第四篇:Letta(原 MemGPT)——把 OS 虚拟内存搬进 Agent
当其他框架还在纠结“向量库好还是知识图谱好”时,Letta(原 MemGPT)走了一条完全不同的路:把操作系统的虚拟内存分页机制引入 LLM 上下文管理。本文深度拆解 Letta 的三大核心创新:将记忆分为“主上下文”与“外存”的分页调度模型、Git 版本化的记忆协同机制、以及 Agent“睡眠”时的后台学习(Sleeptime)。我们将结合 9.82GB 存储成本和 74% 准确率的真实数据,分析这套 OS 隐喻的天才之处与工程代价。读完你会发现:有时候,计算机科学最经典的思想,恰恰是 AI 最需要的解药。
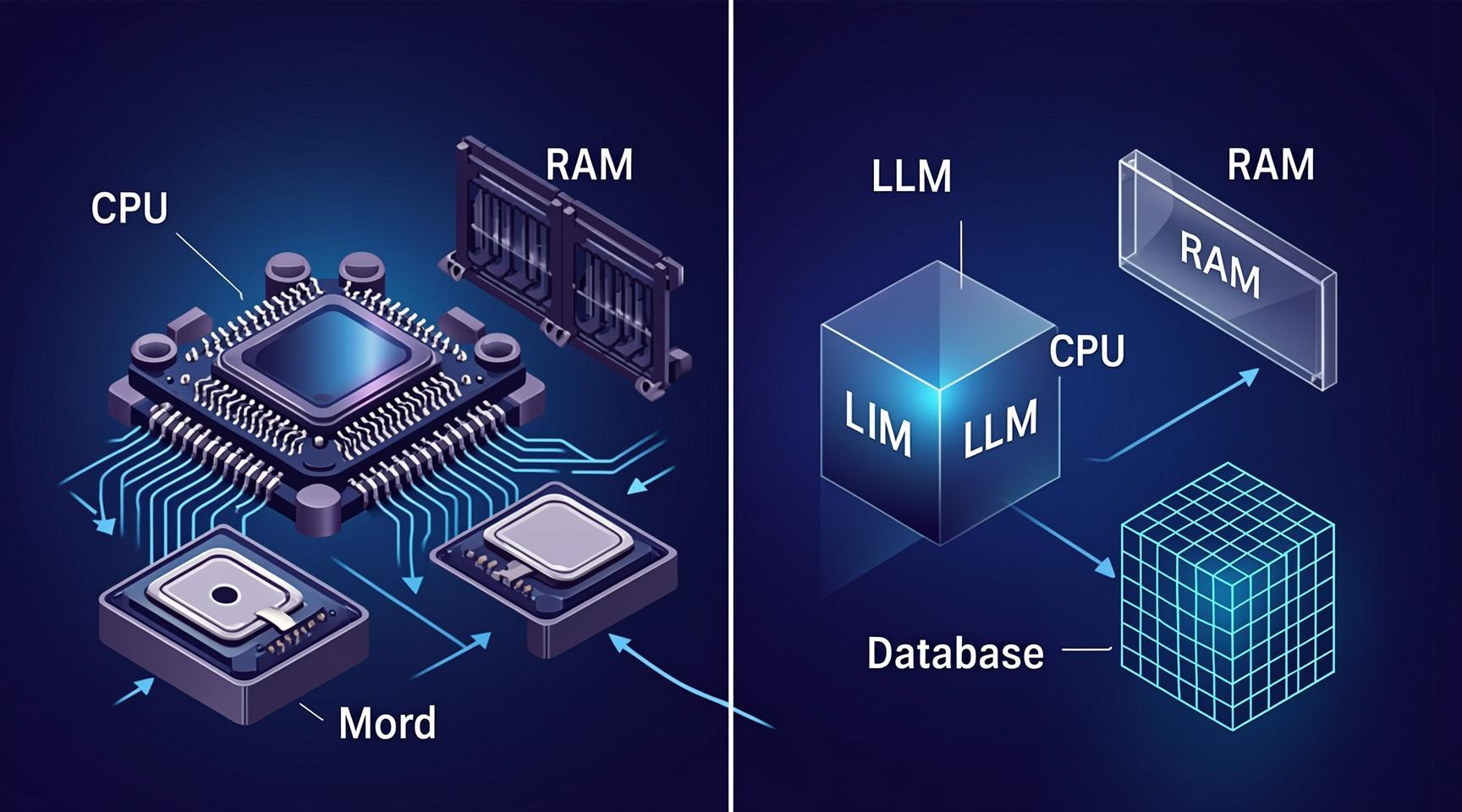
2023 年 10 月,一篇名为《MemGPT: Towards LLMs as Operating Systems》的论文在 AI 圈引起了不小的震动。论文的第一作者 Charles Packer 提出了一个大胆的类比:如果 LLM 是新的 CPU,那么它的上下文窗口就是 RAM——而 RAM 永远是不够用的。 解决方案不是造更大的 RAM,而是像操作系统一样,引入虚拟内存。
这个想法催生了 MemGPT——一个让 LLM 自主管理其自身记忆上下文的框架。2024 年底,项目更名为 Letta,并获得了 1000 万美元种子轮融资。如今,Letta 已成为 Agent 记忆领域最具“学院派”气质的存在:它不追求“开箱即用”的易用性,而是提供了一套完整的内存管理哲学。
这篇文章,我们就来深入拆解 Letta 的设计思想、核心机制与真实局限。
一、核心思想:LLM 就是一台计算机,上下文就是 RAM
Letta 的整个设计都建立在一个核心隐喻之上:
| 计算机系统 | Letta 中的对应物 |
|---|---|
| CPU(处理器) | LLM(大语言模型) |
| RAM(内存) | 上下文窗口(Context Window) |
| 磁盘(外存) | 持久化记忆存储(Vector DB / SQL) |
| 内存管理单元(MMU) | Letta 的记忆调度器 |
| 页表(Page Table) | 记忆索引与检索策略 |
| 进程(Process) | Agent 会话 |
这个类比不是简单的修辞,而是直接映射到了 Letta 的架构实现中。它的核心操作是:当上下文窗口(RAM)快满时,将一部分“不紧急”的记忆交换(swap)到外存(磁盘);当需要时,再从外存调回上下文。
这个思想解决了两个关键问题:
- 无限上下文幻觉:对 LLM 而言,它“感觉”自己能访问无限长的历史,因为记忆调度是透明的。
- 成本可控:真正塞进上下文窗口的 Token 数量是固定的,不会随对话轮次线性膨胀。
二、核心机制一:主上下文与外存的分页调度
Letta 将 Agent 的记忆分为两类:
- 主上下文(Main Context):直接注入 LLM 的 Token,包含系统提示、当前对话轮次、以及从外存调回的“热”记忆。
- 外存(External Memory):持久化存储,可以是非常简单的键值存储,也可以是向量数据库。
调度策略:Letta 在每次 LLM 调用前,会检查当前主上下文的使用量。如果接近上限,它会触发一个记忆管理函数,由 LLM 自己决定哪些内容应该被移出主上下文、移出时应该生成什么样的摘要、以及将来用什么“检索键”来找回。
这种 LLM 自主管理 的方式是 Letta 最具争议也最具特色的地方——它把记忆管理的决策权交给了 LLM 本身,而不是一套硬编码的规则。
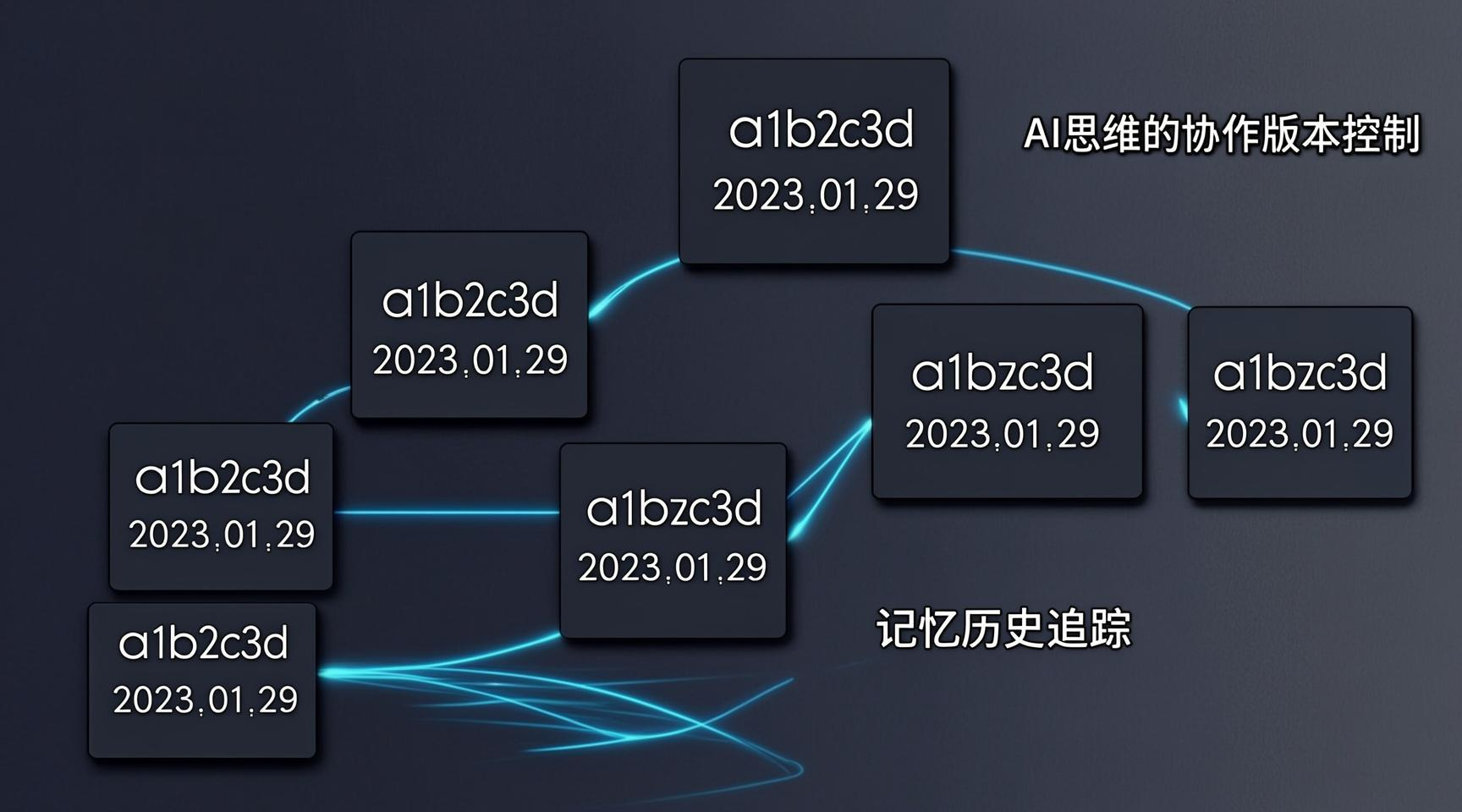
三、核心机制二:Git 版本化记忆
如果说“虚拟内存”是 Letta 的第一个 OS 灵感,那么 Git 版本控制 就是第二个。
Letta 将 Agent 的每一次记忆变更都视为一个 commit。每次 commit 包含:
- 变更了什么记忆内容(增、删、改)
- 变更的原因(由 LLM 生成一条 commit message)
- 时间戳和 Agent ID
这种设计带来了几个独特的好处:
- 可审计性:你可以完整追溯 Agent 记忆的演化历史,看它在什么时间点、因为什么原因修改了某条记忆。
- 协作可能性:多个 Agent 可以像 Git 分支一样操作同一份记忆库,出现冲突时可以 merge 或回滚。
- 版本回溯:如果 Agent 学坏了(记住了错误信息),可以像
git revert一样撤销到之前的版本。
为了直观理解记忆的版本演化,我们来看一个 Git 图例:
但代价也很明显:存储开销巨大。根据 Letta 团队公布的数据,一个典型的 Agent 会话运行 600 轮对话后,其 Git 存储库的大小约为 9.82GB。这还是在开启了压缩和垃圾回收的情况下。
对于个人开发者或小团队,9.82GB 或许可以接受。但对于需要同时运行成千上万个 Agent 的 SaaS 服务来说,每个 Agent 都附带一个近 10GB 的 Git 仓库,存储成本将变得不可承受。
四、核心机制三:Sleeptime 异步后台学习
Letta 的第三个 OS 灵感来自后台进程。它引入了一个名为 Sleeptime 的机制:
当 Agent 处于空闲状态(没有用户请求)时,它会进入“睡眠”模式,但这并非真正的休眠——而是执行一系列后台记忆优化任务:
- 整理和合并碎片化的记忆条目
- 重新计算记忆的重要性权重
- 生成更高层次的摘要,丢弃冗余细节
- 重建索引以优化检索速度
这个设计模仿了人类睡眠时记忆巩固的过程。从工程角度看,Sleeptime 把计算密集型的记忆维护工作从“在线路径”移到了“离线路径”,从而降低了用户感知的响应延迟。
五、性能数据与真实局限
Letta 官方在论文和后续博文中公布了一些关键性能数据:
- LoCoMo 基准测试准确率 74%:LoCoMo 是一个评估长对话记忆能力的基准。Letta 达到了 74%,显著优于当时的基线模型(约 60-65%)。
- 支持 600+ 轮对话不丢失关键信息:在模拟测试中,Letta Agent 能够保持 600 轮对话内的关键信息可召回。
但这些数据背后,有几个需要正视的局限:
局限 1:74% 的准确率仍然不够生产级
74% 意味着每 4 次记忆召回就有 1 次失败。对于严肃的商业应用(如金融顾问、医疗咨询),这个失败率是不可接受的。
局限 2:Git 存储成本的线性膨胀
如前所述,每个 Agent 实例的 Git 仓库会随对话轮次线性增长。虽然有压缩机制,但在多租户场景下,存储成本仍然是一个显著的门槛。
局限 3:LLM 自主管理的不可预测性
让 LLM 自己决定“什么该记住、什么该遗忘”听起来很智能,但也带来了不可预测性。一个错误的摘要生成,可能导致关键信息永久丢失。Letta 虽然提供了人工干预的接口,但在全自动场景下,这种风险始终存在。
局限 4:不是“即插即用”的组件
与 Mem0 的 add()/search() 极简 API 不同,Letta 需要开发者理解其内存管理哲学,并在代码中显式地管理 Agent 的生命周期、Session 的持久化、以及 Git 存储的维护。它的学习曲线更陡峭。
六、适用场景:什么时候该选 Letta?
✅ 强烈推荐 Letta 的场景
- 研究导向的 Agent 开发:如果你正在探索记忆系统的底层机制,Letta 的 OS 隐喻提供了丰富的可调参数和观测接口。
- 需要完整审计追踪的应用:Git 版本化记忆天然适合合规要求严格的领域(法律、医疗、金融审计)。
- 单 Agent 长周期任务:如一个持续数周的个人研究助手,Letta 的虚拟内存可以让它始终“记得”几周前的讨论。
⚠️ 谨慎评估后使用的场景
- 高并发、多租户 SaaS:每个 Agent 一个 Git 仓库的存储模型,在大规模部署时会带来显著的运维负担。
- 对延迟极度敏感的应用:Letta 的记忆调度和 Git 操作会增加额外的延迟,不适合需要毫秒级响应的实时交互。
- 团队缺乏 OS/分布式系统背景:Letta 的很多概念(分页、换入换出、Git 合并冲突)对传统应用开发者可能较为陌生。
❌ 不太适合的场景
- 简单的短期记忆需求:如果 Agent 的任务都是短对话,Letta 的复杂度远超需求。
- 需要与其他框架深度集成的场景:Letta 更像一个独立的 Agent 运行时,而非一个可嵌入的记忆组件。
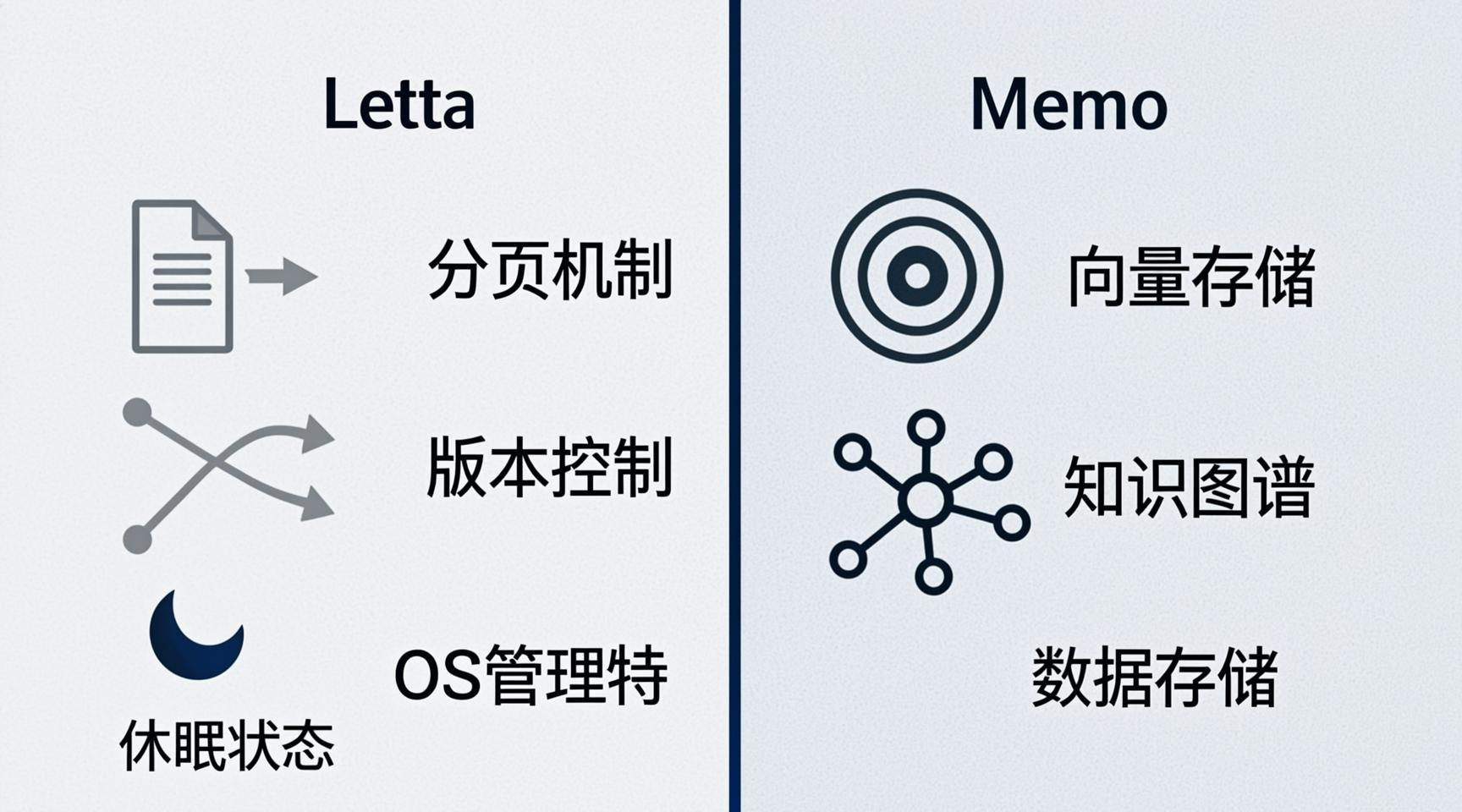
七、Letta vs Mem0:两种哲学的碰撞
为了更直观地比较 Letta 和上一篇文章的主角 Mem0,我们来看一张象限图:
两者的选择本质上是控制力与易用性的权衡。Letta 给你完全的控制权和可观测性,但需要你付出更多的学习和运维成本;Mem0 让你快速上手,但内部的黑盒行为你无法精确干预。
八、小结:OS 隐喻的未尽之路
Letta 最令人着迷的地方,在于它把计算机科学中最成熟的思想——虚拟内存、版本控制、后台进程——系统地移植到了 AI 领域。这种“站在巨人肩膀上”的思路,让它在众多记忆框架中独树一帜。
但 OS 隐喻也是一把双刃剑。计算机操作系统的设计目标是确定性和可靠性,而 LLM 本质上是一个概率系统。让概率系统来扮演内存管理单元的角色,本身就带有一种“用不确定性管理确定性”的悖论。
Git 版本化记忆同样如此。Git 是为代码设计的,代码的变更是精确的、逐行的;而自然语言记忆的变更是模糊的、语义的。用管理代码的工具来管理自然语言记忆,究竟是天才还是过度工程?答案可能取决于你的具体场景。
下一篇,我们将目光转向一个理念截然不同的框架——ReMe,阿里 AgentScope 团队出品的“文件即记忆”。它没有 Letta 那么复杂的 OS 抽象,而是采用了一种极端透明、用户可直接编辑的 Markdown 文件方案。这是一种“返璞归真”,还是一种更聪明的务实?我们下篇见分晓。
如果你觉得这篇文章有帮助,欢迎点赞、收藏。你对 Letta 的 OS 隐喻怎么看?是天才设计还是过度工程?欢迎在评论区留下你的观点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)