程,增强透明性与可控性。 核心思想是“不改变模型本身,通过优化输入激发其潜力”,为后续理解模型内部机制奠定实践基础。
一、Transformer架构基础:大模型的核心引擎
大模型之所以能处理海量文本并生成流畅内容,离不开Transformer架构的支撑。这一架构彻底改变了传统序列模型的局限,核心优势体现在四个方面:
- 并行计算:传统RNN模型只能串行处理文本,而Transformer能同时处理整个句子的所有token,充分利用GPU等现代计算硬件,训练速度提升数倍。
- 捕捉长距离依赖:通过自注意力机制,每个词都能与句子中其他所有词建立联系。比如处理“我昨天买的苹果很好吃”时,模型能直接关联“苹果”和“好吃”,不受距离限制。
- 可扩展性:架构设计简单统一,能轻松扩展到更大参数量和更多训练数据,这也是大模型参数从亿级发展到万亿级的基础。
- 灵活性:既能用于文本生成,也能适配文本分类、机器翻译等各类NLP任务,成为自然语言处理的通用底座。
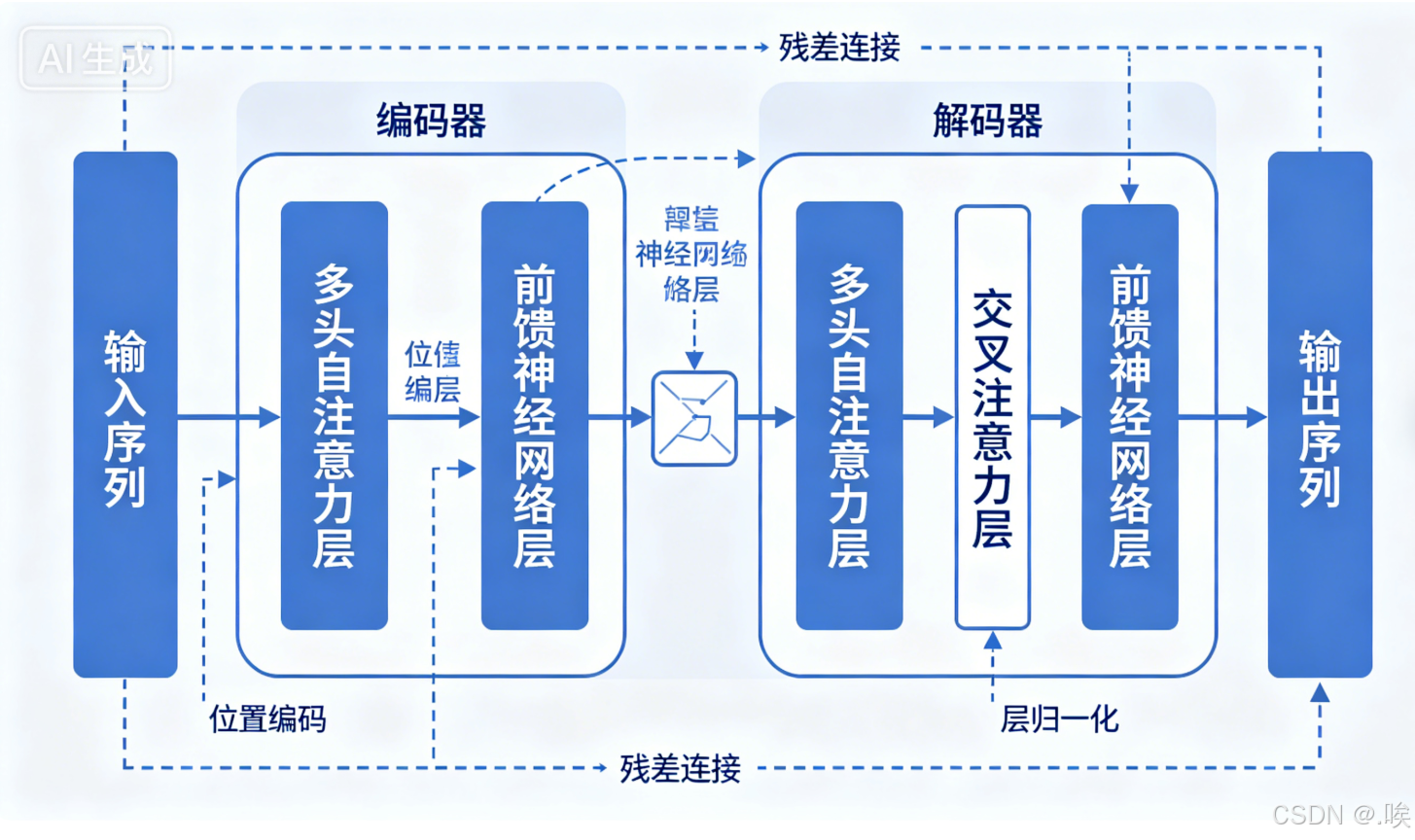
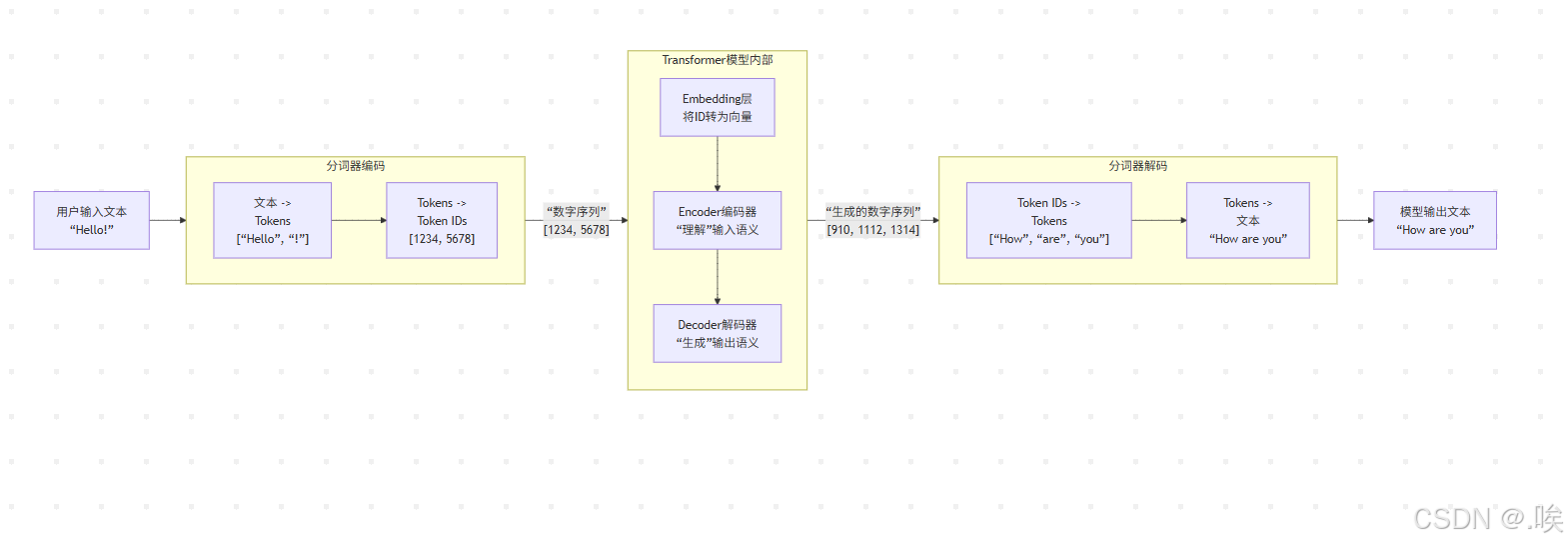
二、大模型的处理流程:从文本到语义的转化
当我们将一句话输入大模型时,会经历四个关键步骤:
- 分词:将“大模型很强大”拆解为“大”“模型”“很”“强大”等基础单元(token),不同模型的分词规则略有差异。
- 词嵌入:把每个token转化为高维向量,语义相近的词(如“猫”和“狗”)在空间中距离较近。
- Transformer处理:通过多层Transformer模块,利用自注意力机制和前馈网络对词向量进行深度加工,捕捉上下文关系。
- 最终内容生成:基于语义信息,通过概率计算逐个生成下一个token,最终拼接成完整回答。
三、训练流程的核心逻辑:从海量数据到人类对齐
大模型的训练不是一蹴而就的,而是分阶段逐步优化的过程。在理解具体流程前,需要先明确四种学习方式:
- 监督学习:人类给机器提供标注好的数据,比如“图片-标签”对,让模型学习输入与输出的对应关系。
- 无监督学习:仅提供未标注的数据,让模型自行挖掘数据中的规律,比如对文本进行聚类。
- 自监督学习:利用数据本身的结构生成“伪标签”,比如遮盖句子中的某个词,让模型预测被遮盖的内容,这是大模型预训练的核心方法。
- 强化学习:让模型通过与环境交互获得反馈,不断调整策略以最大化奖励,比如AlphaGo通过自我对弈提升棋力。
第一阶段:预训练——打造通用语言基础
预训练是大模型能力形成的核心阶段,这一阶段主要采用自监督学习:
- 数据来源:收集海量无标注文本,包括网页、书籍、论文、代码等,覆盖多语言和多领域。
- 训练目标:通过“预测下一个词”或“补全被遮盖的词”等任务,让模型学习语言的语法结构、世界知识和基本推理能力。
- 资源消耗:需要数千块GPU并行训练数周甚至数月,消耗数百万美元的计算成本,最终得到具备通用能力的“基础模型”。
第二阶段:模型微调——从通用到专用
预训练后的模型虽然知识丰富,但还不擅长遵循人类指令。模型微调阶段通过监督学习解决这一问题:
- 指令微调:收集数万条“指令-响应”对,比如“写一首关于春天的诗”对应一首七言绝句,让模型学会理解并执行具体任务。
- 高效微调:针对特定场景,可采用LoRA等技术仅微调少量参数,既保留模型的通用能力,又能快速适配垂直领域需求。
- 效果提升:经过微调的模型能准确理解“总结会议纪要”“生成Python代码”等指令,从“通用学霸”转变为“场景专才”。
第三阶段:基于人类反馈的强化学习——对齐人类价值观
为了让模型输出更符合人类偏好,还需要进行基于人类反馈的强化学习:
- 偏好标注:针对同一指令,让模型生成多个回答,由人类标注员对回答的质量、安全性、得体性进行排序。
- 奖励模型训练:用标注数据训练一个奖励模型,让它学会给符合人类偏好的回答打高分,给有害或低质回答打低分。
- 策略优化:通过强化学习算法(如PPO)优化主模型,使其生成的内容能最大化奖励模型的评分,同时避免偏离预训练和微调阶段学到的能力。
四、实战案例:电商智能客服机器人的训练全流程
为了更直观地理解上述流程,我们以“电商智能客服机器人”为例,拆解其训练过程:
- 预训练阶段:模型先学习海量通用文本,包括百科、新闻、小说等,掌握了“物流”“退款”“商品质量”等基础词汇的语义,以及基本的语法和逻辑推理能力,此时的它就像一个读过很多书但没接触过电商的“书呆子”。
- 模型微调阶段:收集10万条电商场景的“用户提问-客服回答”对,比如“我的快递到哪了?”对应“请提供订单号,我帮您查询物流进度”,让模型学会识别电商领域的指令并给出专业回答,此时它已经能处理常见的客服问题。
- 基于人类反馈的强化学习阶段:针对“我想退货”这类问题,让模型生成三个回答:①“退货流程:登录账号-进入订单页-点击退货-填写原因”;②“退货?你自己去订单页操作吧”;③“抱歉,我们无法为您办理退货”。由标注员对三个回答排序为①>②>③,训练奖励模型后,通过强化学习让主模型更倾向于生成①这样清晰、友好的回答,避免②的冷漠和③的错误信息,最终成为符合人类服务标准的智能客服。
五、总结
从Transformer架构的并行计算优势,到预训练、微调、基于人类反馈的强化学习的三阶段训练流程,大模型的能力形成是一个层层递进的过程。通过电商客服的实战案例,我们能更清晰地看到每个阶段的作用:预训练打基础,微调学技能,基于人类反馈的强化学习塑价值观。理解这些原理,不仅能帮助我们更好地使用大模型,也能为后续的模型优化和应用开发打下基础。
以上是我对大模型工作原理和训练流程的梳理,欢迎大家在评论区交流讨论!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)