SDU软件学院创新实训(三)
上周同组同学做了项目框架和向量数据库的搭建等工作,得到了简单的小程序前端界面,我则是进行了“安诊用药”ai助手的管理员端前后端的编写。接下来介绍管理员端的后端功能开发过程的思考和进度。
一、管理员端功能分析
考虑到后续维护和扩展方便,管理员端采用了模块化设计,没有把所有功能混在一起。结合项目实际需求,拆分出五大核心模块,每个模块各司其职,相互配合,具体如下:
1. 管理员认证模块
后台管理的首要需求就是安全,所以我们采用了JWT Token无状态认证机制。这种方式不用在服务器端存储会话信息,既能减少服务器压力,也能有效防止非法访问,确保管理员的每一步操作都有安全校验。
2. 仪表盘统计模块
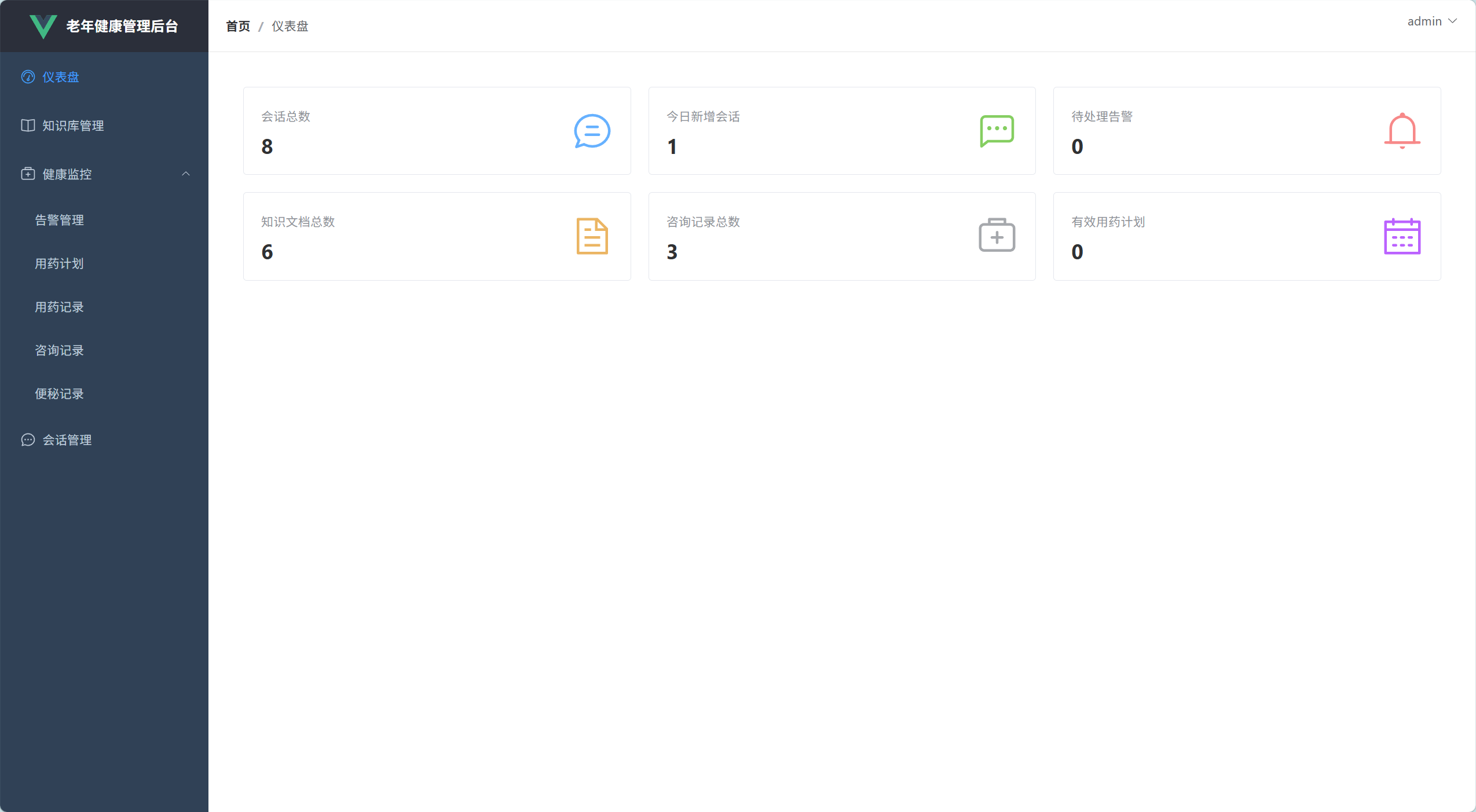
管理员日常工作中,需要快速掌握系统整体运行情况,不用逐个模块去查询。仪表盘把核心数据实时呈现出来,比如会话数、告警数等,帮助管理员更快地掌握系统运行情况。
3. 知识库管理模块
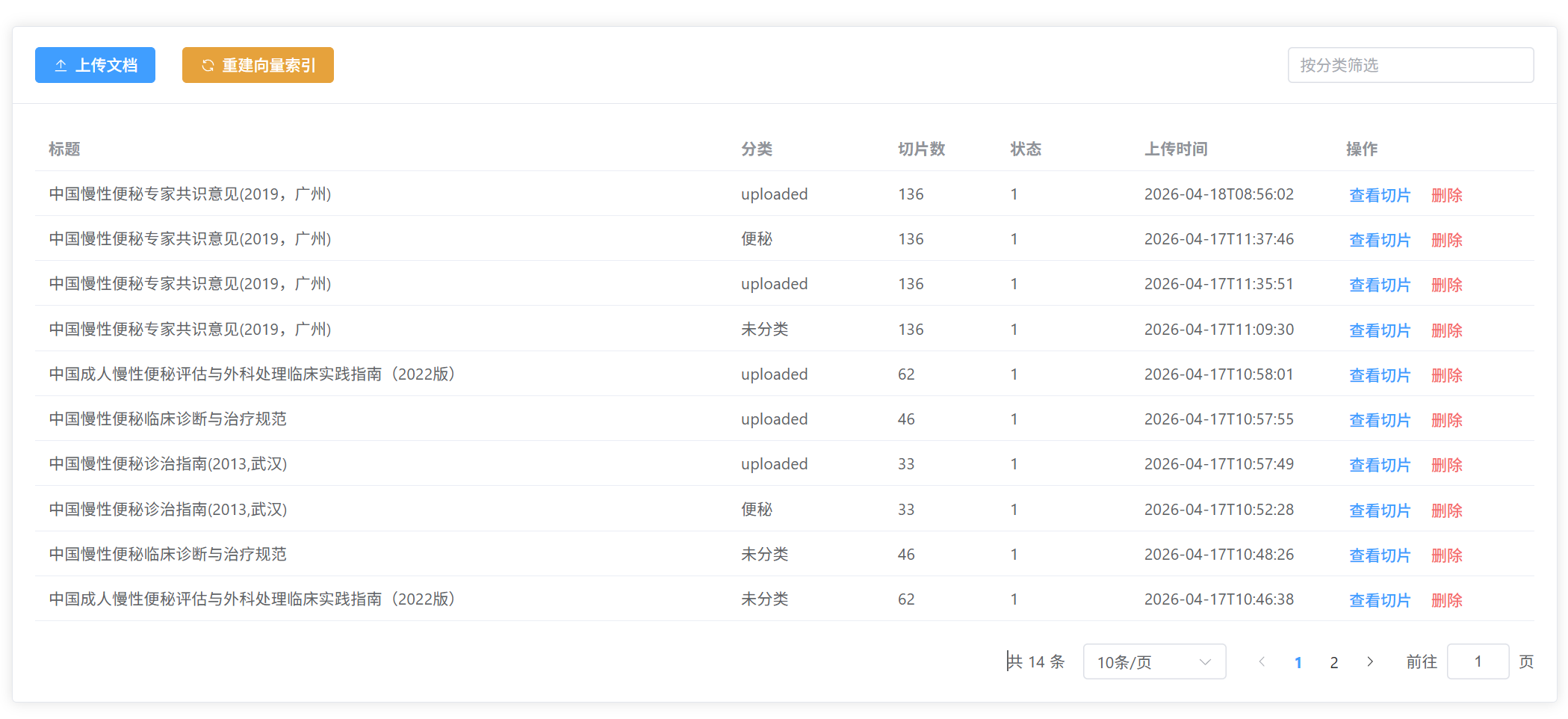
该模块是整个AI智能体的“知识储备库”,智能体要能解答老年人的健康、用药问题,需要这个模块支撑。我们实现了文档上传、向量化处理、切片管理和索引重建功能,确保AI能快速精准地调用相关知识。
4. 健康管理监控模块
老年用户的健康是本项目的核心关注点,这个模块专门用来监控和管理用户相关健康数据,包括健康告警、用药计划、用药记录、咨询记录等。管理员能及时发现异常,跟进处理,保障用户用药和健康安全。
5. 会话审计管理模块
系统运行过程中,会出现一些异常问题,比如用户反馈语音交互异常。该模块就提供了会话查看、消息明细查询和会话删除功能,方便排查问题、审计操作,快速定位并解决异常情况。
二、核心功能实现过程和思考
下面结合实际开发的代码,列举几个核心模块的实现过程,截取项目中的代码进行展示(后续迭代过程中代码可能存在更改)。
(1)管理员认证功能
管理员认证这块,我们选用了Spring Security框架,结合JWT Token来实现,既符合行业常用实践,也能满足项目的安全需求。
@RestController
@RequestMapping("/api/admin/auth")
public class AdminAuthController {
@Autowired
private AuthenticationManager authenticationManager;
@Autowired
private JwtUtils jwtUtils;
@PostMapping("/login")
public Result<Map<String, Object>> login(@RequestBody LoginRequest loginRequest) {
Authentication authentication = authenticationManager.authenticate(
new UsernamePasswordAuthenticationToken(loginRequest.getUsername(), loginRequest.getPassword())
);
UserDetails userDetails = (UserDetails) authentication.getPrincipal();
String token = jwtUtils.generateToken(userDetails);
Map<String, Object> data = new HashMap<>();
data.put("token", token);
data.put("username", userDetails.getUsername());
data.put("roles", userDetails.getAuthorities());
return Result.success(data);
}
@Data
public static class LoginRequest {
private String username;
private String password;
}
}这里有几个关键技术点,也是实际开发中的实现思路,即借助Spring Security的AuthenticationManager,实现管理员账号密码的身份验证,确保登录信息合法;验证通过后,生成JWT Token,后续所有接口调用都需要携带这个Token,相当于管理员的“身份凭证”;返回管理员的用户名和权限信息,方便前端根据权限展示不同的操作菜单。
(2)知识库管理功能
知识库是AI智能体的核心,所以这个模块的功能做得比较全面,支持文档的上传、向量化、切片管理和索引重建,满足日常知识更新和维护的需求。实际开发中,我封装了专门的KnowledgeService来处理复杂逻辑,控制器代码如下:
@RestController
@RequestMapping("/api/admin/knowledge")
@RequiredArgsConstructor
public class AdminKnowledgeController {
private final KnowledgeService knowledgeService;
private final KnowledgeDocMapper knowledgeDocMapper;
private final KnowledgeSliceMapper
knowledgeSliceMapper;
@GetMapping("/docs")
public Result<Page<KnowledgeDoc>> getDocs(
@RequestParam(defaultValue = "1") Integer
page,
@RequestParam(defaultValue = "10") Integer
size,
@RequestParam(required = false) String
category) {
Page<KnowledgeDoc> pageParam = new Page<>(page,
size);
LambdaQueryWrapper<KnowledgeDoc> wrapper = new
LambdaQueryWrapper<KnowledgeDoc>()
.orderByDesc(KnowledgeDoc::getCreateTime);
if (category != null && !category.isEmpty()) {
wrapper.eq(KnowledgeDoc::getCategory,
category);
}
return Result.success(knowledgeDocMapper.
selectPage(pageParam, wrapper));
}
@PostMapping("/upload")
public Result<Map<String, Object>> uploadDoc(
@RequestParam("file") MultipartFile file,
@RequestParam(defaultValue = "未分类") String
category) {
try {
Map<String, Object> result = knowledgeService.
uploadAndIngest(new MultipartFile[]{file},
category);
return Result.success(result);
} catch (Exception e) {
return Result.error("文件上传并索引失败: " + e.
getMessage());
}
}
@DeleteMapping("/docs/{id}")
public Result<Void> deleteDoc(@PathVariable Long id) {
try {
knowledgeService.deleteDoc(id);
return Result.success();
} catch (Exception e) {
return Result.error("删除失败: " + e.getMessage
());
}
}
@GetMapping("/docs/{id}/slices")
public Result<List<KnowledgeSlice>> getDocSlices
(@PathVariable Long id) {
List<KnowledgeSlice> slices =
knowledgeSliceMapper.selectList(
new LambdaQueryWrapper<KnowledgeSlice>()
.eq(KnowledgeSlice::getDocId, id)
.orderByAsc
(KnowledgeSlice::getOrderNum)
);
return Result.success(slices);
}
@PostMapping("/sync")
public Result<Void> syncAll() {
try {
knowledgeService.rebuildVectorIndex();
return Result.success();
} catch (Exception e) {
return Result.error("重建索引失败: " + e.
getMessage());
}
}
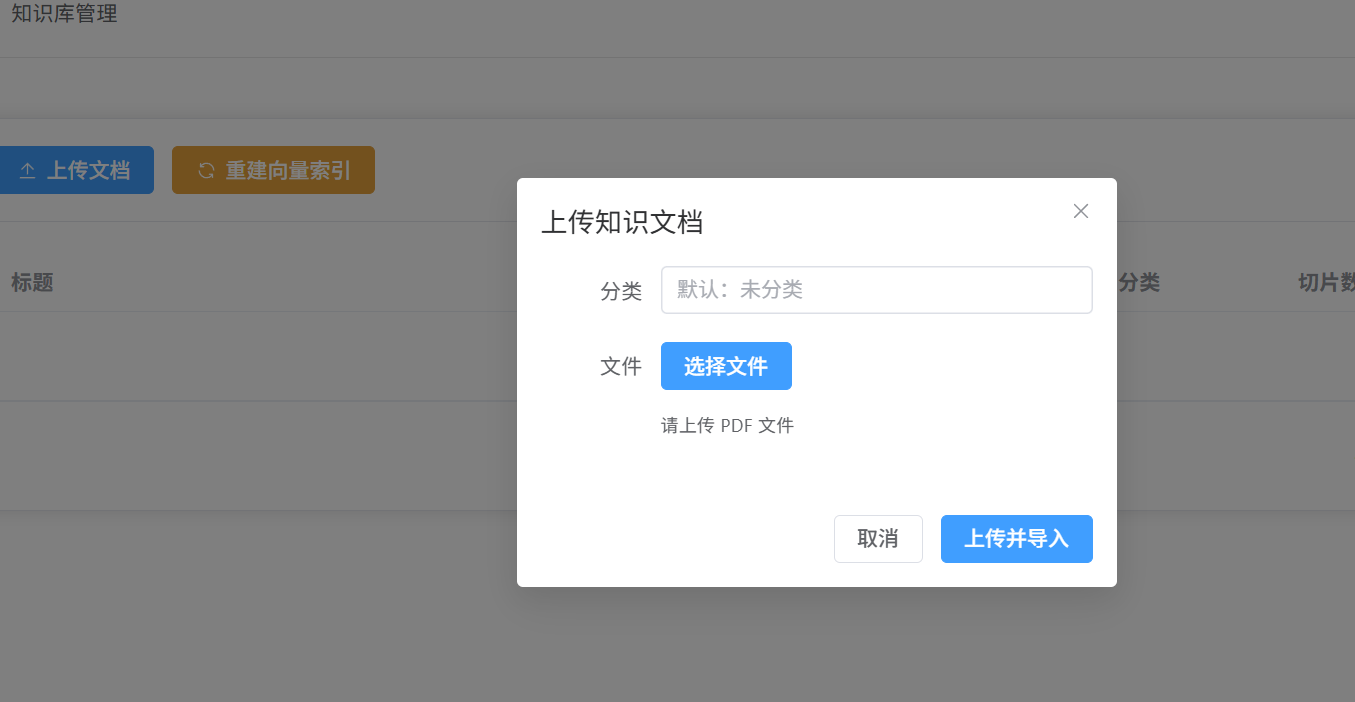
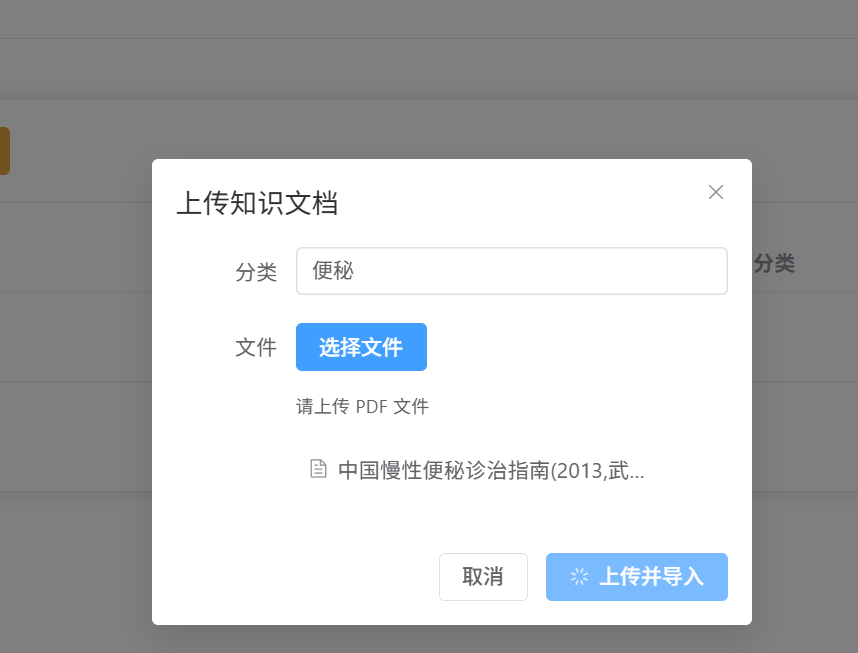
}这个模块提供了几个核心的功能,即文档分页查询,支持按分类筛选,方便管理员快速找到需要的文档,尤其是知识库文档较多时,分页能提升查询效率;支持PDF文档上传,上传后会自动进行向量化处理,让AI能快速检索和调用文档内容;文档删除时,会自动清理关联的切片和索引数据,避免数据冗余;可以查看单篇文档的切片详情,方便管理员核对文档处理是否准确;提供向量索引全量重建功能,当知识库文档批量更新后,重建索引能确保AI检索的准确性。
三、进度展示
我在本周简单搭建了web前端的框架,下面进行进度的展示。
上传知识库
以上就是本周的工作内容,目前管理员端功能基本实现,前端简单搭建。下一步将继续完善功能代码并优化前端界面,测试相关功能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)