我的 GA-CNN-TCN-BiLSTM-Attention 锂电池预测与 SHAP 解释实战
目录
不是把模块堆长就行:我用 GA + CNN + TCN + BiLSTM + Attention + SHAP 做锂电 SOH 预测的一次真实代码复盘
这次我想认真复盘的,不是一篇把模型名字串起来的“组合拳介绍”,而是我在一个锂电池 SOH 预测原型项目里,围绕局部特征提取、长短期依赖建模、关键时间步聚焦、超参数优化和结果可解释性这五个目标,怎么一步一步把方案打磨成 GA + CNN + TCN + BiLSTM + Attention + SHAP 这条完整链路的。
不过在正式展开之前,我先把一个非常关键的事实说清楚:我当前这版仓库里并没有接入真实锂电池实验数据文件。main.py 里实际调用的是 generate_dummy_battery_data(),生成了 1500 条模拟样本;标签是一个带噪声的 SOH 下降曲线,输入特征则被命名为“电压、 电流、 温度、 时间、 循环次数”。也就是说,这套代码现在更像是一个面向锂电 SOH 预测的完整工程原型,而不是已经在真实实验数据上充分验证完毕的最终版本。后面这篇文章,我都会严格按这份真实代码来讲,不会把它包装成代码里并不存在的结果。
项目背景
我之所以会做锂电池状态预测,本质上还是因为这个问题天然具有“时序 + 非线性 + 多因素耦合”的特点。无论我要预测的是 SOH、容量衰减、寿命趋势,还是更广义的性能退化,它都不是一个简单的静态回归问题。电池数据里通常同时存在几类很典型的困难:
局部上,它会有短时间波动,比如充放电过程中的电压、电流、温度变化;全局上,它又存在长期退化趋势,比如随着循环次数增加,容量和健康状态逐渐下降;更麻烦的是,这种变化还经常是非线性的、带噪声的,而且短期模式和长期趋势是交织在一起的。
也正因为这样,我一开始就不太想把问题停留在“单一模型够不够”这个层面。单纯靠一个浅层回归器,很难同时吃掉局部波动和长期依赖;只靠 RNN 或 LSTM,又容易把局部模式的抽取做得不够直接;只靠卷积,长依赖又可能不够。我的想法很明确:不是为了把模型名字拉长,而是想让不同模块各自负责一件事,然后形成互补。
从当前代码看,我最终把预测目标设成了 SOH,一步预测下一个时间点的健康状态。create_sequences() 的写法非常直接,就是用长度为 16 的历史窗口去预测窗口之后的那个 SOH:
for i in range(len(features) - seq_length):
x = features[i:(i + seq_length)]
y = labels[i + seq_length]
这段实现其实已经把任务定义说得很清楚了:我不是做整段序列重建,也不是做多步滚动预测,而是做一个标准的滑动窗口单步预测。
我是怎么把模型结构一步步定下来的
虽然这版仓库里没有把每一个中间版本都保留下来做成可切换 baseline,但从 model.py 里 CNN_TCN_BiLSTM_Attention 的串联顺序,我自己的优化路径其实很清楚。
先说 CNN。我先引入一维卷积,不是因为它“常见”,而是因为我不想一上来就把原始序列整段扔给循环网络。锂电这类多变量时序里,很多有用的信息其实先出现在局部邻域里,比如相邻时刻的电压、电流、温度组合变化。CNN 在这里更像一个短窗口模式提取器。代码里这一层写得很直接:
self.cnn = nn.Conv1d(
in_channels=config.input_dim,
out_channels=config.cnn_out_channels,
kernel_size=config.cnn_kernel_size,
padding=config.cnn_kernel_size // 2
)
输入先从 (batch, seq, feature) 变成 (batch, feature, seq),然后做一维卷积。这一步解决的是“先把局部混合模式卷出来”,而不是让后面的时序模块自己从原始信号里一点点摸索。
然后我加上 TCN。原因也很现实:普通卷积能看局部,但感受野有限;如果我只把 CNN 堆深一点,未必划算。TCN 的价值在于它用膨胀卷积扩大感受野,同时保留卷积在训练稳定性和并行性上的优势。更关键的是,我在 TemporalBlock 里保留了残差结构和 Chomp1d,这说明我希望它在“扩大时间视野”的同时,仍然保持因果对齐和可训练性。代码里 TemporalConvNet 两层的膨胀系数分别是 1 和 2,通道配置是 [32, 64],这意味着它不是无脑堆很多层,而是在一个比较轻量的规模上先做多尺度时序建模。
再往后是 BiLSTM。很多人会问,前面都已经有 TCN 了,为什么还要 BiLSTM,会不会重复?我的理解是,它们做的事并不一样。TCN 更擅长用卷积方式抓多尺度局部时间模式,它对“某种形状出现过没有”很敏感;BiLSTM 更擅长把窗口内前后文联系起来,去理解一个时间步在整个历史片段中的位置关系。对于我现在这个任务来说,输入是完整历史窗口,预测的是窗口之后的下一个 SOH,所以我在窗口内部使用双向 LSTM 并不构成未来泄漏,它只是更充分地利用当前窗口里的上下文信息。也正因为这个原因,我把 BiLSTM 放在 TCN 后面,而不是放在最前面直接吃原始特征。
Attention 是我后面加上的重点。坦白说,我不太喜欢那种“只要是序列模型就默认加个注意力”的做法。我要它,是因为我不想让窗口里 16 个时间步被平均对待。做电池预测时,有些片段的信息密度高,有些片段更像背景;如果模型最后只能拿一个 BiLSTM 的整体隐藏状态去回归,我会担心它把关键时间步冲淡。所以我在代码里用了一个很轻量的加性注意力:
self.attention = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, 1)
)
它的作用很明确,不是生成复杂的对齐矩阵,而是给每个时间步打一个分数,再通过 softmax 形成权重,最后做加权求和得到上下文向量。也就是说,我想让模型自己学会:这 16 个历史点里,到底哪些该看得更重。
接着是 GA。这一块不是“为了高大上”,而是因为我很清楚这种混合模型里有些超参数非常敏感,尤其是学习率、LSTM 隐藏维度、CNN 输出通道数。如果只靠手工调参,我很容易陷入拍脑袋;如果直接做细粒度网格搜索,成本又不太友好。所以我在 ga_optimize.py 里只挑了 3 个最关键的参数让遗传算法去搜:
- learning_rate
- lstm_hidden_dim
- cnn_out_channels
搜索范围也写得很实在:
- 学习率:1e-4 ~ 1e-2
- LSTM 隐藏维:16 ~ 128
- CNN 通道数:16 ~ 64
这说明我的目标不是“全参数自动搜索”,而是优先解决最影响训练行为的几个旋钮,把调参从纯经验驱动,拉回到一个可搜索的范围内。
最后我接入 SHAP。我加它不是为了让项目看起来“带解释性”,而是因为我不希望最后只拿到一张预测曲线,然后对模型内部到底学到了什么一无所知。电池预测不是普通推荐系统,很多时候它会影响维护判断、寿命评估甚至安全决策。模型能不能解释,决定了我到底敢不敢信它。对我来说,SHAP 要回答的是三个问题:模型更关注哪些输入变量;这些变量是怎么推动预测变大或变小的;模型学到的规律到底像不像一个有物理意义的退化模式。
代码实现是怎么串起来的
我这版工程的入口非常集中,主流程几乎都在 main.py 里串起来了。它的执行顺序很清楚:
- 构造配置 Config()
- 生成模拟数据 generate_dummy_battery_data()
- 调 get_dataloaders() 做归一化和序列化
- 调 run_ga_optimization() 搜超参数
- 用最优配置实例化最终模型
- 调 train_best_model() 做正式训练并保存最优权重
- 调 evaluate_and_plot() 输出预测曲线和残差图
- 调 plot_attention_heatmap() 画注意力热力图
- 调 run_shap_analysis() 做 SHAP 分析
先看数据部分。Config 里把核心输入维度和窗口长度都定死了:
- seq_length = 16
- input_dim = 5
- output_dim = 1
主脚本里生成了 1500 个时间点的数据:
features = np.random.randn(samples, input_dim)
time_steps = np.arange(samples)
soh = 1.0 - (time_steps / samples) * 0.3 + np.random.normal(0, 0.01, samples)
这里有一个我必须如实说明的点:从特征命名上看,我原本想把输入理解成“电压、电流、温度、时间、循环次数”五个变量,但当前实际生成的 features 是纯随机高斯噪声,真正体现退化趋势的只有标签 soh。这也意味着这版代码现在验证的是“方法流程能不能跑通”,而不是“模型有没有真正学到电池机理”。
接着是 data_loader.py。这里我用了 MinMaxScaler 做归一化,再用滑动窗口把原始二维特征变成三维序列张量。按当前数据量计算,1500 个原始点经过长度为 16 的窗口切分后,会得到 1500 - 16 = 1484 条样本,再按 8:2 划分成训练集和测试集,差不多是 1187 / 297。由于 train_loader 里设置了 drop_last=True,每个 epoch 真正参与训练的是 1184 条样本,最后 3 条会被丢掉。
这里还有两个很真实的工程细节。第一,当前代码是先对全量数据 fit_transform,再去划分训练集和测试集,这会带来轻微的数据泄漏;第二,函数只返回了 label_scaler,没有把 feature_scaler 一起保存出来。代码注释其实也已经意识到这个问题了,说明我自己也知道,如果后面要做正式推理,Scaler 必须跟着模型一起固化。
再看模型前向过程,这是整个工程里最核心的一段:
x = x.permute(0, 2, 1)
c_out = F.relu(self.cnn(x))
t_out = self.tcn(c_out)
t_out = t_out.permute(0, 2, 1)
r_out, _ = self.bilstm(t_out)
context, _ = self.attention(r_out)
out = self.fc(context)
如果按当前保存下来的最优权重去反推,模型的实际形状变化大致是这样的:
- 输入:(B, 16, 5)
- 转置后:(B, 5, 16)
- CNN 后:(B, 34, 16)
- TCN 后:(B, 64, 16)
- 转回 LSTM 输入:(B, 16, 64)
- BiLSTM 后:(B, 16, 146)
- Attention 聚合后:(B, 146)
- 全连接输出:(B, 1)
这里的 34 和 73 很有意思。Config 默认值其实是 cnn_out_channels=32、lstm_hidden_dim=64,但我把 best_soh_model.pth 的权重形状反推了一下,当前保存下来的最优模型实际上已经把这两个值调成了 34 和 73。这正好也说明 GA 确实在改变网络结构,而不是只做了一个形式上的搜索。至于最终学习率,当前代码没有额外落盘,所以单看现有文件没法反推出运行时的具体值。
GA 和主模型训练的衔接方式也很清楚。ga_optimize.py 里先定义了一个 quick_train_eval(),每组候选参数只快速训练 5 个 epoch,然后直接在验证集上算 MSE,作为适应度。再由 sko.GA 去完成种群搜索。当前设置是:
- 种群数量:10
- 迭代代数:5
- 每个个体快速训练:5 个 epoch
- 变异概率:0.1
这套设计的优点是快,总代价可控;缺点是候选参数的好坏是用“短训练代理”来评估的,跟最终训练 80 轮的真实表现之间不一定完全一致。对原型项目来说,这个取舍我觉得是合理的,但如果后面做正式实验,我会更谨慎地处理。
正式训练部分写在 train_best_model() 里,损失函数就是 nn.MSELoss(),优化器是 Adam,没有加学习率调度器,也没有显式早停,而是靠“验证集损失下降就保存权重”来做 checkpoint 管理。输出结果则非常完整,一次性生成 6 张图:
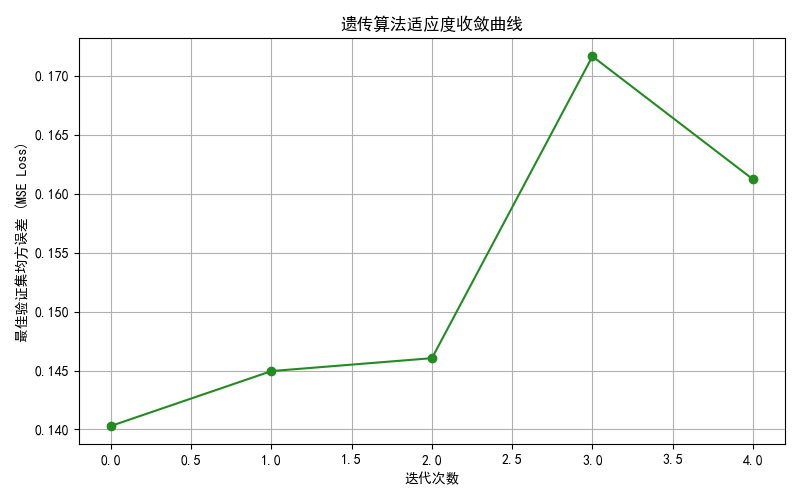
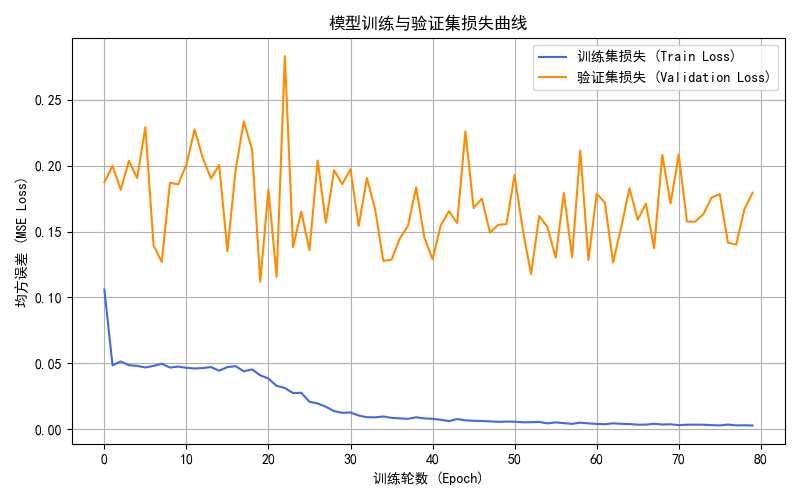
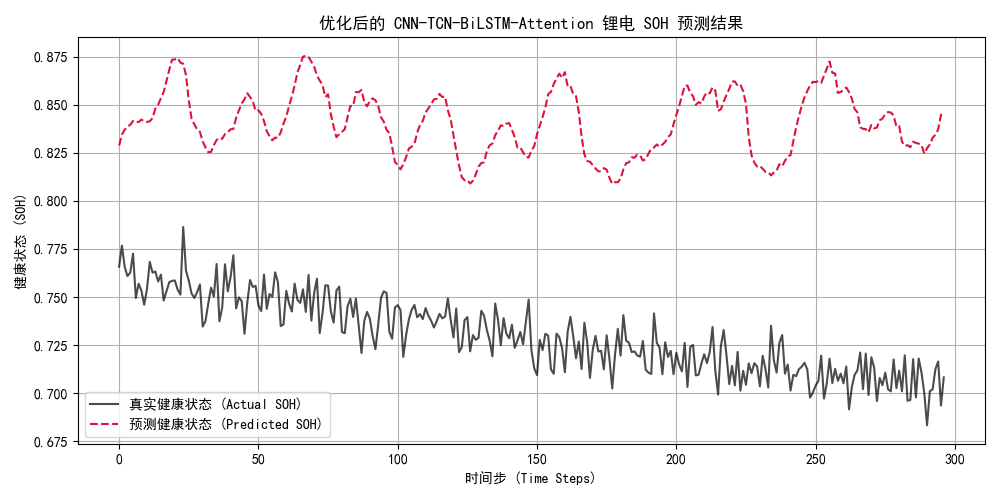
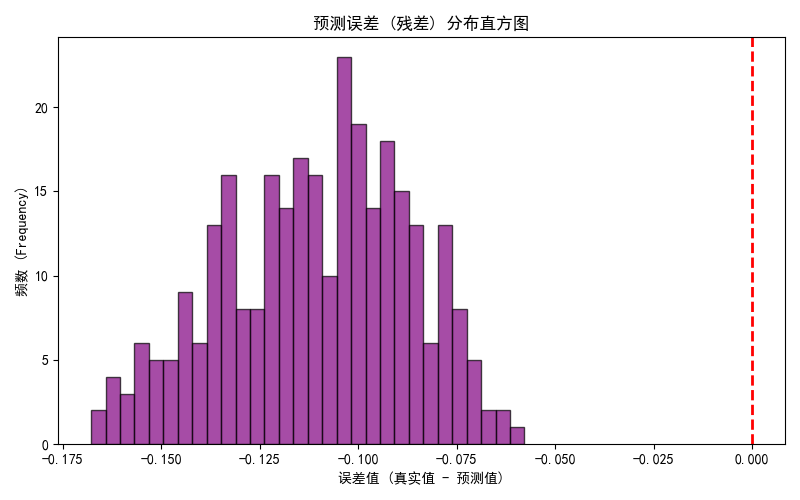


- plot_1_ga_convergence.png:GA 收敛曲线
- plot_2_loss_curve.png:训练/验证损失曲线
- plot_3_soh_prediction.png:SOH 预测曲线
- plot_4_error_distribution.png:残差分布直方图
- plot_5_attention_heatmap.png:注意力热力图
- plot_6_shap_summary.png:SHAP 总结图
SHAP 的接入方式也比较标准。我从训练集中截取前 100 条样本作为背景集,再拿测试集的第一个 batch 作为解释对象,用的是 shap.GradientExplainer。同时我还专门把 torch.backends.cudnn.enabled 临时关掉,这通常是为了避开 RNN 梯度解释时和 cuDNN 的兼容问题。这是一个很典型、也很实用的工程小细节。
核心原理怎么落到我的代码上
我不想把这一节写成脱离实现的纯理论,所以只讲和当前代码真正对应得上的部分。
一维卷积这一步,本质上是在时间维上滑动卷积核,对短窗口内的多变量组合模式做抽取。可以写成:
在我的代码里,k=3,也就是每次看 3 个相邻时间点。它的意义不是做长依赖推理,而是先把局部变化模式卷出来,给后面的 TCN 和 BiLSTM 提供更高层的输入。
TCN 的关键是膨胀卷积。它在第 tt 个位置的计算可以理解成:
其中 dd 是膨胀系数。在我的实现里,两层 TemporalBlock 的膨胀系数分别是 1 和 2。这意味着第二层看到的时间间隔已经被拉开了,感受野比普通卷积大得多,但参数量并没有线性爆炸。
BiLSTM 负责的是对 TCN 输出后的序列做上下文整合。它的门控形式还是标准的 LSTM:
我在代码里用的是双向版本,所以每个时间步最终会得到前向和后向两个隐藏状态的拼接输出。当前保存模型的 hidden_dim=73,所以 BiLSTM 输出维度是 146。
注意力层做的是时间步重加权。对应到代码里的 Attention 模块,可以写成:
et=v⊤tanh(Wht),αt=exp(et)∑jexp(ej)et=v⊤tanh(Wht),αt=∑jexp(ej)exp(et)c=∑tαthtc=t∑αtht
这里的 htht 就是 BiLSTM 在第 tt 个时间步的输出,αtαt 是该时间步的注意力权重,cc 是最后送进全连接层的上下文向量。对我这个项目来说,这一步非常重要,因为它明确告诉模型:16 个时间步不是同权的。
GA 的适应度函数,本质上就是拿验证集 MSE 来衡量一组超参数的优劣:
在 fitness_func() 里,参数向量 pp 对应的就是学习率、LSTM 隐藏维和 CNN 输出通道数。我的目标很明确:不去搜索一大堆边缘超参,只盯住最可能影响训练行为的核心参数。
结果怎么看,模型到底有没有发挥作用
先看 GA 收敛图。当前这版运行结果里,GA 曲线并不是单调下降的,而是存在明显波动。这很正常,也很符合代码设置本身的特点:种群只有 10,迭代只有 5 代,而且每个个体只快速训练 5 个 epoch。换句话说,我这里的 GA 更像是一次轻量级启发式搜索,而不是一个收敛得很充分的大规模超参数优化过程。它的作用主要是把默认参数从“拍脑袋初始化”往“更可用的区域”推一把。
再看训练日志,这部分信息其实非常有代表性:
- Epoch 10:Train Loss 0.047557,Val Loss 0.185718
- Epoch 20:Train Loss 0.040935,Val Loss 0.111830
- Epoch 30:Train Loss 0.012470,Val Loss 0.185943
- Epoch 80:Train Loss 0.002861,Val Loss 0.179426
如果只看训练损失,我很容易误以为模型越训越好;但一看验证损失就会发现,真正的最好点其实出现在第 20 轮左右。后面训练损失继续往下掉,验证损失却开始明显波动甚至反弹。这也是为什么 train_best_model() 要保存验证集最优权重,而不是拿最后一轮直接输出。换句话说,我最终真正用于预测的,不是第 80 轮的模型,而是大概率停在第 20 轮附近的那份 checkpoint。
这一点我后来又用保存下来的 best_soh_model.pth 复核了一次,重新在同样的模拟数据上做评估后,测试集归一化 MSE 正好就是 0.111829,和第 20 轮日志完全对上。这说明当前结果图对应的确实是“验证集最优权重”,而不是随手拿最后一轮凑出来的。
但更重要的是,我在看 plot_3_soh_prediction.png 和 plot_4_error_distribution.png 时,得到的结论并不是“模型效果很好”,而是一个更真实的判断:这套流程跑通了,但当前数据构造并不支持它学出可信的 SOH 规律。
原因很直观。预测曲线整体明显高于真实曲线,残差直方图大部分都落在 0 的左侧,说明 真实值 - 预测值 大多为负,也就是模型在系统性高估 SOH。我把当前保存权重又补算了一下,测试集上的平均残差大约是 -0.1107,预测值主要落在 0.809 ~ 0.875,而真实值主要在 0.683 ~ 0.786。这个偏差已经不是“有点误差”,而是很明显的整体偏移。
这并不意味着 CNN + TCN + BiLSTM + Attention 这个思路本身错了,而是说明当前输入和标签之间没有建立起足够真实的关联。因为 generate_dummy_battery_data() 里那 5 维输入本质上只是随机噪声,模型能学到的主要是训练集分布下的一些偶然模式,很难在测试段上真正追踪 SOH 下降趋势。
注意力热力图倒是提供了一个有意思的侧面信息。当前 plot_attention_heatmap.png 是从测试集第一批数据里只拿一个样本画出来的,所以我不会把它当成全局规律,但至少从这张图上看,最近的时间步权重更高,尤其 t-2 和 t-1 相对更突出。这和单步预测的直觉是吻合的:离预测点越近的历史片段,往往越直接。
至于“加入 Attention 前后到底提升了多少”“GA 优化前后提升了多少”,我这里不会硬写具体数字。原因很简单:当前仓库没有把这些对照实验单独保留下来,也没有做系统消融。能诚实下的结论是,代码结构上它们各自承担了明确职责,但从现有文件我不能负责任地给出一组并不存在的 ablation 指标。
为什么我还要专门做 SHAP
如果这个项目只是为了在图上画出一条预测曲线,其实做到 evaluate_and_plot() 就可以收手了。但我还是把 SHAP 接了进去,因为在电池预测这个问题上,我真的不太接受“黑箱高分”这件事。
如果一个模型能把 SOH 预测得很准,但我完全不知道它到底看重了哪些输入特征,那么这个模型一旦被拿去支持寿命评估、维护建议或者安全相关判断,我心里其实是不踏实的。尤其在电池这种问题上,解释性不是“锦上添花”,而是可信度的一部分。
从实现上看,我当前这版 SHAP 做的是时间序列的全局聚合解释。GradientExplainer 先对三维输入求贡献值,然后我在时间维上做平均,把 (batch, seq, feature, 1) 压缩成接近二维的形式,再去画 summary_plot。这个思路本身没问题,它的目标是回答:从整个窗口的平均贡献来看,哪些输入变量更重要。
但这里我也必须非常诚实地指出,当前 plot_6_shap_summary.png 的展示效果其实并不理想,甚至暴露出了两个我后面一定会改的问题。
第一个问题是实现细节。当前代码里用了:
shap_values_2d = np.mean(shap_values, axis=1)
test_data_2d = np.mean(test_data.cpu().numpy(), axis=1)
可实际 shap_values 的形状是 (batch, seq, feature, 1)。我只对时间维做了平均,却没有把最后那个单输出维 squeeze 掉,这会导致传给 summary_plot 的数组维度不够干净,所以图上现在只清晰显示出了一行特征标签,解释结果是失真的。
第二个问题比实现更本质:当前输入特征本身是随机生成的,它们虽然被命名成“电压、电流、温度、时间、循环次数”,但数值上并没有真正承载这些物理含义。换句话说,就算 SHAP 算出了某个特征更“重要”,这个重要性也很难被解释成可信的电池机理结论。
也正因为这样,我反而更能感受到 SHAP 的价值。它不是只在模型效果很好时才有用,很多时候它还能帮我暴露问题。当前这个结果恰恰提醒了我:如果输入数据本身没有物理含义,解释性图再漂亮,也不应该被过度解读。
总结与反思
如果让我给这套项目做一个真实的自我评价,我会说:这是一套把时序预测、超参数优化和可解释性分析完整打通的原型框架,而且模块职责是清楚的,不是乱堆。
CNN 负责局部模式提取,TCN 负责多尺度时序感受野,BiLSTM 负责上下文整合,Attention 负责关键时间步聚焦,GA 负责降低手工调参的盲目性,SHAP 负责把“模型为什么这么判断”这件事往前推进一步。从工程链路上看,这个设计是成立的。
但如果我要更严格地看它,我也得承认这版代码还有不少原型阶段的痕迹,而且这些问题都挺真实。
第一,数据仍然是模拟数据,输入特征和 SOH 之间没有真正建立物理联系,所以当前结果更适合验证 pipeline,不适合拿来证明模型优越性。
第二,get_dataloaders() 是先归一化再划分数据,存在数据泄漏风险。
第三,当前 test_loader 同时承担了 GA 适应度评估、训练过程选模和最终结果展示三种角色,本质上把验证集和测试集混用了。
第四,GA 虽然会返回最优配置,但当前脚本没有把最终最优学习率等参数持久化到文件里,后续复现并不方便。
第五,SHAP 聚合时还差一步 squeeze,解释图现在只能算“流程跑通”,还谈不上高质量分析。
第六,目录名里的 Attentio 少了一个 n,主脚本也把数据生成、训练、评估、解释全耦合在一个文件里,这种个人项目里很常见,但如果后面要做开源、复现或者论文支撑,我一定会把命名和结构再整理一遍。
如果我继续往下做,我下一步最想补的不是再加一个新模块,而是把基础做扎实:
- 把真实电池数据接进来,让“电压、电流、温度、时间、循环次数”真的对应到可解释的输入。
- 把数据拆成 train / val / test 三部分,Scaler 只在训练集上拟合。
- 给模型补上系统消融实验,真正回答每个模块到底贡献了多少。
- 把 SHAP 的维度处理修正掉,并把时间维解释做得更细,而不是只做全局平均。
- 增加随机种子控制、配置落盘和脚本拆分,让这套工程更容易复现和扩展。
我最后想强调的一点是,这个项目真正值得讲的地方,不是模型名字够不够长,而是我在处理一个典型时序预测问题时,怎么围绕“局部特征、长短依赖、关键时间步、超参数、可解释性”这五件事去分工设计。哪怕当前版本还只是原型,我也更愿意把它写成一份诚实的工程复盘,而不是一篇看起来很强、但和代码真实状态脱节的介绍。
需要源代码的,请在评论区下留言,作者会在半个小时内回复。制作不易,请各位看官老爷点个赞和收藏!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)