通义 Qwen3.6 开源:3B 激活参数硬刚 27B 性能
2026年4月16日晚,阿里巴巴通义千问团队正式开源Qwen3.6系列首款模型——Qwen3.6-35B-A3B。
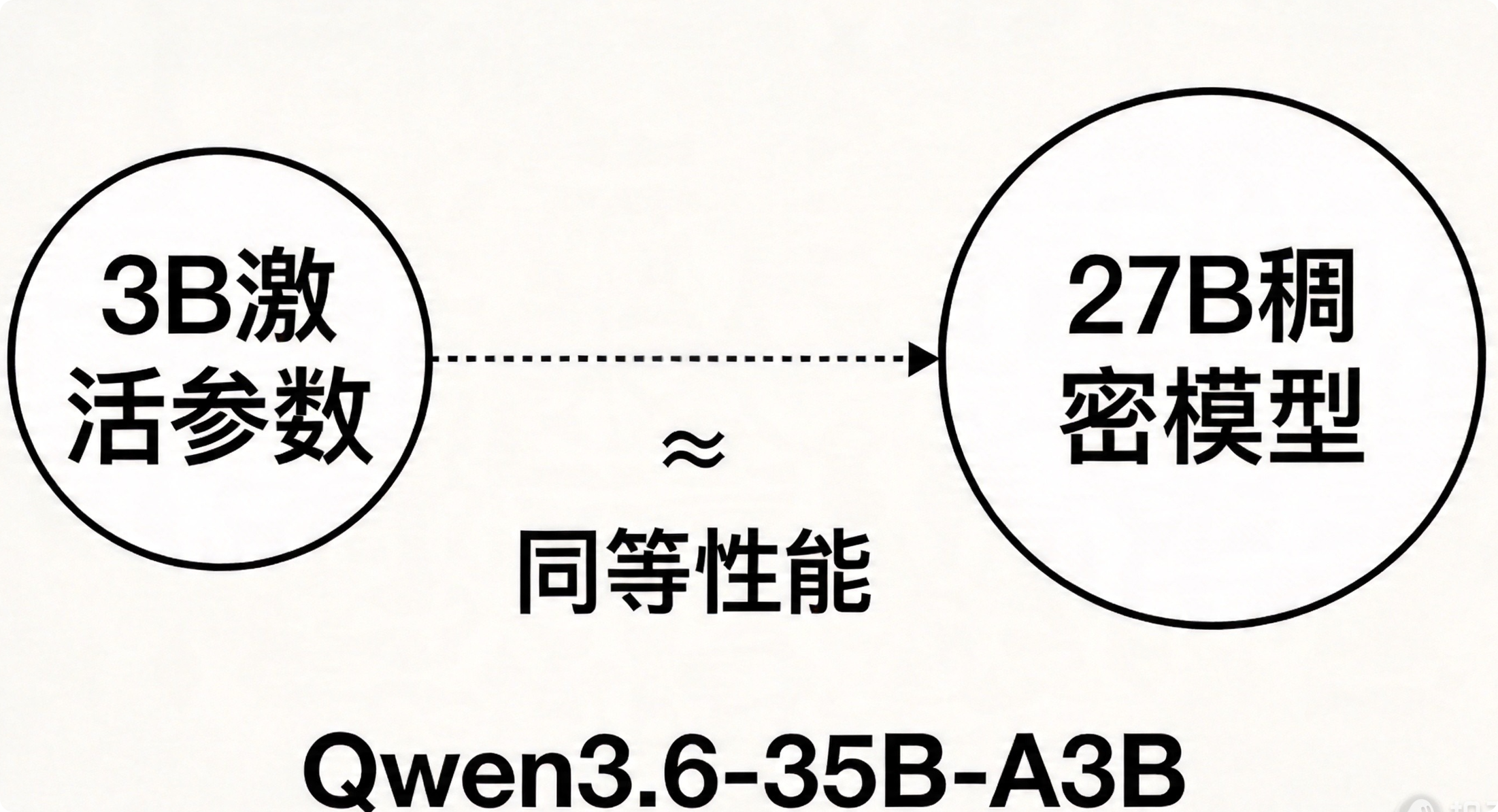
这款大模型采用稀疏混合专家(MoE)架构,总参数量350亿,推理时仅激活30亿参数。从算力消耗看,运行成本接近3B级小模型,但性能可以对标27B-31B的稠密模型。
核心参数
Qwen3.6-35B-A3B是Qwen3.6系列首个开源权重版本,使用Apache 2.0协议。模型内部有256个专家网络,每次推理激活8个路由专家加1个共享专家。架构共40层,隐藏层维度2048,融合了门控DeltaNet与门控注意力两种机制。
上下文方面,模型原生支持262,144 tokens,扩展后可达1,010,000 tokens。
开发者可在Hugging Face、ModelScope下载模型权重,或通过Qwen Studio在线体验。阿里云百炼API平台即将上线,命名为qwen3.6-flash。
编程能力
在智能体编程领域,Qwen3.6-35B-A3B交出了这样的成绩单:
- SWE-bench Verified:73.4分
- Terminal-Bench 2.0:51.5分
- AIME 2026:92.7分
- NL2Repo:29.4分
对比来看,SWE-bench Verified得分与Qwen3.5-27B的75.0基本持平,大幅超越前代Qwen3.5-35B-A3B的70.0。Terminal-Bench 2.0得分51.5,领先所有同级对比模型。NL2Repo取得29.4分,也超过了Qwen3.5-27B的27.3。
数学推理方面,AIME 2026得分92.7,MMLU-Pro 85.2,GPQA 86.0。
多模态表现
Qwen3.6-35B-A3B原生支持多模态输入输出,内置视觉编码器。在主流视觉语言基准测试中:
- MMMU:81.7分
- MathVista:86.4分
- RealWorldQA:85.3分
- OmniDocBench:89.9分
这些分数在大多数视觉语言基准上已与Claude Sonnet 4.5持平,部分任务实现超越。
空间智能方面表现更突出:RefCOCO得分92.0,ODInW13得分50.8,EmbSpatialBench得分84.3。视频理解方面,VideoMME(含字幕)86.6,VideoMMMU 83.7,VideoMMMU得分超过Claude Sonnet 4.5的77.6。
生态兼容性
模型已实现与主流编程智能体工具的深度兼容,包括OpenClaw、Claude Code、Qwen Code。API层面同时支持OpenAI与Anthropic两套标准协议,开发者切换模型时无需修改原有代码逻辑。
新功能方面,模型支持思维保留(Thinking Preservation)机制,可在多轮对话中保留历史推理上下文,减少重复推理开销。同时支持多模态思考与非思考模式切换,适配不同复杂度的任务需求。
技术架构
MoE架构的核心思路是:传统稠密模型无论任务难易都激活全部参数,而MoE将模型拆分为多个专家网络,根据任务类型动态选择合适的专家组合。以极低的激活参数实现接近全参数模型的性能。
模型兼容Transformers、vLLM、SGLang、KTransformers等主流推理框架。运行需要安装最新版本transformers,以及torchvision和pillow依赖。
本地部署友好
普通消费级显卡即可运行,编译产物仅数 MB,适合 Serverless 和边缘部署
模型下载:
- Hugging Face:https://huggingface.co/Qwen/Qwen3.6-35B-A3B
- ModelScope:https://modelscope.cn/models/Qwen/Qwen3.6-35B-A3B
- 在线体验:https://chat.qwen.ai/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)