跨模态知识蒸馏:仅凭H&E染色图像,就能“读”出空间转录组定义的细胞生态位
论文信息
标题:Cross-Modal Knowledge Distillation from Spatial Transcriptomics to Histology
跨模态知识蒸馏:仅凭H&E染色图像,就能“读”出空间转录组定义的细胞生态位
一句话速览 魏茨曼科学研究所的研究团队提出了一种跨模态知识蒸馏方法,成功将空间转录组学揭示的、分子层面定义的细胞生态位结构,“迁移”到了仅使用H&E染色图像的分析模型中。这意味着,未来在临床实践中,仅凭一张常规病理切片,就可能推断出原本需要昂贵、稀缺的空间转录组技术才能获得的组织微环境精细图谱。
背景与痛点:当“高清卫星图”遇见“百万张普通照片”
想象一下,你正在研究一座城市的生态。你有两种地图:一种是极其昂贵、但信息量爆炸的“高清卫星热力图”,它能精确显示每个街区的温度、湿度、植被种类、甚至空气成分;另一种是随处可见、成本低廉的“普通航拍照片”,主要展示建筑形态、街道布局和颜色。
在生物医学领域,空间转录组学 就是那张“高清卫星热力图”。它不仅能告诉你每个细胞(相当于城市中的“建筑”)里成千上万个基因的表达水平(“内部状态”),还能精确记录细胞在组织中的空间位置。这使得科学家能够无监督地发现 “细胞生态位” —— 即由特定细胞类型组成、功能协同、在空间上连续的区域,如肿瘤核心区、免疫浸润带、正常基质区等。理解这些生态位对于解密癌症进展、免疫反应等至关重要。
然而,这张“高清图”的问题在于太贵、太稀缺。目前,空间转录组检测成本高昂,通常只能应用于少数研究样本的局部区域,难以大规模推广。
与此同时,H&E染色病理切片 则是那“百万张普通航拍照片”。它是临床诊断和研究的基石,全球医院存档数以亿计,获取容易且成本极低。它通过颜色(细胞核呈蓝色,细胞质呈粉色)展示细胞的形态学特征。近年来,基于自监督学习的病理基础模型(如UNIv2)已经能从这些图像中提取出非常丰富的形态学特征。
但核心痛点在于:形态学特征再丰富,也不等同于分子状态。 就像仅凭建筑外观(颜色、形状),很难准确推断其内部的温度、湿度或居民活动。许多关键的细胞生态位是由微妙的分子程序定义的,这些信息在H&E图像中可能是隐晦甚至缺失的。因此,仅基于形态学进行无监督聚类,得到的分区往往粗糙、充满噪声,无法与分子定义的、具有明确生物学意义的生态位对齐。

这就形成了一个尴尬的局面:我们拥有海量的普通照片(H&E),却渴望高清图(空间转录组)才能提供的深层生态洞察。如何用“普通照片”的钱,办“高清图”的事?
核心方法:让“高清图”当老师,“普通照片”当学生
魏茨曼团队提出的解决方案,灵感来源于教育中的“知识蒸馏”。他们设计了一个“师生”学习框架:
-
博学的“分子老师”(冻结):这位老师由空间转录组数据训练而成。具体来说,他们采用了一个名为 NOLAN 的自监督模型。NOLAN的聪明之处在于,它不仅看单个细胞的基因表达,还看细胞的“邻里关系”——以每个细胞为中心,在一定物理半径内的所有邻居细胞共同构成一个“社区”。NOLAN分析这些“分子社区”,无监督地学习并划分出具有空间连贯性的生态位。这个训练好的模型被“冻结”,作为知识权威,不再更新。
-
勤奋的“图像学生”(可训练):这位学生只接收H&E图像信息。对于每个细胞,从H&E切片上截取以该细胞为中心的小块图像,通过一个冻结的病理基础模型 UNIv2 提取形态学特征。同样地,学生也观察细胞的“图像社区”——由邻居细胞的形态学特征构成,并加入了与老师相同的位置编码来感知空间关系。
-
蒸馏的核心:学习“软标签”而非“硬答案”:训练的关键不是让学生死记硬背老师给出的最终生态位编号(硬标签),而是让学生学习老师思考问题的“逻辑”。具体来说,对于同一个细胞社区,老师(基于分子数据)会输出一个K维的“逻辑值向量”,经过温度参数软化后,形成一个概率分布,表示该社区属于各个生态位的“可能性”。例如,它可能以0.7的概率属于“免疫富集区”,0.2的概率属于“基质交界区”,0.1的概率属于其他。 学生的任务是,仅根据图像社区的特征,让自己的输出概率分布尽可能接近老师的分布。他们使用KL散度作为损失函数来最小化两者之间的差异。
这种方法的精妙之处在于:通过匹配概率分布,学生被迫去捕捉老师所理解的、生态位之间复杂的相似性与差异关系,而不仅仅是简单的分类边界。这相当于学生学会了老师那套基于分子上下文理解组织结构的“思维模式”。
最终,在推理阶段,只需运行训练好的“学生模型”。输入新的H&E图像和细胞位置,模型就能直接预测出每个细胞所属的、与分子定义对齐的生态位,完全不需要空间转录组数据。
实验结果:学生不仅“学得像”,甚至在某些方面“表现更佳”
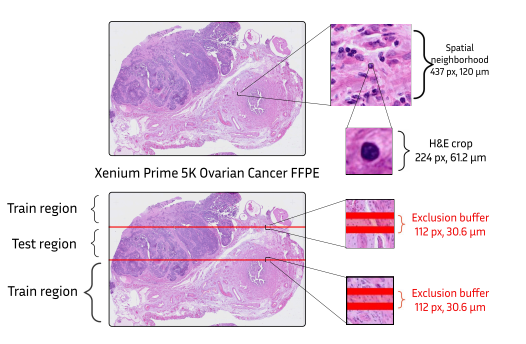
研究团队在16个公开的Xenium数据集上进行了全面评估,涵盖结肠癌、乳腺癌、卵巢癌、脑癌等12种不同组织类型。
1. 定量对比:与“老师”的共识度大幅领先 他们使用调整兰德指数(ARI)和标准化互信息(NMI)来衡量学生预测的生态位分区与老师(基于转录组)的分区有多一致。作为对照,设置了两个仅使用H&E特征的基线模型:一个是将NOLAN框架直接用在图像特征上(Histology-NOLAN),另一个是直接在图像特征上进行Leiden聚类(Histology-Leiden)。
结果令人印象深刻(见表1):在设定生态位数量K=10和20两种情况下,蒸馏学生模型与老师的一致性(ARI约0.5-0.62)显著高于两个基线模型(ARI约0.17-0.28)。这表明,蒸馏方法成功地将分子信息注入了图像模型,使其预测结果远超单纯的形态学分析。
2. 生物学验证:细胞类型组成高度吻合 分区标签一致,是否意味着生物学意义也一致?为此,他们分析了每个生态位内的细胞类型组成。使用公开的细胞类型注释,计算学生模型预测的生态位与老师定义的生态位在细胞类型分布上的Jensen-Shannon散度(JSD,值越低越相似)。
如表2所示,在卵巢癌、胰腺癌和乳腺癌数据上,学生模型预测的生态位,其细胞类型组成与老师的相似度最高(JSD最低),远优于基线模型。这证明学生不仅“形似”,而且“神似”,真正抓住了生态位的生物学本质。
3. 临床相关性:甚至能更好地对齐病理学家标注 更有趣的发现来自与金标准——病理学家手动标注的对比。在卵巢癌数据上,他们用SVM分类器来评估各模型预测的生态位,对病理标注的肿瘤亚区(Tumor 1, 2, 3)的区分能力。
结果(表3)显示,蒸馏学生模型预测的生态位,在区分这些临床相关区域时,其宏观F1分数甚至超过了作为老师的转录组模型本身。这表明,学生模型在吸收老师分子智慧的同时,可能还强化或纯化了其中与形态学最相关、最贴合病理视觉诊断的那部分信息,从而产生了对临床注释更具判别力的表示。
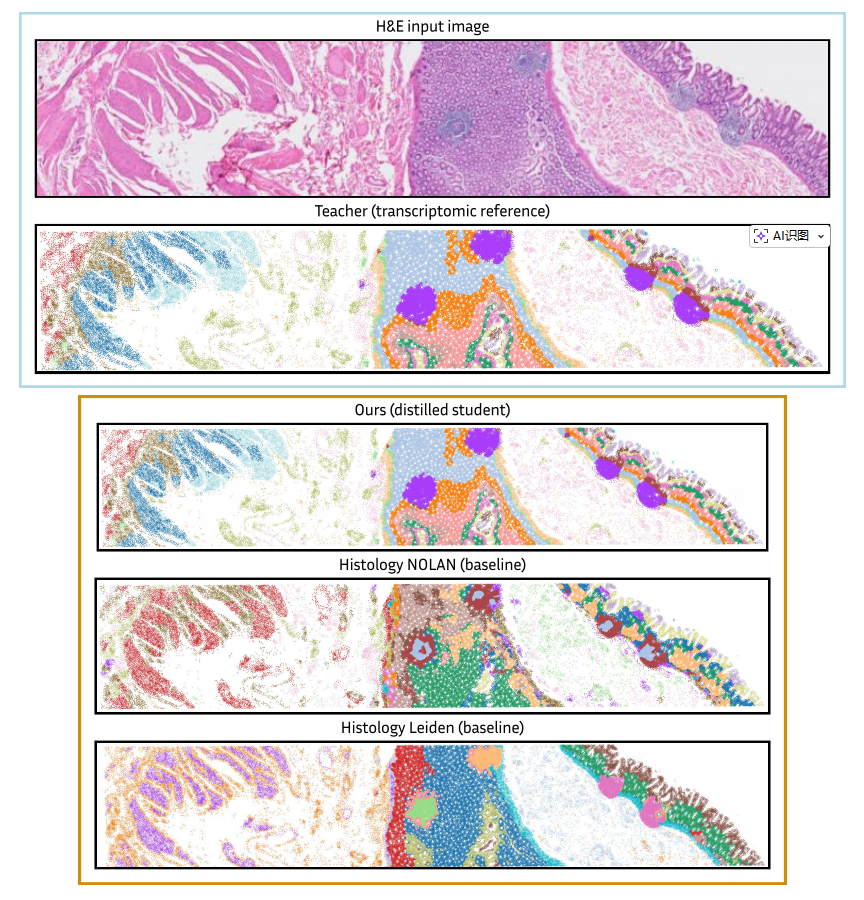
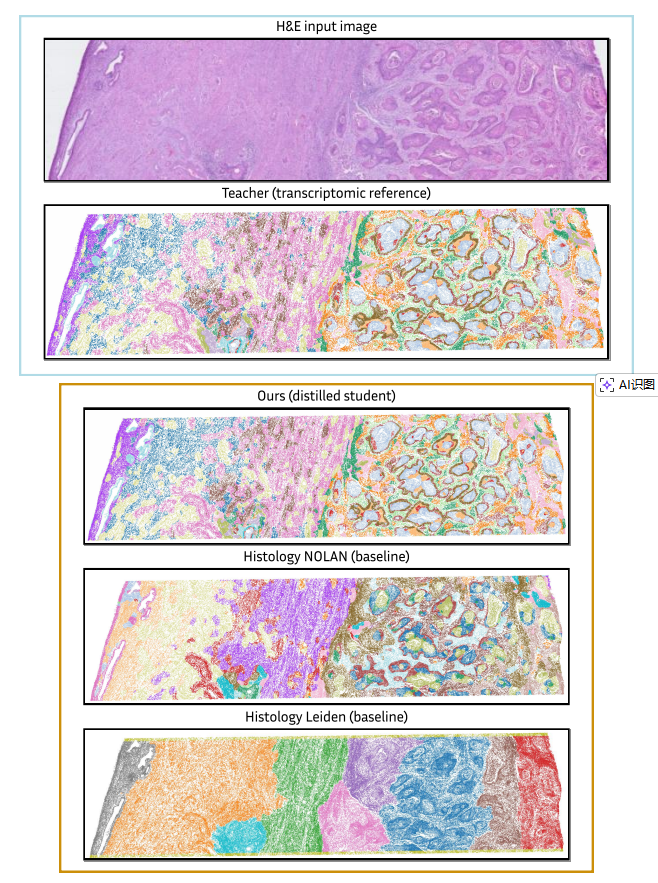
4. 定性可视化:精细结构的完美复现 从图3(健康结肠)和图4(宫颈癌)的对比可以直观看到,学生模型(Ours)几乎完美地复现了老师模型揭示的精细空间结构:如结肠中的B细胞滤泡(紫色斑块)、上皮分区(绿色/蓝色分层)、宫颈癌中的侵袭性癌巢边界等。而两个基线模型的结果则要么噪声很大(Histology-NOLAN),要么过于粗糙、丢失细节(Histology-Leiden)。这生动地展示了跨模态蒸馏带来的质的飞跃。
意义与展望:推开一扇通往“可扩展空间生物学”的大门
这项工作为计算病理学和空间生物学领域开辟了一条富有前景的新路径。
核心意义在于“桥梁”的搭建:它巧妙地将稀缺但信息丰富的空间转录组数据,与海量但信息较粗的H&E数据连接起来。一旦在某种组织类型上通过配对数据建立了这座“桥梁”(即训练好学生模型),该模型就可以应用于该组织数以万计的历史或新增H&E切片,以极低的成本批量生成“伪空间转录组”生态位图谱。这极大地扩展了空间生物学发现的规模。
潜在应用场景广泛:
-
生物标志物发现:在大规模H&E队列中,快速识别与预后、治疗反应相关的特定生态位结构。
-
药物研发:评估药物对肿瘤微环境的空间重塑效果,无需对每个样本进行昂贵的多组学检测。
-
临床决策支持:为病理医生提供超越形态的、定量化的微环境分析报告,辅助更精准的诊断和分型。
-
历史档案挖掘:对医院储存的数十年历史切片进行回溯性研究,探索疾病生态位演变的长期规律。
局限性
该方法目前最主要的限制在于其“启动成本”:要针对一种新的组织类型应用该方法,必须首先获得该组织的配对空间转录组和H&E数据来训练蒸馏模型。虽然一旦模型训练完成即可无限扩展,但获取这组初始的配对数据仍然是必要的前提。此外,模型性能上限受限于“老师”NOLAN从转录组数据中发掘生态位的能力,以及“学生”所依赖的病理基础模型(如UNIv2)提取形态学特征的质量。
这项研究展示了一种优雅的解决方案,通过知识蒸馏弥合了不同数据模态间的鸿沟。它让我们看到,人工智能不仅能在单一模态内挖掘规律,更能成为在不同模态间翻译和传递知识的“使者”。随着配对的多模态数据日益增多,这种跨模态学习范式有望彻底改变我们利用现有临床资源进行深度生物学研究的方式。一个随之而来的问题是:当这种技术成熟并普及后,基于H&E图像的生态位分析,是会作为空间转录组的“平替”融入常规病理流程,还是最终会揭示出一些仅凭形态与分子关联都无法独立发现的全新组织生物学原则?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)