从云端到本地:Spring AI 集成 Ollama 的实战排错与优化全记录
摘要: 在探索本地大模型应用开发的过程中,我尝试使用 Spring AI 连接远程服务器上的 Ollama 服务。然而,这条路并非一帆风顺,我先后遭遇了 Bean 注入冲突以及最致命的内存不足(OOM)问题。本文将详细复盘这段“踩坑”之旅,记录如何从云端服务器转向本机开发,并最终成功实现流式对话的全过程。
一、 环境准备:引入核心依赖
在开始编码之前,我们需要在 pom.xml 中引入必要的依赖。为了兼顾阿里云的 DashScope 服务(作为备用)和本地的 Ollama 服务,我配置了以下核心依赖:
- Spring Boot Web/Reactive:提供 Web 容器和响应式流支持。
- Spring AI Ollama:连接本地大模型的核心驱动。
- Alibaba Cloud AI:用于接入云端模型(本文中作为对比参考)。
核心依赖代码 (pom.xml):
二、 代码实现:构建流式对话接口
目标是实现一个流式接口,能够将用户的输入转发给大模型,并实时返回模型的“思考”过程。
代码逻辑 (OllamaController.java):
@RestController
@RequestMapping("/ollama")
public class OllamaController {
@Autowired
private OllamaChatModel ollamaChatModel; // 注入 Ollama 模型 Bean
@GetMapping("/stream")
public Flux<String> stream(String message, HttpServletResponse response) {
// 关键:设置编码防止中文乱码
response.setCharacterEncoding("UTF- 8");
// 调用模型的 stream 方法,返回 Flux 流
return ollamaChatModel.stream(message);
}
}三、 初次尝试:云端配置与 Bean 注入冲突
在本地开发阶段,我最初的设想是连接远程服务器(ECS)上的 Ollama 服务。但在启动项目时,遇到了第一个拦路虎。
1. Bean 注入冲突排查
报错信息显示:
Field chatModel in cn.evan.llm.llmentor.controller.PromptTemplateController required a single bean, but 2 were found:
dashScopeChatModelollamaChatModel
- 原因:项目中同时引入了
spring-ai-alibaba-starter-dashscope(阿里云千问)和spring-ai-ollama。这两个 Starter 可能都尝试注册了同名的 Bean(chatModel)。 - 解决:
将项目中所有引入的ChatModel改名为dashScopeChatModel:@Autowired private ChatModel chatModel; 改为: @Autowired private ChatModel dashScopeChatModel;
2. 远程服务器配置陷阱
配置文件 application.yml 最初是这样写的:
spring:
ai:
ollama:
base-url: http://xx.xxx.xxx.xxx:11434 # 服务器公网 IP
chat:
model: qwen3:4b排错过程:
- YAML 缩进问题:最初因为缩进错误,导致
model属性没有被读取到,报500错误。YAML 对空格极其敏感,必须确保model与base-url处于同一层级。
四、 核心阻碍:服务器内存不足 (OOM)
当我修正了配置,准备在远程服务器上运行时,遇到了最致命的硬伤。
报错日志:
Error: 500 Internal Server Error: model requires more system memory (3.3 GiB) than is available (2.3 GiB)
深度分析:
- 资源需求:
qwen3:4b(40亿参数版本)在运行推理时,需要至少 3.3GB 的系统内存(RAM)。 - 环境现状:我使用的云服务器配置较低,仅有 2GB 内存。
- 结论:物理限制无法突破。在云服务器上运行 4B 级别的模型不仅昂贵,而且对于开发调试来说是资源浪费。
五、 最终方案:回归本机开发环境
鉴于云端服务器的高昂成本与配置限制,我决定切换回 Windows 本机 进行开发。利用本机的高性能硬件(通常 16GB/32GB 内存)来运行模型,既经济又高效。
本机配置调整 (application.yml):
spring:
application:
name: llmentor
ai:
ollama:
# 关键:Java 运行在本机,直接连接本地服务
base-url: http://localhost:11434
chat:
model: qwen3:4b六、 总结
这次开发经历让我深刻理解了大模型应用的底层逻辑:
- 依赖管理:Spring AI 的生态正在完善,混合使用不同厂商的 Starter 时,要注意 Bean 的命名冲突。
- 配置严谨:YAML 的缩进和模型名称的拼写是第一道关卡。
- 硬件是基础:大模型对内存的“吞噬”能力惊人。对于个人开发者,“本地开发 + 云端轻量部署(小模型)” 是目前最可行的路线。
现在,我的 Spring Boot 应用已经能够流畅地与本机的 qwen3 进行对话了!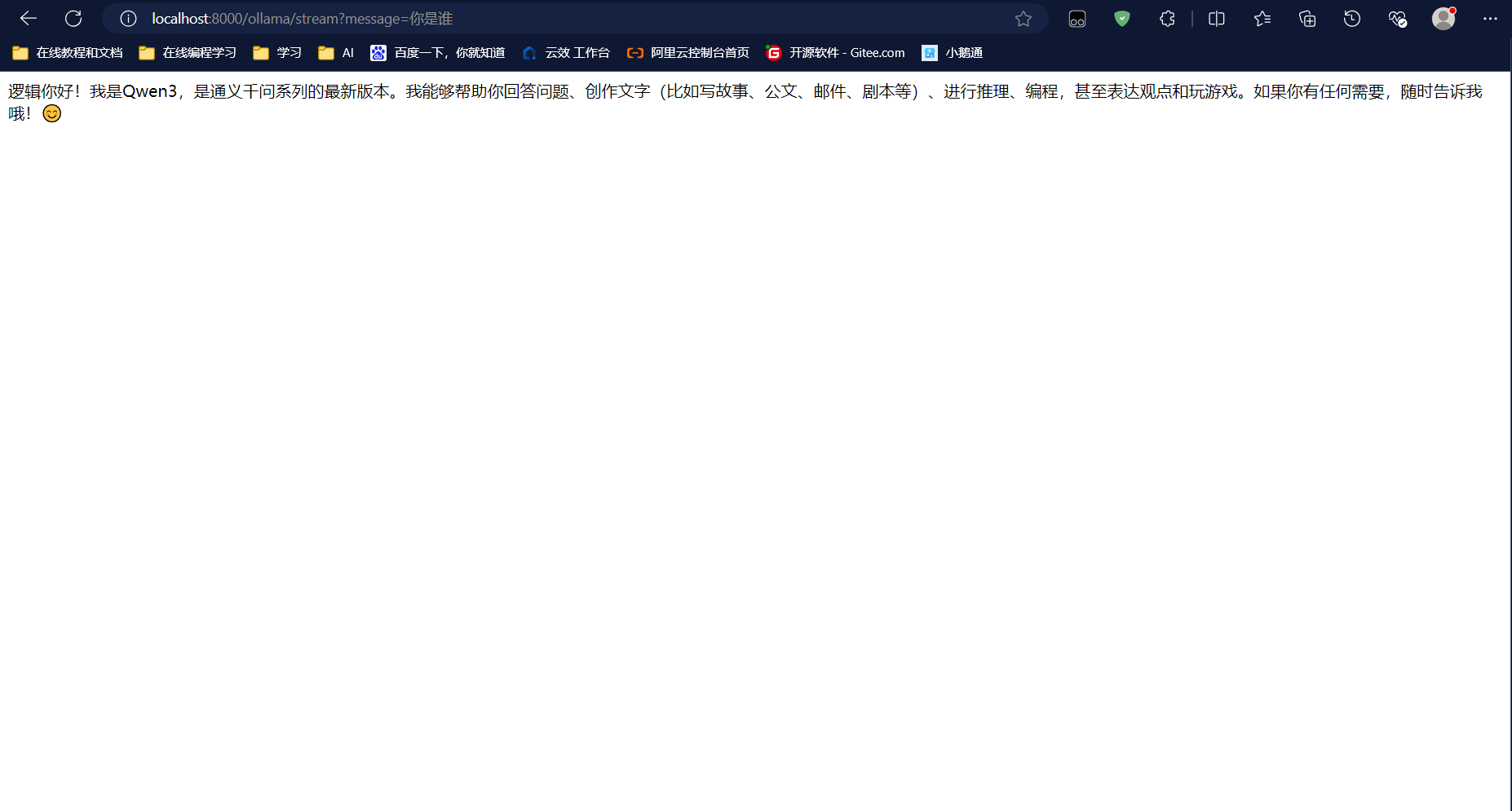

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)