【IEEE TGRS 2026】基于“特定域原型”和“对比学习”实现跨域增量学习新范式——Cross-Domain Incremental Learing(CDIL)
原文链接:
Cross-Domain Incremental Image Classification via Domain-Specific Prototypes and Contrastive Learning | IEEE Journals & Magazine | IEEE Xplore https://ieeexplore.ieee.org/document/11333380
https://ieeexplore.ieee.org/document/11333380
Abstract
增量学习(Incremental Learning,IL)场景中的遥感模型通常需要应对新出现的类和跨领域的特征转移,本文将这种综合挑战称为跨域 IL(Cross-Domain,CDIL)。
现有方法通常单独处理类 IL (CIL) 或者域 IL (DIL),无法有效处理跨域转换的重复类,并导致跨域的灾难性遗忘或特征错位。为了解决这一问题,本文提出了一种新的 CDIL 框架,它将具有领域特定的适配器模块(domain-specific adapter)的冻结的预训练主干(frozen-ViT)和特定领域的原型(domain-specific prototype)构建集成在一起。该架构通过冻结预训练的ViT保留了泛化的特征表示,同时通过轻量级适配器捕获特定于域的细微差别,它用来存储来自每个域的类原型以统一重复类的知识。
同时,本文进一步引入多级监督对比损失(multilevel supervised contrastive losses),以确保跨领域的类表示一致。
Introduction
目前的增量学习(Incremental Learning,IL)主要方法如下:
①基于排练(Rehearsal-based),存储先前数据的缓冲区并在训练期间重播它,但这引起了隐私和可扩展性问题。
②基于正则化(Regularization-based),限制参数更新以保留先前学到的知识,但在存在域转移的情况下通常表现不佳。
③动态架构(Dynamic architectural),通过扩展网络或通过特定于任务的模块路由输入来增强模型能力。
最近的一项重大发展是采用预训练模型 (PTMs),利用大规模预训练,基于 PTM 的方法通过结合prompt tokens进行特定领域或类适应,或使用轻量级适配器来实现特定于任务的子空间扩展 ,从而有效地对抗遗忘并增强泛化。
尽管这些方法提供了参数和内存效率,但在面对跨多个域的重复类时表现出明显的缺点:
①类 IL (Class-IL) 技术通常缺乏针对不同域中的同类提示的显式对齐策略;
②域 IL (Domain-IL) 方法可能会存在破坏当前重复类的一致识别能力;
③任务 IL (Task-IL) 方法通常假设任务标识(task-id)在推理时已知,并为每个任务分配单独的头或适配器,但这种对显式任务标签的依赖在实际部署中是不切实际的。
而本文提出了一种更全面、更实用的范式:跨域 IL(CDIL)。本文是第一个将 CDIL 定义为一种可能多次发生同时具有类扩展和域演化的增量学习任务,如下图1描述。

①CIL 跨单个域中的任务引入了新类;
②DIL 在转移域的同时跨任务保留相同的标签空间;
③CDIL 结合了类扩展和跨任务的域转移。
Methods
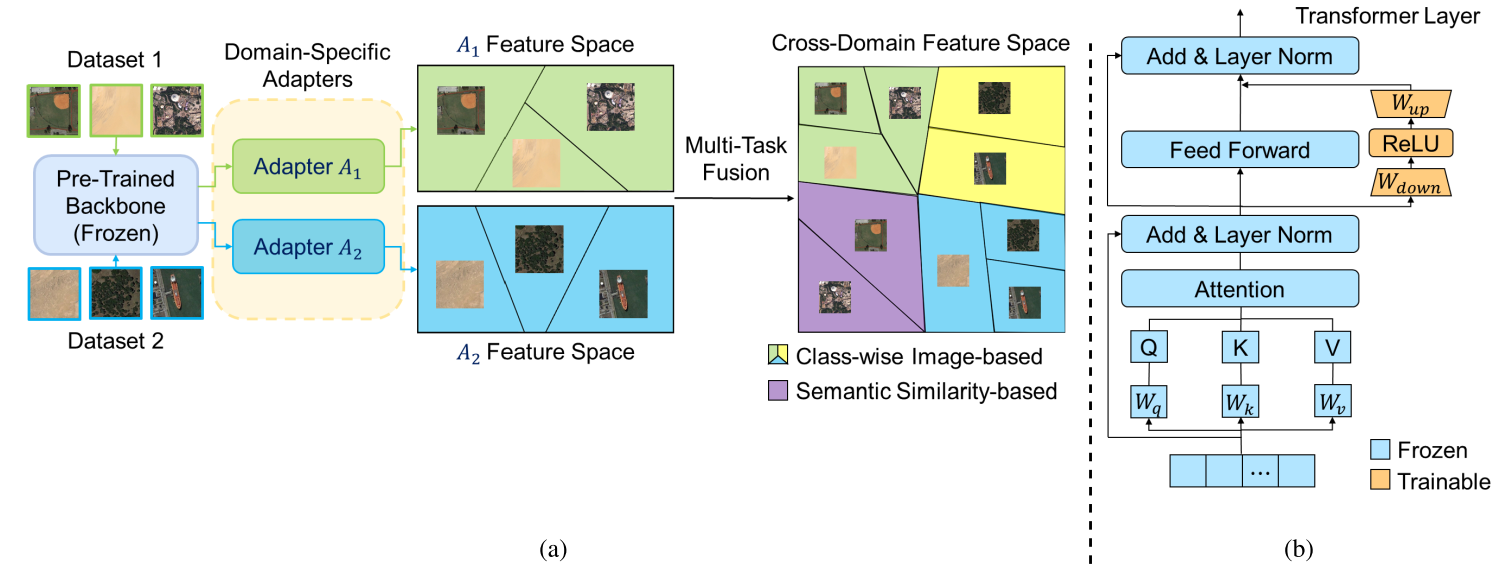
本文采用在 ImageNet-21K 上预训练的 ViT 作为特征主干网络 fθ(·),该主干在整个训练过程中保持冻结状态,以保留在大规模预训练期间获得的丰富的通用视觉表示。
在每个冻结的 Transformer 层之上,我们在 Transformer 层的前馈网络 (FFN) 旁边插入一个特定于域的适配器模块 Adapter,Ai,以使该模块适应不同任务。每个Adapter是一个瓶颈多层感知器(bottleneck-MLP),由下投影层W_down、非线性激活函数 σ 和上投影层 W_up组成。训练时,使用标准监督的交叉熵损失训练Adapter。
同时,模型将属于同一类的所有特征的平均值作为该类的分类原型P_Di_c_Ai。这些原型在跨不同领域的增量学习期间为所学习的类充当简练且稳定的类锚点,避免了因拟合新领域或新类中的实例而导致的潜在特征漂移。
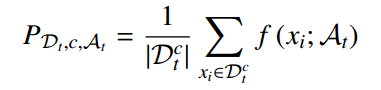
其中 f(xi ; At) 是通过将样本 xi 通过frozen-backbone和特定于域的Adapter :At 生成的特征表示。
第一个任务完成训练后,模型将按顺序继续执行下一个增量学习任务,同时不访问先前任务的数据。由于每个任务都会引入来自不同域的数据,且可能包含未见过的新的类别,所以CDIL 不仅涉及扩展标签空间,还需要适应域转移。
因此,模型为每个增量任务 Tt 引入一个单独的领域特定Adapter:A_t,同时冻结预训练的backbone,并保持先前学习的其他任务的Adapters固定不变。
在获得每个任务的类原型后,下一步是融合这些原型以进行最终分类。但是,将所有特定领域Adapter的输出直接融合进行分类时,由于存在跨任务和领域转移的共享类,模型存在干扰。为了实现跨领域和类别的图像识别而不存储任何过去任务的数据,本文构建了特定于领域的原型来对所有领域进行分类。
在推理时,未知域的测试图像通过所有特定于域的Adapter以生成域对齐特征。这些特征与各自域的原型相匹配,最终的预测是所有域中与域对齐特征具有最小余弦距离的原型的类别。因此,如果测试图像的特征分布与特定域密切相关,则其最终分类将由该域特征空间内最近的原型确定。介于这一点,本文使用两种策略构建跨越所有类和领域的原型,包括基于分类图像的原型构建和基于语义相似性的原型迁移。
①基于分类图像的原型构建
该原型直接根据特定任务域的图像计算,对于在T_t域出现的所有类别,通过该域的适配器At来计算原型P_Dt_c_At。
但是,由于通常存在一些新出现的类没有出现在以前的任务域中,因此需要在不访问特定于域的类数据的前提下,估计早期域的类原型。为了解决这个问题,假设这样一个结论:类原型在语义上是稳定不变的并且可以跨域转移。也就是说,虽然低级图像特征(例如颜色、分辨率和纹理)在域之间可能存在显着差异,但类的高级语义应在很大程度上保持不变。
这种假设使得模型能够通过重用从新领域中的观察到的新类别的图像特征,通过之前学习的适配器来投影它们,以此绕过对特定领域数据的访问需求,为这些新类构建特定于领域的原型:
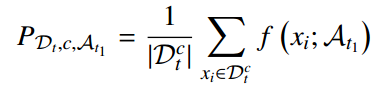
使用前一个任务的域适配器 A_t1从任务 T_t 的分类数据中编码特定于域的特征。
例如,在当前任务域T_t中出现了新类——船舶图像,但是前一个域中没有船舶图像,模型也可以通过前一个域的适配器 A_t1 投影来自当前域的船舶图像,以近似表示在前一个域的特征空间中的船舶类原型,这样,就可以在早期领域中嵌入新出现的类。
②基于语义相似性的原型构建
这个问题的定义与上述相反,上面是在当前域出现新类时,如何将新类的特征转移到前域的特征特征空间中;相反的情况是,如果船舶图像在前域中存在,但在当前域不存在,模型则无法通过当前域的数据构建船舶特征,由于无法访问前域的数据,也无法直接使用Adapter估计的方式。
因此,需要将重心转向当前任务 T_t 和先前任务 T_t1 都包含的重叠类 的语义相似性来构建原型。还是假设一个结论:如果两个类之间具有相似的关系,那么他们之间的特征就不依赖于数据域的变化。所以,通过使用余弦相似度计算所有只在前域中存在的类原型与所有两个域中重叠类的类原型之间的相似度,选择相似度较高的类原型进行使用Adapter的特征转移。
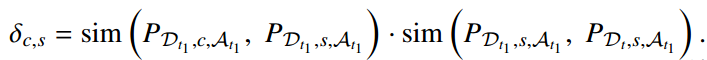
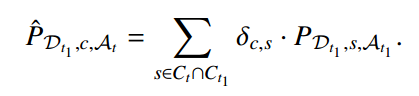
通过这种方式,就可以将只在前域中存在的类的语义结构投影到当前域Tt 上,从而允许在没有访问前域数据的情况下近似缺失的域和类原型。
通过结合上述两种机制,就构建了跨越所有先前见过的域和类的特定于域的原型,表示为原型矩阵 P:矩阵的每一行对应于一个域的原型,每列对应于每个类的原型。
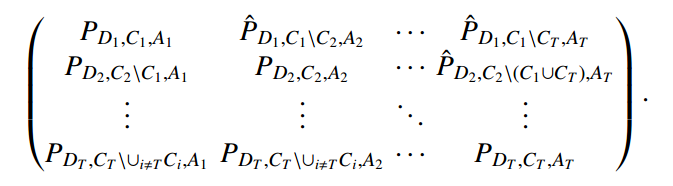
跨域对齐的对比损失:
如果没有明确的跨领域特征对齐,同一类的特征可能会产生显著差异,从而增加错误分类的风险。同时,来自不同类别的特征可能会变得纠缠在一起,因为模型在不参考旧类别的情况下学习新类别。这种失调不仅会降低当前任务的表现,还会加剧对过去知识的遗忘。
为了实现跨域和跨类的特征表示对齐,本文使用了跨域监督对比损失来规范训练过程,该损失结合了三个互补的组件:①“实例-实例(I2I)”对比损失;②“实例-原型(I2P)”的对比损失; ③“原型-原型(P2P)”对比损失。如图3所示。
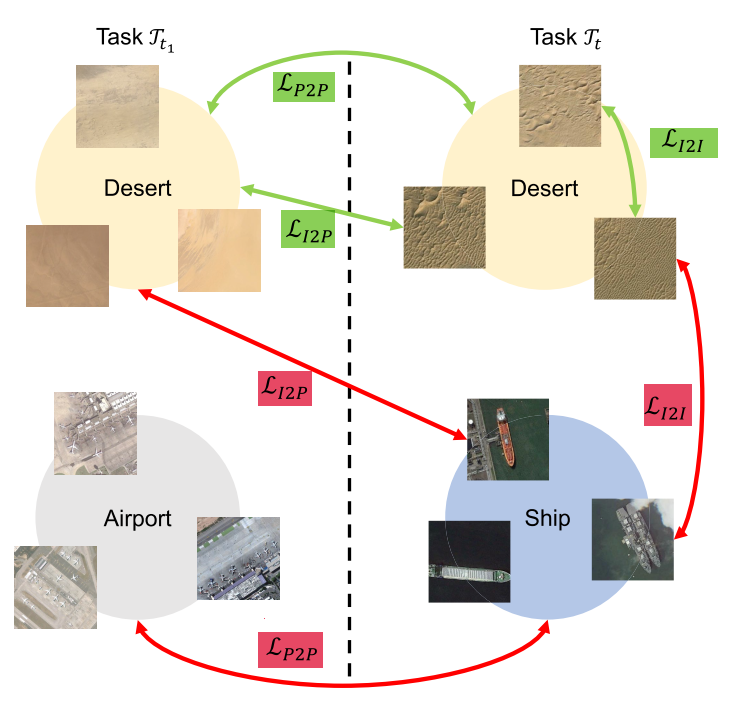
①“实例-实例”对比损失 LI2I;②“实例-原型”对比损失 LI2P;③“原型-原型”对比损失 LP2P。
①“实例-实例(I2I)”对比损失
L_I2I将单个任务中、相同类别的各个特征对齐,它鼓励同一类的特征在不同的领域中聚集在一起,而来自不同类的特征则被分开。
对于任务 Tt 的训练,先为输入batch构建增强数据,并使用所有可用的域Adapters提取特征。例如,在任务 Tt 中,每个图像及其增强数据被送到当前域适配器 At ,产生两个特征向量。
将 z_i 表示为实例 xi 从相依域适配器 At 获得的的特征,将 Z 表示为每个批次数据及其增强数据通过Adapter得到的特征集合。对于图像 xi ,我们将正集定义为 P = {z_i ∈ Z :y_ j = y_i} ,将负集定义为 N = {z_i ∈ Z :y_ j ≠ y_i} 。因此实例到实例的损失定义为:
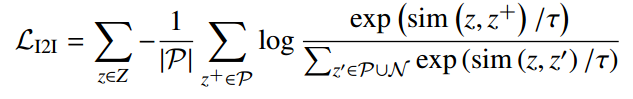
②“实例-原型(I2P)”的对比损失
L_I2P鼓励图像特征xi与先前学习的不同类别的原型分离,并将xi拉向不同领域的同一类别的原型。
对于训练任务 Tt 的图像特征 zi ,我们收集来自不同领域和不同类别的原型作为负样本 N ,并收集先前学习的领域中同一类别的原型作为正样本 P,基于原型的正样本和负样本。因此L_I2P定义为:
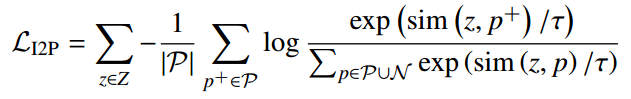
其中 p + 表示来自先前学习的领域的同一类的原型。L_I2P 有助于将新域的特征融入到现有的特征空间结构中,减少新类和旧类之间的混淆,并减轻灾难性遗忘。
③“原型-原型(P2P)”对比损失
L_P2P 确保旧任务和重复训练任务之间具有全局一致的原型表示。也就是说,来自不同类的任何一对原型(表示为负对 N )在特征空间中相互排斥,以实现明显区分,而跨域的重叠类原型(不同任务中均包含的类原型,表示为正对 P )被拉在一起。通过以这种方式对比所有类质心,L_P2P 鼓励跨领域的类嵌入空间进行良好分离。
具体实现中,类原型被表示为高斯分布,其中类质心作为平均值,协方差矩阵作为方差。在训练过程中使用指数移动平均值(EMA)来获得每个类的原型均值和协方差,每个原型都被建模为高斯分布。使用衰减率为 0.99 的 EMA 计算平均值和协方差,这可以稳定有限任务数据下的估计。同时, Kullback-Leibler (KL) 散度每批次计算一次。因此,对于之前对比损失中的相似函数 sim(·;·),L_P2P 改为采用负 KL 散度来考虑两个原型分布之间的不确定性,公式定义如下:
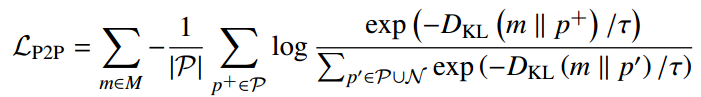
其中{M}表示当前任务的原型集合,p + 表示先前域中同一类的原型,DKL(·k·)表示两个原型分布之间的KL散度。该损失增强了类质心级别的一致性,补充了 L_I2I 和 L_I2P 强制执行的实例级别对齐。
综上,这三个loss通过将同一类的表示(即使来自不同的领域)放在一起,并分离不同类的表示,共同鼓励类一致、领域不变的特征。因此,总损失可以表示为:
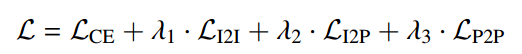
其中平衡项设置为 10.0、10.0 和 10.0。 L_CE 表示应用于当前任务的标准交叉熵损失。
Experiments
原文中作者做了大量有价值的对比实验和消融实验,篇幅较长且细节较多,建议直接阅读原文实验部分图文。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)