GLM高效协作手册:3个真实场景教你用“规则收敛“释放AI最大战斗力
人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。———— 马尔科姆·格拉德威尔

🌟 Hello,我是Xxtaoaooo!
🌈 "代码是逻辑的诗篇,架构是思想的交响"
一、引言
在AI编程助手百花齐放的今天,Claude、GPT、GLM三足鼎立,各有拥趸。但很多开发者的真实体验是:同一个需求,换一个模型,效果天差地别。
这不是模型能力的问题,而是你没有"对症下药"。
经过大量真实使用对比,我发现一个有趣的规律:Claude像一只聪明的哈基米,它会主动猜你想干什么;GPT像个固执的学霸,更在乎它学过的标准答案;而GLM则像一名士兵——你给的指令越明确,它执行得越到位。
本文将基于我的真实使用体验,深入剖析三大模型的"性格差异",并分享一套经过验证的 GLM高效协作方法论,帮助你用"规则收敛"的方式释放GLM的最大战斗力。
二、三大模型的"性格档案"
2.1 Claude——省心但有主见的"哈基米"
Claude之所以被大多数人觉得好用,核心原因是省力。你和它说话,它会主动帮你做决策、补全你的模糊意图,就像一只聪明的哈基米,总能在你开口之前猜到你要什么。
优势: 对话成本低,模糊提示词也能得到不错的结果。
局限: 当你的需求非常精确、不允许"自由发挥"时,Claude的自作主张反而会成为干扰。
2.1.1 示例演示
为了直观展示三大模型的性格差异,我用同一个模糊提示词分别测试:
测试提示词:
帮我写一个Android的蓝牙扫描功能
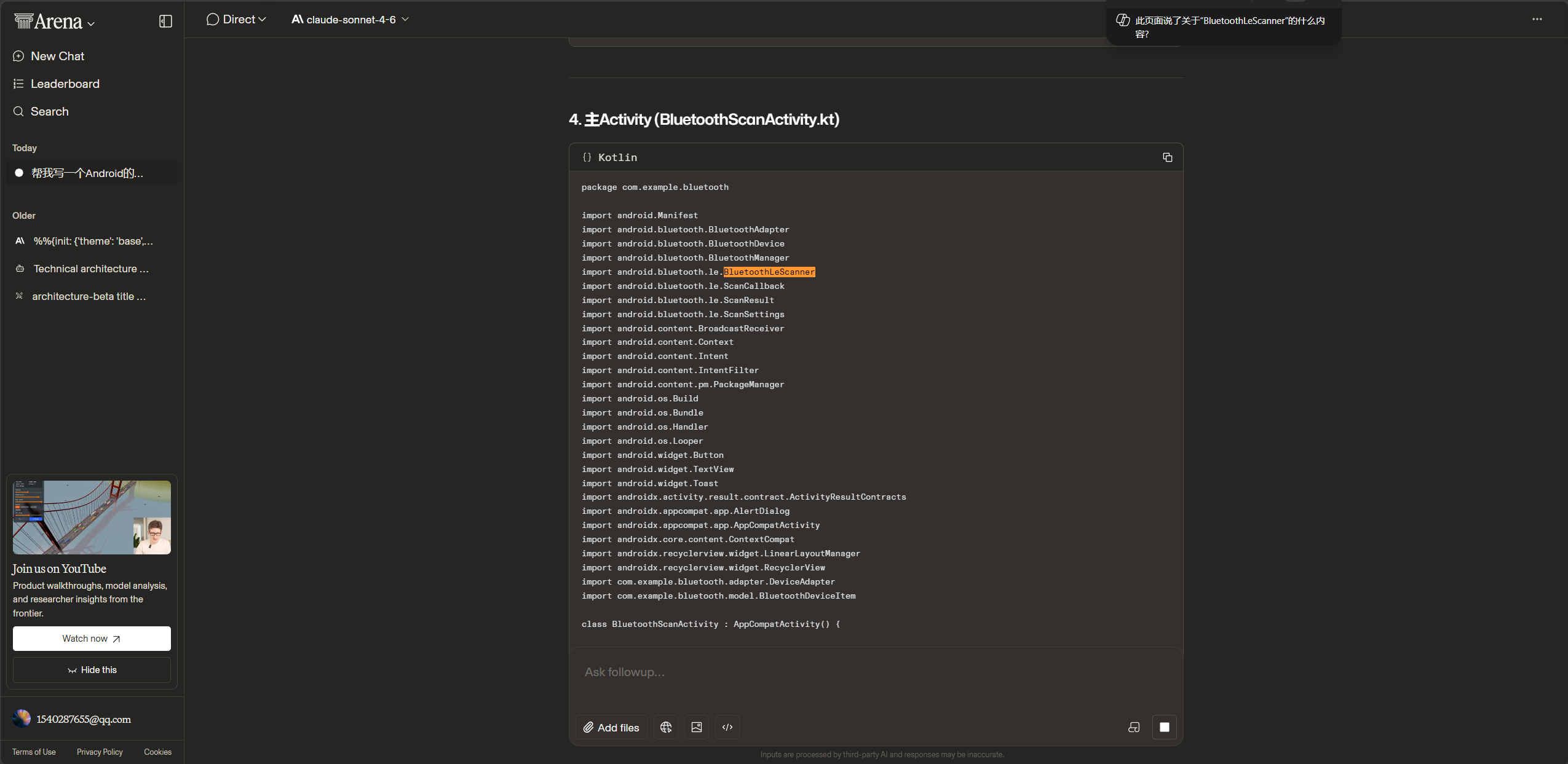
Claude 收到这个提示词后,会主动帮你做决策:它大概率会自己选择 Kotlin 语言、自己决定用 BluetoothLeScanner、自己加上权限声明、甚至自己补充连接逻辑——尽管你只说了"扫描"。它猜到了你可能"其实还需要连接",于是自作主张地把后面的步骤也一并写了。
Claude的典型行为特征:
|
行为 |
表现 |
|
主动猜测意图 |
你只说扫描,它把连接也写了 |
|
自选技术方案 |
自动选定 Kotlin + BLE |
|
补充未要求内容 |
自行添加权限、异常处理、回调 |
|
输出风格 |
省力,但不可控 |
可以很明显看出来,Claude 会主动帮我们做决策、补全模糊意图。
2.2 GPT——忠于"公共解"的固执学霸
GPT更在乎它所学习到的公共知识。不管你说什么,它内心有一套自己的答案体系,倾向于给出"大多数人认为对的东西"。
优势: 通用场景下答案质量稳定,解释性强。
局限: 当你的需求偏离"主流方案"时,你会发现GPT很难被说服,它总会把你拽回它认为"正确"的方向。
2.2.1 示例演示
测试提示词:
帮我写一个Android的蓝牙扫描功能
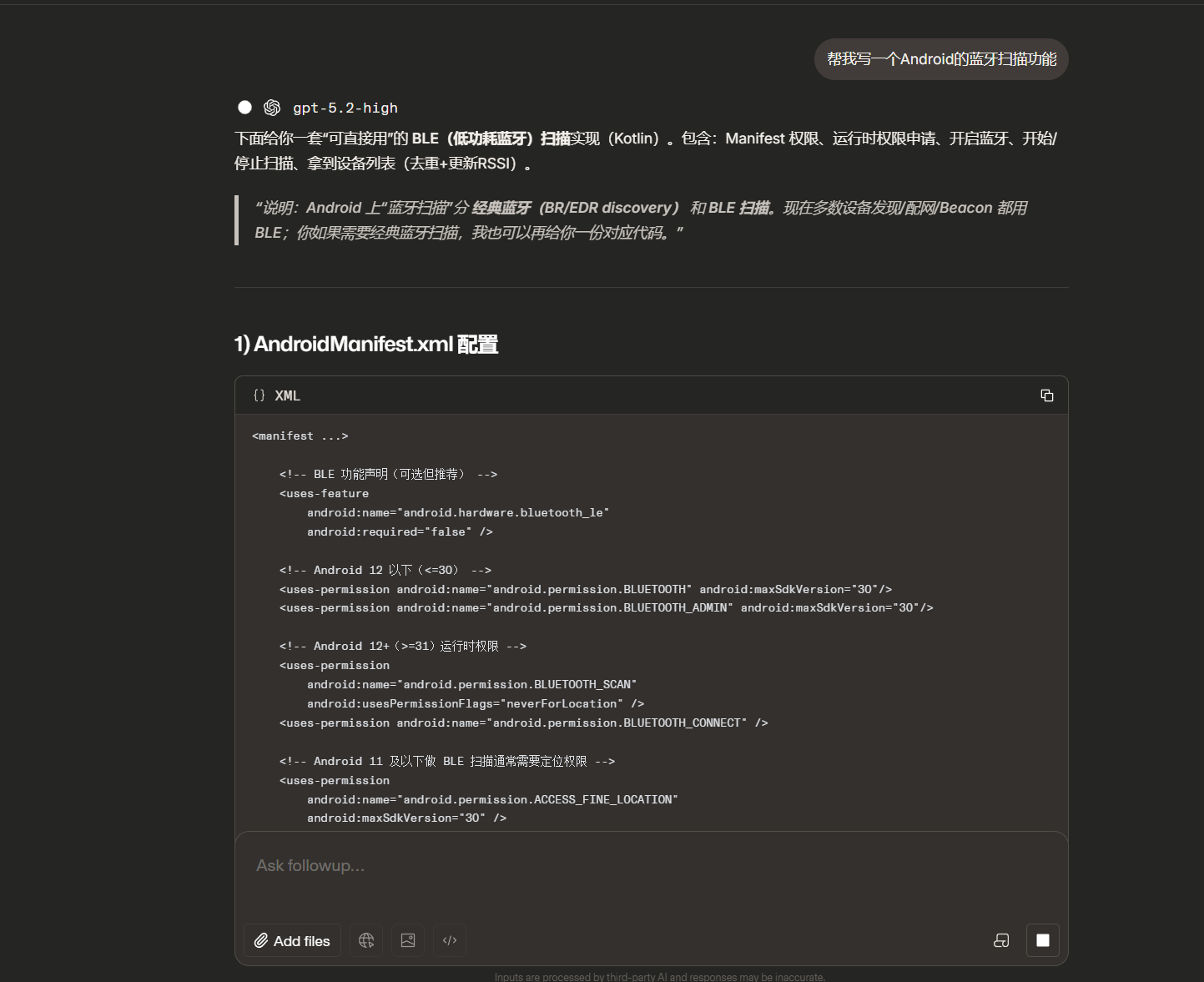
GPT 收到这个提示词后,会给出一份教科书式的回答:标准的 BroadcastReceiver 写法、完整的权限说明、一大段原理讲解。它不会像 Claude 那样主动帮你选方案,也不会像 GLM 那样等你指挥,而是给出它认为"最正确、最通用"的标准答案。
GPT的典型行为特征:
|
行为 |
表现 |
|
给标准答案 |
倾向于教科书式通用方案 |
|
大段解释 |
先讲原理,再讲用法,最后讲注意事项 |
|
不主动延伸 |
你问什么答什么,很少"多做事" |
|
输出风格 |
正确但冗长,缺乏针对性 |
可以看到GPT尝试给我们标准的答案,“可直接用”的方式,并且给我们讲解原理。
2.3 GLM——令行禁止的"钢铁士兵"
GLM更像一个士兵。如果你给它的提示词比较简单,它需要花更多时间去寻找方向,甚至可能给出错误结果。但一旦你把规则定清楚、流程规范好,它的执行力和精准度会让人惊艳。
优势: 规则遵循能力极强,在收敛范围内表现超越同类。
局限: 对提示词质量要求高,"随便说说"很难得到好结果。
2.3.1 示例演示
测试提示词:
帮我写一个Android的蓝牙扫描功能
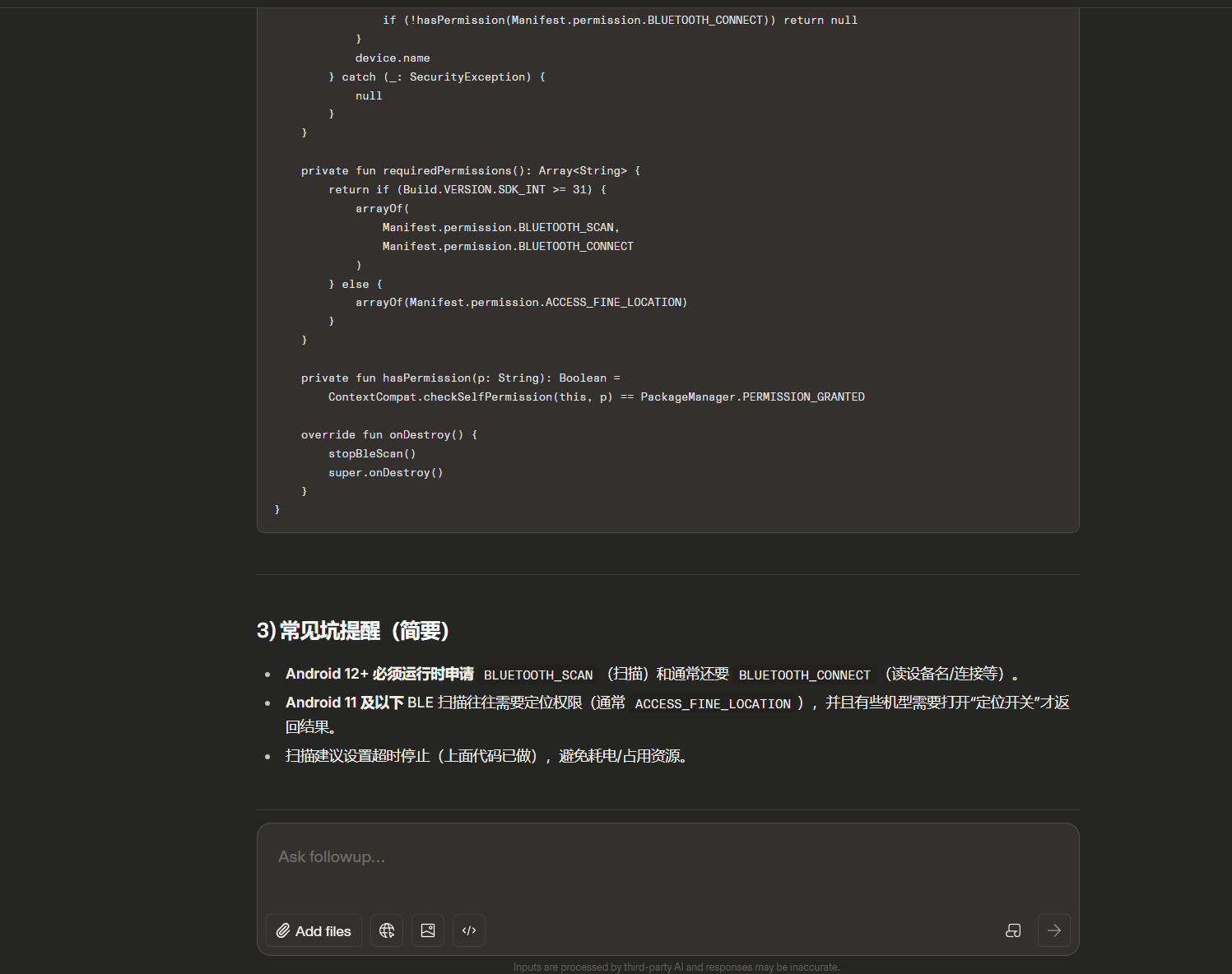
GLM 收到这个提示词后,大概率会给出一个相对简短的回答。它不会像 Claude 那样帮你做决策,也不会像 GPT 那样长篇大论讲原理。它会把"扫描功能"的基本代码写出来,但可能在语言选择(Java还是Kotlin)、API版本(经典蓝牙还是BLE)上出现不确定,甚至给出一个略显"保守"的通用模板。
GLM的典型行为特征:
|
行为 |
表现 |
|
等待指令 |
提示词模糊时输出偏保守 |
|
不会自作主张 |
你没说的它不做 |
|
简洁直接 |
少废话,直奔代码 |
|
输出风格 |
取决于你的提示词质量——好的提示词给出顶级结果,差的提示词给出平庸结果 |
GLM不会去扩展别的内容,给出的内容非常精简,不会像 Claude 那样帮你做决策,也不会像 GPT 那样长篇大论讲原理。它会把"扫描功能"的基本代码写出来。
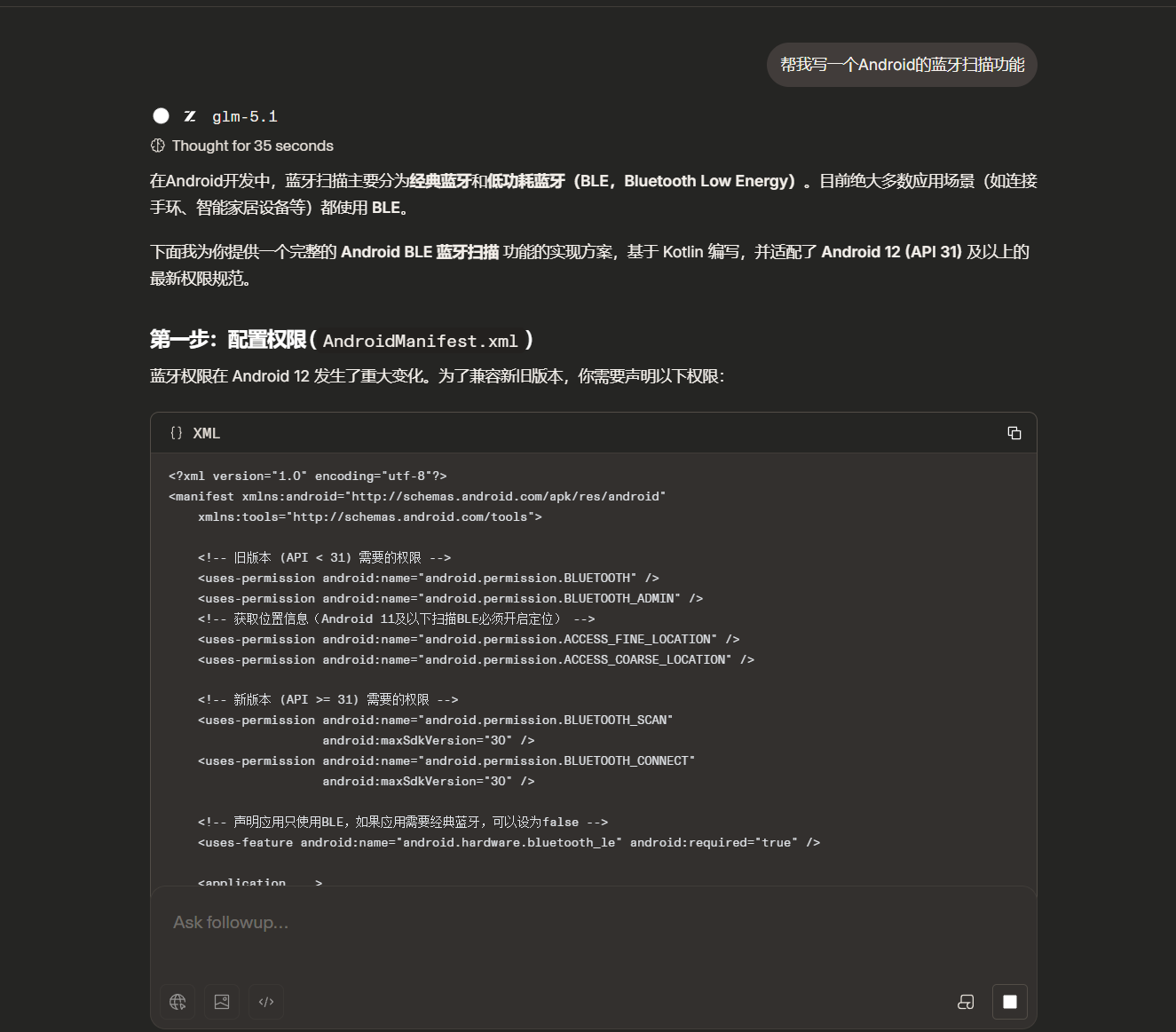
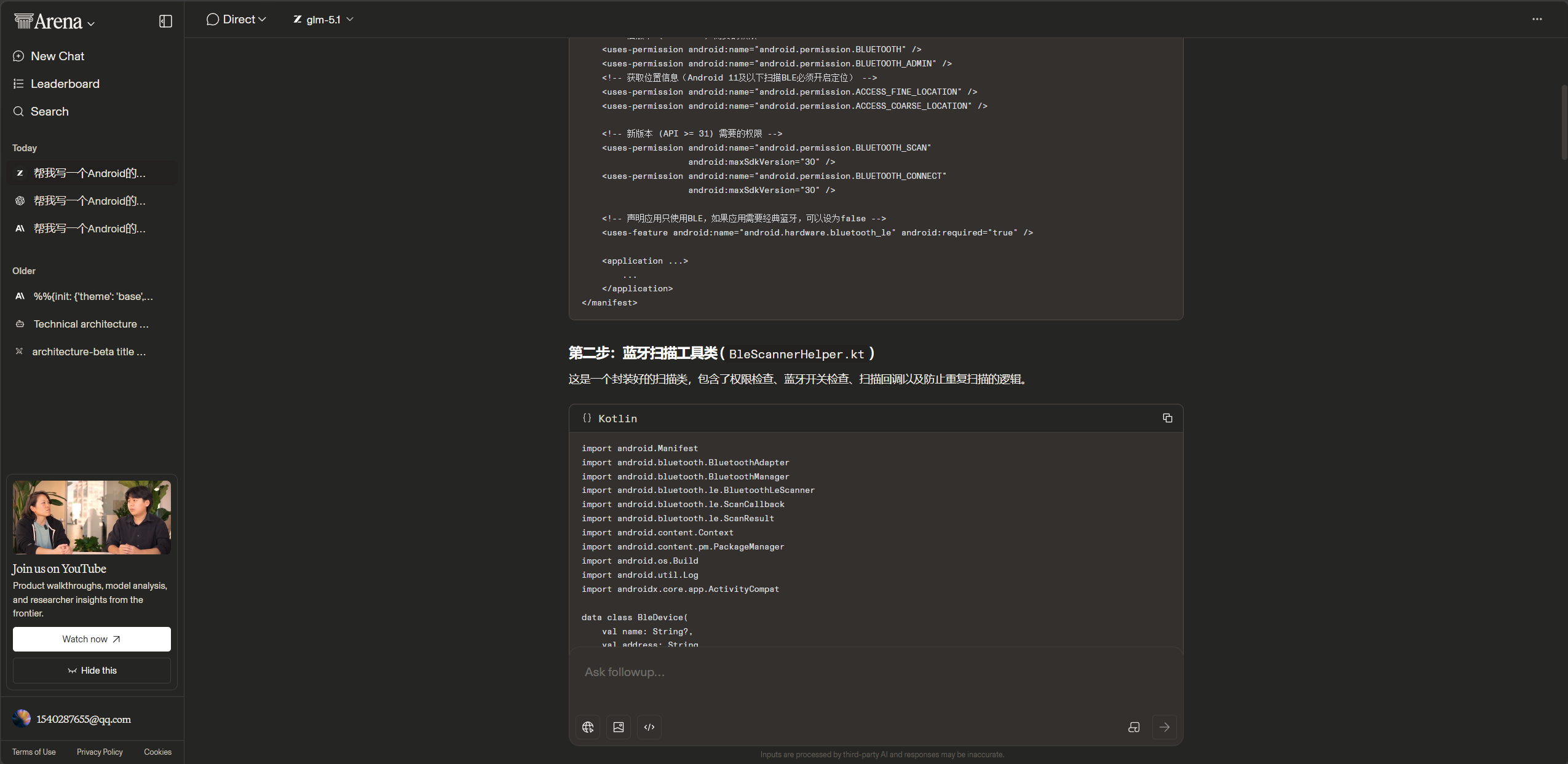
在日常开发中,我一般是通过Claude code集成GLM进行开发,GLM的令行禁止能力太过于强大,能够明确完成我们”要求“的内容,并不是想Claude 和 GPT一样给我们扩展甚至建议。
同时使用 Claude Code 这种动本地文件的工具,最怕 AI“自作主张”。它多改一行代码,你就得花时间去查去改。所以在这种时候,GLM 这种“你说一它不二”、绝不乱发挥的特性,就不是可有可无的亮点了,而是必须得有的保命符。
我们要求规范的越好,执行越完美。
三大模型在自主性与指令遵循上的分布 :
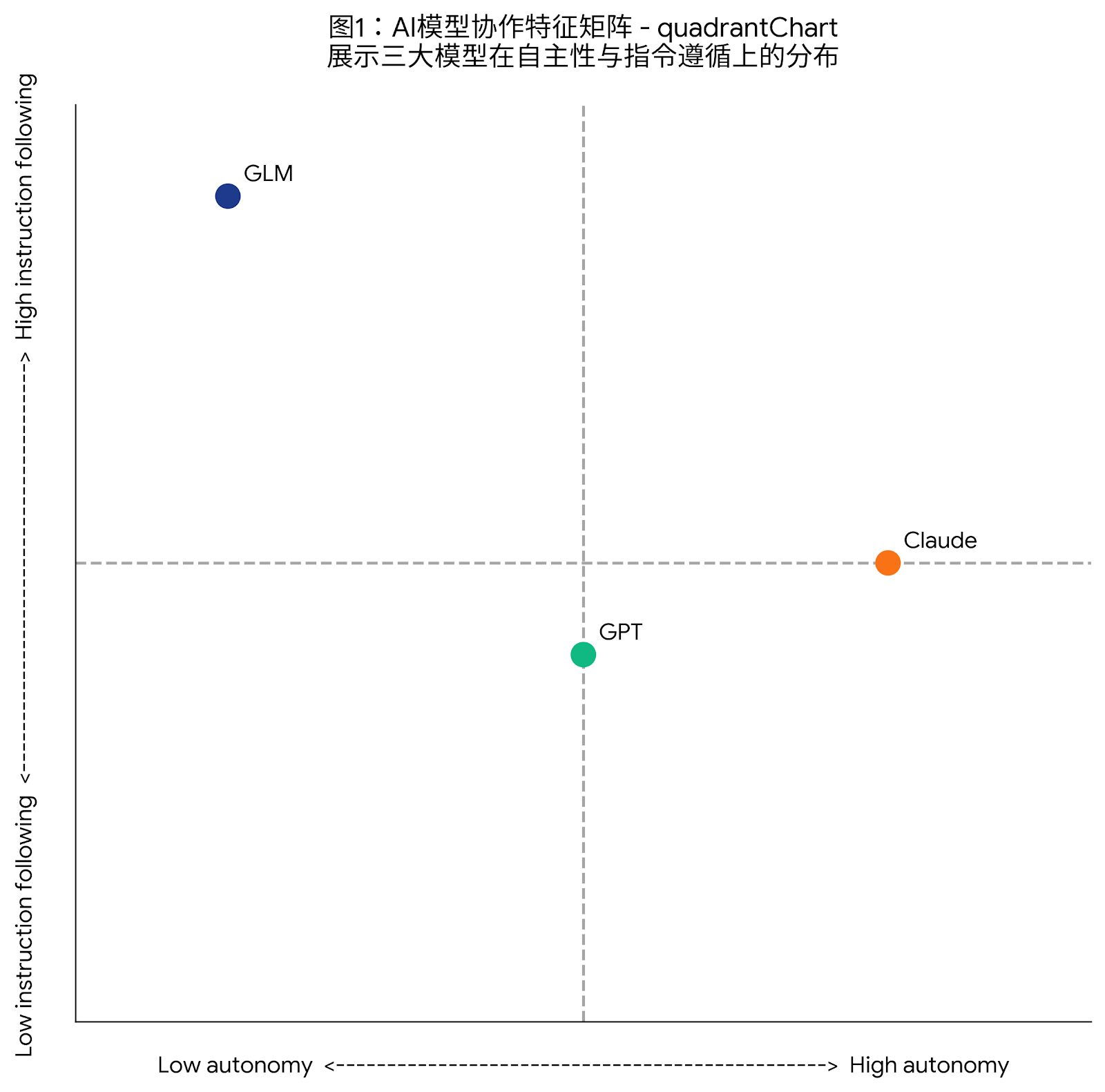
图1:AI模型协作特征矩阵 - quadrantChart - 展示三大模型在自主性与指令遵循上的分布
三、核心方法论——规则收敛,释放GLM战斗力
3.1 两大核心认知
认知一:作用域越小,AI越有力。
这是一个通用规律。当你把AI的工作范围收窄到某个特定领域时,它的输出质量会显著提升。这不是GLM独有的特性,但GLM在这个维度上的收益最为明显。
认知二:规则越多,AI越容易产生幻觉——但GLM是例外。
通常情况下,过多的规则约束会让AI模型产生混乱和幻觉。但GLM的"令行禁止"能力是目前最强的。当你在同样的上下文中用规则去限定工作时,GLM执行到位的能力更强,反而比Claude系列有更好的表现。
简而言之:给GLM的约束越多越具体,它的输出质量越高,这与直觉相反,但已被实践反复验证。
3.2 GLM高效协作公式
基于以上认知,我总结出一套GLM协作公式:
高质量的提示词 + 收敛的作用域 + 明确的规则文档 = GLM的最佳表现区间
图2:GLM高效协作流程图 - flowchart - 展示从模糊需求到高质量输出的完整收敛过程
四、实战场景教学
4.1 场景一:编写一个Android无障碍服务
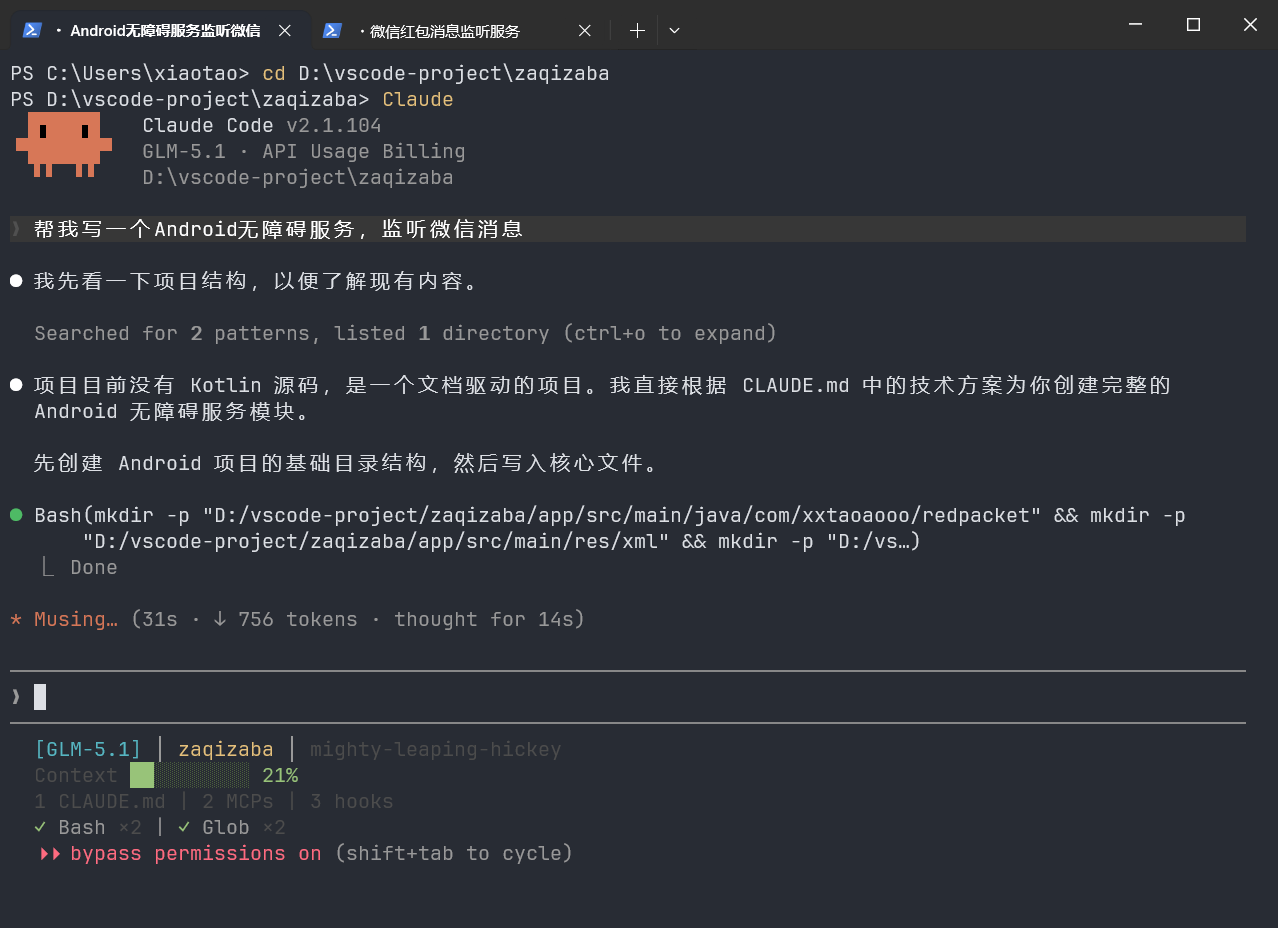
❌ 低效写法(简单提示词):
帮我写一个Android无障碍服务,监听微信消息这种写法对GLM来说太模糊了。它不知道你要监听什么类型的消息、用什么方式存储、UI怎么展示,结果大概率是一个泛泛的模板代码。
可以看到简单提示词的GLM已经开始了编码,可以很肯定的说,生成代码绝对只能作为参考,无法直接使用。
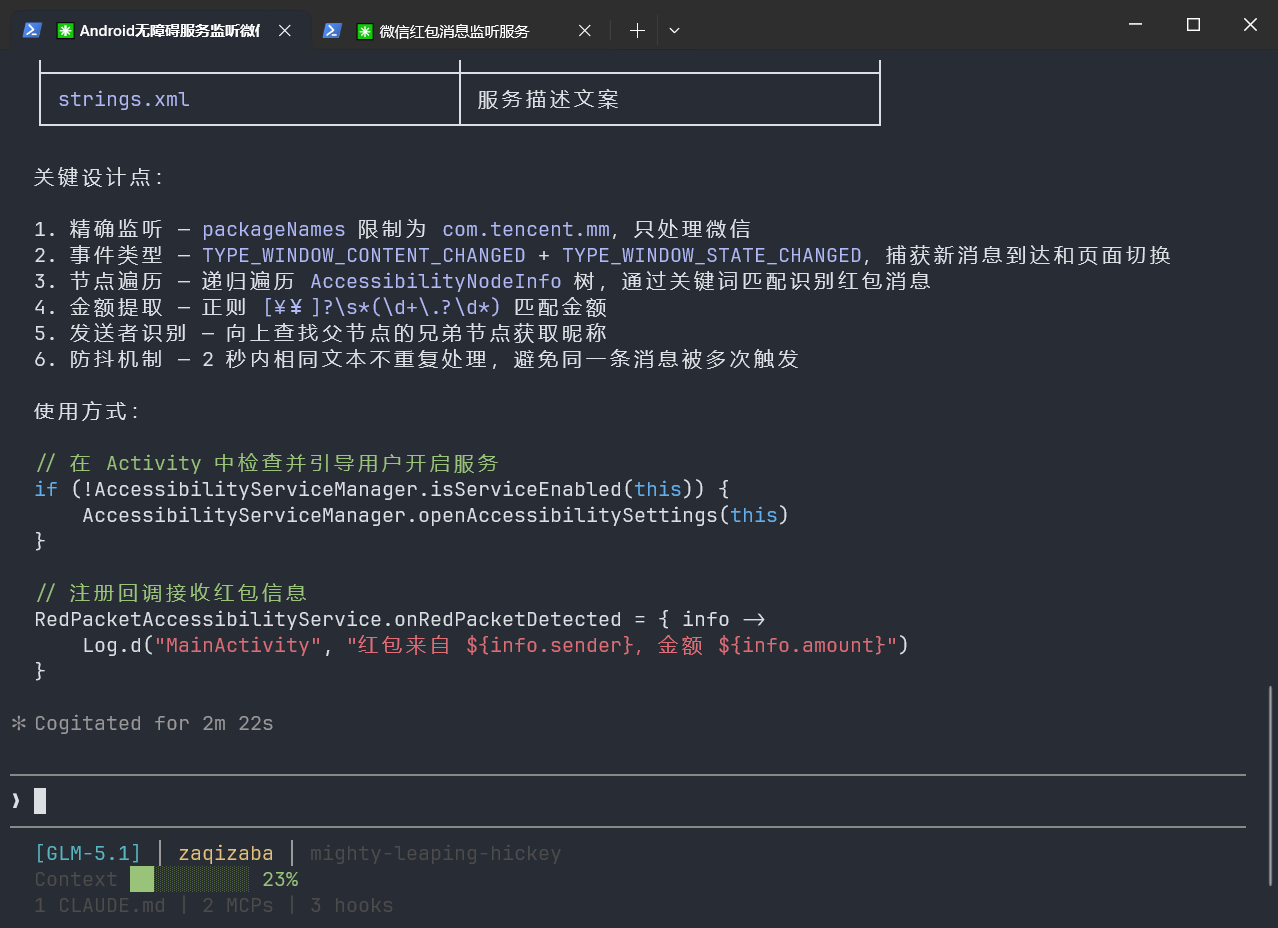
✅ 高效写法(收敛提示词):
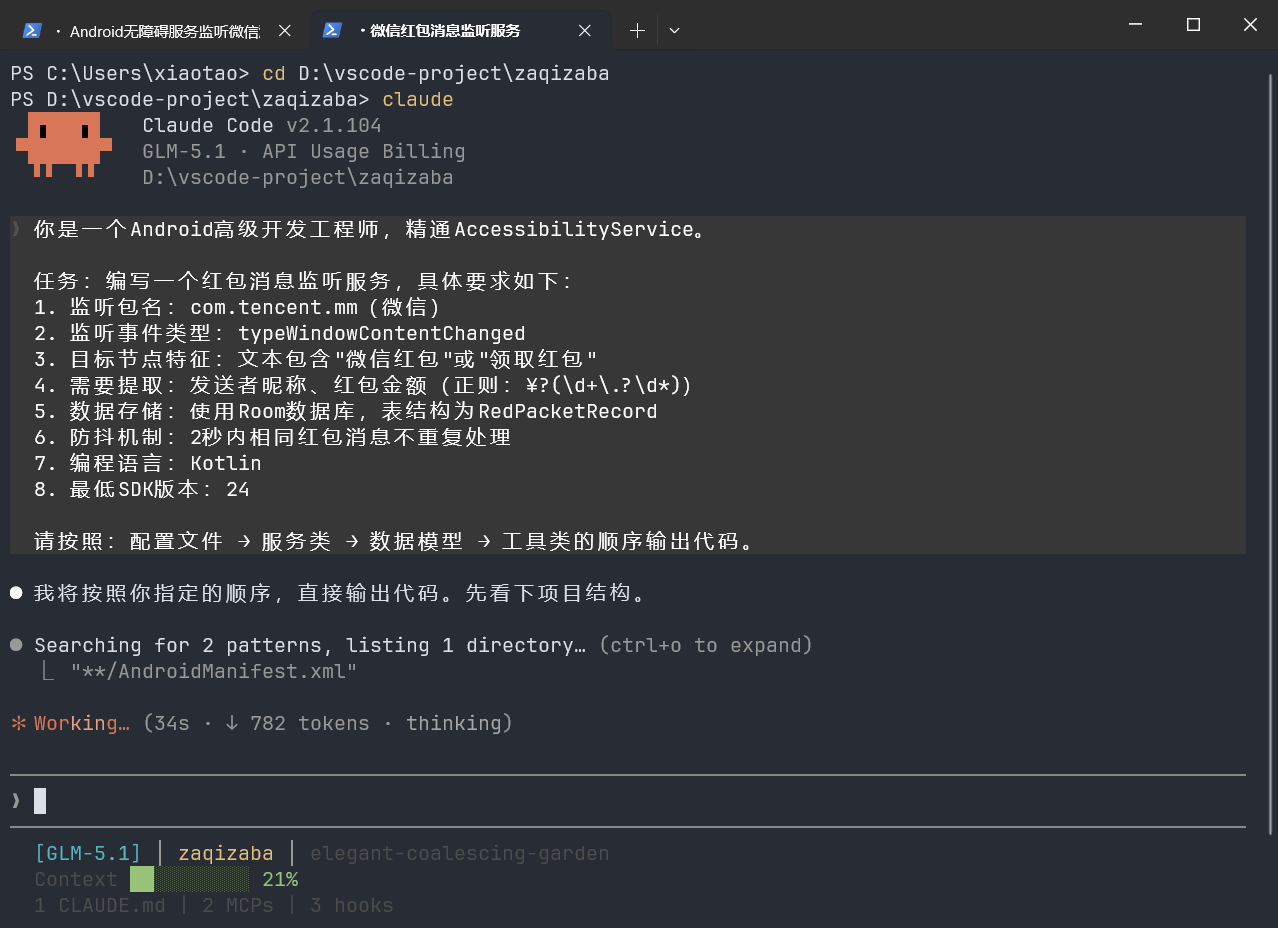
你是一个Android高级开发工程师,精通AccessibilityService。
任务:编写一个红包消息监听服务,具体要求如下:
1. 监听包名:com.tencent.mm(微信)
2. 监听事件类型:typeWindowContentChanged
3. 目标节点特征:文本包含"微信红包"或"领取红包"
4. 需要提取:发送者昵称、红包金额(正则:¥?(\d+\.?\d*))
5. 数据存储:使用Room数据库,表结构为RedPacketRecord
6. 防抖机制:2秒内相同红包消息不重复处理
7. 编程语言:Kotlin
8. 最低SDK版本:24
请按照:配置文件 → 服务类 → 数据模型 → 工具类的顺序输出代码。收敛提示词后的GLM仿佛被设定好了,从哪儿一步开始,到哪一步的结束,甚至智能体工作流里面都已经列好了步骤,这样生成的内容也让人放心。
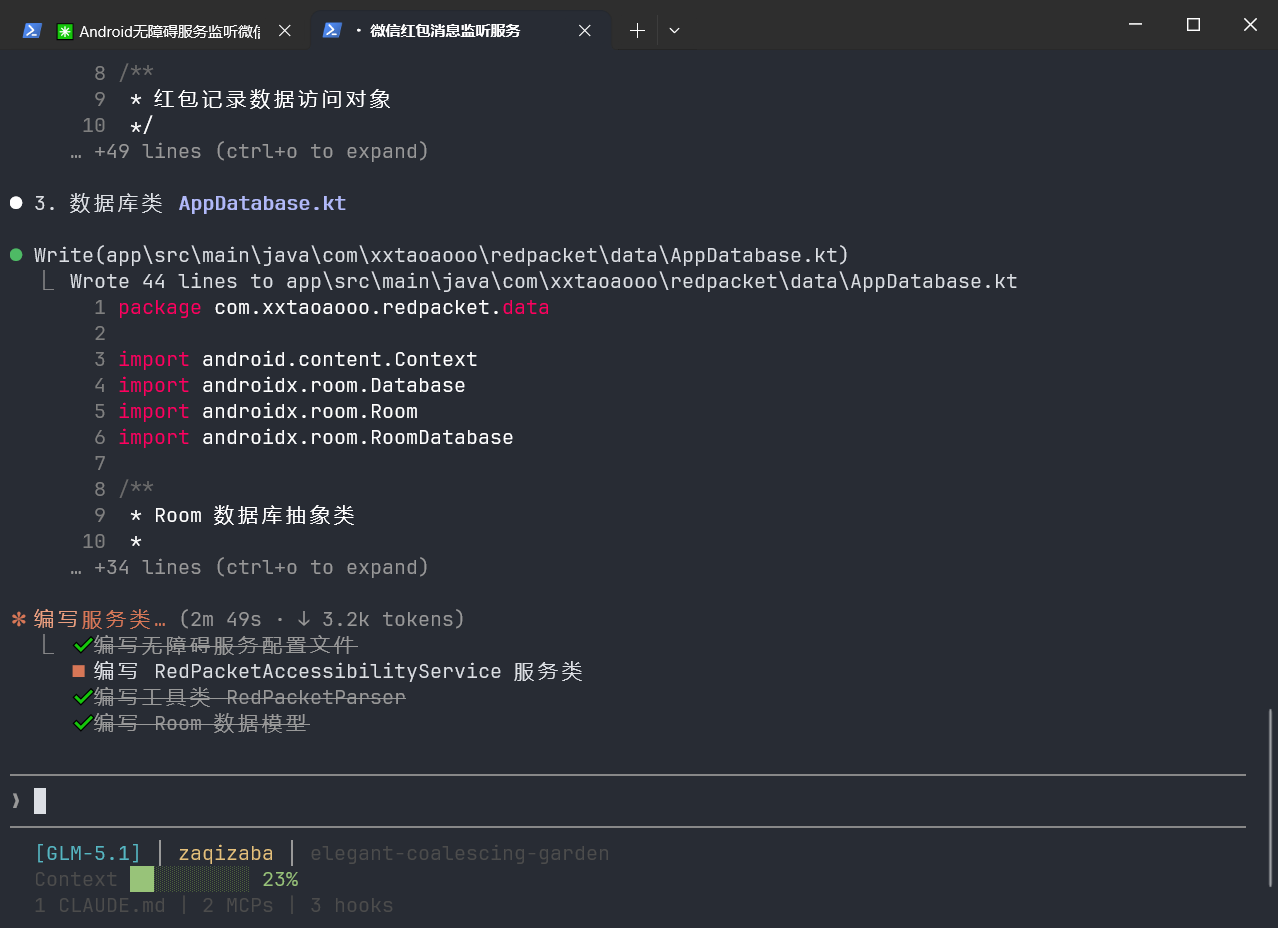
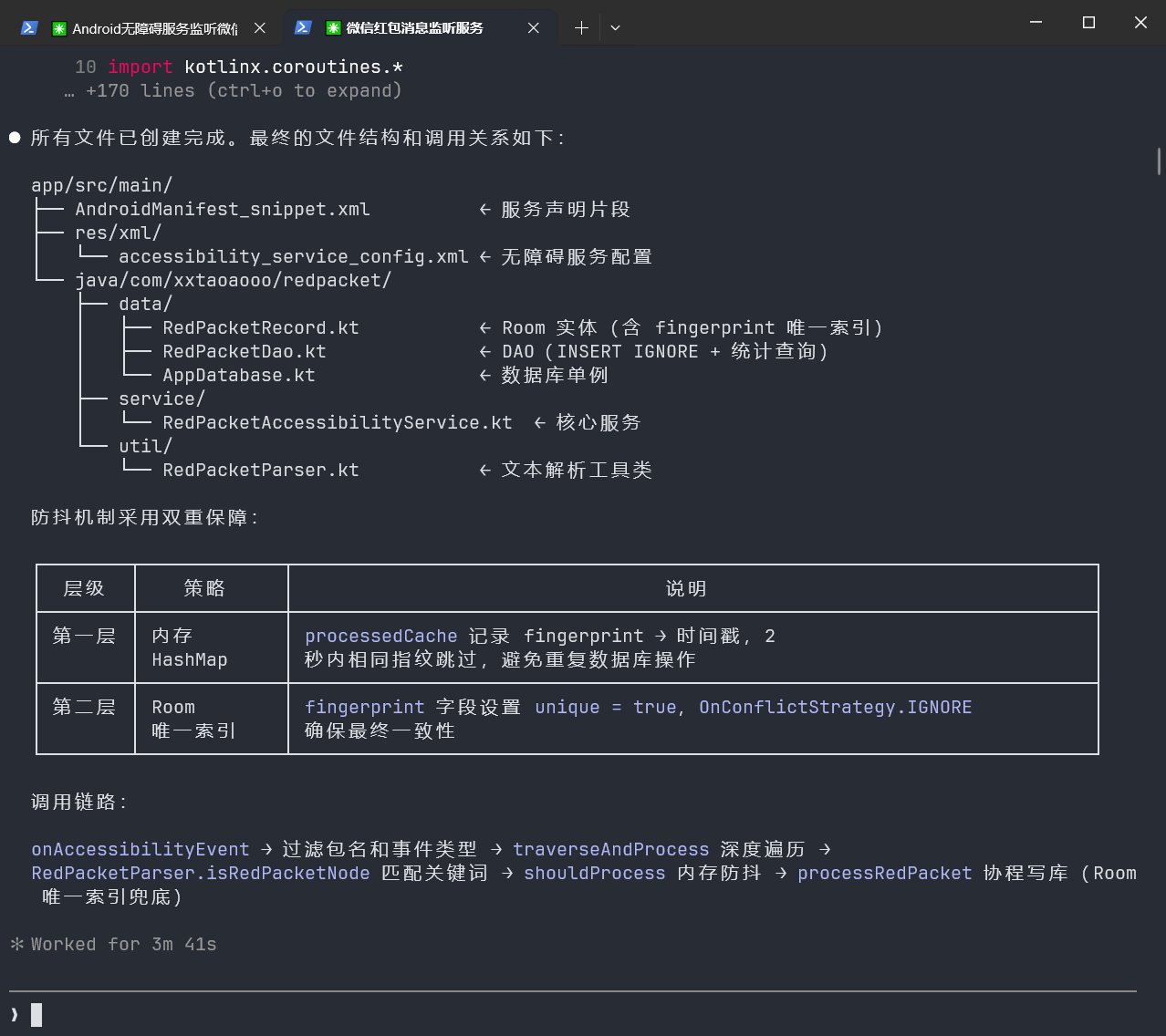
效果对比:
|
对比项 |
简单提示词 |
收敛提示词 |
|
代码完整度 |
模板代码,缺少细节 |
完整可运行的模块代码 |
|
是否符合需求 |
部分符合 |
精确匹配 |
|
需要修改次数 |
3-5轮对话 |
0-1轮微调 |
4.2 场景二:生成Rokid眼镜通信协议代码
❌ 低效写法:
帮我写Rokid眼镜的蓝牙通信代码GLM面对这种提示词,可能需要花很长时间去"搜索"相关知识,而且大概率会生成一个通用的蓝牙通信模板,和Rokid的实际SDK差距很大。
这里我项目中附带了实际SDK,这也是一种规则限定,GLM首先帮我们去找到真正的SDK,在进行开发。规则并没有完全限定好,导致找到错误的信息。
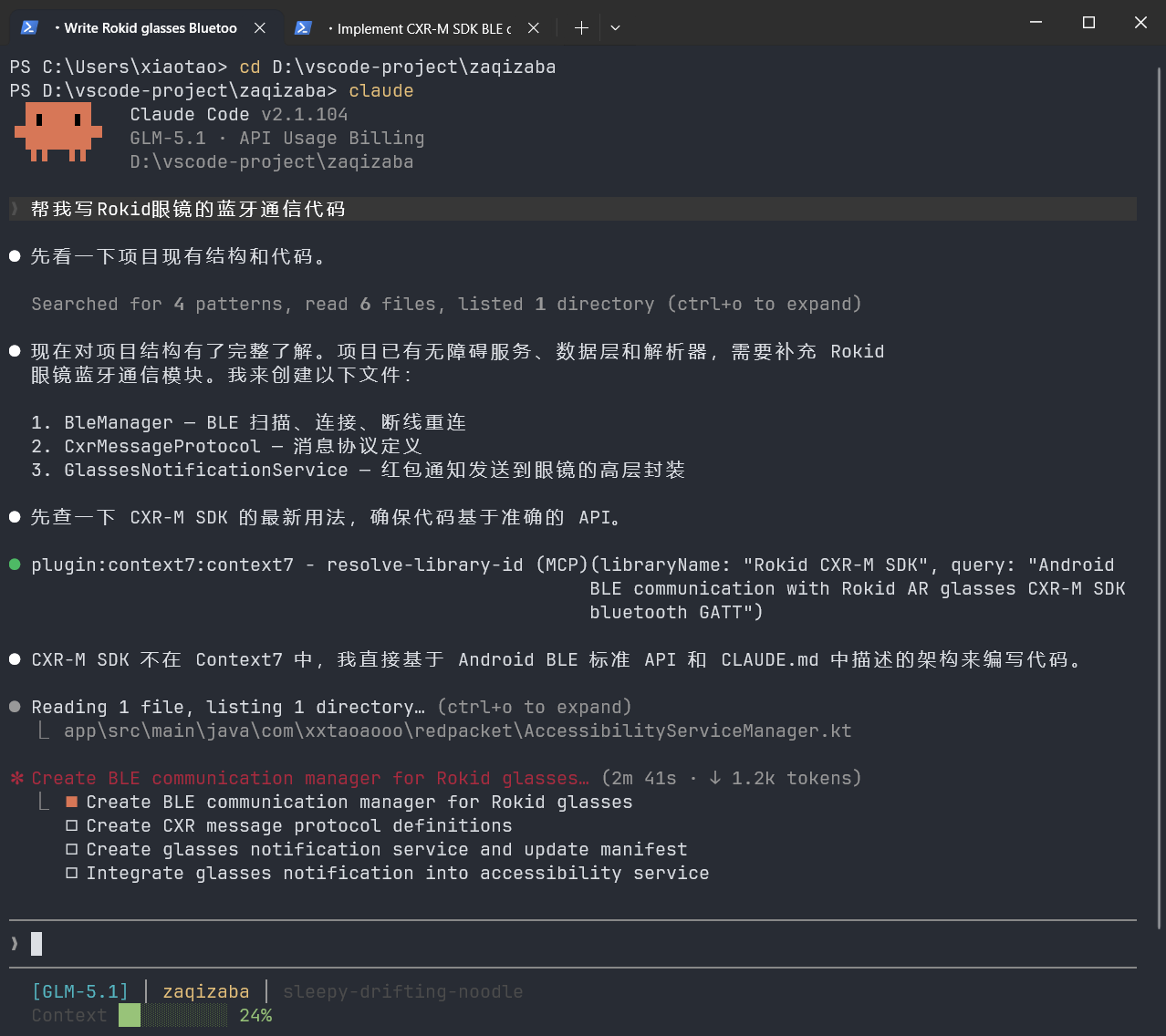
而且生成的内容还受到其他上下文影响,上下文被污染;实际开发过程中规则定的越明细、规范,效果越好。
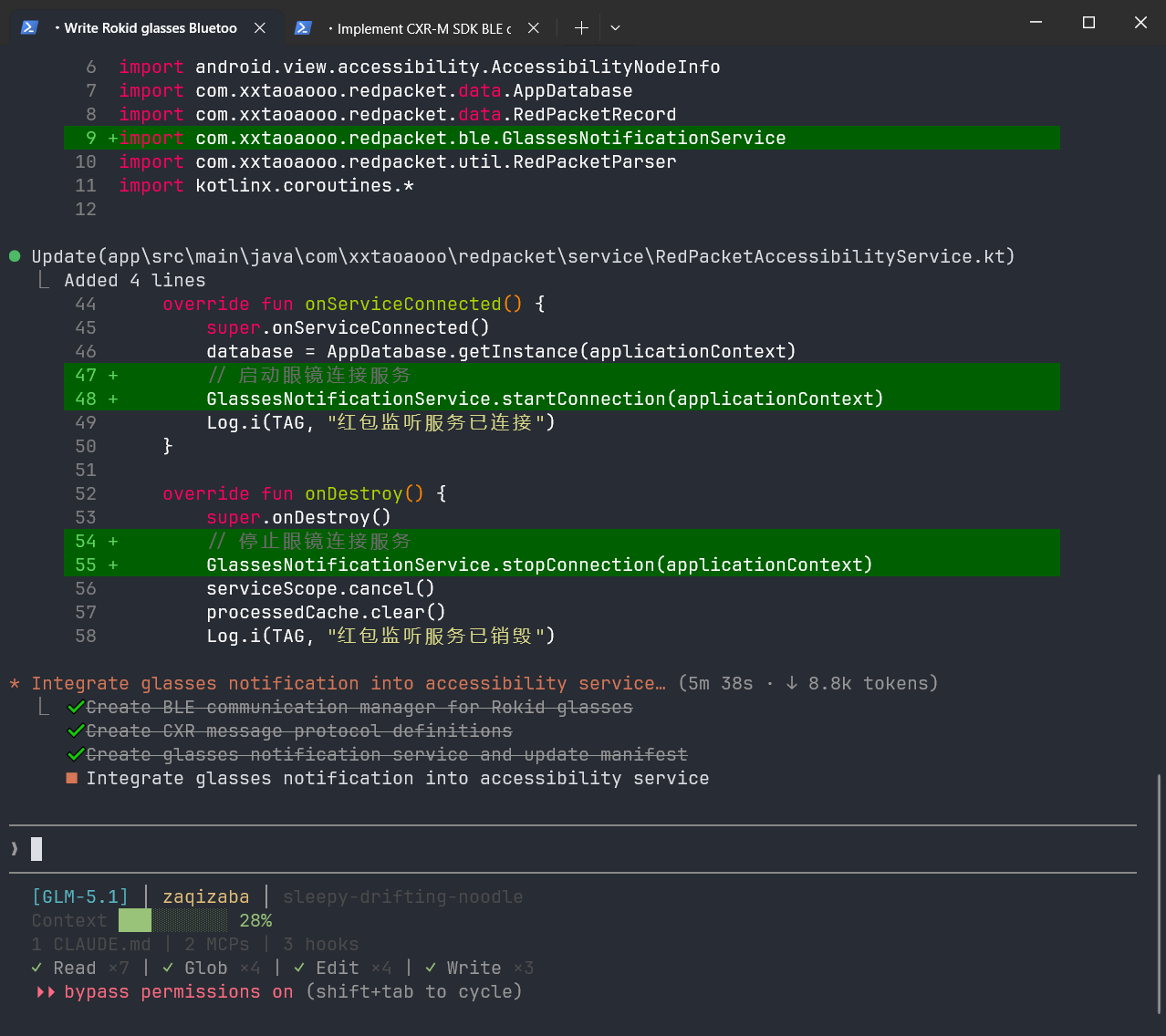
✅ 高效写法(附加规则文档):
角色:你是一位精通CXR-M SDK的Android开发者。
背景知识:
- CXR-M SDK是Rokid眼镜的移动端通信SDK
- 通过蓝牙BLE连接,服务UUID:00009100-0000-1000-8000-00805f9b34fb
- 消息格式为CxrBaseMessage,包含type和data两个字段
- data为JSON字符串
任务:实现以下功能模块
1. BLE设备扫描(过滤Rokid设备)
2. 设备连接与断线重连(指数退避策略,最大重试5次)
3. 消息发送封装(支持JSON序列化)
编码规范:
- 使用Kotlin协程处理异步操作
- 每个函数添加kdoc注释
- 错误处理使用Result<T>包装
输出格式:每个功能模块单独一个代码块,模块间用注释说明调用关系。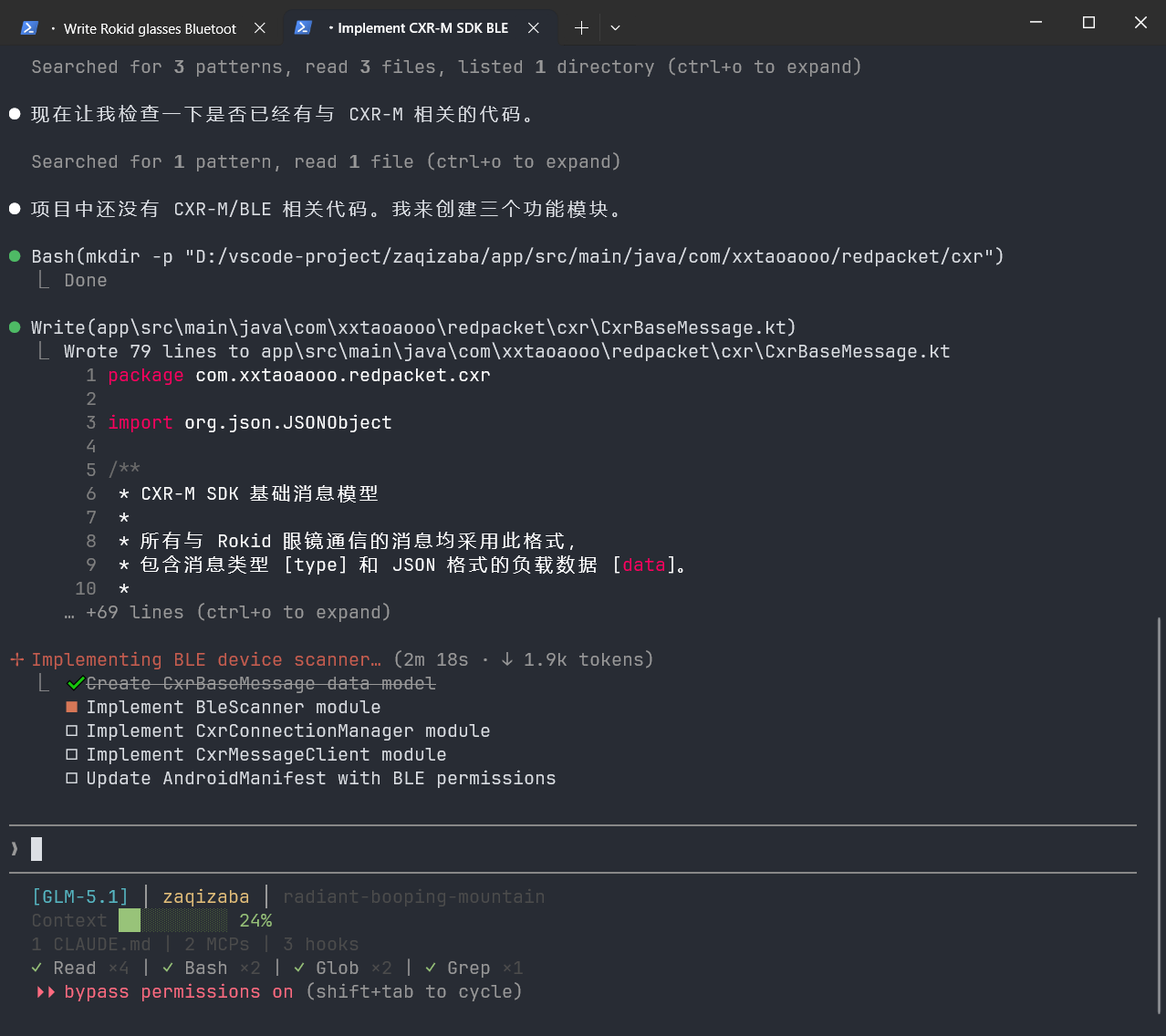
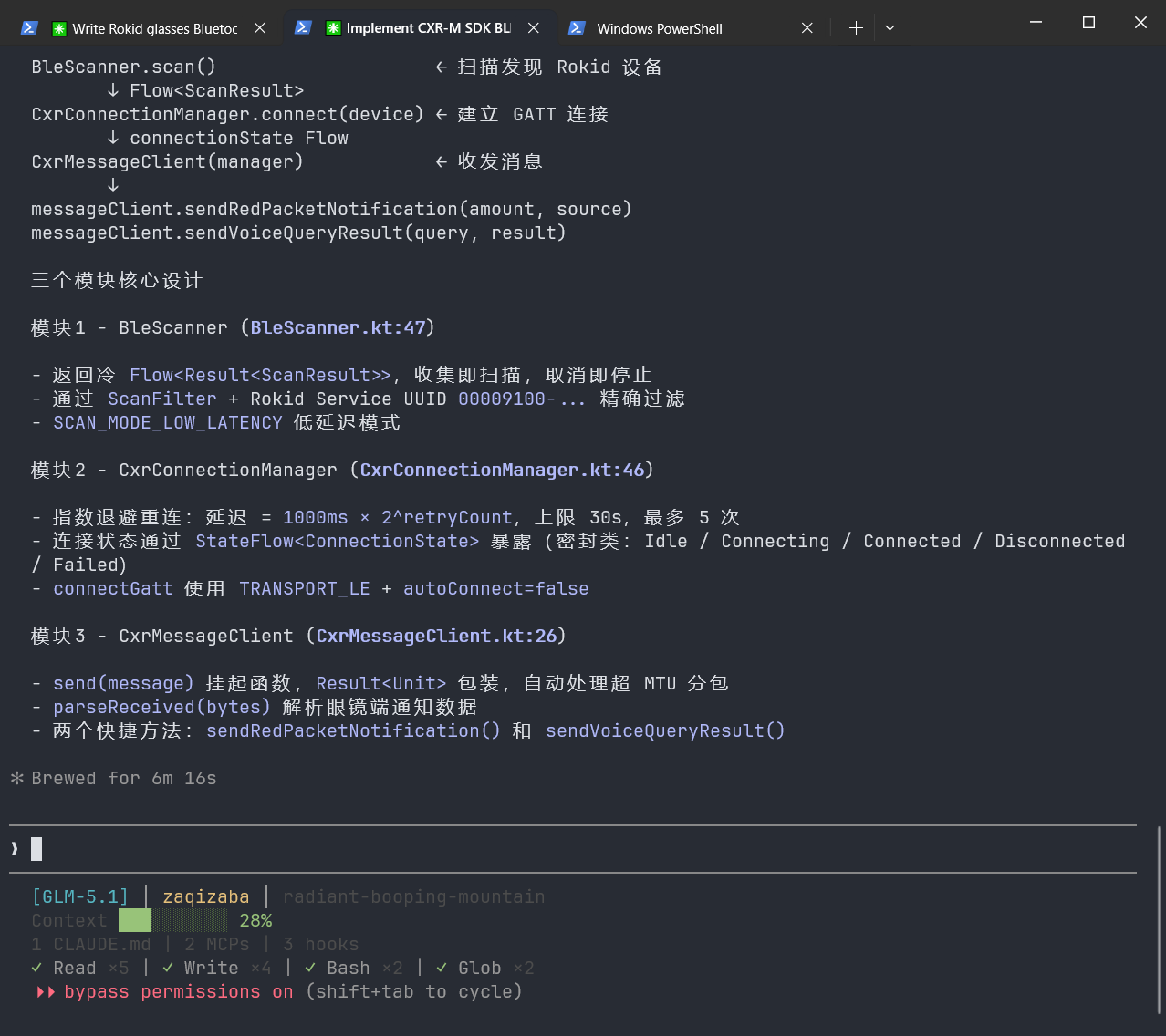
核心点评:
- 通过附加"背景知识"块,直接为GLM提供了知识锚点,避免了它在训练数据中盲目搜索
- 明确的"编码规范"和"输出格式"约束,让GLM的输出可以直接进入项目使用
- 这就是"规则收敛"的威力——你给出的信息越多,GLM的不确定性就越低
五、实践总结
5.1 GLM协作的核心心法
|
心法 |
说明 |
效果 |
|
角色锚定 |
先定义"你是谁" |
收敛知识范围 |
|
需求拆解 |
把大需求拆成编号列表 |
减少歧义 |
|
附加知识 |
主动提供背景信息 |
避免模型幻觉 |
|
格式约束 |
明确输出格式要求 |
减少返工轮次 |
|
示例引导 |
给出期望输出的样例 |
对齐预期 |
5.2 能力溢出时代的务实选择
当下的一个现实是:大部分任务的AI能力已经溢出。
这意味着,对于日常开发任务,Claude、GPT、GLM三者都能做到"及格"。在这种背景下,谁快谁好。GLM 的爽感,本质来源于"当能力及格,则快的爽"。
但如果你追求的是精确执行、严格遵循规则、可控的输出质量,那么给GLM一份完善的规则文档,它的表现会让你重新认识这个模型。
六、参考资料
🌟 嗨,我是Xxtaoaooo!
⚙️ 【点赞】让更多同行看见深度干货
🚀 【关注】持续获取行业前沿技术与经验
🧩 【评论】分享你的实战经验或技术困惑作为一名技术实践者,我始终相信:
每一次技术探讨都是认知升级的契机,期待在评论区与你碰撞灵感火花🔥

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)