大模型Agent面试50问(1-25)
原创 乔木mq
前几天看到大厂大神乔木发的AI面试题,自己也做了一遍。做完之后拿豆老师打分:超过75的就懒得动了,给各位道友安排一个原汁原味;不到70的就按豆老师的思路重新改一遍。有的问题一题多解,所以我按照我在数据仓库和CRM知识体系的解答,不一定满足大众口味。但学弟们学会了,面试过复试足够了。
1. 请推导 ReAct (Reasoning + Acting) 框架中,当 LLM 生成的 Action 执行失败(如 API 返回 Error)时,如何通过构造特定的 Observation Prompt 引导模型进行自我修正?请给出一个具体的 Prompt 模板及其背后的梯度更新逻辑假设。
-
知识点:ReAct的本质是,reasoning-》action-》observation;
-
判断API返回error的可能选项。存量(已有的error_type),拉取已有的skill;增量(未知的error_type),调用能调整observation prompt模板的skill;
-
增量,立足诊断-》定位-》修正-》重试,但这样有可能进入死循环,或者带来token浪费。修正的具体数学表达式是:i. 设N步trajectory, τ={S1,A1,T1,S2,A2,T2,……, St,At,Tt,……, SN,AN },τ~πθ,θ是参数。在第t步的奖励是Rt,则在πθ策略下、st的状态动作值函数Q(St,At)为:
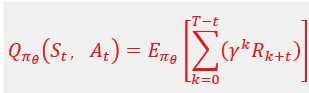
即按πθ分布对累计奖励求期望,工作目的就是J,是为了让Q(St,At)最大化,从而对参数θ进行梯度优化:
![]()
对于一个observation prompt如下,在第t步thought后,自动创建了如下prompt:
|
1、Observation:action failed; |
|
2、Error_type:123; |
|
3、Error_description:未能找到工具; |
|
4、基于第1、2、3行error的输出,分析问题的原因,并对Q(St,At)给与RM的惩罚; |
|
5、基于第4行的问题原因,选择新的action或者工具; |
|
6、不要再重复error的action; |
|
7、以上1至6步如果出现第5次,即判定为死循环,对Q(St,At)追加惩罚。 |
2. 在基于 LangChain 或 AutoGen 的多 Agent 协作系统中,如何从数学角度量化“通信开销”与“任务完成度”之间的 Trade-off?请设计一个损失函数 并解释各项含义。
- 知识点:LangChain是LLM推理模型,只干活;AutoGen是智能体互相聊天,所以问题的核心点是,让LangChain好好干活(让LLM会查资料,写代码),减少AutoGen(让多个智能体之间互相通信)聊天。
- L=R(任务完成度)-P(通信开销)-》 RLHF (根据用户上下文判断用户是否对此满意,最简单的就是pros & cons)+ SSRL(根据系统的历史上下文的近似,批量计算系统的满意程度)- α (输出的token数)-β(时长)-γ(系统自身的模型action失败次数)-δ(上下文rot)
- 或者,L=Ltask+λ*Lcommunication, Ltask=1-T, T=count(已完成任务数)/count(总任务数); Lcommunication=λ(α通信轮次+βtoken总数+γ智能体总数)/Cmax, Cmax:最大允许通信开销数
3. 针对 Long-Context Agent,请分析 Ring Attention 机制在处理超过显存容量的历史对话记忆时,其 KV Cache 的分块加载与注意力计算的具体流程,并计算其相对于标准 Attention 的通信复杂度变化。
- 知识点:Ring Attention 通过将 KV Cache 分块、多卡环形传递、逐块计算注意力,把显存占用从平方级O(L2d)降到线性级O(L/N*d),通信复杂度从O(1)仅上升为 O (Ld),让 Long-Context Agent 能记住超过单卡显存上限的无限长历史对话;
- Ring attention,第一、切上下文;第二、切Q;第三、每个节点的Q和滚动过来的每个kv算一次attention;第四、组装q。
4. 请推导 Function Calling 过程中,LLM 输出 JSON 格式参数的概率分布 ,并解释为何在微调阶段需要引入 Syntax Constraint Loss 来减少格式错误?
- 知识点:LLM在function calling的时候,生成式输出了JSON格式的sequence,由于是语法优先的,所以经常漏括号,造成语法错误;
- LLM是条件概率,如果一个完整的json串有N个字符串,则第n个括号要靠前n-1个token的概率乘机来表示,概率衰减越来越低,联合概率分布越大,才能保证json格式正确;但是,LLM的工作只是上上下文的概率似然最大,即:L = −E[logP(yi∣上文)],只能做到让每个字符串貌似输出,而不能完全做到格式正确;
- 对于sft,就是通过写入函数,人为调整一些token类的概率输出,对于这个场景,应该是可以的但不能杜绝的;所以,在RM里引入一个Lsyntax奖惩机制(如果出现语法错误,Lsyntax-1,否则+1)帮助sft能够更好地学习语法的严谨性;Ltotal=LSFT+λ⋅Lsyntax;λ是学习系数,建议先小后大;
- 根本的方法,就是形成一个text2sql,严谨地用函数生成json,而不是用LLM生成;这个考题,不一定要走常规路。
5. 在 Tool Learning 场景下,对比 Fine-tuning (如 Gorilla) 与 In-context Learning (ICL) 在泛化到未见过的 API 时的表现差异,并从 Fisher 信息矩阵的角度解释为何 ICL 更容易发生灾难性遗忘或幻觉。
1. Fisher信息矩阵,
![]()
是基于X样本对参数θ进行微调时的、“信息量”的平均大小。FIM越大,说明这个流形(一种抽象意义的几何曲面)下的梯度的二阶方差变大了。所以沿着这个方向的微调,要慎重不要步长太大;而反之,就可以大胆地进行调整。
2. 相比之下ICL没有了fisher矩阵的约束,也不改变参数,而是通过prompt的上下文改变,将输出分布强行推到模型未知的概率分布的特定区域,这些区域如果FIM其实支撑点极低,使得模型在一个低期望的区间输出,就会产生幻觉。
3. Gorilla是美国加大伯克利和微软联合研发的基于FT的专注tool learning的大模型,学会了各种hugging face和个hub的许多API。好处是靠谱,缺点是泛化较低学习成本高,所以有时候和ICL一起使用。
4. Fisher信息矩阵可以看成是KL散度在θ附近的一种二阶近似,即
![]()
KL散度,如同距离,是两个分布之间的总的偏差,恒为非负数;FIM,是两个分布差的动态速度的方差。
6. 请详细分析 Reflexion 算法中,自我反思信号 (Reflection Signal) 是如何作为 Reward 嵌入到后续轨迹生成中的?请写出其价值函数 的更新公式。
设一个![]() 第t步的奖励是rt,价值函数为V(St);
第t步的奖励是rt,价值函数为V(St);
1. MC方法,设总步骤是T,衰减因子为γ,则
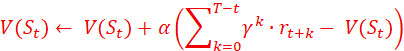
即:仅跟当前状态到总步骤结束的总奖励有关;
- 2. TD差分,则
![]()
即:要与下一步状态的价值函数和奖励挂钩,显然,MC收敛慢,不会死循环;TD收敛快,要避免死循环
7. 针对多步推理任务,Tree of Thoughts (ToT) 相比于 Chain of Thoughts (CoT) 在搜索空间爆炸问题上的解决方案是什么?请设计一种基于蒙特卡洛树搜索 (MCTS) 的剪枝策略,并给出其启发式函数 的定义。
1. 知识点:ToT,基于思维树的搜索,特别适用于“总在做选择题”的场景,比如问医、做题。缺点是搜索空间爆炸,如果超过4个branch的ToT,就有可能达到10000次以上的分叉。所以通常的措施就是pruning(剪枝)+搜索结构化推理+回溯;
2. pruning,在思维树的推理阶段中,综合打分过低的branch,将被故意地忽略;
3. 结构化,把树状搜索空间,分成一段一段的结构化区域,在推理阶段随机按照思维树的方向,对每个区域的多个分支做整体评分,即探索;整体价值最高的,被利用;
4. 回溯backtracking,比如只要经过1步搜索而奖励函数达不到阈值的,就退回原地;
5. MCTS启发函数举例:
其中α、β和γ是归一化系数。
8. 在 Agent 规划 (Planning) 阶段,如何处理环境状态的 Partial Observability (部分可观测性)?请结合 POMDP (Partially Observable Markov Decision Process) 模型,描述 Belief State 的更新机制。
1、知识点:Partial observability,是指交互对话、机器人学习等场景下,agent对于环境是无法预测的,必须通过贝叶斯公式,先验概率和观测似然相乘,再进行归一化处理,从而得到新的信念状态的后验概率分布。
2、设第t个状态的时候,信念状态分布b(St)t=【bs1, t, bs2, t】,执行了at之后,ot为第t轮的观测结果,则已知T(St+1|St,at)的前提下,得到下一步(预测步)的先验信念:
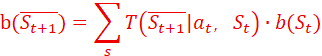
根据贝叶斯公式:后验信念
![]()
从而获得第t+1步的信念状态分布为bt+1=【bs1, t+1, bs2, t+1】。
3、或者另一种工程表述为:
- 选择并执行一个动作a ;
- 环境根据真实状态 s (Agent 不知道)和动作 a ,建立转移到新状态s'的概率模型P(s' | s,a) ;
- 根据新状态 s' 和动作 a ,环境产生一个观测 o (例如传感器读数,或者直播弹幕);
- Agent 接收到观测 o ;Agent 用贝叶斯规则计算一个信念值b(s'),这个信念值和历史的信念值都有关,是考虑了历史价值的后验概率输出,所以尽量避免让人觉得agent前言不搭后语、或者神经错乱;
- 根据b(s'),再去决定下一步怎么做,即a'。
9. 请推导 DPO (Direct Preference Optimization) 在优化 Agent 行为轨迹时的目标函数,并解释其如何避免 PPO 中训练 Value Model 带来的显存开销和不稳定性?
知识点:DPO直接基于集合{x,yw,yl}进行策略优化,X是prompt /state/ 上下文,而yw是胜者输出;yl是败者输出。比PPO省去了价值函数和critic,更简单,端到端。
- DPO的目标函数为
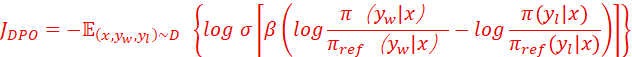
2. PPO里面有actor和critic,都是大模型,还要计算优势函数Ast,以及clip剪裁参数α和KL散度调整参数β,超参越多泛化能力越差。相比之下,DPO大模型少,显存开销少,超参少,稳定性相对高。
10. 当 Agent 调用外部工具导致长延迟时,异步执行架构 (Async Execution) 如何设计状态机以管理并发请求?请画出状态流转图并说明如何处理竞态条件 (Race Condition)。
1)Async Execution:开启一个线程,异步调用外部工具,对从启动到成功返回的时间计数;状态机的流程为:初始状态为idle,如果是,则具备了调用外部工具的条件;状态设置为pending,随时准备调用外部工具;调用中,会返回running、success、failed、timeout;如果临时取消状态,会返回cancelled;成功或者cancelled,把状态重置为idle;
2)race condtion是发生了抢工具接口的情况,要进行分布式锁的设定。
11. 在 RAG (Retrieval-Augmented Generation) 驱动的 Agent 中,如何解决检索内容与生成内容之间的“忠实度” (Faithfulness) 问题?请提出一种基于 NLI (Natural Language Inference) 的实时校验算法。
知识点:基于NLI,通常把LLM计划输出的sequence判定为entailment,neutral和contradiction;算法流程如下:
- 对一个prompt,进行检索输出,形成RAG输出序列R={r1,r2,…,rn}
- 与2同步地、对prompt调用LLM,形成LLM输出序列G={g1,g2,..., gm};
- 对G进行句子切分,去掉冗余文字和格式,再形成序列Gi={gi1,gi2,…,git}
- 遍历Gi,逐句地与R进行相似性比对(内积、或者归类、或者其他逻辑关系确认),根据阈值,判断Gi序列的每个输出是entailment, neutral, 还是contradction;
- 基于R的标准,如果是Gi里属于contradiction的句子,不输出。
12. 请分析 Memory Bank 机制中,向量数据库检索的 Top-K 结果如何影响 LLM 的注意力分布?若 值过大,是否会引发“迷失在中间” (Lost in the Middle) 现象?请给出理论解释。
知识点:memory bank是LLM的一个外挂记忆,在进行attention的时候,当遇到long context时,由于attention的机制总是每次与序列最先和最末尾的向量,有更高的注意力,所以如果外挂的排序恰好在中间且K过大时,就会被遗忘,即所谓的lost in the middle。
13. 针对代码生成 Agent,如何设计一种静态分析与动态执行相结合的反馈回路,以在编译错误发生前预测潜在的 Runtime Error?
1、知识点:runtime error有多种表现形式,比如死循环、除数为0、死锁、空指针,等等;
2、静态分析一是利用AST,对代码的语法进行分段特征分析,识别出各种syntax报错信息;二是利用知识库,把常见的代码执行逻辑问题,查出来;以上报错信息合计的累计相似度如果小于阈值,则进行沙箱测试;否则,直接报错;
3、报错的信息再动态地反馈给知识库,描述清楚后再增加该问题点的置信参数;以此类推。
14. 请推导 Multi-Agent Debate 机制中,共识达成过程的收敛性条件。若各 Agent 初始观点差异过大,如何通过调整 Temperature 参数或引入 Moderator Agent 来避免死锁?
1、知识点,关键是对各agent输出观点的概率分布,用带温度T值的softmax函数映射到(0~1);
2、设有n个agent,每个agent在第t轮输出的观点为xt,可以是概率分布、sequence或者策略的embedding,则第t+1轮,第i个agent的观点的修正值为:
![]() ,
,
W矩阵 是xt,和xj两个向量做内积再进行归一化的结果
![]()
在对![]() 进行差异化对比的时候,考虑将引入概率分布
进行差异化对比的时候,考虑将引入概率分布
![]() ,
,
其中T是一个正值,这样当T升高的时候,分布变得较为均衡,大家的好意见都会被采纳一些;再通过温度的降低annealing,把最好的意见抽提出来。如果开始温度T就太低,就会出现各方分歧明显,永远达不到收敛条件,死锁。
3、Moderate Agent就是对在所有的xi里,找到一个平均![]() ,然后强制所有的xi+1向
,然后强制所有的xi+1向![]() 靠拢,形成了一种一定会收敛的凸平均集合。
靠拢,形成了一种一定会收敛的凸平均集合。
15. 在 Web Navigation 任务中,DOM Tree 的结构化表示如何转化为 LLM 可理解的 Token 序列?请分析 HTML 标签截断策略对元素定位精度的影响。
1、DOM tree是document object model,是browser把html解析成一种结构化的树状格式,让JS具体对各种对象进行增删改查。DOM tree的结构化表示,是根据depth first search的原则,即每个层级走到最深后再走另一个层级,把html里的结构延展成包含了id、对象、class、交互等所有前端元素的一个序列,供LLM理解;
2、DOM tree必须被压缩成一个sequence,里面包含了html的然后喂给LLM。这个sequence可能非常之长,所以如果采用HTML标签截断策略,必然导致某些深度层级元素、或者某个分支元素的丢失,从而影响了元素定位的精度。
16. 请解释 GitRepl 或类似代码操作 Agent 中,如何利用 Diff 序列作为 Action Space 来最小化 Token 消耗并提高修改的原子性?
1、知识点:Diff序列,就是返回两组sequence的不同点,并且用标准的格式表示出来;
2、由于只返回了Diff序列,所以代码调优方面肯定比整个序列少很多,减少token;而由于返回的格式是标准化的,非黑即白不存在中间状态,所以是原子性的。
17. 针对具身智能 (Embodied AI) Agent,如何将视觉观察 (Pixel) 与语言指令 (Instruction) 在潜在空间 (Latent Space) 中对齐?请描述 VLA (Vision-Language-Action) 模型的架构细节。
1、知识点:alignment,在隐空间对齐,就是把每个表达像素的Zv(dv维度)加上位置编码或其他特征编码后,映射到高维d2;同时把表达语言指令的Zt(dt维度)的向量,加上位置编码或其他特征编码后,也映射到高维d2,从而,使得新的Zv和Zt,属于同一个维度为d2的latent space。即VLA模型的特征提取,位置解码部分;
2、新的latent space满足,Z=concat(Zv,Zt),是分别映射到高维d2空间的Zv集合和Zt集合的并集;
3、由于新的Zv和Zt的维度是相同的,就可以通过cross-attention,让彼此互相关注;
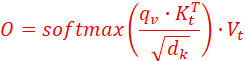
4、cross-attention高的Zv和Zt,就容易被同时被输出出来,融合后的特征还需要通过动作头(Action Head)解码,才能输出最终的动作序列导致正确的action,这就是VLA。
18. 请分析 Agent 在长期运行中产生的 Context Window 溢出问题,对比 Summary-based Compression 与 Vector-based Retrieval 两种策略在信息保留率与推理延迟上的具体差异。
1、知识点,summary-based compression是摘要总结性的压缩,即把一大段context压缩成一小段摘要(摘要的原文可以存在文件中,用skills去召回),所以如果没有召回就会有细节丢失;vector-based retrieval就是把所有的上下文embedding到向量数据库,再通过向量检索的方式召回。显然,信息保留率上后者好;推理延迟上前者快速。
2、实际应用时,可以考虑混合使用,或者与文件系统一起组合使用。
19. 在 Tool Use 微调数据构造中,如何合成高质量的负样本 (Negative Examples) 以增强模型对无效工具调用的识别能力?请描述一种基于对抗生成的数据增强方案。
1、知识点:negative examples,就是教会agent,哪些工具使用的trajectory,是错误的。
2、考虑这样一个格式
Tool name:abc;
Api secret:ps1234567;
参数:x、y、z;
返回:α,β;
所以,可以按照这个schema,分别故意除去其中的赋值或者参数、随意改变流程、非法权限、非法的64位解码,等等,并对每个负样本标记报错类型;
3、对抗生成的负样本,就是利用代码,在一个正样本的格式基础下按照结构化的报错类型,随机生成负样本prompt;先用schema检查一下,保证具有报错能力;再用沙箱测试一下,保证不能运行;最后喂给大模型去测试,如果判断为有用,就保留;否则,就是低效样本,丢弃。
20. 请推导 GraphRAG 中,知识图谱的子图提取算法如何优化检索路径,以减少 LLM 处理无关实体时的注意力噪声?
1、知识点:GraphRAG是利用图数据库来进行检索增强,
2、设G(V,E)是图数据库的知识图谱,V是vertex,顶点即对象;E是edge,边即逻辑关系。则目标是:构造 最优子图 G∗⊆G,满足:
![]() s.t.Acc(Q∣G∗)≈Acc(Q∣G)
s.t.Acc(Q∣G∗)≈Acc(Q∣G)
3、最初级的一个办法是在检索开始时,对于检索到的N个路径,都与问题计算相似度,即价值函数,将最高相似度的m(m<N)保留,而把剩余的路径剪枝。剪枝的方式,可以减掉顶点、顶点及以下、边、边及以下,等等。这样就可以达到减少噪声的目的。
21. 针对隐私敏感场景,如何在本地部署的轻量级 Agent 中实现差分隐私 (Differential Privacy),同时保证工具调用的准确性?请给出噪声添加的数学公式。
1、知识点:differential privacy用于对query或者训练样本的隐私保护,使得无法逆向获得原始的全部信息。
2、![]() +Laplace(参数),Laplace函数是一个好选择,为什么是Laplace函数?这是因为:
+Laplace(参数),Laplace函数是一个好选择,为什么是Laplace函数?这是因为:
1)需求是要让从非脱敏观测集合D里观测到o1的概率p(o1|D),与从DF观测集合D’里观测到o的概率p(o1|D’),要非常接近,具体地说,要让:
![]() ,
,![]() 同时满足;
同时满足;
2)要让o2、o3,……一系列观测都要非常接近;具体地说,要让:
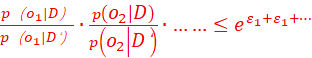 ,
,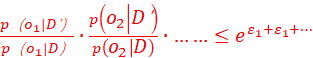 这两个关系同时满足。且从而把不确定性的乘积级别的的放大,压缩成可以控制的指数幂乘积的关系
这两个关系同时满足。且从而把不确定性的乘积级别的的放大,压缩成可以控制的指数幂乘积的关系
3)满足1),2)的噪声添加函数里,Laplace函数是一个中间很尖两头快速下落的函数,刚好与噪声添加函数的需求图像很接近。
4)实际使用时如果ε取很小的值,比如0.1,10次调用后总偏差也就2.7,属于极强的保护;取1,则两次调用后不到6,属于标准保护。
22. 请分析 SWE-agent 中,交互式 Shell 的状态保持机制,以及如何通过正则表达式解析器从非结构化的 Terminal 输出中提取结构化状态?
1、SWE-agent 的交互式 Shell 状态保持,核心就是:用长连接维持 Shell 会话上下文,用沙箱保证环境隔离与状态可恢复;用文件快照能够持久化此前状态的记录;用PTY伪终端把bash的进程、目录/path,环境变量等保持住;报错日志.
2、接收Terminal输出的纯文本;利用正则表达式提取结构,转化为结构化数据;结构化数据转化为json格式;json扁平化成sequence;sequence向量化。
23. 在多模态 Agent 中,当输入包含图像和文本时,Cross-Attention 层如何动态调整对视觉 Token 和文本 Token 的权重?请给出权重计算公式。
1、知识点:可以把文本的查询矩阵Qt想象成来自decoder,而把视频的Kv,Vv矩阵想象成来自于encoder;
2、如有Qt∈RLt×dk![]() , Kv∈RLv×dk
, Kv∈RLv×dk![]() , Vv∈RLv×dk
, Vv∈RLv×dk![]() ,则Cross-attention输出矩阵:Ov=A·Vv,A是权重矩阵,满足
,则Cross-attention输出矩阵:Ov=A·Vv,A是权重矩阵,满足
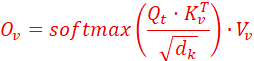
24. 请设计一种基于 Uncertainty Estimation (不确定性估计) 的机制,使 Agent 在置信度低于阈值时主动寻求人类帮助 (Human-in-the-loop),并写出置信度分数的计算逻辑。
1、Uncertainty estimation,是LLM当泛化到真实场景时,agent对自己是否在“低效输出”甚至“幻觉”的一种自检模式;human-in-the-loop,是当置信度低于阈值时,中断输出并向人类发出请求,从而自动输出一系列人类预先编辑好的提示,或者,启动一个interview过程,等待人类用户对agent给与更明确的解释;
2、最简单、最快捷的方式,是MC dropout;即不改变θ,而是在每一个layer、每一次FFN时时,随机地掩码屏蔽掉一些神经元,让大模型扰动起来,破坏了原有的sequence输出惯性,设一个问题x,有随机输出Y={y1,y2,…,yn},则置信度的计算为:
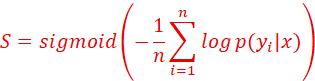
S越大,说明模型越可靠。MC dropout的工作就是让的优点就是预测幻觉的精度高,缺点就是每个layer都要做掩码矩阵计算,耗时是其他方法的3-10倍以上。更快、精确度低的方式,有自洽升温采样法,SC temperature;有信息熵法。
3、MC dropout的优点就是预测幻觉的精度高,缺点就是每个layer都要做掩码矩阵计算,耗时是其他方法的3-10倍以上。更快、精确度低的方式,有自洽升温采样法,SC temperature。
25. 针对复杂任务分解,对比 Least-to-Most Prompting 与 Plan-and-Solve Prompting 在错误传播 (Error Propagation) 方面的差异,并给出一种回溯修正 (Backtracking) 算法。
1、Least-to-Most Prompting,由简致繁的sequence序列,Plan-and-Solve Prompting,计划和执行sequence序列。二者都属于context engineering的范畴;
2、Least-to-Most,在error propagation上一步错步步错,适用于单向树状推理的复杂任务场景,错了就没有回头路;Plan-and-Solve,有可能Plan就是个错误的Plan,所以全局错了,局部也不可能solve。建议与pruning和backing混合使用。
基于Least-to-Most prompting的回溯修正算法如下:设N步LtM(trajectory)τ={Q1,A1,Q2,A2,…, Qk,Ak,…, QN,AN },τ~πθ,而πθ是策略分布函数;则Ak对应的价值函数Q 满足
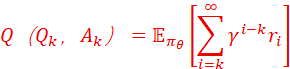
ri的取值来自于RLHF时,RM的自动计算输出,训练的依据是HF对trajectory的人工排序和标记;
置信度![]()
如果Sk<阈值,则回退到第k-1步,同时剪枝掉Qk,Ak,Qk+1,Ak+1,…, QN,AN;
在第k-1步,重新生成新的Qk,Ak,Qk+1,Ak+1,…。
(未完待续)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)