llama.cpp部署Gemma4-26B,并给Claude使用的经验
我使用GLM的Coding套餐,经常还是把额度用满。在这个暴躁的AI时代,没有模型可用,感觉空空的,是不是得了大模型病。所以想部署一个本地大模型给自己用。
Gemma4最近出来,我也用Ollama跑起来了,感觉效率还没有发挥到极致。所以想通过llama.cpp部署Gemma4-26B,网上说在12G显卡上能跑Q4量化版本。
结论
llama.cpp跑Gemma4-26B Q4版本能跑,GPU能发挥100%,这点比Ollama要强。但是连接Claude Code有点问题,会导致Claude持续分配内存,直到把所有内存都占用完。
环境及前置条件
我用的Windows11,显卡是RTX5070 TI 12GB显存,笔记本电脑。
配置好CUDA,安装Anaconda等。可以参考之前的文章。
安装llama.cpp
llama.cpp的安装方式很多,我这里选择最简单的,直接安装预编译好的版本。
- 到llama.cpp的官方github下载windows的安装包, https://github.com/ggml-org/llama.cpp/releases ,我用的是
llama-b8833-bin-win-cuda-13.1-x64.zip。另外一个CUDA 13.1 DLLs可以不用管,他是运行时库文件包,给愿意折腾的人用的。 - 将
llama-b8833-bin-win-cuda-13.1-x64.zip解压到D:\llama - 将
D:\llama加入到Windows环境变量 - 在命令行窗口测试一下:随便找个目录测试一下
llama-cli.exe,如果显示了error: --model is required(如下图),就说明设置正常。
图:选择预编译包
图:测试llama.cpp
准备大模型文件
准备执行的是Gemma4-26B模型,它有很多量化版本。这里也用一个比较省事、但不一定省心的方案。
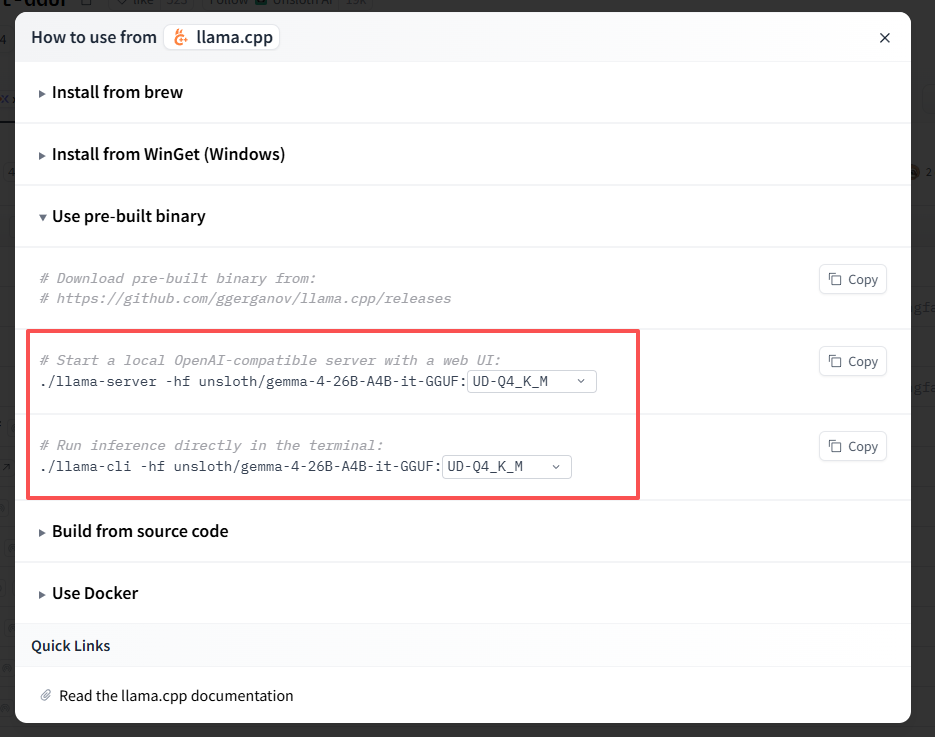
在huggingface的网站找到Gemma4-26B的模型,地址是: https://hf-mirror.com/unsloth/gemma-4-26B-A4B-it-GGUF/tree/main 。
在右上角有个按钮Use this model,点击llama.cpp,出现下面的窗口,可以复制你要的命令,我复制的是./llama-server -hf unsloth/gemma-4-26B-A4B-it-GGUF:UD-Q4_K_M。
特别注意: 这行命令会把模型下载到 C盘。这不是我想要的。所以一定要改地址:llama-cli -hf 下载的模型缓存位置优先由 LLAMA_CACHE 环境变量控制。如果没有设置 LLAMA_CACHE,则会继续检查 Hugging Face 相关缓存变量,例如 HF_HUB_CACHE、HUGGINGFACE_HUB_CACHE 和 HF_HOME。
下载模型失败解决方案
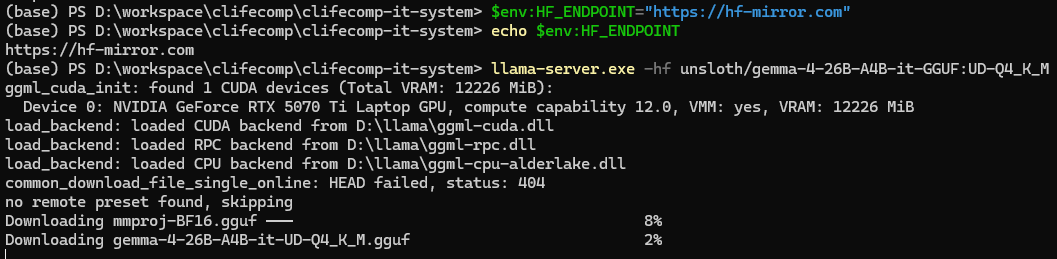
我执行上面的命令,会出现下面的错误,根本原因是无法直接访问huggingface的网站。而我之前是通过hf-mirror.com访问。
get_repo_commit: error: HTTPLIB failed: Could not establish connection
get_repo_files: failed to resolve commit for unsloth/gemma-4-26B-A4B-it-GGUF
error: failed to download model from Hugging Face
解决方案:$env:HF_ENDPOINT="https://hf-mirror.com",设置环境变量,然后就可以下载了。
调整启动命令
之前的llama-server 命令是hf给的,是默认的。这次为了能跟Claude Code对接,我将参数调整一下,重点是端口、上下文大小:ctx大小为128k
llama-server -hf unsloth/gemma-4-26B-A4B-it-GGUF:UD-Q4_K_M --host 0.0.0.0 --port 17691 --ctx-size 131072 --temp 1.0 --top-p 0.95 --top-k 64 --repeat-penalty 1.0 -ctk q8_0 -ctv q8_0 --flash-attn on --batch-size 1024 --ubatch-size 512 --threads 10 --threads-batch 12 --no-mmap --mlock --parallel 1 --no-warmup --jinja
我用E4B模型的启动命令,默认是带视觉识别:
llama-server -hf unsloth/gemma-4-E4B-it-GGUF:Q8_0 --host 0.0.0.0 --port 17691 --ctx-size 131072 --temp 1.0 --top-p 0.95 --top-k 64 --repeat-penalty 1.0 -ctk q8_0 -ctv q8_0 --flash-attn on --batch-size 1024 --ubatch-size 512 --threads 10 --threads-batch 12 --no-mmap --mlock --parallel 1 --no-warmup --jinja
为了追求最高的性能,可以将视觉去掉,只支持文本。关键是通过-m gguf的地址 指定模型文件,具体的地址可以在LLAMA_CACHE 找到。启动命令是:
llama-server -m E:\hgcache\models--unsloth--gemma-4-E4B-it-GGUF\snapshots\ce152932ac27bc40bc9c727386760424d50bb456\gemma-4-E4B-it-Q8_0.gguf --host 0.0.0.0 --port 17691 --ctx-size 131072 --temp 1.0 --top-p 0.95 --top-k 64 --repeat-penalty 1.0 -ctk q8_0 -ctv q8_0 --flash-attn on --batch-size 1024 --ubatch-size 512 --threads 10 --threads-batch 12 --no-mmap --mlock --parallel 1 --no-warmup --jinja
Claude Code连接llama.cpp的大模型
建议使用 CCSwitch
设置如下,模型名称unsloth/gemma-4-E4B-it-GGUF:Q8_0: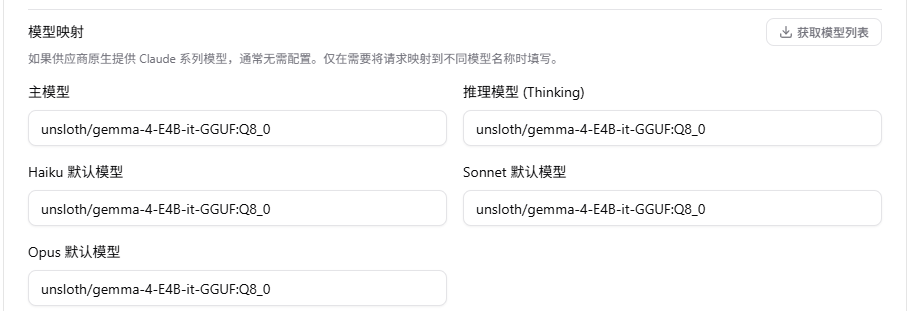
Claude Code内存溢出
启动Claude连接本地llama.cpp模型,只是简单问一句你是什么大模型?,Claude就会一直增加内存占用,要很久大概10几分钟才会有反馈。不知道是哪里配置错误。
我改成E4B模型,还是有同样的问题存在。一会就占了10G内存,把内存都撑爆了。
和Ollama对比
我用Ollama跑Gemma4 26B模型,对话还是基本能够一秒回复几个字。GPU占用不高。
用llama.cpp,很明显的对比是GPU能跑满100%,但是对话一直很慢。
显存是否够用,结论是不够
llama.cpp 在加载模型时会输出显存/内存需求信息,例如:ggml_init_cgraph(): allocating memory: 5120 MB
还可以:
- 使用
--verbose或--log-level debug启动,查看加载阶段的内存分配日志 - 根据模型大小、量化等级(如 Q4_0、Q5_K_M)和上下文长度(
--ctx-size)预估显存需求 - 适当降低
--n-gpu-layers或--ctx-size来减少显存占用
我启动成功之后,将日志给OpenClaw分析,结果如下:
🎮 显存占用 (GPU - RTX 5070 Ti Laptop 12GB)
总计:约 9938 MiB (9.7 GB)
| 项目 | 大小 |
|---|---|
| 模型权重 (31层) | 7716.76 MiB |
| KV 缓存 (非滑动窗口) | 1360.00 MiB |
| KV 缓存 (滑动窗口) | 159.38 MiB |
| 计算缓冲区 | 702.55 MiB |
| 剩余可用 | 1087 MiB |
💾 内存占用 (RAM)
模型相关:约 9103 MiB (8.9 GB)
| 项目 | 大小 |
|---|---|
| CPU 模型缓冲区 | 9103.04 MiB |
| CPU 计算缓冲区 | 271.30 MiB |
| CLIP 视觉编码器 | 1139.46 MiB |
| 提示词缓存 | 最高 8192 MiB (动态) |
📊 关键发现
- 显存压力较大:由于 131K 上下文和 Q4_K_M 量化,模型无法完全放入 GPU,有 20 层溢出到 CPU
- KV 缓存占显存大头:131K 上下文需要约 1.5GB 的 KV 缓存
- 总系统内存需求:约 18-20GB (模型缓冲区 + 视觉编码器 + 提示词缓存)
优化建议: 如果不需要 131K 超长上下文,可以降到 64K 或 32K,能显著减少 KV 缓存占用的显存。
参考:
在12GB显存部署Gemma4 26b a4b:
https://carteakey.dev/blog/running-gemma-4-26b-a4b-locally/#1-build-mainline-llama-cpp
https://github.com/carteakey/l3ms

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)