推荐系统中的特征交互模型
推荐系统中的特征交互模型详解
一、什么是特征交互
特征交互是指两个或多个特征之间存在的组合效应,这种组合效应对预测结果的贡献不等于各特征单独贡献的简单相加。
例子
- 用户A + 电影类别:科幻 → 高兴趣
- 用户B + 电影类别:科幻 → 低兴趣
即使用户A和用户B在其他方面很相似,他们对同一类别的偏好也可能完全不同。这种差异就是"用户×类别"的特征交互。
二、为什么特征交互很重要
- 个性化更精准:单纯的特征加权无法捕捉复杂偏好模式
- 现实场景复杂:用户决策往往受多重因素共同影响
- 传统模型局限:线性模型和简单Deep Model难以显式建模交互
三、常见的特征交互模型
- FM (Factorization Machines, 2010)
核心思想:用向量内积建模二阶特征交互
ŷ = w₀ + Σᵢ wᵢxᵢ + Σᵢⱼ<vᵢ, vⱼ>xᵢxⱼ
优点:
- 时间复杂度从 O(n²) 降到 O(kn),k是隐向量维度
- 可以处理稀疏数据
缺点:
- 只能建模二阶交互,无法捕捉高阶关系
- 每对特征交互权重相同(缺乏灵活性)
- DeepFM (2017)
架构:FM组件 + Deep组件并行融合
output = sigmoid(FM-part + Deep-part)
设计目的:
- FM部分:显式学习低阶特征交互
- Deep部分:隐式学习高阶特征交互
- 两者共享embedding层
- FFM (Field-aware Factorization Machines, 2016)
核心改进:每个特征在不同Field下有不同隐向量
<vᵢⱼ, vⱼᶠⁱ> 其中 fᵢ 是特征j所在的field
应用场景:CTR预测等有明显Field结构的场景
- xDeepFM (2018)
创新点:CIN(Compressed Interaction Network)
CIN通过逐层显式构建高阶特征交互:
Xᵏ = CIN(Xᵏ⁻¹, E) # E是embedding
特点:
- 显式建模高阶交互
- 每阶交互都有独特向量
- 参数量相比全连接网络大幅减少
- AFM (Attentional Factorization Machine, 2017)
核心创新:引入注意力机制给不同交互分配不同权重
aᵢⱼ = attention(vᵢ ⊙ vⱼ) # ⊙表示逐元素相乘
优势:自动学习哪些特征交互更重要
- DCN (Deep & Cross Network, 2017)
Cross Network核心公式:
xₗ₊₁ = x₀(xₗWₗ + bₗ) + xₗ
特点:
- 残差连接保证信息流动
- 特征交叉时保持原始特征x₀
- 参数量随层数线性增长
- DCN V2 (2020)
改进:
- 支持显式高阶特征交叉
- 低秩分解减少参数量
- 混合专家架构增强表达能力
- AutoInt (2019)
核心:多层Transformer风格的交互
H = softmax(QKᵀ/√d)V
特点:
- 自注意力机制自动学习交互模式
- 可处理多阶交互
- 端到端训练
- FiBiNET (2019)
两个核心组件:
- Fi-MLP(Squeeze-and-Excitation):重加权的embedding
- Bilinear-Feature:用双线性池化替代简单的哈达玛积
- PNN (Product-based Neural Networks, 2016)
Product Layer:
- Inner Product Layer: 内积
- Outer Product Layer: 外积
捕获特征间的乘法关系。
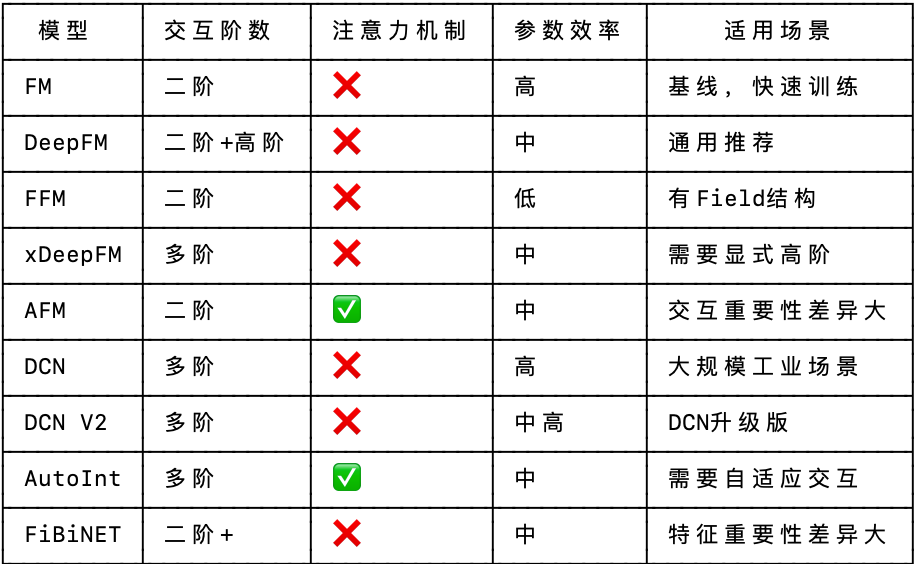
四、模型对比总结

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)