【进阶篇】打破“仅跑通”僵局:RAG 企业私有知识库落地的五大性能瓶颈与解决方案
·
前言
在上一篇文章中,我们聊到了 RAG(检索增强生成)的基本架构和简单实现。很多开发者在跑通 Demo 后,信心满满地投入生产环境,却发现现实很骨感:
- AI 回答总是“答非所问”。
- 检索速度慢如蜗牛。
- 回答内容甚至不如直接问通用模型。
RAG 从“能用”到“好用”之间,横亘着巨大的鸿沟。 今天,我们就来深入探讨 RAG 系统落地过程中的核心难点,并给出相应的进阶优化策略。
一、 RAG 系统的性能“杀手”在哪里?
一个工业级的 RAG 系统,其性能和准确性往往取决于以下五个关键环节:
- 数据清洗(Data Cleansing):垃圾进,垃圾出。
- 文本切分(Chunking):切得太细,丢失语义;切得太粗,检索不准。
- 多路召回(Hybrid Retrieval):单一的向量检索往往不够健壮。
- 精排(Re-ranking):如何找到那 1% 最相关的上下文。
- Prompt 工程(Prompt Engineering):如何让模型更好地利用上下文。
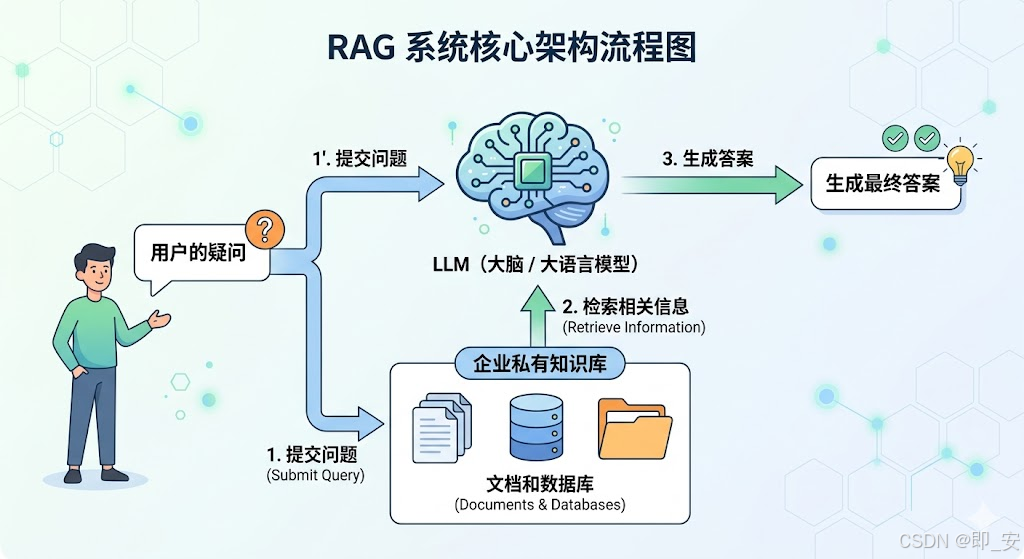
二、 进阶优化方案
为了解决上述问题,我们需要对现有的 RAG 流程进行升级。
1. 深度文档解析(Deep Document Parsing)
不要仅仅依赖基础的 PDF 加载器。你需要处理表格(Table)、图片(Image)和复杂的排版。
- 优化方案:引入 OCR 技术提取图片中的文字,利用版面分析(Layout Analysis)技术保留文档的逻辑结构,将表格转换为 Markdown 格式存储。
2. 父子分块策略(Parent-Child Indexing)
传统的固定长度切分(如 512 token)往往会截断关键语义。
- 优化方案:采用层次化切分。先切分为较大的“父块”(Parent Chunk)以保留完整语境,再切分为较小的“子块”(Child Chunk)用于向量检索。检索时,通过子块定位到父块,将完整的父块上下文提交给模型。
3. 多路召回与混合搜索(Hybrid Search)
向量搜索(Dense Retrieval)在处理模糊查询和语义理解上表现优异,但在处理专有名词(如“SKU12345”)或精确数字时经常失效。
- 优化方案:引入关键词搜索(Sparse Retrieval,如 BM25)。在检索阶段,同时运行向量搜索和关键词搜索,然后将结果进行合并。
4. 精排模型(Re-ranking)的引入
向量数据库返回的前 N 个结果,并不一定是语义最相关的。
- 优化方案:在向量检索后,添加一个精排阶段。使用专门的精排模型(如基于 BERT 的 Cross-Encoder)对初步筛选出的文档块进行再次评分和排序,挑选出最核心的上下文。
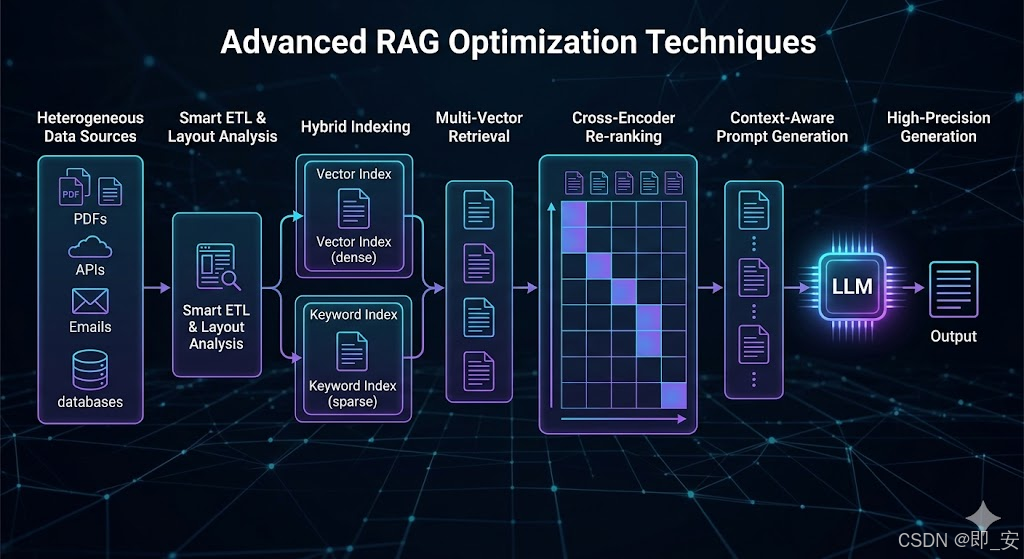
三、 进阶代码示例(基于 LangChain 和 Re-ranker)
这里展示如何利用 Rerank_cross_encoder 对检索结果进行优化:
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from sentence_transformers import CrossEncoder
# 1. 初始化基础检索器
embeddings = OpenAIEmbeddings()
db = FAISS.load_local("faiss_index", embeddings)
base_retriever = db.as_retriever(search_kwargs={"k": 20}) # 先捞20个出来
# 2. 初始化精排模型
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512)
compressor = CrossEncoderReranker(model=model, top_n=3) # 精排后只取前3个
# 3. 构建压缩检索器(即带精排的检索器)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=base_retriever
)
# 4. 执行检索
query = "如何处理2024年第N1号财务报表中的长短期负债冲突?"
compressed_docs = compression_retriever.get_relevant_documents(query)
# 打印精排后的结果
for i, doc in enumerate(compressed_docs):
print(f"[Result {i+1}] Score: {doc.metadata['relevance_score']:.4f}\nContent: {doc.page_content[:200]}...\n")

四、 总结与参考资料
RAG 系统的优化是一个系统工程,需要从数据源头一直调优到模型的 Prompt。只有不断地迭代和调优,才能让 RAG 真正满足企业级的业务需求。
如果你想了解更多关于 RAG 技术落地的细节和更复杂的架构设计,请参考以下链接:
- 原文详细教程与背景:点击查看详情
- 相关工具:LangChain, Cross-Encoder 模型, FAISS 向量库。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)