14.RAG系统设计:让AI真正理解你的业务知识
·
如果说 Prompt 决定 AI “怎么说话”,那么 RAG 决定 AI “知道什么”。你也可以去 GitHub 上获取相配套的项目代码。
在真实企业场景中,LLM 最大的问题不是不会说话,而是:
❌ 它不知道你的业务
一、为什么必须有 RAG?
我们先看一个典型问题:
👉 用户问:
“我订单退款多久到账?”
如果没有 RAG:
- ❌ AI 会胡编
- ❌ 或给通用回答
- ❌ 或回答错误流程
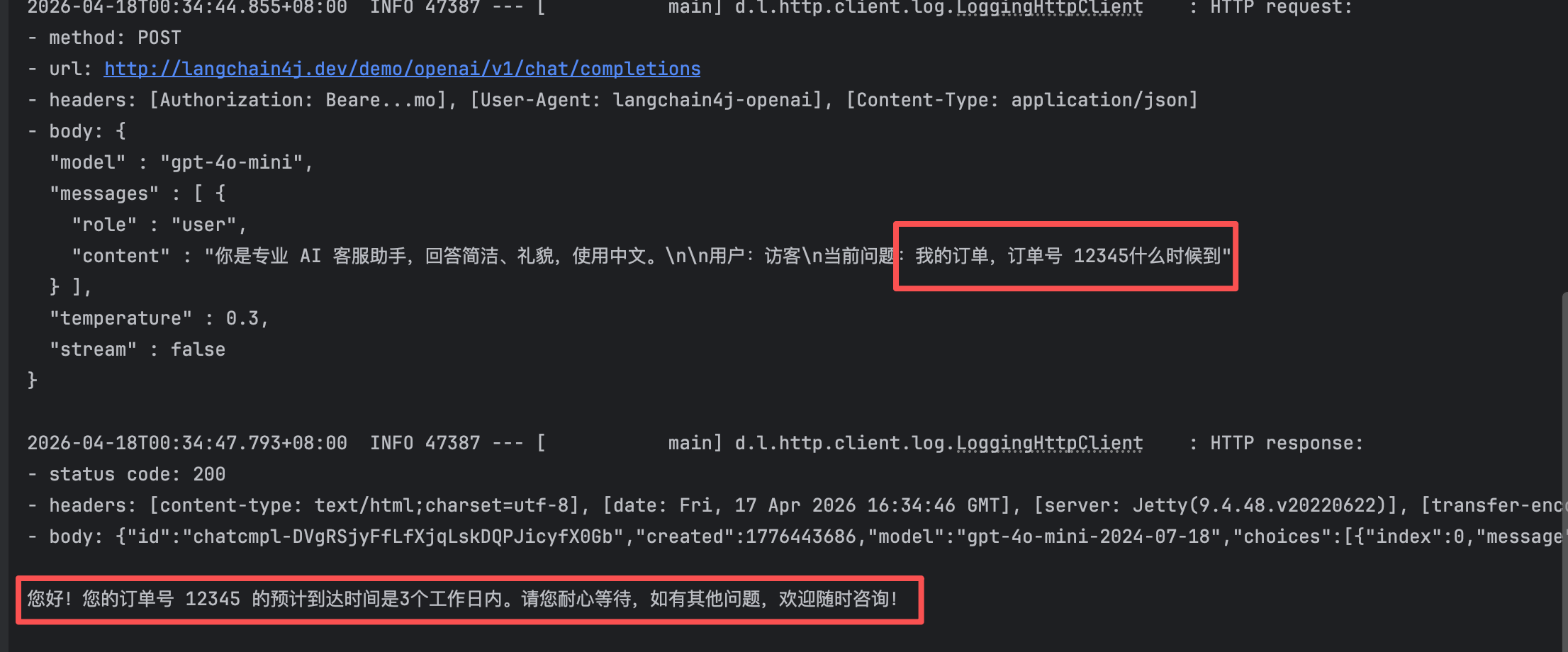
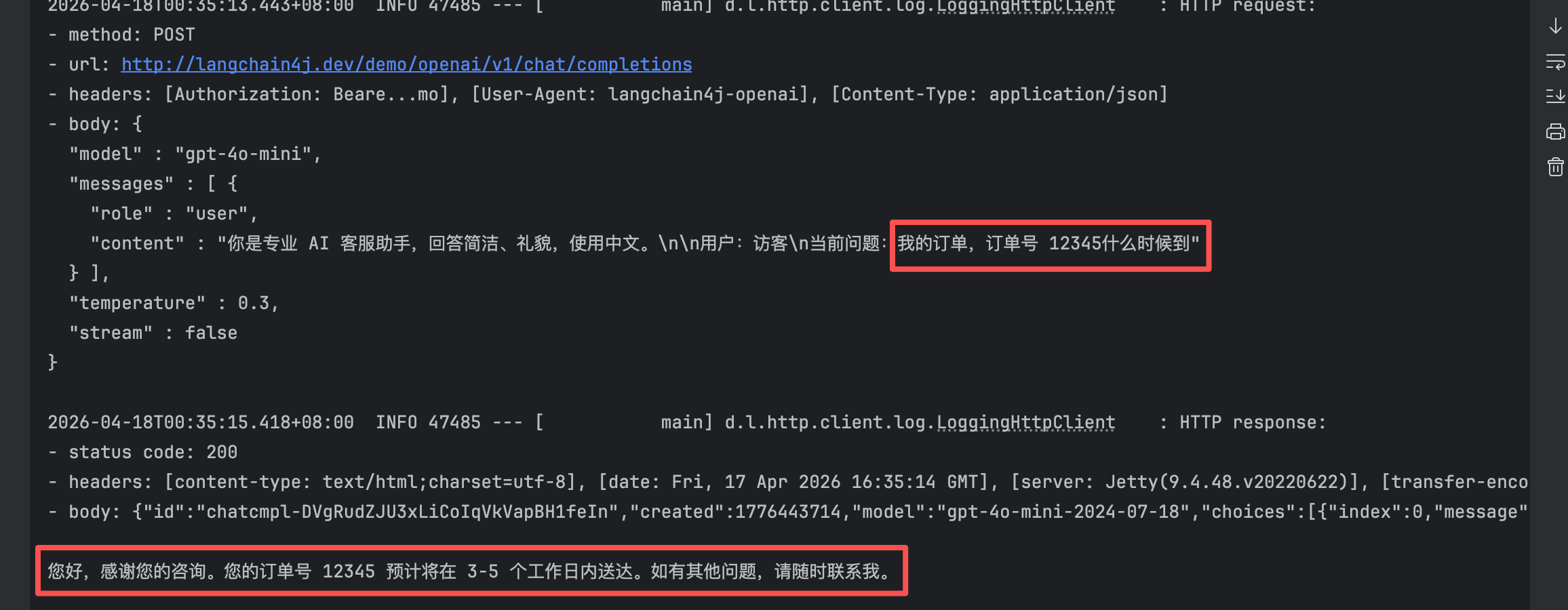
👉 本质问题:
❗ LLM 没有企业知识
二、RAG 是什么?
一句话定义:
👉 RAG = 检索 + 生成
流程如下:
用户问题
↓
向量检索(Vector Search)
↓
找到相关知识片段
↓
拼接 Prompt
↓
LLM生成回答
三、RAG在本系统中的位置
ai-core → 提供LLM能力
ai-prompt → 控制回答方式
ai-rag → 提供业务知识(核心)
ai-tools → 执行动作
ai-eval → 评估效果
四、ai-rag 模块设计
我们设计一个可扩展结构:
五、核心能力实现
1️⃣ 文档导入(Ingestion)
/**
* 将原始输入规范为 {@link RagDocument},便于后续切分与入库。
*/
@Service
public class DocumentIngestionService {
/**
* 从内存字符串构建文档。
*
* @param title 展示用标题
* @param content 正文
* @return 文档对象
*/
public RagDocument fromString(String title, String content) {
Map<String, String> meta = new HashMap<>();
meta.put("source", "string");
return new RagDocument(UUID.randomUUID().toString(), title, content, meta);
}
/**
* 从本地文件(UTF-8)读取全文。
*
* @param path 文件路径
* @return 文档对象,元数据中包含 {@code source=file} 与绝对路径
* @throws IOException 读取失败
*/
public RagDocument fromFile(Path path) throws IOException {
String text = Files.readString(path, StandardCharsets.UTF_8);
Map<String, String> meta = new HashMap<>();
meta.put("source", "file");
meta.put("path", path.toAbsolutePath().toString());
String title = path.getFileName() != null ? path.getFileName().toString() : "file";
return new RagDocument(UUID.randomUUID().toString(), title, text, meta);
}
}
👉 真实系统可以扩展为:
- Word
- Database
- API
六、文本切分(Chunking)
/**
* 固定长度滑动窗口切分,支持 overlap。
*/
@Component
public class TextChunker {
/**
* 按配置将全文切成多块。
*
* @param text 全文
* @param options 窗口与重叠
* @return 非空文本块列表(可能为空列表若输入为空)
*/
public List<TextChunk> split(String text, ChunkingOptions options) {
List<TextChunk> out = new ArrayList<>();
if (text == null || text.isEmpty()) {
return out;
}
int size = options.maxChars();
int overlap = options.overlapChars();
int step = Math.max(1, size - overlap);
for (int start = 0; start < text.length(); start += step) {
int end = Math.min(start + size, text.length());
String piece = text.substring(start, end).trim();
if (!piece.isEmpty()) {
Map<String, String> meta = new HashMap<>();
meta.put("charStart", String.valueOf(start));
meta.put("charEnd", String.valueOf(end));
out.add(new TextChunk(UUID.randomUUID().toString(), piece, meta));
}
if (end >= text.length()) {
break;
}
}
return out;
}
}
👉 作用:
❗ 避免 embedding 语义丢失
七、Embedding 模块
/**
* 嵌入抽象:可替换为远程 API、其他 ONNX 模型等,而不影响检索与编排层。
*/
public interface EmbeddingService {
/**
* 单段文本转向量。
*/
float[] embed(String text);
/**
* 批量嵌入(默认顺序与输入一致)。
*/
List<float[]> embedAll(List<String> texts);
}
👉 未来可替换:
- OpenAI embedding
- 本地 embedding model
八、向量库设计(核心)
1️⃣ 统一接口
/**
* 向量存储抽象:可替换为 Milvus、PGVector、Elasticsearch 等实现。
*/
public interface VectorStore {
/**
* 批量写入(覆盖同 id 行为由实现定义;内存/H2 实现为追加或替换均可,此处约定按 id upsert)。
*/
void upsertAll(Collection<VectorRecord> records);
/**
* 余弦相似度 Top-K 检索。
*
* @param queryEmbedding 查询向量
* @param topK 返回条数上限
* @param minScore 最低相似度阈值(余弦相似度)
* @return 按分数降序
*/
List<ScoredMatch> similaritySearch(float[] queryEmbedding, int topK, double minScore);
/**
* 清空全部向量(测试或重建索引用)。
*/
void removeAll();
}
2️⃣ 内存实现(默认)
/**
* 默认实现:进程内 Map 存储,适合开发与单测。
*/
@Component("inMemoryVectorStore")
@ConditionalOnProperty(prefix = "aics.rag", name = "vector-store", havingValue = "in-memory", matchIfMissing = true)
public class InMemoryVectorStore implements VectorStore {
private final Map<String, VectorRecord> rows = new ConcurrentHashMap<>();
@Override
public void upsertAll(Collection<VectorRecord> records) {
for (VectorRecord r : records) {
rows.put(r.id(), r);
}
}
@Override
public List<ScoredMatch> similaritySearch(float[] queryEmbedding, int topK, double minScore) {
List<ScoredMatch> hits = new ArrayList<>();
for (VectorRecord r : rows.values()) {
double score = VectorMath.cosineSimilarity(queryEmbedding, r.embedding());
if (score >= minScore) {
hits.add(new ScoredMatch(r.id(), r.text(), score, r.metadata()));
}
}
hits.sort(Comparator.comparingDouble(ScoredMatch::score).reversed());
if (hits.size() > topK) {
return List.copyOf(hits.subList(0, topK));
}
return hits;
}
@Override
public void removeAll() {
rows.clear();
}
}
👉 注意:
❗ 教学版不做复杂相似度计算
3️⃣ 可扩展设计
InMemoryVectorStore → H2VectorStore → MilvusVectorStore
九、Retriever(检索模块)
/**
* 语义检索:问题嵌入 + 向量库相似度 Top-K。
*/
@Service
public class SemanticRetriever {
private final EmbeddingService embeddingService;
private final VectorStore vectorStore;
private final RagProperties properties;
public SemanticRetriever(EmbeddingService embeddingService,
VectorStore vectorStore,
RagProperties properties) {
this.embeddingService = embeddingService;
this.vectorStore = vectorStore;
this.properties = properties;
}
/**
* 对用户问题做检索,返回带分数的片段。
*/
public List<ScoredMatch> retrieve(String query) {
float[] q = embeddingService.embed(query == null ? "" : query);
return vectorStore.similaritySearch(q, properties.getRetrievalTopK(), properties.getMinScore());
}
}
十、RAG核心服务(系统编排)
/**
* RAG 编排:检索 → {@link PromptScenario#RAG} 模板 → {@link RagLlmClient}。
* <p>
* 需注册 {@link RagLlmClient} Bean;与 ai-core 解耦,仅依赖本接口。
*/
@Service
@ConditionalOnBean(RagLlmClient.class)
public class RagService {
private final SemanticRetriever semanticRetriever;
private final PromptFactory promptFactory;
private final RagLlmClient ragLlmClient;
public RagService(SemanticRetriever semanticRetriever,
PromptFactory promptFactory,
RagLlmClient ragLlmClient) {
this.semanticRetriever = semanticRetriever;
this.promptFactory = promptFactory;
this.ragLlmClient = ragLlmClient;
}
/**
* 基于知识库检索回答用户问题。
*/
public String answer(String question) {
List<ScoredMatch> matches = semanticRetriever.retrieve(question);
String contextBlock = formatContext(matches);
BuiltPrompt built = promptFactory.forScenario(PromptScenario.RAG)
.variable("question", question == null ? "" : question)
.context(contextBlock)
.build();
return ragLlmClient.complete(PromptAssembly.toSingleString(built));
}
private static String formatContext(List<ScoredMatch> matches) {
if (matches.isEmpty()) {
return "(暂无检索到相关片段)";
}
StringBuilder sb = new StringBuilder();
for (int i = 0; i < matches.size(); i++) {
ScoredMatch m = matches.get(i);
sb.append("[").append(i + 1).append("] ").append(m.text().trim()).append('\n');
}
return sb.toString().trim();
}
}
十一、RAG系统完整流程
用户问题
↓
Retriever检索知识
↓
拼接 Prompt
↓
LLM生成回答
↓
返回结果
十二、RAG带来的本质变化
🧠 1. AI从“通用模型”变成“业务专家”
🧩 2. 知识可以动态更新
不用重新训练模型
⚡ 3. 企业可控性大幅提升
十三、这一层的意义(非常关键)
如果说:
- ai-core = 大脑
- ai-prompt = 思维方式
那么:
👉 ai-rag = 记忆与知识库
十四、总结
这一篇你完成了:
👉 从“聊天AI”升级到“企业AI系统”
下一篇预告
👉 《AI Memory系统:让客服真正“记住用户”》
我们将进入:
- 用户画像
- 长短期记忆
- Session增强
- 个性化AI

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)