自动驾驶中VLM与VLA的核心区别:一文看懂底层逻辑

「一文理清自动驾驶架构的底层逻辑」
目录
如今在自动驾驶领域,"大模型"、"端到端"、"VLM"、"VLA"等词汇满天飞,很多人甚至将VLM和VLA混为一谈。
事实上,这两者虽然只有一字之差,但在自动驾驶系统架构中的地位和作用却有着天壤之别。
简单来说,VLM(视觉语言模型)能看能说但不能直接输出动作,在架构里只是充当"慢思考"的辅助角色;
而VLA(视觉-语言-动作模型)才是真正把感知、理解、决策统一到一个模型里的一段式端到端方案。
本文将沿着"规则系统→端到端+VLM→VLA"这条技术演进路线,结合最新的行业案例,为你理清自动驾驶架构的底层逻辑。
01 第一阶段:规则系统时代——精密但僵化的"老司机"
在2023年之前,行业主流的智驾系统基本都是基于规则的模块化架构。工程师们将驾驶任务拆解为感知、预测、规划和控制四个独立环节,每个环节由专门的算法模块负责。这种结构虽然清晰、可调试,但在面对突发状况(业内称为"长尾场景")时,往往会因为规则覆盖不足而表现得非常僵化 。
举个例子:当车辆遇到路边一个形态奇特的充气广告人,或者地面上一摊反光的水渍时,传统的感知算法可能无法将其归入任何预定义的标签类别(行人、车辆、障碍物……),导致系统不知所措——要么急刹,要么无视。这就是规则系统的根本瓶颈:它只能处理工程师预见到的情况,而现实世界的复杂性远超任何规则库的覆盖范围。
02 第二阶段:VLM登场——能看能说的"军师"
为了打破感知的"天花板",VLM(Vision-Language Model,视觉语言模型)被引入了自动驾驶系统。VLM通过在海量互联网数据(图文对、视频等)上进行预训练,获得了一种近乎于人类的常识推理能力。它不再仅仅是将像素点分类,而是能够理解场景中的深层语义逻辑 。
比如,VLM能识别出前方车辆开启的双闪灯意味着故障停车,并建议后车进行绕行;它能看懂路边"前方施工,请绕行"的文字告示牌;它甚至能根据天气、光线等环境因素,对驾驶策略给出更合理的建议。这些能力是传统感知算法望尘莫及的。
VLM的局限性:行动鸿沟与实时性短板
尽管VLM在环境理解和语义推理方面表现优异,但它在直接驱动车辆运行上依旧存在着先天不足:
行动鸿沟(Action Gap):目前的VLM大多是为文本生成而设计的,其输出结果一般是自然语言,比如"我看到前方有行人正在过马路,我应该减速让行"。然而,车辆底盘需要的是具体的制动压力(比如施加多少牛顿的制动力)、转向扭矩或者是精确到厘米的行驶轨迹点。这种从文本描述到物理操作的转换,需要一个额外的"翻译模块",而每一次翻译都可能导致信息在传递中丢失或失真 。
实时性差:主流的VLM通常拥有数十亿甚至数百亿的参数量,在处理高分辨率图像并生成连贯文本时,其推理延迟可能达到数百毫秒甚至秒级。而自动驾驶系统每秒需要进行数十次决策计算,VLM的响应速度远远无法满足这种实时控制需求 。
因此,在2024年主流的"端到端+VLM"双系统架构中,两者各司其职:端到端模型负责快速驾驶决策(系统1:快思考),而VLM模型则作为旁路的辅助插件,负责更高层次的语义理解和推理(系统2:慢思考)。理想汽车是这一架构的率先量产者 。
这种"双系统"架构的灵感来源于诺贝尔经济学奖得主丹尼尔·卡尼曼提出的认知双系统理论:系统1负责快速、直觉性的判断,系统2负责缓慢、深思熟虑的推理。
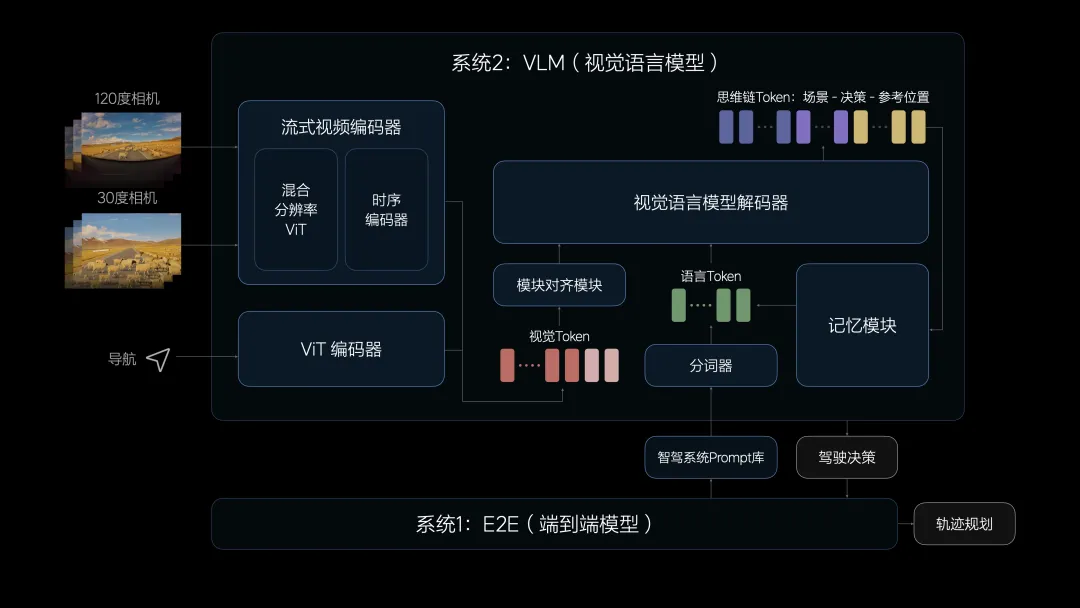
图 | 理想汽车此前量产的双系统智驾架构示意。系统1为E2E(端到端模型),负责快速驾驶决策;系统2为VLM(视觉语言模型),负责场景理解和慢思考推理。两个系统协同工作,但VLM只能提供建议,无法直接输出驾驶动作。(来源:极客公园)然而,这种架构的问题在于:空间理解、语言理解和行为决策仍然分散在不同模型中,信息在模型间传递时存在损失,对齐效率不够理想。VLM终究只是一个"军师",它能出谋划策,但无法亲自上阵。
03 第三阶段:VLA的诞生——认知与执行的物理融合
为了解决VLM"脑子懂了"但"手脚不协调"的问题,研究者们开始寻求一种能够将理解与行动深度耦合的新技术路径。这就是VLA(Vision-Language-Action,视觉-语言-动作模型)。
VLA的出现,本质上是将车辆的认知系统与执行系统进行了一次彻底的物理融合。它不再把驾驶看作是先理解场景再执行动作的两个独立步骤,而是将其视为一个统一的、从传感器输入到执行器输出的一段式端到端学习过程 。
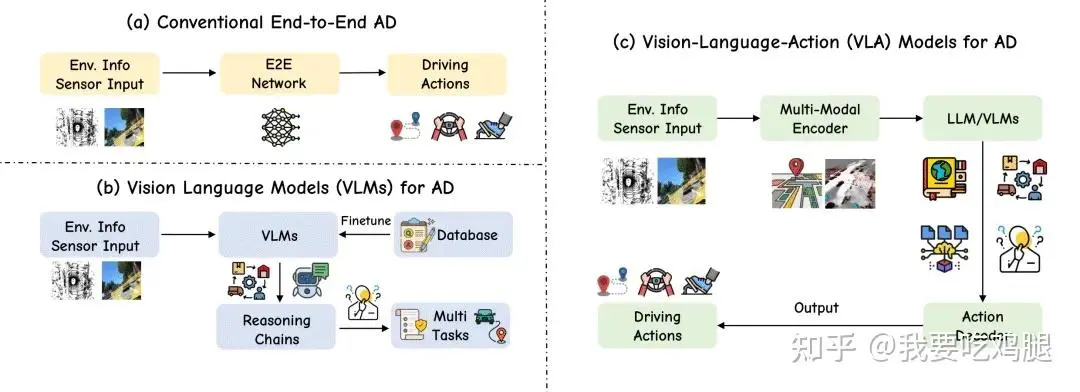
图 | 三种自动驾驶架构的对比。(a) 传统端到端自动驾驶:传感器输入→E2E网络→驾驶动作;(b) VLM用于自动驾驶:传感器输入→VLM→数据库/推理链/多任务,但不直接输出动作;(c) VLA用于自动驾驶:传感器输入→多模态编码器→LLM/VLMs→动作解码器→驾驶动作,实现了从感知到行动的完整闭环。
VLA的关键技术突破
动作标记化(Action Tokenization):VLA的核心创新之一,是受谷歌机器人模型RT-2的启发,将车辆的转向、加速、制动等驾驶动作转化为一种特殊的"词汇表"(Token)。在这种设定下,生成一段平滑的变道轨迹,在模型看来与写出一个句子并无本质区别——都是在一个统一的词汇空间中进行序列预测 。
统一的高维特征空间:在VLA框架下,视觉特征、语言指令和驾驶动作被编码到同一个高维特征空间中进行交互。这意味着模型在学习如何识别红绿灯的同时,也在学习遇到红灯时应该如何调节刹车踏板。感知与行动不再是两个割裂的任务,而是同一个学习过程的两面。
连续轨迹生成:为了解决离散动作标记可能导致的车辆行驶抖动问题,VLA引入了扩散模型(Diffusion)或并行解码技术来生成平滑的连续轨迹。例如,理想的MindVLA-o1就采用了Discrete Diffusion(离散扩散),通过多步迭代去噪,将语义层面的动作标记转化为经过优化的平滑轨迹;小鹏的VLA 2.0则更为激进,直接从视觉信号生成连续控制信号,彻底跳过了语言层 。
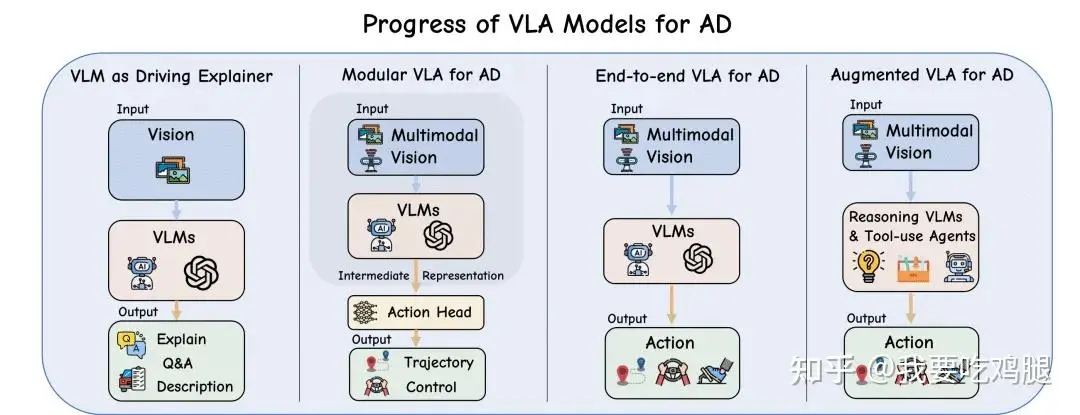
图 | VLA在自动驾驶中的演进路线。从早期的VLM作为驾驶解释器(VLM as Driving Explainer),到模块化VLA(Modular VLA for AD),再到端到端VLA(End-to-end VLA for AD),最终发展为增强型VLA(Augmented VLA for AD)。每一步都在缩小"理解"与"行动"之间的鸿沟。
04 VLM与VLA的核心区别对比总结
通过上述的演进脉络,我们可以清晰地总结出VLM与VLA在自动驾驶中的核心区别:

从行业落地来看,2026年3月,小鹏VLA 2.0(去语言层的纯视觉端到端路线)与理想MindVLA-o1(保留语言层的原生多模态统一训练路线)相继发布。
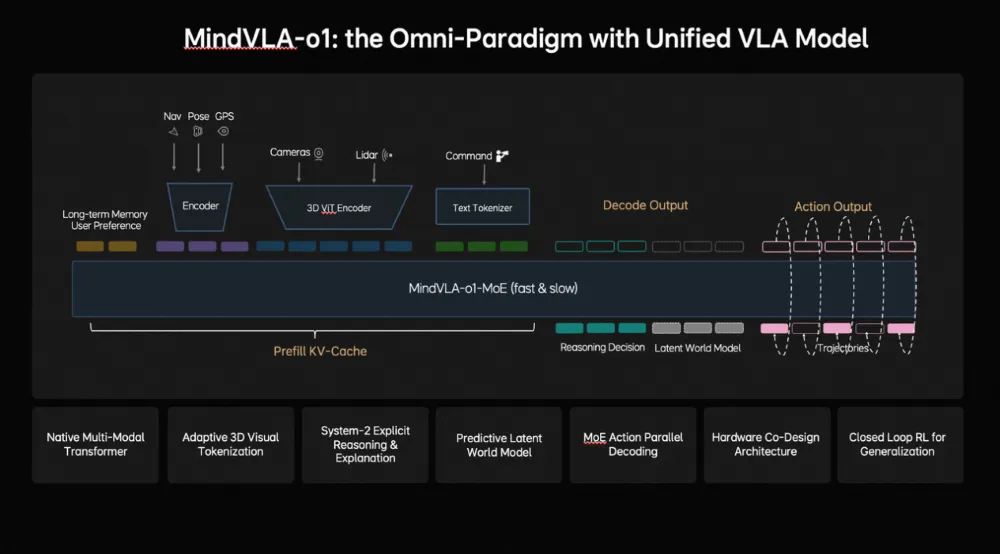

图 | 小鹏VLA2.0与理想MindVLA-o1。
虽然两者在具体架构上存在分歧——小鹏认为语言层是多余的延迟来源,理想认为语言层是不可或缺的推理基础——但它们都标志着自动驾驶正从"端到端+VLM"的双系统时代,迈向了VLA大一统模型时代。
05 结语:通向通用具身智能的必由之路
VLM与VLA的区别,不仅仅是技术名词的更迭,更是自动驾驶底层逻辑的深刻变革。VLM赋予了汽车理解世界的能力,而VLA则赋予了汽车改变世界的能力。
从"规则系统"到"端到端+VLM"再到"VLA",自动驾驶的技术演进路线清晰地指向一个方向:让机器像人一样,在感知、理解和行动之间建立无缝的连接。VLA不仅是自动驾驶从辅助驾驶向全自动驾驶跨越的关键技术,更是通向通用具身智能(如人形机器人)的必由之路。理想汽车在发布MindVLA-o1时就明确表示,同一套VLA模型可以迁移到机器人控制,用同一套基础模型、技术范式和数据系统训练不同形态的物理智能体 。
随着技术的不断演进,我们有理由相信,未来的智能汽车将不仅仅是一个交通工具,更是一个真正具备物理世界行动能力的智能体。
参考资料
[1] 已有VLM,自动驾驶为什么还要探索VLA? 知乎, 2025.
[2] 詹锟讲理想下一代自动驾驶基础模型MindVLA-o1. 知乎, 2026-03.
[3] 小鹏分享物理AI涌现成果:发布第二代VLA、Robotaxi、全新一代图灵芯片. OFweek新能源汽车网, 2026-03-03.
[4] 理想MindVLA-o1基础模型相比上一代有哪些变化 ,与小鹏VLA 2.0有什么不同? 第一电动, 2026-03.
[5] 理想汽车发布下一代自动驾驶基础模型MindVLA-o1. 央视网, 2026-03-18.
[6] 小鹏和理想均押注VLA ,两者技术各有啥特色? 知乎, 2026-03.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)