EASE VS SD-LoRA 并排对比,一眼看懂两篇顶刊
一 ` 简单描述
这两篇论文都在做 foundation model 场景下的 class-incremental learning,也都强调 exemplar-free / rehearsal-free。但它们的思路其实很不一样:
- EASE:走的是 “显式扩子空间” 路线。每来一个任务,就加一个 adapter,形成新的任务子空间;再靠 prototype complement 把旧类在新子空间里的表示补出来。
-
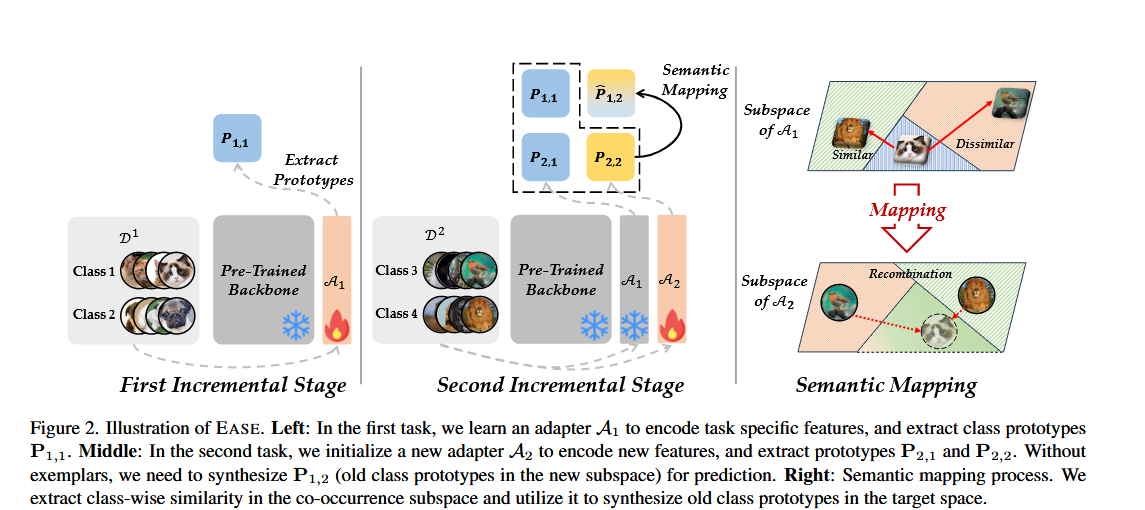
- SD-LoRA:走的是 “参数更新方向复用” 路线。不是给每个任务搞一套显式分类子空间,而是把 LoRA 更新拆成 direction + magnitude,保留旧方向,只继续学新方向和所有方向的缩放系数。
-

二 ` 并排对比表
| 维度 | EASE | SD-LoRA |
|---|---|---|
| 论文定位 | 解决 PTM-based CIL 中“新任务覆盖旧任务”的问题,同时避免 expandable backbone 的高成本和 exemplar 依赖。 | 解决 foundation-model CIL 中“随着任务数增长,prompt/LoRA 池或 rehearsal 方案不够 scalable”的问题,强调 rehearsal-free、inference-efficient、end-to-end 三者兼得。 |
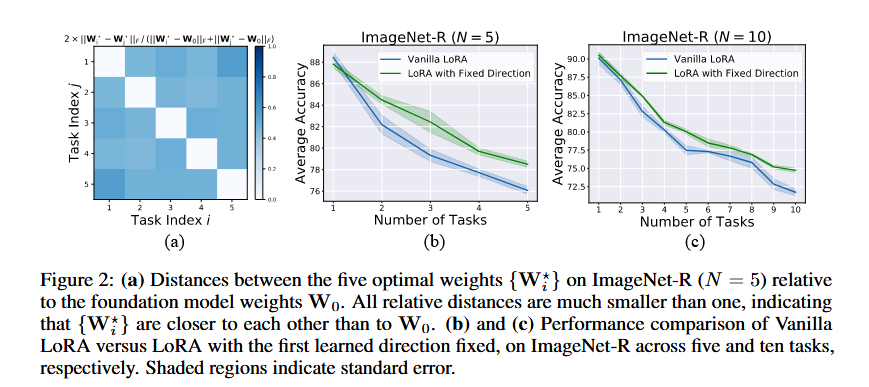
| 核心范式 | Adapter-based subspace expansion:每个任务一个独立 adapter,一个任务一个子空间。 | Decoupled LoRA:把 LoRA 更新拆成 magnitude 和 direction,旧 direction 固定,新任务增量学习新 direction,并联合调整各 direction 的 magnitude。 |
| 抗遗忘机制 | 通过“新任务写入新 adapter”来避免直接改坏旧任务特征;旧知识以历史子空间形式保留。 | 通过“保留历史 LoRA direction,只重标定 magnitude 并新增少量 direction”来沿低损失路径移动,减少对旧任务的破坏。 |
| 统一分类怎么做 | 用 prototype-based classifier;把各子空间的 prototype 拼起来分类。最大难点是旧类在新子空间中没样本,因此用 semantic-guided prototype complement 补齐。 | 不搞 prototype 补全;直接用最后训练好的模型推理,不需要测试时做 task/component selection。 |
| 最有辨识度的创新点 | 语义引导的原型补全:用旧/新类在共现空间中的相似性,去重建旧类在新子空间里的 prototype。 | direction–magnitude decoupling:作者还给出经验和理论分析,说明早期 direction 更关键,后续 direction 更像小修正。 |
| 推理形态 | 推理时要聚合多个 adapter 子空间的特征,并对子空间 logits 做 reweight。 | 推理时直接使用最终模型,无需 prompt/LoRA 组件选择,因此更强调 inference scalability。 |
| 参数增长方式 | 随任务数增长持续保存 adapter;作者明确说 adapter 很轻量,但长期看模型体积仍会增加。 | 也会随任务增加 LoRA 组件,但提出 SD-LoRA-RR 和 SD-LoRA-KD 两个变体来降低参数增长。 |
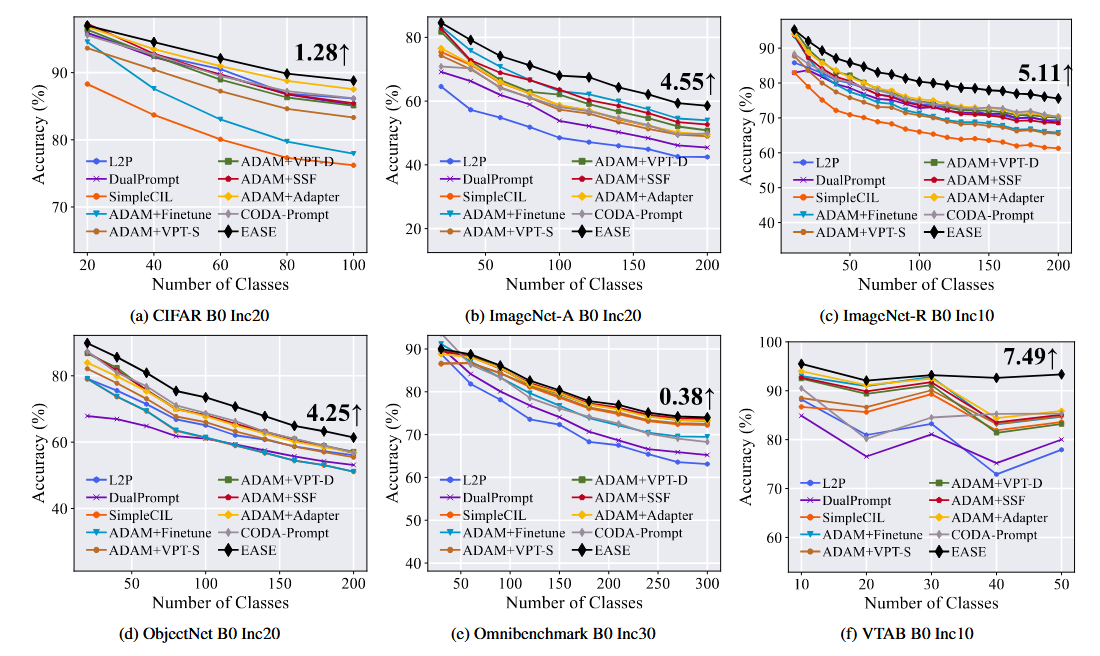
| 实验优势 | 在 7 个 benchmark 上取得最优,且不用 exemplars;还接近“有 exemplars 直接算旧类 prototype”的 upper bound。 | 在多个 benchmark 和不同 task length 上优于现有方法,尤其强调任务数变多时优势扩大;同时兼顾推理效率与零存储旧样本。 |
| 更像哪类方法 | 更像 architecture expansion / feature-space composition。 | 更像 PEFT + low-loss path / model merging 风格。 |
| 主要短板 | 子空间越来越多,adapter 需要一直存;作者把 adapter 压缩列为未来方向。 | 尽管更 scalable,但本质上仍是增量叠加 LoRA 组件,所以极长任务序列下仍需继续控制参数膨胀。 |
三 ` 再从研究视角并排看
1. 它们到底在“保护什么”
EASE 更像是在保护 表示空间。
它假设灾难性遗忘主要来自“新任务把旧特征空间改坏了”,所以干脆给每个任务独立子空间,让旧任务特征别被动。问题变成:这些子空间最后怎么统一分类。于是才有 prototype complement。
SD-LoRA 更像是在保护 参数更新轨迹。
它假设多个任务的较优解可能落在相近、甚至部分重叠的低损失区域,所以重点不是“彻底隔离任务”,而是“保留历史更新方向,在已有好方向上继续调节步长和少量新方向”。
2. 它们如何解决“没有旧样本”
EASE 的回答是:不用旧样本也能重建旧类在新空间中的 prototype。这是一个很强的“分类器补全”思路。
SD-LoRA 的回答是:尽量别把问题变成旧类重建问题。它通过保持参数更新方向的连续性,直接让最终模型维持对旧任务的能力,不额外设计 prototype reconstruction。
3. 哪个更“工程友好”
如果你关心 结构直观、模块清晰、解释性强,EASE 很强:
“每任务一个 adapter + prototype 补全 + 子空间集成”,逻辑很完整,也很好做消融。
如果你关心 推理效率和长任务序列的扩展性,SD-LoRA 更占优:
论文明确把 “rehearsal-free + inference-efficient + end-to-end optimization” 当成设计目标,而且给了效率表,ImageNet-R (N=20) 上 SD-LoRA 与 InfLoRA 一样是 35.12 GFLOPs,但不需要存旧特征;SD-LoRA-RR 还能把可学习参数从 0.37M 压到 0.23M。
四 ` 实验结果怎么理解
1.EASE
EASE 在 ViT-B/16-IN21K backbone 下,7 个 benchmark 都是表中最优,比如 CIFAR100 为 91.51 / 85.80,CUB 为 92.23 / 86.81,ImageNet-R 为 78.31 / 70.58,ImageNet-A 为 65.34 / 55.04。作者还说它在若干数据集上比 runner-up 高出约 4%–7.5%。
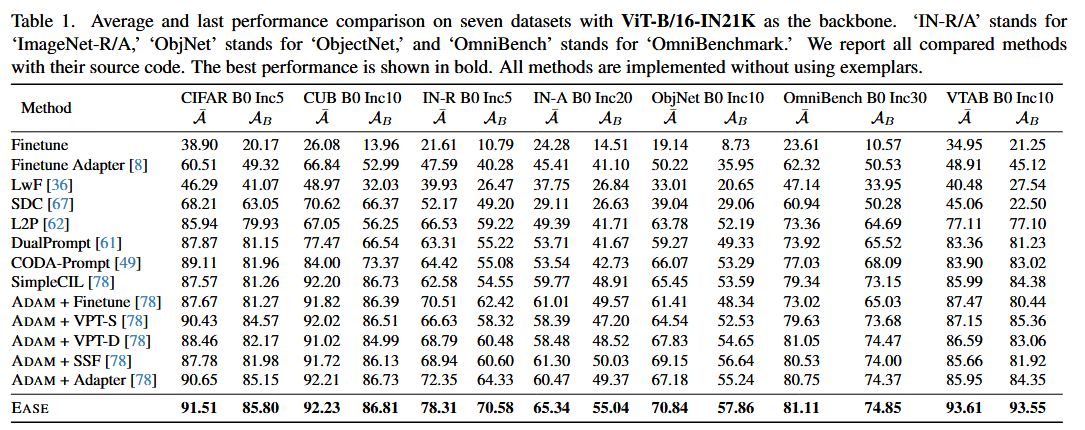
更关键的是,EASE 不用 exemplars,却几乎追平了“存 exemplars 直接算旧类 prototype”的 upper bound:在 ImageNet-R B0 Inc20 上,upper bound 是 81.73 / 76.08,EASE 是 81.73 / 76.17;在 CIFAR B0 Inc10 上 upper bound 是 92.32 / 87.79,EASE 是 92.35 / 87.76。这几乎直接证明了 prototype complement 的有效性。
2.SD-LoRA
SD-LoRA 在 ImageNet-R 的不同 task length 上都优于对比方法,而且任务越多,优势越明显。论文还明确写到:在 ImageNet-R (N=20) 上,SD-LoRA 相比 InfLoRA,Acc 提升 7.68%,AAA 提升 4.62%。在 ImageNet-A 上,也明显优于 HiDe-Prompt。
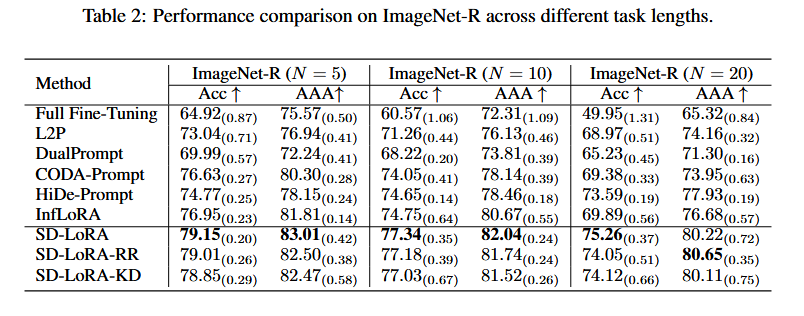
具体数值上,ImageNet-A (N=10) 为 55.96 / 64.95,DomainNet (N=5) 为 72.82 / 78.89;两个轻量变体 RR 和 KD 只带来很小性能损失。
五 ` 如果要把它们当成硕士研究切入点
1.更适合从 EASE 往下做的方向
如果你偏好 表示学习 / 原型学习 / 无样本分类器补全,EASE 很适合继续挖。
因为它天然留下几个可研究问题:
- prototype complement 能不能更强,比如从 similarity mapping 升级到 learned transport / generative prototype completion;
- adapter 数量增长后,怎么做压缩、合并或路由;
- prototype-based classifier 是否能和更强的 calibration 结合。
2.更适合从 SD-LoRA 往下做的方向
如果你偏好 PEFT / optimization / 理论分析 / scalability,SD-LoRA 更适合。
因为它天然对应的问题是:
- direction 为什么能跨任务复用;
- 低损失路径能否更显式地建模;
- RR/KD 能否做成更有理论保证的 rank allocation / component pruning;
- 能不能把 decoupled LoRA 和 adapter / prefix / prompt 结合。
六 ` 最后给你一个结论版
EASE 更像是在说:
“我给每个任务一个独立特征子空间,再想办法把这些子空间拼成统一分类器。”
SD-LoRA 更像是在说:
“我不强调任务隔离子空间,而是复用历史参数更新方向,在共享低损失区域里持续前进。”
所以如果你问我两篇谁更“像一条主线上的连续演进 ? ”
答案其实是:不是。它们代表的是 CIL+PEFT 里两条不同哲学。
- EASE 偏表示空间扩展
- SD-LoRA 偏参数更新几何

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)