Selenium WebDriver——必会知识
在介绍之前先来说一下HTML、Selenium、WebDriver的关系
HTML(超文本标记语言):它是一个网页的骨架,通过各种标签和属性(id、class)定义了页面的元素
DOM(模型):当浏览器解析HTML后会在内存中对HTML结构生成一个DOM树。如图所示:
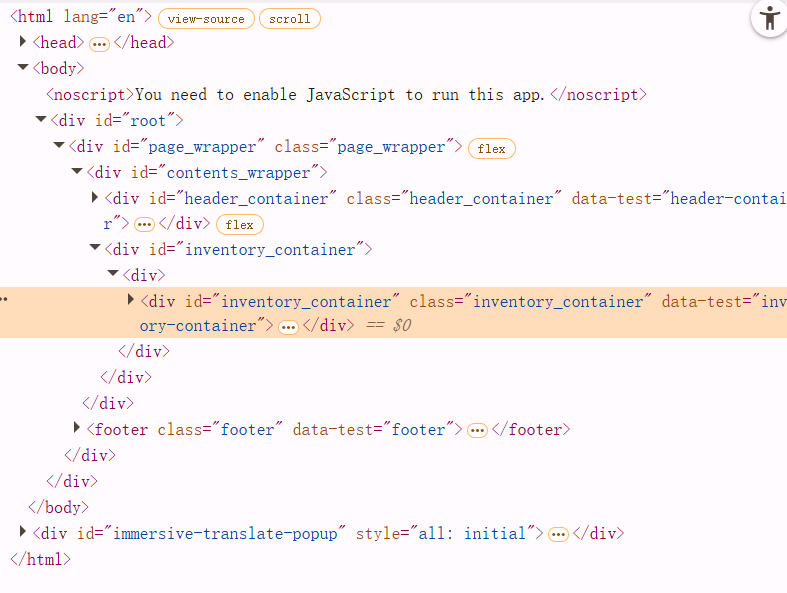
Selenium:是一个自动化工具/API,通过它来抓取到DOM模型上的元素
WebDriver(驱动程序):是一个API或协议,selenium独有的,selenium需要用WebDriver控制浏览器做进行抓取,每一个浏览器都由一个特定的WebDriver实现支持(例如chrome需要chrome driver),它负责浏览器和Selenium之间的通信
Locator(定位器):Selenium实现抓取元素的具体工具,利用自身包含的8种定位器抓取元素
1、元素定位八大方法:
基础定位:
id:通过元素id属性定位
driver.find_element(By.ID,"login_btn")
name:通过name属性定位,用于表单中的输入框
driver.find_element(By.NAME,"username")
class_name: 通过class属性定位,如果有多个class用空格隔开,只能选其中一个
driver.find_element(By.CLASS_NAME,"s_ipt")
链接定位(针对<a>标签)
link_text: 通过链接的完整文本定位
driver.find_element(By.LINK_TEXT," 新闻 ")
partial_link_text:通过链接的部分文本定位
driver.find_element(By.PARTIAL_LINKLTEXT,"新")
标签与结构定位(万能)
tag_name:通过标签名定位(如div,input)
driver.find_element(By.TAG_NAME,"input")
xpath :万能定位器,而已根据层级、属性、文本等文件组合定位
driver.find_element(By.XPATH,"//*[@id,'ui'] // a[text()="新闻"]")
css_selector:性能最高的复杂定位方法,速度比xpath快
driver.find_element(By.CSS_SELECTOR,"#u1.s_ipt")
这里继续补充知识点:
1、Webdriver是驱动程序的统称,每个浏览器都有自己名字的Driver,为什么不能通用?
因为每个浏览器的内核不一样,它们解析出的DOM树逻辑是一样的,但每个浏览器内部调用底层节点的API不一样,为了抹平差异利用WebDriver写python代码实现在不同浏览器上运行
2、WebDriver没每次“抓取”信息过程:
发出请求(调用find_element),编码传输(selenium将动作打包成HTTP请求),驱动执行(收到请求后在浏览器生成的DOM树扫描),返回结果(将抓取到的内容打包成HTTP响应传回代码)
3、现在更流行另一种工具——PlayWright
为什么selenium比PlayWright慢?
Selenium基于WebDriver单向通信,每次操作又要发送一次请求,遇到网络延迟累加就会很慢
PlayWright是基于WebSocket双向通信,实时监听浏览器的动作,不需要下载匹配版本的驱动文件,效率更高
2、selenium的页面操作:点击、输入、下拉框、弹窗处理等怎么实现?
基础动作:
输入文本:send_keys
input_box=driver.find_element(By.ID,"kw")
input_box.send_keys("小徐学编程")点击元素
search_btn=driver.find_element(By.ID,"xu")
search_btn.click()清空输入框
input_box.clear()下拉框处理(Select类)
普通HTML有<select>按钮可以直接用click 点击
from selenium.webdriver.support.ui import Select
#定位到select本身
dropdown =Select(driver.find_element(By.ID,"city_select"))
dropdown.select_by_index(1) #根据索引选
dropdown.select_by_value("sh") #根据value 属性选
dropdown.select_by_visible_text("北京") #根据显示的文字选
网页弹窗(由Javascript触发的alert, confirm , prompt)不属于DOM树,鼠标无法点击,必须要用到 switch_to 切换到警告框
#切换到当前的弹窗
alert= driver.switch_to.alert
print(alert.text) #输出弹窗里的文字
alert.accept() #点确定
#alert.dismiss() #点取消
#alert.send_keys("输入内容") #输入内容鼠标悬停与拖拽
from selenium.webdriver.common.action_chains import ActionChains
menu=driver.find_element(By.ID,"user_menu")
#鼠标悬停在菜单上
ActionChains(driver).move_to_element(menu).perfom()
#从source元素拖拽到target
source=driver.find_element(By.ID,"draggable")
target=driver.find_element)BY.ID,"droppable")
ActionChains(driver).drag_and_drop(source,target).perfom()重点:多窗口与Iframe切换
问题:某些元素定位是对的但找不动元素
Iframe切换:有些网页藏在<iframe>标签里
#切换进iframe
driver.switch_to.frame("login_frame")
#操作完成后,必须切回到主页面
driver.switch_to.default_content()
多窗口切换:点击链接跳出新的标签页,WebDriver的焦点还在旧页面
#获取所有窗口句柄
handles=driver.windows_handles
#切换到最新打开窗口
driver.switch_to.windows(handles[-1])3、等待机制:
显示等待:
使用场景:异步类型的
异步加载的元素:点击按钮后由Javascript生成的弹窗和列表项
状态切换验证:按钮在点击后需要等进度条消失
页面跳转:等URL包含某个特定的关键词、页面标题发生变化
上传/下载:文件上传下载时出现提示文字
注意事项:必须配合定位器使用,传入By和expected_conditions
遇到长代码时和代码一起封装进去
针对不同的操作设置不同的超时
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriver
from selenium.webdriver.support import expected_conditions as EC
#【设置显示等待】具体针对登录操作的按钮
#显示等待用WebDriver(变量名,时间)来调用
#1、等待发布笔记的按钮在真正可以被点击时再点击
wait=WebDriverWait(driver,15)
pubilish_btn=wait.until(EC.element_to_be_clickable((By.XPATH,"//button[contains(text(),"发布笔记")]")))
publish_btn.click()
#2、等待登录成功的弹窗消失
wait.util(EC.invisibility_of_element_located((By.CLASS_NAME,"loading_mask")))隐式等待:
在项目初期搭建:项目结构简单时,网页加载速度快、异步请求较少,可以用隐式等待做一个基本的全局保障
保底机制:设置一个较短时间(5″)防止网络抖动导致脚本崩塌
#隐式等待用umplicitly_wait()函数调用
from selenium import webdriver
driver=webdriver.Chrome()
#全局生效,设置一次其他命令都执行
driver.implicitly_wait(5)
driver.get("https://www.xioahongshu.com")
diver.find_element(By.ID,"search").send_keys("穿搭")
driver.find_element("class name","search").click()注意:
1、显示等待和隐式等待不能混用在同一个项目
2、代码逻辑中先执行until拿到元素对象,再执行等待操作
3、EC(Expected Conditions)常用法:
EC.presence_of_element_located:只要HTML树里有这个标签就行
EC.visibility_of_element_located:HTML里有,用户能看到
EC.element_to_be_clickable:不仅能看到还没有遮挡
4、显示等待抛出超时异常时要考虑代码逻辑中是否捕获做一些(截图、清除缓存)的处理
5、场景模拟:
| 场景需求 | 推荐方案 | 理由 |
| 页面跳转后的第一个元素 | 隐式等待 | 页面刚刷新,给所有基础元素一个通用的加载缓冲。 |
| 点赞后等待“点赞成功”提示消失 | 显示等待 | 隐式等待只能等“出现”,不能等“消失” |
| 点击“发送验证码”后,按钮进入 60s 倒计时 | 显示等待 | 需要判断按钮的属性变为 disabled 或文本内容改变 |
| 网络环境极差,且页面有很多动态加载的小组件 | 显示等待 | 针对核心组件设置超长等待,非核心组件不等待,提高脚本效率。 |
4、POM框架封装
一个完整的POM框架包括四部分:
BasePage 封装
显示等待集成:将WebDriverWait 封装进find方法
截图/日志:在点击方法里植入日志记录,出现异常就自动截图
JavaScript 执行器:封装 js_click 或 scroll_to_element“解决看得见却点不到”的顽固元素。
链式调用:多个动作一行代码执行
login_page.input_user("admin").click_login().verify_welcome_msg()
数据驱动
将数据内容使用 pytest.mark.parametrize 配合外部文件YAML/JSON/Excel 存放
断言
写在Text Case类中,负责调用 Page 方法拿到结果用 assert 比对
实例:“小红书登录并进入个人中心” 的业务逻辑
BasePage 将selenium不稳定的API封装起来(如各种click)
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class BasePage:
def __init__(self,driver):
self.driver=driver
self.wait=WebDriverWait(self.driver,10)
def find(self,locator):
return self.wait.util(EC.presence_of_element_located(locator))
def click(self,loctor):
el=self.wait.util(EC.element_of_to_be_cickable(locator))
el.click()
def send_keys(self,locator,text):
el=self.find(locator)
el.clear()
el.send_keys(text)LoginPage.py 将页面的元素和逻辑装起来,解决“页面能做什么”的问题
from selenium.webdriver.commmen.by import By
class LoginPage(BasePage):
user_name=(By.ID,"name")
login_btn=(By.CLASS_SELECT,".login_btn")
def login_action(self,user_name):
self.send_keys(self.user_name,"xu")
self.click(login_btn)
# 【链式调用】:返回下一个页面的对象
# 注意:在 Python 中为了避免循环导入,通常在方法内部 import
from pages.index_page import IndexPage
return IndexPage(self.driver)
test_login.py 判断功能对不对
import pytest
from pages.login_page import LoginPage
class Test_Login:
@pytest.mark.parametize("user",["1234456","213248763"])
def test_login(self,driver,user):
#初始化登录页
login_p=LoginPage(driver)
# 【链式调用】:一行代码完成业务流
# 执行登录动作,直接拿到首页对象,并调用首页的方法获取结果
index_p=login_p.login_page(user)
result_text=index_p.get_nickname()
assert "我的小红书" in result_text注:若ID信息发送改变,只需要修改LoginPage即可,不需要改其他两个class
5、yield用法
先说一下yield是做什么的
简单来说就是函数里的“暂停键”,保留当前运行的状态
在测开中,yield的场景主要是:
1、pytest 里的环境管理
在自动化测试里,我们经常需要“前置准备”(比如打开浏览器)和“后置清理”(比如关闭浏览器)。yield 完美地把这两步缝合在了一个函数里:
import pytest
@pytest.fixture()
def setup_database():
print("\n1. 连接数据库...") # 【前置操作】
db = "MySQL_Connection"
yield db # 【暂停交接】把 db 交给测试用例去跑。用例在跑的时候,代码就停在这行等。
print("\n2. 断开数据库连接...") # 【后置操作】测试用例全跑完了,它苏醒过来,接着往下走打扫战场。2、生成器:节省内存
在多个测试样例时防止大量数据堆积,可以使用它批量加入数据,防止内存撑爆
def create_test_users(limit):
for i in range(limit):
yield f"test_user_{i}" # 生产一个,交给你,暂停。下次要,再生产下一个。
# 调用它:
users = create_test_users(10000000)
print(next(users)) # 输出: test_user_0
print(next(users)) # 输出: test_user_1
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)