Obsidian + Claude Code + LLM Wiki:基于Karpathy 构建你的智能第二大脑完整指南
基于 Karpathy 方法论 | 告别 RAG 低效循环 | 让 AI 成为你的知识管理员
🌟 引言:知识管理的困局与破局
每天,我们都在信息洪流中挣扎:收藏了无数文章却再也找不到,做了大量笔记却无法形成体系,想要深入某个领域却发现知识碎片散落各处。
传统解决方案如 RAG(检索增强生成)存在根本缺陷:没有积累。每次提问,AI 都从头搜索原始文档,临时拼凑答案。就像每次做饭都从头种菜,而不是建立一个储备充足的厨房。
LLM Wiki 提供了新的范式:让 AI 增量构建和维护一个持久化的 Wiki(互相链接的 Markdown 文件)。知识被"编译"一次,然后持续更新,形成可复利的数字资产。
本文将带你完整搭建一个基于 Obsidian + Claude Code + LLM Wiki 的智能第二大脑,让你:
- 🎯 每天 5 分钟,AI 自动整理所有阅读素材
- 🧠 提问即得答案,AI 从你的知识库精准回答
- 📈 知识复利增长,每篇文章都增强整个系统
- 🛠️ 维护成本趋近于零,AI 负责所有繁琐工作
🔍 核心概念:三位一体的完美组合
1. Obsidian:你的数字大脑皮层
- 本地优先:所有文件存储在你自己电脑上,无需担心服务商跑路
- 双向链接:知识自动形成网络,发现意想不到的关联
- Markdown 原生:10 年后换工具也能打开,无锁定风险
- 插件生态:通过社区插件无限扩展功能
2. Claude Code:你的 AI 工作引擎
- 命令行界面:让 Claude 直接操作文件系统
- 上下文感知:理解你的知识库结构和规则
- 安全模式:每次修改前确认,防止意外破坏
- 多模型支持:Haiku(快速)、Sonnet(平衡)、Opus(深度)
3. LLM Wiki:你的知识组织哲学
- Karpathy 方法论:OpenAI 创始成员提出的知识管理理念
- 持久化编译:知识被结构化整理,而非临时检索
- 增量更新:新素材自动融入现有体系
- 交叉引用:相关概念自动链接,形成知识网络
🚀 完整搭建指南:30 分钟搞定
基于 GitHub 项目 obsidian-ai-second-brain,以下是精简版搭建步骤:
阶段一:安装环境(10 分钟)
Step 1:安装 Obsidian
- 访问 obsidian.md 下载对应版本
- 创建新 vault(仓库),路径避免中文和空格
- 示例:
D:\KnowledgeBase\而非D:\我的知识库\
Step 2:安装 Claude Code
# 安装 Node.js(如果尚未安装)
# 访问 nodejs.org 下载 LTS 版本
# 安装 Claude Code
npm install -g @anthropic-ai/claude-code
# 验证安装
claude --version
Step 3:安装 Claudian 插件
- Obsidian → 设置 → 社区插件 → 浏览
- 搜索 “Claudian”(作者 Yishen Tu)
- 安装并启用
obsidian 安装claude code(报错,注意npm安装的claude code的环境变量)
https://github.com/YishenTu/claudian/releases/tag/2.0.3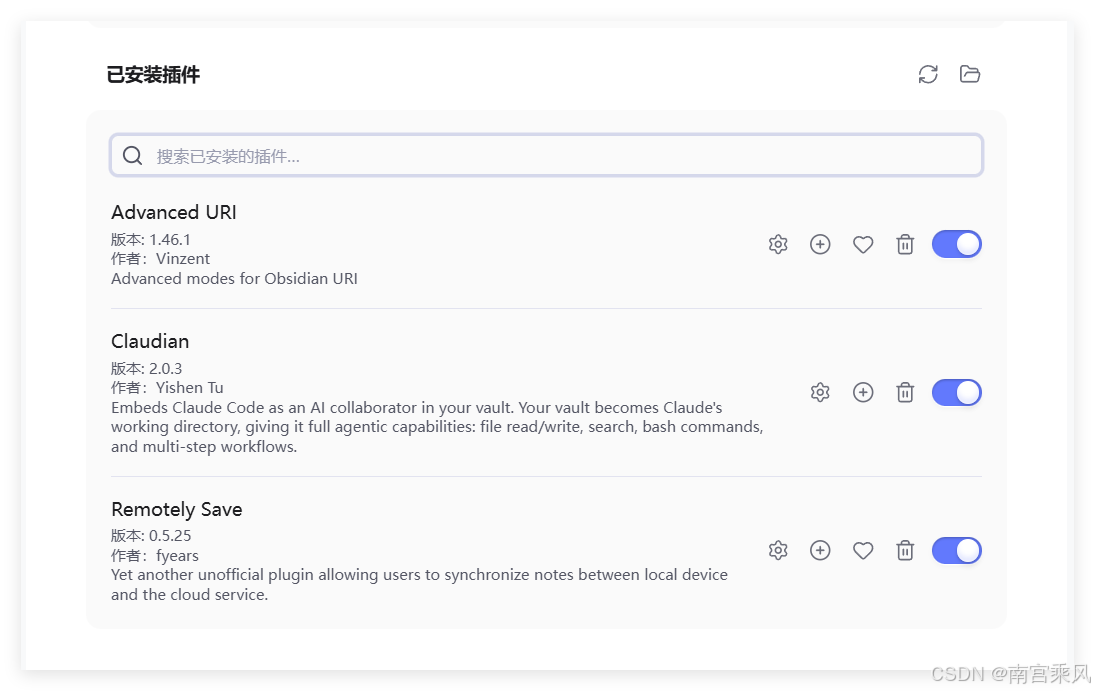
Step 4:配置 Claudian
- CLI Path:通常自动检测,如需手动填写终端
which claude的输出 - Safe Mode:建议设为
acceptEdits(修改前确认) - 模型选择:日常用 Sonnet,复杂任务切 Opus
Step 5:安装 Obsidian的Skills
请参考: https://github.com/kepano/obsidian-skills
阶段二 数据收集
用Chrome浏览器插件Obsidian Web Clipper 做素材采集
1、在浏览器安装 Obsidian Web Clipper 扩展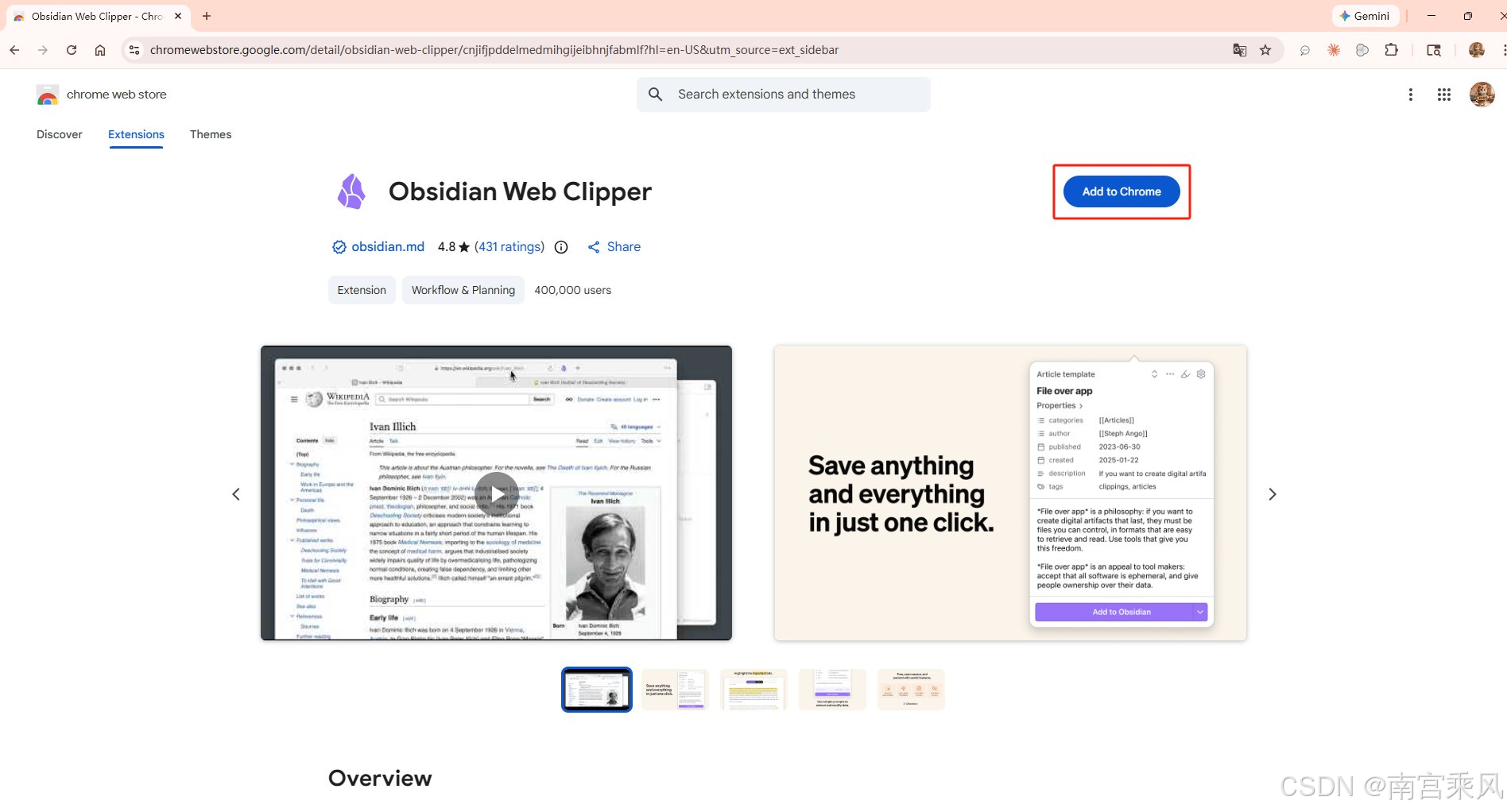
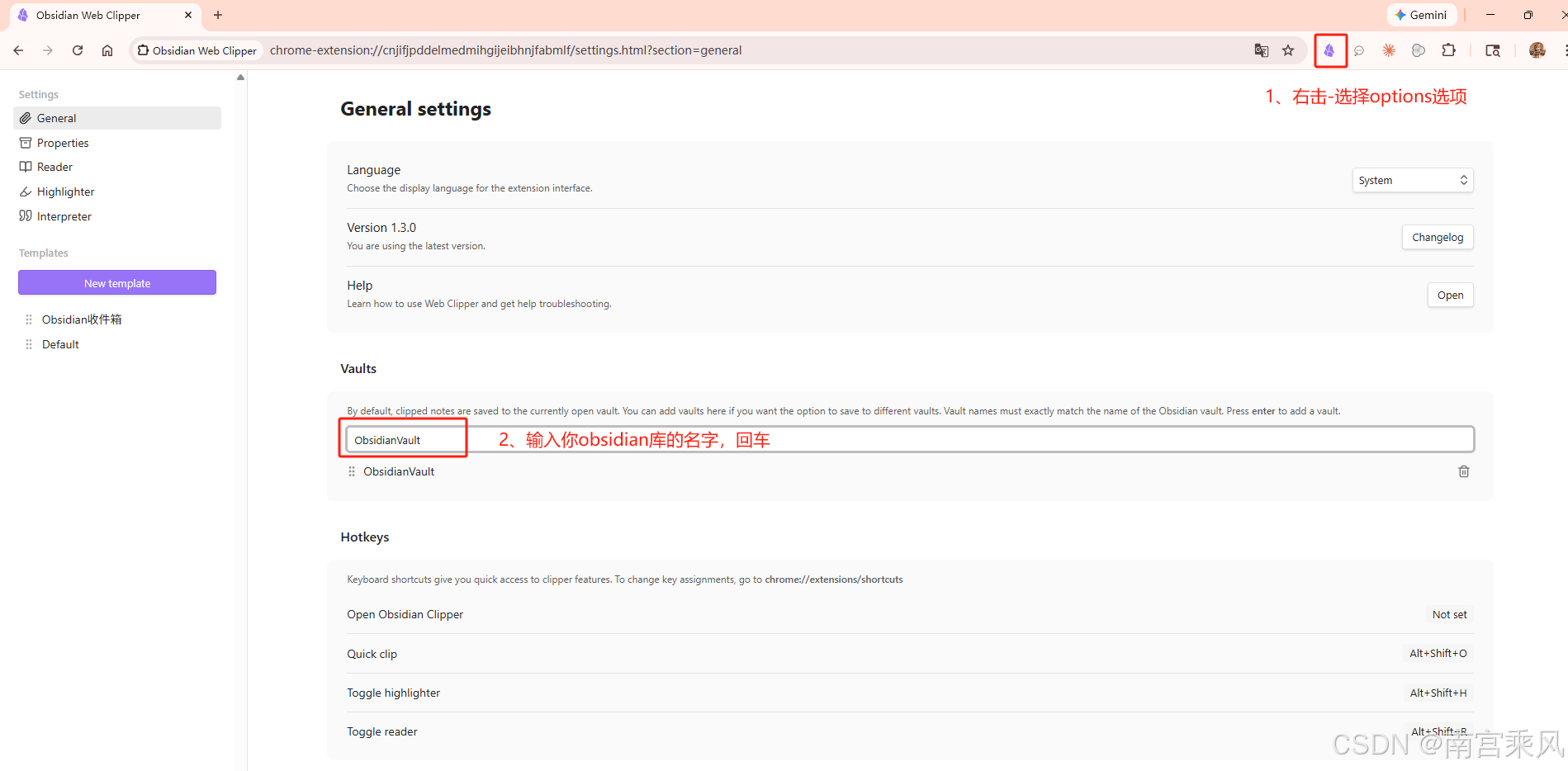
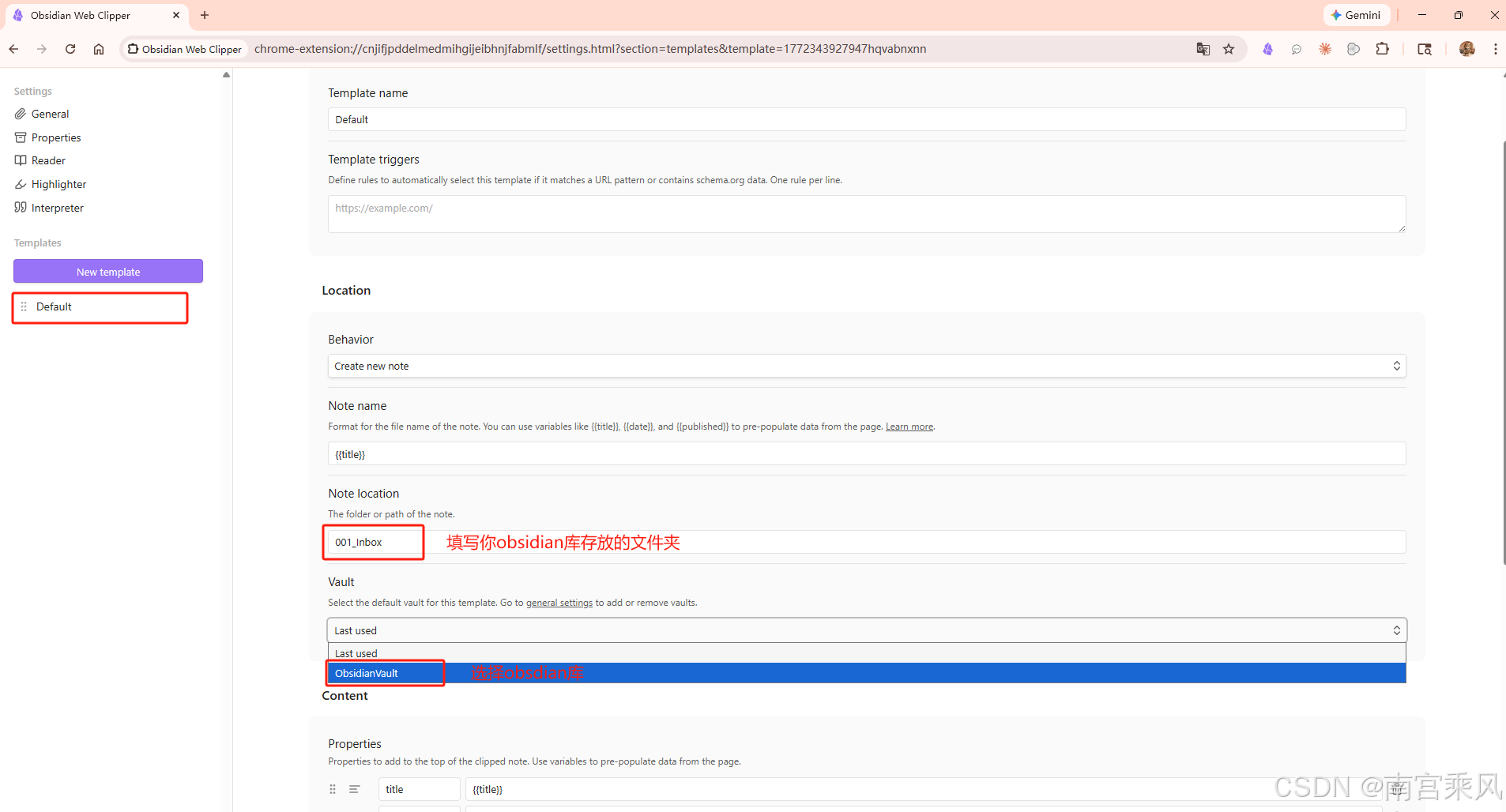
2、打开任意网页文章,点击扩展图标–Add to Obsidian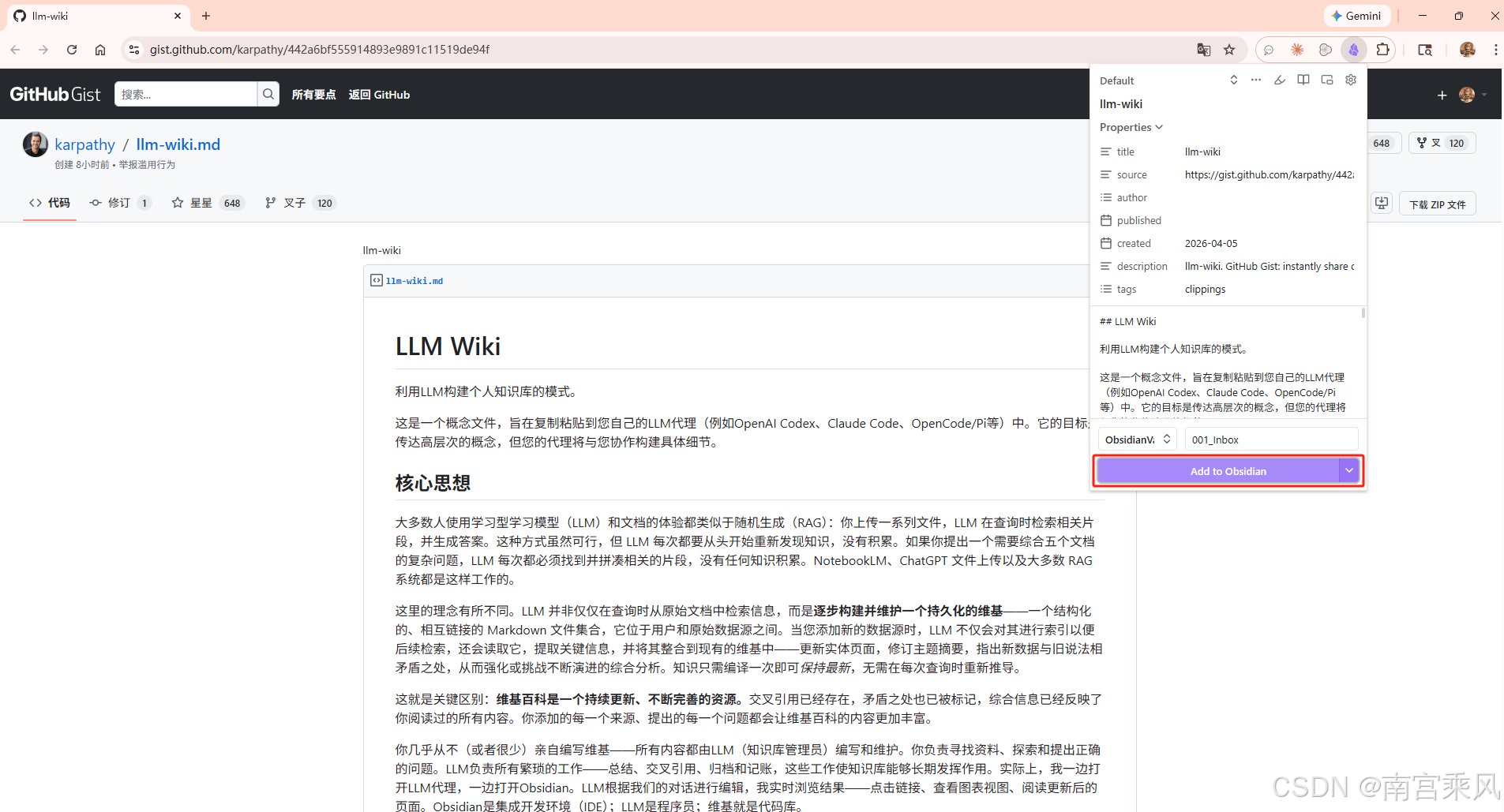
3、保存后文章自动转为 Markdown 出现在 Obsidian 里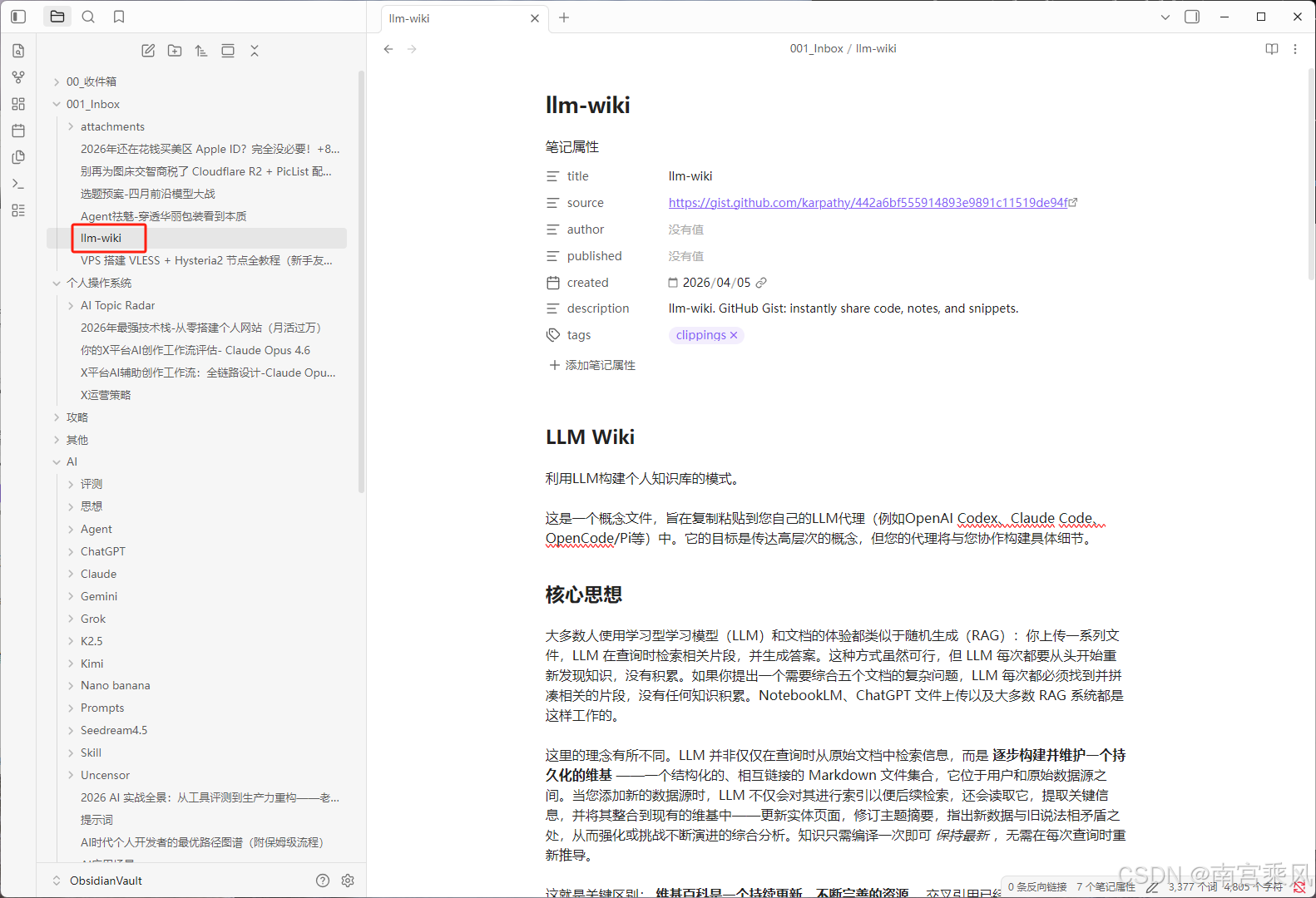
一个快捷键,让图片本地化,告别外链失效
剪藏下来的文章,图片通常还是外链,过几个月链接一挂,文章就残了。更关键的是,AI 读不了挂掉的图片链接。 Karpathy 的方案是两步配置,一劳永逸:
第一步:统一附件存储路径
打开 设置 → 文件与链接 → 找到附件存储路径 → 设为当前文件夹下指定的子文件夹,子文件夹名称设为attachments 不推荐Karpathy的固定到一个目录 raw/assets/ 因为多了之后附件混在了一起不好管理。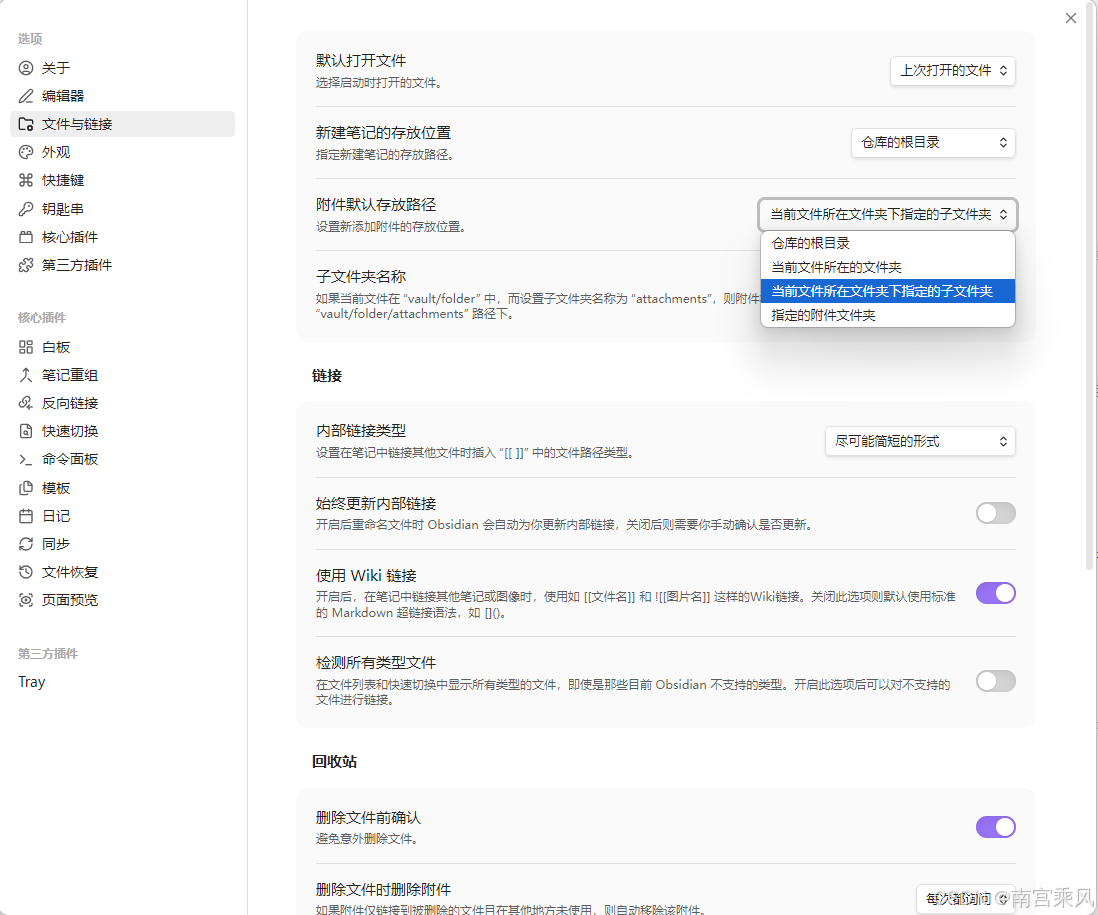
第二步:绑定下载快捷键 设置 → 快捷键 → 搜索 “下载” → 绑定快捷键Ctrl+Shift+D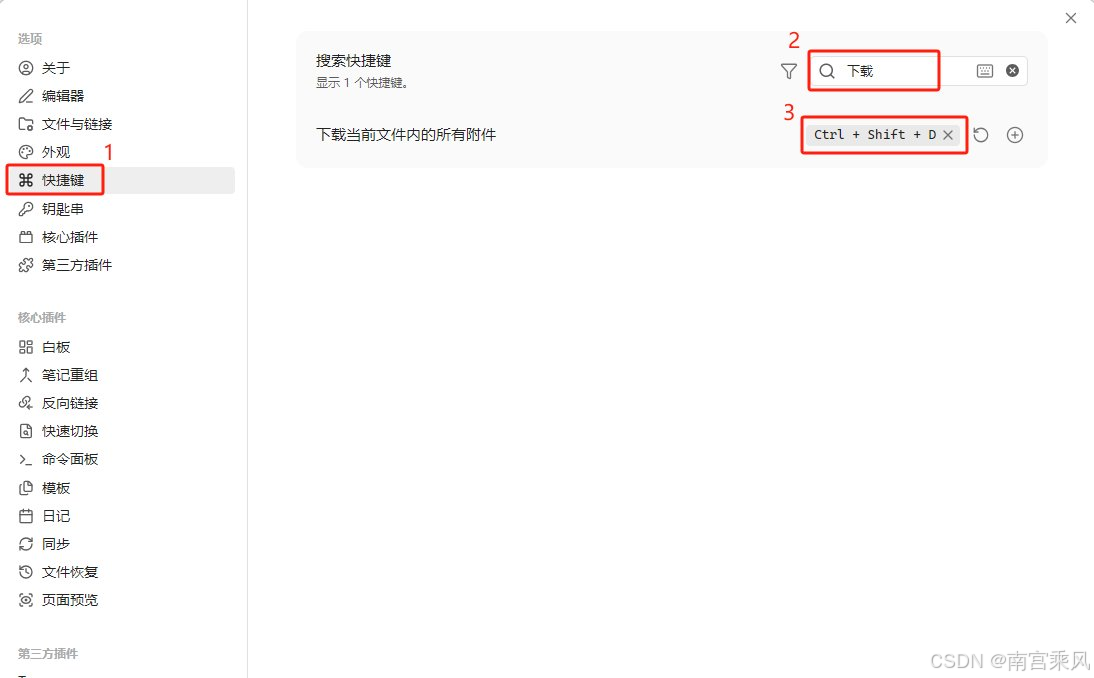
以后每次剪藏完一篇文章,按一下 Ctrl+Shift+D,所有图片自动下载到本地。AI 就能直接读取和引用这些图片了
这里Karpathy分享了一个小细节:LLM 目前没法一次性读取带内嵌图片的 Markdown。变通做法是先让 AI 读文本内容,再让它单独查看文章引用的图片,不够优雅,但管用。
阶段三:搭建知识库结构(5 分钟)
请访问: https://github.com/nangongchengfeng/obsidian-ai-second-brain.git
Step 5:创建目录结构
你的vault/
├── raw/ # 原始素材(AI 只读,不改)
├── wiki/ # AI 维护的知识库
└── assets/ # 配图资源
在 Obsidian 中创建这些文件夹,然后在 wiki/ 下创建:
index.md- 全局索引(先写标题即可)log.md- 操作日志
Step 6:创建 CLAUDE.md(核心文件)
将项目中的 CLAUDE.md 复制到你的 vault 根目录,或使用以下精简版:
# Personal LLM Wiki
## 目录职责
- **raw/** — 原始素材,AI 只读,永不修改
- **wiki/** — AI 维护的消化笔记
- **assets/** — 配图资源
## 两个特殊文件
- **wiki/index.md** — 全局索引
- **wiki/log.md** — 操作日志
## 三个触发行为
1. **Ingest**:录入新素材,触发词"加到 wiki"、"ingest 这个"
2. **Query**:查询知识库,触发词"wiki 里关于 X"、"根据我的 wiki 总结"
3. **Lint**:知识库体检,触发词"lint wiki"、"体检"
关键:文件名必须是全大写
CLAUDE.md,不是claude.md
Step 7:创建主题目录
raw/AI工作流/
raw/产品设计/
wiki/AI工作流/
wiki/产品设计/
主题按你的兴趣领域创建,无需一次建完。
阶段四:日常使用(5 分钟掌握)
Step 8:Ingest(录入素材)
# 在 Claudian 对话框中输入
ingest 这个:
[粘贴文章内容 / 拖入文件 / 贴链接]
AI 会自动:
- 保存原始素材到
raw/ - 编译成结构化 wiki 文章
- 合并相关主题,避免重复
- 更新索引和日志
支持格式:
- 文章全文(直接粘贴)
- 网页链接(AI 尝试抓取)
- PDF/视频/图片(拖入 raw/ 后告诉 AI)
- 视频笔记/转录文字
Step 9:Query(查询知识)
# 基本查询
我的 wiki 里关于 AI 工作流有什么?
# 对比分析
对比一下 LangChain 和 LangGraph,根据我的笔记
# 保存结果(加"存下来")
根据我的 wiki 总结 AI 工作流核心模式,存下来

Step 10:Lint(定期体检)
lint wiki
# 或
体检
AI 检查项:
- ✅ 索引与文件一致性(自动修复)
- ✅ 内部链接有效性(自动修复)
- ⚠️ 事实矛盾(报告待确认)
- ⚠️ 孤立页面(报告待处理)
建议频率: 每周一次,或文章超过 20 篇后
阶段五:进阶优化(随用随加)
Step 11:自定义 CLAUDE.md 规则
用了一两周后,根据你的需求添加规则:
## 我的主题分类
- AI工作流 — AI 工具、方法、工作流
- 产品设计 — 产品思维、设计方法论
- 一人公司 — 创业、商业模式、IP 构建
## 命名约定
- wiki 文章用中文描述性命名
- raw 文件保持原名不改
## 交叉引用规则
写新文章时,检查是否和已有文章有关联,有就在文末加 See Also
Step 12:知识复利增长
- 第 1 篇文章:独立知识点
- 第 10 篇文章:开始产生交叉引用
- 第 50 篇文章:AI 能从多篇文章综合出创新见解
- 第 100 篇文章:知识库比你自己的记忆更可靠
关键习惯: 每天花 5 分钟 ingest 当天看到的好内容。
📊 LLM Wiki vs 传统 RAG:根本性差异
| 维度 | 传统 RAG | LLM Wiki |
|---|---|---|
| 知识积累 | ❌ 无积累,每次从零开始 | ✅ 持续积累,知识复利 |
| 维护成本 | ⚠️ 每次查询都需处理 | ✅ 一次性构建,接近零维护 |
| 人类角色 | 📝 不断提供文档和查询 | 🧠 只需阅读、思考、提问 |
| AI 角色 | 🔍 被动检索,临时拼凑 | 🛠️ 主动构建,持续维护 |
| 知识结构 | 🗂️ 文档集合,缺乏结构 | 🌐 结构化网络,双向链接 |
| 适用场景 | 🎯 临时性、一次性查询 | 🏆 长期性、系统性知识管理 |
| 自动化程度 | 🔄 低,依赖人工整理 | 🤖 高,全流程自动化 |
| 版本管理 | ⚠️ 通常缺乏 | ✅ Git 集成,完整历史 |
核心区别: RAG 是临时餐馆(每次从市场买食材),LLM Wiki 是自家厨房(食材储备充足,随时可用)。
1. 内容转化流水线
LLM Wiki 结构化笔记
↓
博客文章草稿(一键导出)
↓
社交媒体片段(自动提取)
↓
演讲幻灯片(通过 Marp 转换)
2. 可持续工作流
- 输入:每天 5 分钟 ingest 阅读内容
- 处理:AI 自动整理、分类、链接
- 输出:需要时快速生成高质量内容
- 维护:AI 定期体检,保持知识库健康
💡 实践建议与避坑指南
建议 1:从最小可行开始
- 先只用基础功能,跑通整个流程
- 1 个月后再考虑添加 Dataview、Marp 等进阶插件
- 避免"完美主义瘫痪",先行动再优化
建议 2:建立每日微习惯
- 设定每天固定时间(如下午 5 点)
- 花 5 分钟 ingest 当天看到的好内容
- 坚持 30 天,知识库自然形成规模
建议 3:善用安全模式
- Claudian 设置 Safe Mode 为
acceptEdits - AI 每次修改前都会确认
- 初期可以监督 AI 行为,学习其工作模式
常见问题与解决
Q:已有大量 Obsidian 笔记怎么办?
- 分批 ingest,一天处理一个主题
- 不要一次性导入,质量优先于数量
- 利用现有笔记作为 raw 素材
Q:手机上能用吗?
- Obsidian 有手机版,可查看和编辑
- Claudian 仅支持桌面端(需 AI 操作时)
- 工作流:手机随手记 → 电脑端 ingest
Q:数据安全吗?
- Obsidian 文件存在本地电脑
- Claude API 处理时发送内容,但不永久存储
- 敏感信息(密码、API Key)不要放入 vault
Q:AI 回答不准确怎么办?
- 可能原因 1:知识库缺乏相关内容 → ingest 更多素材
- 可能原因 2:AI 理解偏差 → 在 CLAUDE.md 添加规则约束
- 可能原因 3:索引未更新 → 运行 lint 修复
🌈 后记:从信息消费者到知识创造者
我们正处在一个转折点:AI 不再是简单的问答机器,而是能够与我们共同思考、共同创造的合作伙伴。
Obsidian + Claude Code + LLM Wiki 这套组合,本质上是将 AI 的能力深度整合到你的个人知识工作流中。它解决了知识管理的核心矛盾:
- 积累与检索:从临时检索到持久积累
- 人工与自动:从繁琐整理到智能维护
- 碎片与体系:从孤立笔记到网络知识
作为个人博客者,这不仅是效率工具,更是创作能力的放大器。当你拥有一个不断成长、自我优化的知识库时:
- 写作不再是从零开始,而是从丰富的素材库中提炼
- 思考不再是孤立的,而是在知识网络中游走
- 创作不再是消耗,而是在已有基础上的创新
今天花 30 分钟搭建,未来每天节省 2 小时。 更重要的是,你不再只是信息的消费者,而是拥有自己数字大脑的知识创造者。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)