【机器学习实战】支持向量机、贝叶斯、决策树与随机森林:心脏病预测全流程与算法底层逻辑(二)
在上一篇博文中,链接如下:https://blog.csdn.net/Malvin_chan/article/details/159736704?spm=1001.2014.3001.5501
我们基于心脏病数据集完成了 K 近邻(KNN)和逻辑回归算法的实现与分析,验证了机器学习算法在医疗分类任务中的可行性。本文将承接上篇内容,继续实现支持向量机(SVM)、朴素贝叶斯、决策树、随机森林四类经典分类算法,并从准确率、精确率、召回率、AUC 等维度横向对比算法性能,最终明确不同算法在心脏病预测任务中的优劣。
一、项目背景与数据预处理回顾
1.1 数据集说明
本项目使用的心脏病数据集包含 14 个特征(年龄、性别、胸痛类型、静息血压等),目标变量target标记患者是否患有心脏病(1=患病,0=无病)。数据包含数值型特征(如age、chol)和分类型特征(如sex、cp),样本量均衡,适合分类任务。
1.2 数据预处理
分别对特征型数据进行了标准化处理和对类别型数据进行了独热编码,详见上一篇博文的数据处理章节。这里为保证算法对比的公平性,所有算法使用完全相同的预处理流程。
二、算法实现与结果分析
2.1 支持向量机(SVM)
2.1.1 算法原理
SVM 是一种用于高维数据分类任务的强大算法。它通过在多维特征空间中寻找一个“最优超平面”,旨在将患有心脏病和未患心脏病的患者数据以最大间隔分开。即不仅要把正负样本(患病与健康)分开,还要让离这个平面最近的样本点(支持向量)到平面的距离最大化。对于心脏病这种存在复杂非线性关系的生理数据,我们通常使用核技巧,将低维空间线性不可分的数据映射到高维空间使其变得可分。常用核函数包括线性核、高斯核(RBF)、多项式核等。
2.1.2 代码实现(核函数调优 + 模型评估)
-
SVM 的核心在于核函数(Kernel)的选择。在代码中,我们分别测了线性核、多项式核、高斯核和sigmoid核,其中高斯核应用最为广泛。
SVC在划分超平面时有时需要升维,但是传统低纬度映射到高纬度的方法计算过于复杂,这里采用了核技巧,即通过简单的低维运算,获取了数据(点)在高维空间的几何关系(内积相似度),而不需要将数据真的升维
- linear:线性核 (没升维)
- poly:多项式核
- sigmoid:sigmoid核
- rbf:高斯核 (万能核,理论上可以映射到无限维)几何理解为对水面上投石子(数据点),水波纹呈高斯分布,越近的两个石子互相影响(相似度)越大
###从sklearn.svm模块中导入向量机分类器,用于高维数据分类任务
from sklearn.svm import SVC
###创建空列表,用于之后存放不用核函数对应的准确率
svc_score = []
kernels = ['linear','poly','rbf','sigmoid'] ###定义要测试的核函数列表
#SVC在划分超平面时有时需要升维,但是传统低纬度映射到高纬度的方法计算过于复杂,这里采用了核技巧,即通过简单的低维运算,获取了数据(点)在高维空间的几何关系(内积相似度),而不需要将数据真的升维
#linear:线性核(没升维),poly:多项式核,sigmoid:sigmoid核
#rbf:高斯核***(万能核,理论上可以映射到无限维)几何理解为对水面上投石子(数据点),水波纹呈高斯分布,越近的两个石子互相影响(相似度)越大
for i in range(len(kernels)):
svc_classifier = SVC(kernel=kernels[i]) ###创建支持向量机分类器,指定当前核函数
svc_classifier.fit(x_train,y_train) ###用训练集训练模型
svc_score.append(svc_classifier.score(x_test,y_test)) ###计算测试集准确率并存入刚刚创建的空列表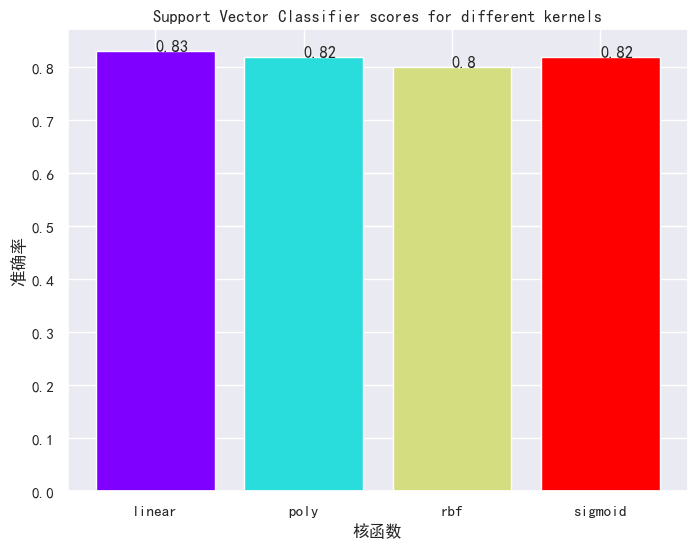
2.1.3 结果与分析
绘制每个核函数对应的准确率柱状图,可以看出Linear核表现最好。
-
核函数效果:线性核(83%)> 多项式核(82%)= sigmoid核(82%)> RBF核(80%),说明心脏病数据特征间存在线性关联,线性核更能捕捉复杂特征关系;
-
优缺点:
-
优点:在高维空间表现优异;泛化能力强,配合 RBF(高斯核)核函数能很好地处理非线性生理数据。
-
缺点:计算复杂度高,不适合超大规模数据集;模型本身是“黑盒”,难以向医生解释某条具体的判断依据;对缺失值和噪声敏感。
-
2.2 朴素贝叶斯(Naive Bayes)
2.2.1 算法原理
朴素贝叶斯基于贝叶斯定理,其“朴素”二字来源于一个强假设:各个特征之间相互独立。通过计算后验概率实现分类;针对数值型特征,选择高斯朴素贝叶斯,由于我们的心脏病数据集中包含连续数值(如年龄、血压),假设这些连续变量的概率密度服从正态(高斯)分布。
2.2.2 代码实现
from sklearn.naive_bayes import GaussianNB ###导入高斯贝叶斯工具
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
###导入准确率,分类报告,混淆矩阵工具
#初始化高斯朴素贝叶斯分类器
nb_classifier = GaussianNB()
#使用训练集训练
nb_classifier.fit(x_train,y_train)
#用测试集测试
y_pred_nb = nb_classifier.predict(x_test)
#输出准确率(将真实结果和预测结果进行计算)
acc_nb = accuracy_score(y_test,y_pred_nb)
print('The accuracy of Naive Bayes Classifier is {:.2f}%'.format(acc_nb*100))
#混淆矩阵
print('\nConfusion Matrix:')
print(confusion_matrix(y_test,y_pred_nb))
#输出分类报告
print('\nClassifier report:')
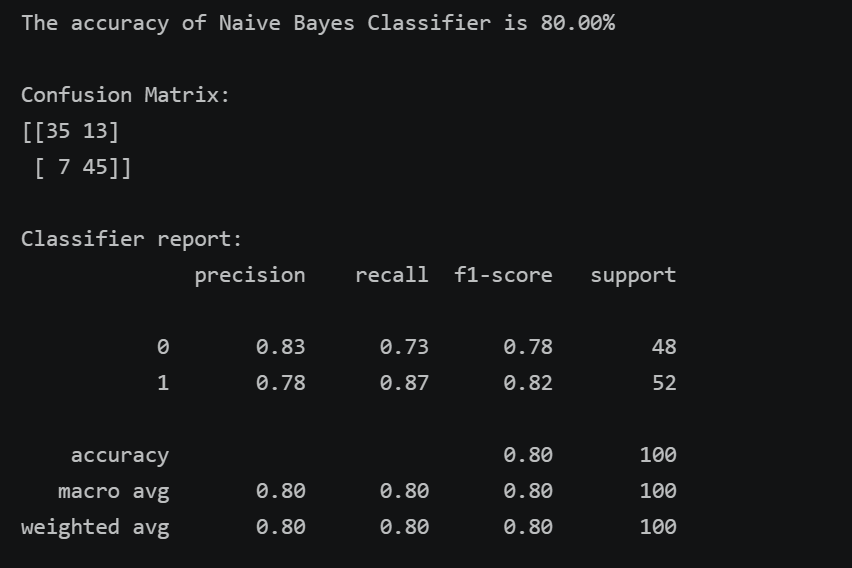
print(classification_report(y_test,y_pred_nb))2.2.3 结果与分析
-
核心指标:准确率=80%,低于 SVM/逻辑回归;
-
特征独立假设的影响:心脏病数据中特征并非完全独立(如 thalach 与 exang 高度相关),违背了朴素贝叶斯的核心假设,导致性能下降;
-
优缺点:
-
优点:算法极其简单,计算速度极快;在数据量较少时依然能保持不错的性能。
-
缺点:“特征绝对独立”的假设在医疗现实中几乎不成立(例如“年龄”和“最大心率”显然存在关联),这会限制其最终的预测上限。
-
2.3 决策树(Decision Tree)
2.3.1 算法原理
1. 核心结构
一棵完整的决策树由三种节点组成:
1)根节点(Root Node):包含所有的训练数据,是决策过程的起点。
2)内部节点(Internal Node):表示对某一个特征(如“年龄”、“血压”)的测试条件。
3)叶子节点(Leaf Node):表示最终的分类结果(如“患病”或“健康”)。
2. 核心问题:如何选择最好的特征进行分裂?
决策树构建过程中最关键的一步是:在每一个节点,应该选择哪个特征、哪个阈值来进行切分,才能让分出来的子集最“纯”?
在机器学习中,“纯(Purity)”意味着一个集合中只包含某一种类别的数据。为了衡量纯度,决策树引入了“不纯度(Impurity)”的概念。
常见的不纯度计算指标有两种:
A. 信息熵(Entropy)与信息增益(ID3/C4.5 算法使用)
-
信息熵用来衡量一个集合的混乱程度。混乱程度越高(比如健康和患病各占 50%),熵越大;非常纯粹(比如 100% 都是患病),熵就为 0。
-
公式:假设数据集D中有K个类别,第k类样本所占的比例为
,则数据集D的信息熵为:
-
信息增益(Information Gain):父节点的熵,减去分裂后子节点的加权平均熵。决策树总是选择能带来“最大信息增益”的特征进行分裂。
B. 基尼不纯度(Gini Impurity)(CART 算法使用,如 Scikit-learn 的默认配置)
-
基尼不纯度表示从数据集中随机抽取两个样本,其类别标签不一致的概率。基尼系数越小,纯度越高。
-
公式:
-
同样,算法会寻找分裂后使得基尼不纯度下降最多的特征和阈值。
3. 构建流程
-
开始:所有训练数据都放在根节点。
-
寻找最佳分裂点:遍历当前节点包含的所有特征及其所有可能的划分点,计算每一种划分方式产生的信息增益或基尼下降值。
-
节点分裂:选择增益最大(或不纯度下降最多)的特征和阈值,将当前节点的数据一分为二(或多份)。
-
递归:对生成的子节点重复步骤 2 和 3。
-
停止条件:当满足以下条件之一时停止生长,成为叶子节点:
1)节点内的所有样本都属于同一类(基尼系数或熵为 0)。
2)达到了预设的最大树深度(max_depth)。
3)节点内的样本数量小于预设的最小分裂样本数。
2.3.2 代码实现(参数调优 + 可视化)
###从sklearn.tree模块中导入决策树分类器,用于构建树结构进行分类
from sklearn.tree import DecisionTreeClassifier
dt_scores = [] ###创建空列表存放之后不同max_features参数下的准确率
###遍历max_features 从1到特征总数的所有可能性,range()左闭右开,所以需要加1
for i in range(1,len(x.columns) + 1):
dt_classifier = DecisionTreeClassifier(max_features=i,random_state=0)
##初始化决策树分类器,设置当前max_features和随机数种子
dt_classifier.fit(x_train,y_train) ###训练
dt_scores.append(dt_classifier.score(x_test,y_test)) ###测试并保存到空列表2.3.3 结果与分析
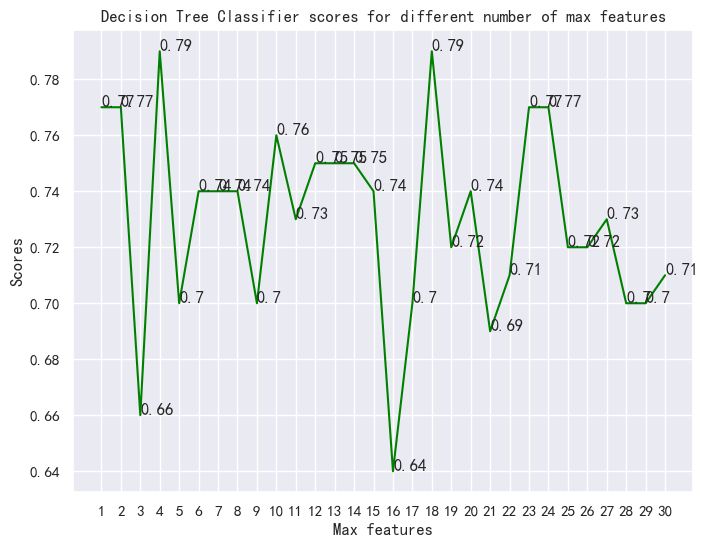
选择了从1到30个特征作为最大分裂特征数来看一下每种情况下的准确率:
-
参数调优:max_depth=4 or 18 时准确率最高(=79%);
-
优优缺点:
-
优点:白盒模型,可解释性无敌。可以直接画出决策路径,极其符合医疗场景下的逻辑审查;不需要做特征缩放(标准化对它无影响)。
-
缺点:极易过拟合(如果不限制深度,它会死记硬背训练集);极其不稳定,数据发生微小改变,整棵树的结构可能完全颠覆。
-
2.4 随机森林(Random Forest)
2.4.1 算法原理
决策树容易出现“过拟合”现象(即对训练数据死记硬背而泛化能力差)。
为了解决这个问题,随机森林采用集成学习(Ensemble Learning)的思想,集成了多棵决策树来提高准确率。它通过随机抽取部分样本和特征构建大量独立的决策树,最后通过“投票”的方式决定患者是否患病。这种机制极大地提升了模型在未见数据上的稳定性和预测精度。
2.4.2 代码实现(集成调优)
###从sklearn.ensemble模块中导入随机森林分类器,用于集成多棵决策树提高准确率
from sklearn.ensemble import RandomForestClassifier
rf_scores = [] ##创建空列表,用于存放不同估计器数下的模型准确率
estimators = [10,100,200,500,1000] ###定义不同数量的估计器
for i in estimators:
rf_classifier = RandomForestClassifier(n_estimators=i,random_state=0)
##初始化随机森林,设计估计器数量和随机种子
rf_classifier.fit(x_train,y_train)
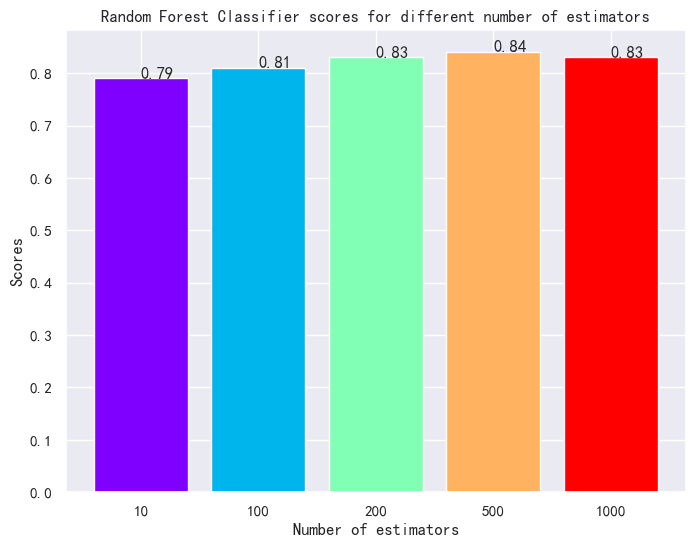
rf_scores.append(rf_classifier.score(x_test,y_test))2.4.3 结果与分析
-
参数调优:n_e stimators=500时准确率=84%(单棵决策树=79%),集成后性能显著提升,且无过拟合;
-
特征重要性:比单棵决策树更优秀,且权重更均衡(降低单特征噪声影响);
-
优缺点:
-
优点:集大成者。极大地降低了过拟合风险;准确率和泛化能力极高;自带“特征重要性”(Feature Importance)评估,能告诉我们哪些生理指标对心脏病影响最大。
-
缺点:失去了单棵决策树的可解释性(变成了黑盒);模型庞大,训练和预测的时间、空间开销较大。
-
三、算法总结
3.1 总结与建议
-
最优选择:随机森林在所有指标上表现最优,且鲁棒性强,适合作为心脏病预测的核心模型;
-
轻量化选择:逻辑回归/朴素贝叶斯训练速度极快,适合嵌入式/实时预测场景(如 Web 端可视化);
-
可解释性需求:决策树可直观展示“哪些特征导致患病”,适合医疗报告解读;
-
非线性场景:SVM(RBF 核)适合特征关系复杂的数据集,但需精细调参。
3.2 Web 端可视化落地
同时,为了让枯燥的算法模型更具实用性,我在项目的最后阶段开发了一个名为“疾病风险预测系统”的 Web 端前端页面。该页面允许用户直接输入临床指标,并实时获取心脏病风险评估。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)