李沐深度学习代码精讲
李沐部分深度学习代码(日更)
注:
1. 本篇仅作针对李沐的代码的分层解析,不完全负责理论课部分的讲解,烦请读者加上关于李沐的各种B站课程(包括但不限于理论课、代码课)一起食用,效果更佳。
2. 本篇由于单篇长度过大,便分为几篇来更新,有意向者可关注后续更新博客内容。
一、torch的安装以及导入
1.安装
①首先以Windows系统为例——先通过Win+R输入CMD(小写也行)打开Windows PowderShell,输入“nvidia-smi”查看自己的GPU的型号(如果有的话)确认好之后,如果有GPU会有类似这样的输出:
重点要关注的就是CUDA Version,后面的数字直接决定了你应该安装哪一个版本的torch(GPU版的)
以128为例
②然后回到PyCharm里面,先检查自己的终端是否有(.venv)字样——
 <-这样才行
<-这样才行
如果没有.venv:在终端运行这样的命令——.\venv\Scripts\activate.bat
③然后在PyCharm终端输入如下的命令行:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128——如果自己是12.2的那就改成122
④然后就是等待下载安装——这个过程系统自动执行无需人为操作——而且python会自动“断网重连”,无需焦虑
⑤安装完成后,终端会显示Successfully installed ……表示——安装成功了,就可以开始导入使用了
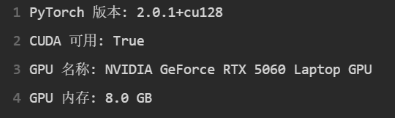
⚠如果还担心的话可以这样测试:——注意!请在自己的本地PyCharm里测试!请勿在本网站测试!
import torch
print("PyTorch版本: ", torch.__version__)
print("CUDA可用: ", torch.cuda.is_available())
print("GPU名称: ", torch.cuda.get_device_name(0))
print("GPU内存: ", torch.get_device_properties(0).total_memory / 1024**3, "GB")应该看到类似这样的输出:
⑥常见的问题如下——

(CPU版本)——不需要指定版本,因为CPU版的都是通用的
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple2.导入
在pyCharm第一行写import torch即可
import torch(注意——自己在自己本地的PyCharm里面尝试时,一开始全部显示为灰色是正常现象,因为你此时只是导入但并未使用,可以尝试在接下来一行的代码里调用它。这个具体的方法后续会讲。)
二、torch(软件)包的基本运用
1. .range()函数:定义指定范围的张量(一维数组)
首先我们可以定义一个指定范围的张量——即多维数组。比如这样:
import torch
x = torch.arange(12)
print(x)2. .shape()函数:展示张量的大小/形状
import torch
x=torch.arange(12)
print(x.shape)3. .numel()函数:展示张量的元素个数
import torch
x = torch.arange(12)
print(x.numel()) # X = tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])4. .reshape()函数:重塑张量的结构
import torch
x=torch.arange(12)
X = x.reshape(3, 4)# 这里的意思是3行4列
print(X)5. .zeros() .zero_like() .ones() .one_like()等函数的集体辨析
〇先说明一下为什么要用ones_like这类函数:
在深度学习中,我们经常需要:
- 初始化梯度(比如反向传播前清零)
- 构造掩码(mask)
- 创建占位符(placeholder)用于后续计算
- 对齐张量形状(shape alignment)
而这些操作往往要求新张量的形状、数据类型、所在设备与某个已有张量一致。这时候如果我们直接写 torch.ones(3, 4) 就不够灵活,因为我们得手动指定形状;但是如果我们用 ones_like(x),编译器就会自动匹配 x 的一切属性!
① .zeros(input)函数
import torch
Y=torch.zeros((2, 3, 4))
print("使用全0 全1 甚至是其他常量 或者从特定分布中随机采样的数字都行\n我们选择用 全0 展示数组结果如下:")
print(Y)
print("\n")② .zero_like(input, fill_value)函数
import torch
x=torch.arange(12)
print(f"原张量是: {x}")
X_zeros_like = torch.zeros_like(x)
print(f"调用zeros_like()函数后是:{X_zeros_like}")③ .ones(input)函数
import torch
print("使用全0 全1 甚至是其他常量 或者从特定分布中随机采样的数字都行\n我们选择用 全1 展示数组结果如下:")
Z=torch.ones((2, 3, 4))
print(Z)④ .ones_like(input, fill_value)函数
import torch
x=torch.arange(12)
print(f"原张量是: {x}")
X_ones_like = torch.ones_like(x)
print(f"调用ones_like()函数后是:{X_ones_like}")⑤ .full_like(input, fill_value)函数
import torch
x=torch.arange(12)
A_1 = torch.full_like(x, 5)
print(A_1)⑥ .empty_like(input)函数
注意:这个函数一般不建议使用,毕竟会分配内存但不初始化,所以很容易使得里面出现垃圾值,快但危险
⑦ .randn_like(input)函数
这里先说一点——rand是均匀分布(在0~1之间),而randn是正态分布
import torch
x_2 = torch.arange(2).float()
temp_2 = torch.rand_like(x_2)
print(temp_2)原理解释(randn的)——这是以输入(即input)的张量为模板去通过高斯分布/钟形曲线(即标准正态分布)来输入随机值的过程。大部分的值会集中在-1~1之间,有的值可能会“溢出”(即超出这个范围)
import torch
x=torch.arange(4).float() # 转为float32
temp = torch.randn_like(x)
print(temp)⑧总结
以上这些函数(带like的)都默认不继承requires_grad(即是否可导),需要自己手动确认是否可导
import torch
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = torch.randn_like(x)
print(y.requires_grad) # 默认输出False6. .tensor()函数:手动重塑张量——手动指定填入哪些值
import torch
x = torch.arange(12)
Q=torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(f"数组已被修改为: {Q}\n")7. tensor包里张量的计算
值得注意的是,如果x里面有一个数是浮点数,那么整个x数组就是浮点数张量。y在跟x计算时,计算结果也会被转换成浮点数张量。
import torch
x=torch.tensor( [1.0, 2, 4, 8] )
y=torch.tensor( [2, 2, 2, 2] )
print("俩数组分别是:")
print("x=[1.0, 2, 4, 8]\n")
print("y=[2, 2, 2, 2]\n")
print("x+y=",x+y)
print("\n")
print("x-y=", x-y)
print("\n")
print("x*y=", x*y)
#此处的乘不是矩阵算法,只是“点对点”计算(即一一对应)
print("\n")
print("x/y=", x/y)
print("\n")
print("x**y=(等价于x^y=...)", x**y)
print("\n")
print(torch.exp(x))
#此处公式等价于e^x=?
print("e+00的意思是*10^0=1")
print("\n")
8. 张量的按维度拼接
能拼接的前提条件是同个维度,并且每个拼接方法对应的结果也不同
以二维张量为例:
import torch
x = torch.arange(12, dtype=torch.float32).reshape((3, 4))
y = torch.tensor( [ [2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1] ] )
temp1 = torch.cat((x, y), dim = 0) # 按行来拼接
temp2 = torch.cat((x, y), dim = 1) # 按列来拼接
print(f"按行来拼接的结果是{temp1}")
print(f"按列来拼接的结果是{temp2}")如果是三维的话:
其实本质上跟以上的拼接结果是一样的,只是在外层多加了对中括号而已。
总结:
我真觉得在三维里面所谓的dim = 1(其实对应二维里面的dim = 0一样的拼法)或者dim = 2(其实对应二维里面的dim = 1一样的拼法),真的不该纠结于维度的问题(这都是模型该干的事情)。反正我觉得——这技术跟二维的拼法没什么区别,一模一样,就是外壳多了对中括号而已。我的思路就是——先看维度确定几维,比如是三维,如果dim是1,那么就是:3最大,然后2次之(dim = 2——镜像对应 二维 里面的dim = 1), 最后是1(dim = 1——镜像对应 二维 里面dim = 0)
import torch
A = torch.tensor([[[1, 2, 3],
[4, 5, 6]]])
B = torch.tensor([[[7, 8, 9],
[10,11,12]]])
C1 = torch.cat([A, B], dim=1)
print(f"C1.shape是:{C1.shape}")
print(f"C1结果是:{C1}")
C2 = torch.cat([A, B], dim=2)
print(f"C2.shape是:{C2.shape}")
print(f"C2结果是:{C2}")9. 张量是否相等的判断
前提是两个张量维度相同!
然后结果会对于每一个值返回 True 或者 False
当然也可以写各种其他形式的判断比如>=等等
import torch
C = torch.tensor([[[1, 2, 3],
[4, 5, 6]]])
D = torch.tensor([[[7, 8, 9],
[10,11,12]]])
print(f"{C == D}")10. .sum()函数:对某个张量内部元素进行求和,输出只含一个元素——求和结果的张量
import torch
y = torch.tensor( [ [2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1] ] )
print(f"{y.sum()}")
D = torch.tensor([[[7, 8, 9],
[10,11,12]]])
print(f"{D.sum()}")11. 通过广播机制(broadcasting mechanism)去修改元素或者进行计算——很容易错!
import torch
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
print(f"a张量是{a}\n\nb张量是{b}\n\na+b的结果是: {a + b}")
原理解释——其实就是a跟b会先都被通过广播机制转换成3*2的矩阵,然后两个矩阵再进行计算——跟矩阵计算算法不同,在Pytorch里面,是“点对点计算”(即是每个元素相对应去计算)
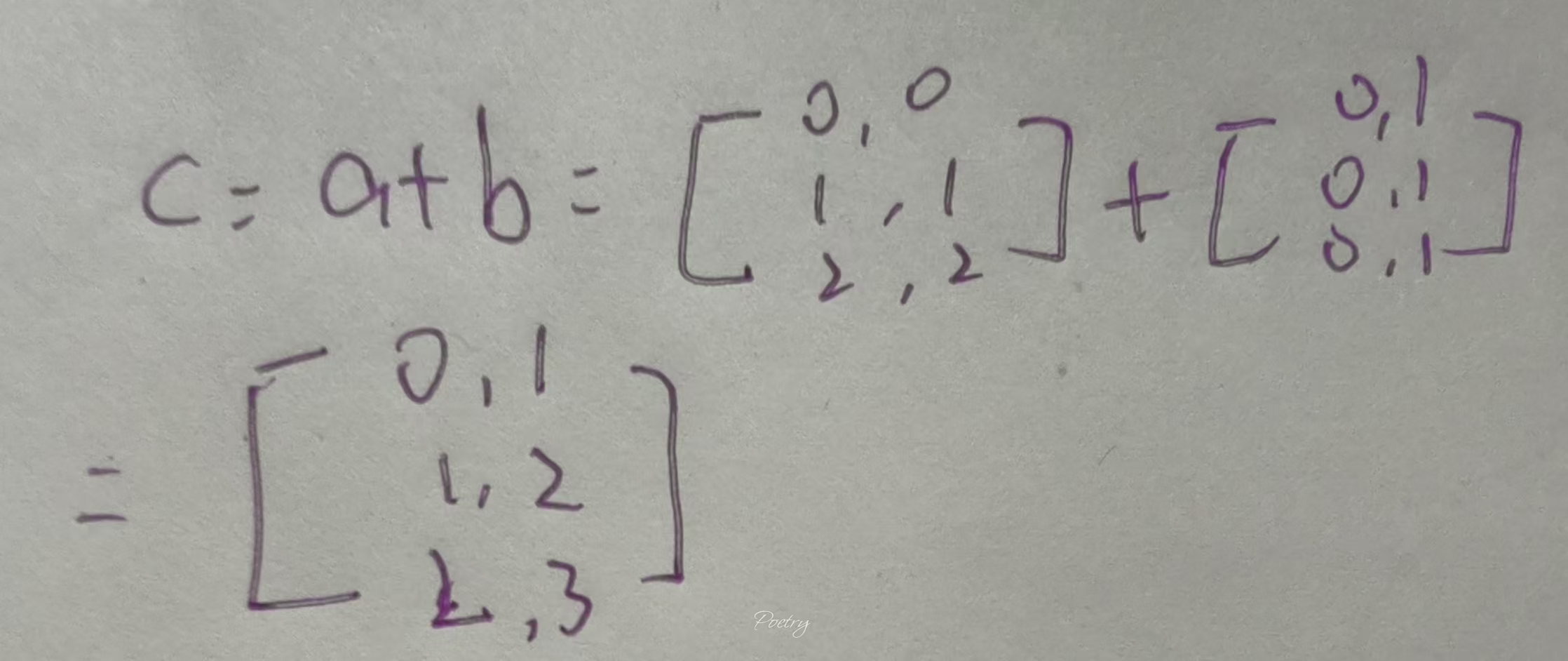
12. 给张量里的元素赋值
(1)通过索引指定单个元素赋值
import torch
x = troch.arange(12).reshape(3, 4)
x[1, 2] = 9
print(x)(2)通过索引指定多个元素赋值
import torch
x = torch.arange(12).reshape(3, 4)
x[0:2, :] = 12
print(x)这里的代码的第三行的中括号里面的意思其实是:我们选择从张量的第0行开始,到第2行前结束,以及这个范围内的所有列的元素,都赋值为12(当然还涉及到缺省的知识点,在此不再赘述)
(3)内存的赋值及分配问题
在python里面不会像C/C++那样去考虑内存的问题——python会自动分配内存。这也就导致了我们在PyCharm里面去编写代码的时候,很容易使得我们因为运行了一些操作而导致PyCharm编译器为新结果分配内存
id()函数的解释
在python里面,id可以类比为C/C++语言里面的指针的用法
import torch
x = torch.arange(12).reshape(3, 4)
x[0:2, :] = 12
print(x)
y = torch.arange(12).reshape(3, 4)
before = id(x)
x += y
print(f"{id(x) == before}")
x = x + y
print(f"{id(x) == before}")在这里解释一下——之所以第一次出现True,是因为在python里面,+=是原地操作,而= +是会修改变量内存地址的一个操作。换句话说,后者是先计算x+y,创建了一个新的张量,再赋值给y。
顺带补充一下:
| 操作 | 等价的函数 |
| x += y | x.add_(y) |
| x = x + y | x.add(y) |
再具体点解释一下原地操作:
import torch
x = torch.arange(12).reshape(3, 4)
x[0:2, :] = 12 # 修改一下但是偷懒版
y = torch.arange(12).reshape(3, 4)
z = torch.zeros_like(x)
print(f"id(z) = {id(z)}")
z[:] = x + y
print(f"id(z) = {id(z)}")你会发现输出是两个一模一样的地址。这是因为我们只是对z的元素进行了修改而已。如果我们写成z = x + y的话就会完全不一样了
import torch
x = torch.arange(12).reshape(3, 4)
x[0:2, :] = 12
y = torch.arange(12).reshape(3, 4)
z = torch.zeros_like(x)
print("原地址如下: ")
print(f"id(z) = {id(z)}")
z[:] = x + y
print(f"id(z) = {id(z)}")
print("原地操作不会修改地址")
z = x + y
print("但经过了z = x + y之后, 地址改为: ")
print(f"id(z) = {id(z)}")(4)矩阵之间的赋值问题
我们可以通过 .clone()的方式来给新的变量赋原来的矩阵的值
import torch
A = torch.arange(20, dtype = torch.float32).reshape(5, 4)
B = A.clone()# 通过分配新内存,将A的一个副本分配给B
print(A)
print()# 控制换行的小技巧
print(A + B)(5)总结
如果我们在后续计算中并没有重复使用x的话,我们也可以使用 x[ : ] = x + y 或者 x += y来进行原地操作减少内存开销
(6)其余赋值函数
1. NumPy是非常基础的多元数组的运算框架,不论何种框架都可以通过NumPy进行转换
import torch
x = torch.arange(12)
A = x.numpy()
B = torch.tensor(A)
print(f"type(A)={type(A)}, type(B)={type(B)}")2. 将大小为1的张量转换为Python标量
import torch
a = torch.tensor([3.5])
print(a, a.item(), float(a), int(a))三、数据预处理
1.创建数据集
比如我们创建一个人工数据集,并存储在csv(逗号分割值)文件里面
import os #注意是小写!
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n')
# 列名——NumRooms的意思是有多少个房子,alley的意思是”我进门的路径“是什么样的,price意思是卖多少钱
f.write('NA, Pave, 127500\n') # NA意思是未知的数据,Pave的意思是已经铺路了?
f.write('2, NA, 106000\n')
f.write('4, NA, 178100\n')
f.write('NA, NA, 140000\n')
# 接下来从pandas库去加载创建的csv文件里面的原数据集
import pandas as pd
data = pd.read_csv(data_file)
print(data)2. 修改数据集
1.插值
import os
import torch
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名——NumRooms的意思是有多少个房子,alley的意思是”我进门的路径“是什么样的,price意思是卖多少钱
f.write('NA, Pave, 127500\n') # NA意思是未知的数据,Pave的意思是已经铺路了
f.write('2, NA, 106000\n')
f.write('4, NA, 178100\n')
f.write('NA, NA, 140000\n')
# 接下来从pandas库去加载创建的csv文件里面的原数据集
import pandas as pd
import numpy as np
data = pd.read_csv(data_file)
data['Alley'] = data['Alley'].replace(' NA', np.nan)
print(data)
# 插值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]# iloc的意思是index location
inputs = inputs.fillna(inputs.mean(numeric_only=True))# 隐形大坑点!!!这里必须加上这个numeric_only=True!
print(inputs)对于NaN,我们将其视为一个类别,具体的将Pave跟NaN转换成数据类别的方法如下:
那如果想把这样的结果转换成数字类型呢(比如浮点数——有利于神经网络传播),方法如下(在前面的代码的前提下加上一些代码):
import os
import torch
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n')
f.write('NA, Pave, 127500\n')
f.write('2, NA, 106000\n')
f.write('4, NA, 178100\n')
f.write('NA, NA, 140000\n')
# 接下来从pandas库去加载创建的csv文件里面的原数据集
import pandas as pd
import numpy as np
data = pd.read_csv(data_file)
data['Alley'] = data['Alley'].replace(' NA', np.nan)
# 插值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean(numeric_only=True))
inputs = pd.get_dummies(inputs, dummy_na=True)
x, y = torch.tensor(inputs.values.astype(np.float32)), torch.tensor(outputs.values) # 进行类型转换后就可以了
print(x, y)需要注意的是:CPU更擅长数据的预处理(比如逻辑判断语句等),GPU并不擅长这些
- GPU 擅长:规则的、大规模并行计算(如矩阵乘法、卷积)
- CPU 擅长:复杂的逻辑判断、字符串处理、条件分支
优化数据时的预处理花费的时间其实是必要的,更有利于后期GPU”大展身手“
四、线性代数
1. 哈达玛积
定义:两个矩阵的按元素的乘法。在数学上记为⊙
2. 指定维度轴相加
axis=0的意思是:把每个block里面(即0~19这个block,跟20~39这个block里面)对应行里面的每个对应的元素加起来,然后合并为一行。换句话说,就是把第0维(两个block)相加。

axis=1的意思是:把第 1 维(也就是每块里的 5 行)加起来。换句话说,就是比如第一列,我们把0跟4以及8 12 16加起来
顺带补充以下axis = [0, 1]:是前两者的结合体,但不代表直接把计算结果简单相加——那违背了这种模式下的计算原则
具体例子解析如下

import torch
"""
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]],
[[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31],
[32, 33, 34, 35],
[36, 37, 38, 39]]])
"""
A_sum_axis0 = A.sum(axis=0)
print(A_sum_axis0)
print()
print(A_sum_axis0.shape)
print()
A_sum_axis1 = A.sum(axis=1)
print(A_sum_axis1)
print()
print(A_sum_axis1.shape)
print()
print(A.sum(axis = [0, 1]))3. 求平均值

我的问题:1.为什么要在In[20]那里写shape[0]
答:
2. 那如果遇到了axis取[0, 1]怎么办?
答:
遇到的问题:
这表明我忽略了一个问题——在计算平均数时,只有浮点数才能用于计算
原因:在Torch/PyCharm里面,默认在计算的时候不改变存储的数据类型,但是在计算平均数的时候,难免会有浮点数的出现。但!如果出现了浮点数,在PyCharm想存储计算结果的时候,发现——那个张量只允许存储整数类型——这就是冲突的点!!!
import torch
# 先表示标量——由只有一个元素的张量表示
x = torch.tensor([3.0])
y = torch.tensor([2.0])
print("张量之间的计算结果: ")
print(f"x + y 的结果是:{x + y}")
print(f"x * y 的结果是:{x * y}")
print(f"x / y 的结果是:{x / y}")
print(f"x ** y 的结果是:{x ** y}")
print()
A = torch.arange(20*2, dtype= torch.float32).reshape(2, 5, 4)
print(f"A张量的内容是:{A}")
print()
print(f"A张量的形状是:{A.shape}")
print()
print(f"A张量求和结果是:{A.sum()}")
print()
"""
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]],
[[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31],
[32, 33, 34, 35],
[36, 37, 38, 39]]])
"""
# 按维度轴求和
A_sum_axis0 = A.sum(axis=0)
print(f"A按照第0维求和结果是:{A_sum_axis0}")
print()
print(f"A按照第0维求和结果的形状是:{A_sum_axis0.shape}")
print()
A_sum_axis1 = A.sum(axis=1)
print(f"A按照第0维求和结果是:{A_sum_axis1}")
print()
print(f"A按照第1维求和结果的形状是:{A_sum_axis1.shape}")
print()
A_sum_axis_0_1 = A.sum(axis=[0, 1])
print(f"A按照第[0, 1]维求和结果是:{A_sum_axis_0_1}")
print()
print(f"A按照第[0, 1]维求和结果的形状是:{A_sum_axis_0_1.shape}")
print()
# 求均值
print(f"求均值的结果:按照A.mean(), A.sum() / A.numel()的方式结果是:")
print(f"{A.mean()}, \n, {A.sum() / A.numel()}")
print()
print(f"求均值的结果:按照A.mean(axis = 0), A.sum(axis = 0) / A.shape[0]的方式结果是:")
print(f"{A.mean(axis = 0)}, \n, {A.sum(axis = 0) / A.shape[0]}")
print()
# 计算总和或均值时保持轴数不变
print("计算总和时保持轴数不变")
print("保持第1维这个轴计算结果如下:")
sum_A = A.sum(axis = 1, keepdims = True)# 这个keepdims对使用广播机制而言非常好用
print(sum_A)
print()
# 通过广播机制将A除以sum_A——两个张量的大小、维度必须一样
print("通过广播机制将A除以sum_A的计算结果如下:")
print(A / sum_A)
print()
# 通过某个轴计算A元素的累积总和
print(f"通过某个轴计算A元素的累积总和:(以第0维为例)\n{A.cumsum(axis = 0)}")
# 点积——相同位置的按元素乘积的和
x = torch.arange(4, dtype= torch.float32)
y = torch.ones(4, dtype=torch.float32)
print(f"x张量是:{x}")
print()
print(f"y张量是:{y}")
print()
print("这两个张量进行点积运算的结果是:")
print(torch.dot(x, y))
print()
# 按元素乘法,然后进行求和来表示两个向量的点积
print("按元素乘法,然后进行求和来表示两个向量的点积——张量保持不变")
print(torch.sum(x * y) )
4. 矩阵向量积Ex
结果是一个长度为m的列向量,其i^th元素是点积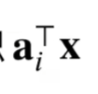
import torch
print(f"先来看一下E这个张量的大小,以及x这个张量的大小:")
E = torch.arange(20, dtype= torch.float32).reshape(5, 4)
x = torch.arange(4, dtype = torch.float32)
print(E.shape, '\n')
print(x.shape, '\n')
print("再来看一下矩阵乘以向量的结果——")
print(torch.mv(E, x))5. 矩阵乘法BE
我们可以将矩阵-矩阵乘法BE看作是简单地执行m次矩阵-向量积,并将结果拼成 一个n × m的矩阵
import torch
E = torch.arange(20, dtype= torch.float32).reshape(5, 4)
B = torch.ones(4, 3)
print("我们可以将矩阵-矩阵乘法BE看作是简单地执行m次矩阵-向量积,并将结果拼成 一个n × m的矩阵")
print()
print(f"B矩阵是这样的:{B}")
print(f"它的形状是{B.shape}")
print()
print("这两个(E跟B)矩阵计算结果是:")
print(torch.mm(E, B))6. 矩阵范数(norm)L2
L2范数是向量元素平方和的平方根
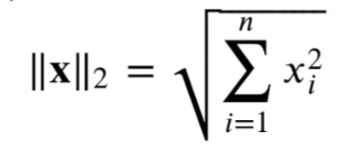
import torch
u = torch.tensor([3.0, -4.0])
print(f"u这个向量长这个样子:{u}")
print(f"u向量的L2范数是:{torch.norm(u)}")
print()7. 矩阵范数L1
它表示为向量元素的绝对值之和
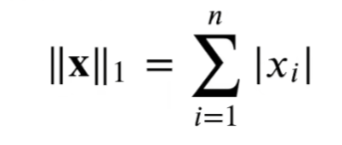
import torch
u = torch.tensor([3.0, -4.0])
print(f"u的L1范数结果是:{torch.abs(u).sum()}")8. 矩阵范数拓展——佛罗贝尼乌斯范数
它是矩阵元素的平方和的平方根
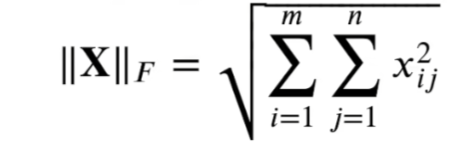
import torch
print( torch.norm( torch.ones( (4, 9) ) ) )9. 常出错点的复盘

这样的报错是因为:不同维度的张量,不能用于比较。
五、矩阵计算
因为在数学里面的算法跟编程里面的不同,所以不做解释了,前面也解释过了
六、自动求导
1. requires_grad()函数
在计算梯度之前,我们需要一个地方来存储梯度。
我们便用requires_grad()函数——用于跟踪梯度的函数,True表示——需要追踪
注:以下的代码不要运行!仅仅作为例子存在!
x = torch.arange( 4.0, requires_grad(True) )然后是y = 2( x · x )函数的求导实现:
y = 2 * torch.dot(x, x)# dot的意思是x求内积(毕竟是两个x做 · 乘嘛)输出结果如下——如果真想看结果
import torch
x = torch.arange(4.0)
x.requires_grad_(True)# 等价于x = torch.arange(4.0, requires_grad = True)
print(x.grad)# 默认值是None
# 计算y
y = 2 * torch.dot(x, x) #回顾一下——dot的意思是内积计算——x·x
print(y)输出结果里面的grad_fn=<MulBackward0>的意思是:这是一种规则,我(这个张量)是通过乘法运算得到的,如果你要对我进行反向求导,请使用“乘法的求导规则”。
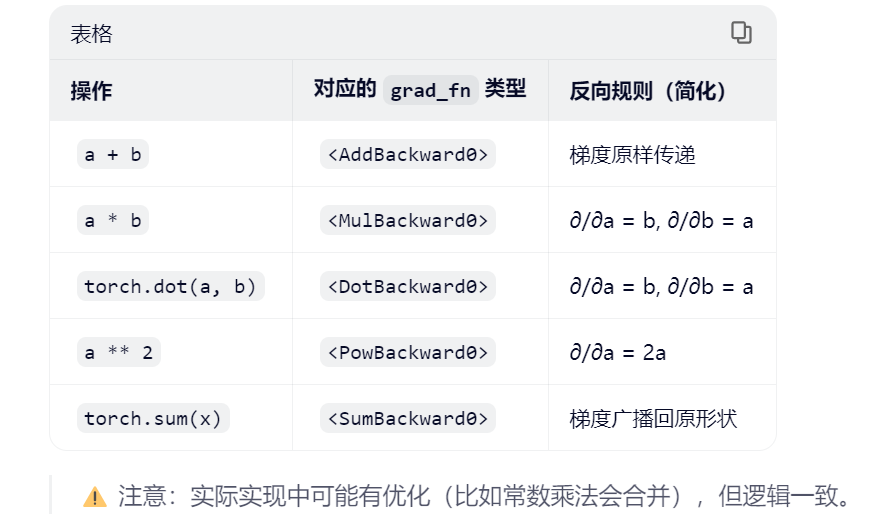
2. .backward()函数
在完成了上述计算后,我们便可以通过调用反向传播函数来自动计算y关于x每个维度的梯度
y.backward()
print(x.grad)检验——
x.grad == 4 * x最后的输出结果——
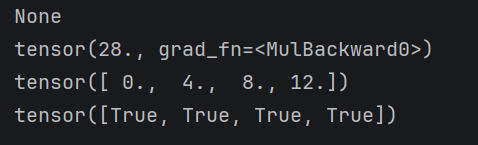
我们来解释一下第三行的输出结果——

3. .grad.zero_()函数
这个函数的用法是——如果我们要计算别的函数的话(即一共不止1个函数),那么我们可以调用上面的函数。因为:在默认情况下,Torch会累积梯度,我们需要清除之前的值
import torch
x = torch.arange(4.0, require_grad = True)
# 接下来给x的梯度清零
x.grad.zero_()
# 开始求y关于x的另一个函数——x.sum()
y = x.sum()
# 开始求梯度/求导
y.backward()
# 检验:自动求导结果
print(x.grad)问个问题——为什么需要用这个函数?如果不用会怎么样?
注释前的输出结果如下:
注释后的输出结果如下:
其实这是可以得到解释的——
还记得最开始我们的函数自动求导之后的结果吗——应该是上面的结果,但由于我们注释掉了x.grad.zero_(),那么之前累积的梯度便不会被清空,会随之而被带入到接下来的梯度计算里面
4. 对非标量求导
在深度学习中,我们的目的不是计算微分矩阵,,而是批量中每个样本单独计算的偏导数之和
什么是非标量?是有方向的而不是只有大小的量。
那既然有方向,我们就得明确求导方向呀。但是backward函数只能对标量使用
在训练神经网络时,我们不是要算一个复杂的“雅可比矩阵”(所有输出对所有输入的偏导),而是只想知道:每个参数对整个 batch 的总损失(或平均损失)的“总影响”是多少——也就是把每个样本的偏导数加起来(或取平均)。
让我们来回顾一下雅可比矩阵:
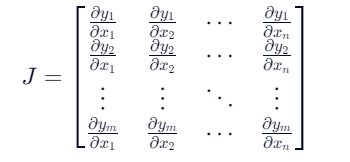

(batch是样本的意思)

5. 为什么要求平均损失?
使用平均损失(而不是总和)可以让梯度的大小与 batch size 无关,从而让学习率(learning rate)在不同 batch size 下保持稳定,训练更可控。
还记得更新梯度下降处理之后的结果的公式吗?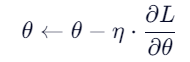
这里的η就是学习率,而学习率参考损失结果,如果学习率太大,会导致每一次调整的步长太大导致处理结果变化太大(比如求原点的切线斜率);如果学习率太小,则导致每一次调整都幅度太小,很浪费算力。
而我们之所以选择平均损失而不是总和,就是因为——平均跟总和之间,隔着个1/n。求平均之后,这一步的计算结果会相对总和小很多,而且η是有取值范围的要求的——在0到1之间。
6. 对非标量的求导的代码实现
注:这里就省略了前面的一部分代码了
x.grad.zero_()
y = x * x
y.sum().backward()
print(x.grad)7. 将某些计算移动到记录的计算图之外
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
print(x.grad == u)我解释一下为什么最终输出全是True:
在计算过程中,u不会被追踪到后续的梯度追踪中,也就实现了7. 里面的“移动”,也就是说:z的梯度计算结果,其实就是u本身。但!u本身是标量!!!所以能参与进正常的张量计算中。而且由前面可知,其实u的结果是[0, 1, 4, 9](x = 1.0, 2.0 , 3.0, 4.0)——关注u的数值!而且对z的求导结果,会存入x.grad中!于是x.grad的结果,也会是[0, 1, 4, 9](python不管那些别的,就看结果)
七、线性回归
请注意:w是权重,b是偏置,features是特征输入(对应x的值),labels是标签(对应y的值——模型的真实输出)
以上内容以后不再赘述,请读者知悉。
从零开始实现的话,会包括数据流水线、模型、损失函数、小批量随机梯度下降优化器……
1. 人造数据集
我们可以根据带有噪声的线性模型构造一个人造数据集。我们使用线性模型参数来实现,比如

这里的w表示的是权重(参数),b表示偏置项,最后面的那个常数项表示随机噪音,让我们的拟合结果更真实
①代码版本
| 参数 | 类型 | 含义 | 举例 |
|---|---|---|---|
w |
torch.Tensor |
真实权重向量(我们假装知道的“真相”) | tensor([2.0, -3.4]) |
b |
float 或 Tensor |
真实偏置(截距) | 4.2 |
num_examples |
int |
要生成多少条样本(数据点) | 1000 |
w的长度决定了每个样本有多少个特征
# 线性回归从0实现
import random
import torch
from d2l import torch as d2l
# from test import features
from GPU_utils import warm_GPU
warm_GPU.warmup_gpu()
"""
根据带有噪声的线性模型构造一个人造数据集。我们使用线性模型参数来搞
"""
"""----------------1. 生成数据----------------"""
def synthetic_data(w, b, num_examples):# 训练样本
"""生成y = Xw + b + 噪声"""
# w = [2, -3.4], b = 4.2
"""
·w 是我们要“假装知道”的权重(比如你认为某个变量对结果影响大)
·b 是偏置项(常数项,类似“基础值”)
·num_examples 是你想生成多少条数据(比如1000条)
"""
x = torch.normal(0, 1, (num_examples, len(w)))
# 均值是0,标准差是1,形状是(num_examples, len(w))
"""
·生成一个形状为 (num_examples, len(w)) 的张量 X
·每个元素是从 标准正态分布 中随机抽取的(均值=0,方差=1)
·len(w) 表示有多少个特征(比如有两个特征:年龄、身高)
"""
y = torch.matmul(x, w) + b# 矩阵计算——模拟生成线性回归的拟合线
y += torch.normal(0, 0.01, y.shape)
"""
这里的0是均值,0.01是标准差
"""
# 加入噪声——随机误差——模拟不完美——毕竟线性拟合还得是有“反面教材”嘛
"""
reshape((-1, 1)) 是为了确保每个标签都单独成一列,方便后续处理(比如喂给神经网络时格式统一)
"""
return x, y.reshape((-1, 1))# 这里的reshape的意思是——我们经过刚才的xw计算之后,
"""
接下来是接收批量大小、特征矩阵和标签向量作为输入的函数,它生成大小为batch_size的小批量
"""
"""----------------2. 数据迭代器----------------"""
def data_iter(batch_size, features, labels):
"""
还记得全局以及局部变量吗——你这样定义其实没什么,只是同名而已,作用不同的——毕竟这里的features】labels只是形参而已
"""
num_examples = len(features)
indices = list( range(num_examples) )# 搞索引
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = indices[i:min(i + batch_size, num_examples)]
yield features[batch_indices], labels[batch_indices]
"""
回归模型函数
"""
"""----------------3. 模型定义----------------"""
def linreg(X, w, b):
"""
线性回归模型
"""
return torch.matmul(X, w) + b
"""
损失函数——均方损失版
"""
"""----------------4. 损失函数----------------"""
def squared_loss(y_hat, y):
return ( y_hat - y.reshape(y_hat.shape) ) ** 2 / 2
"""
小批量随机梯度下降
"""
"""----------------5. 优化算法----------------"""
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
"""
以下是主函数部分
"""
if __name__ == "__main__":
"""
1 synthetic_data——生成数据
"""
true_w = torch.tensor([2, -3.4])
true_b = 4.2
# w → (2, 1)
# b → (1,)
features, labels = synthetic_data(true_w, true_b, 1000)
# features → (1000, 2)
# labels → (1000, 1)
print(f"features : {features[0]}")
print(f'labels : {labels[0]}')
d2l.set_figsize()
# matplotlib.pyplot.rcParams['figure.figsize'] = (x, y)
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)
"""
2 data_iter
"""
batch_size = 10
for x, y in data_iter(batch_size, features, labels):
print(x, '\n', y, '\n')
break
"""
定义、初始化模型参数
"""
"""
这里是我们给模型的值,模拟模型一开始“乱猜”
"""
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True) # w是从正态分布里面取值
b = torch.zeros(1, requires_grad=True)
"""
训练过程
"""
lr = 0.03
num_epochs = 3 # 全部数据扫描3遍
net = linreg # 给函数起别名
loss = squared_loss # 给函数起别名
for epoch in range(num_epochs):
for x, y in data_iter(batch_size, features, labels):
l = loss(linreg(x, w, b), y)
l.sum().backward()
sgd([w, b], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
"""
比较真实参数跟通过训练学到的参数来评估训练的成功程度
"""
print(f"w的估计误差:{true_w - w.reshape(true_w.shape)}")
print(f"b的估计误差:{true_b - b}")②具体的机制解释(synthetic函数到到print处)
第一步:我们先确定一个“正确答案”,比如如上代码中所述的列向量版的,然后我们生成输入特征x(即features)
x = torch.normal(0, 1, (num_examples, len(w)))又因为我们自己有“心中所属”(具体解释就是我们的w = [2, -3.4], len(w) = 2, num_examples = 1000),所以变成了这样的代码——
x = torch.normal(0, 1, (1000, 2))它是生成一个1000行, 2列的张量(类似表格),每个格子里面填一个来自标准正态分布的随机数。
第二步:用真实公式算理想输出y
y = torch.matmul(x, w) + b(以下只是举个例子,实际计算中python是并行 / 批量计算的)

请注意:在实际的计算机计算中,b是最后统一通过广播机制加上的
(注:以上的图已包含第三步:计算真实y)
第四步:调整标签形状reshape( (-1, 1) )——工程细节
首先来解释一下为什么要这样干:
1. 我们经过了wx的计算后,本来是二维的wx因为矩阵计算而变为了一维的了,形状是(1000,),是一维数组,我们需要把它变成二维的列向量(本质上是n*1的矩阵)
对比一下就知道了——
"""
reshape 前 (1000,)
"""
tensor([9.28, 0.88, -2.1, ...])
"""
reshape 后 (1000, 1)
"""
tensor([[9.28],
[0.88],
[-2.1],
...])2. 在后续训练的时候,模型的输出通常是(batch_size, 1),而损失函数(比如MSE)要求预测值和真实标签形状一致
3. 针对(-1, 1)的解释
-1表示“我不知道一共多少个元素,你(解释器/python)自己帮我算然后你自己心里(虽然没有心,叫内存)有个数”,1表示我需要你帮我把这些数据的格式改成n行1列
这比写死 y.reshape((1000, 1)) 更通用——无论你生成 100 条还是 10000 条数据,(-1, 1) 都能正确工作!
第五步:拿到样本
features, labels = synthetic_data(true_w, true_b, 1000)
print(f"features : {features[0]}") # 打印第一个样本的两个特征
print(f'labels : {labels[0]}') # 打印第一个样本的标签假设输出如下:
features : tensor([0.5000, -1.2000])
labels : tensor([9.2920])那就说明第一个输入是x = [0.5000,-1.2000], 输出是y = 9.2920(或者一个接近这个值的值)
| 值 | 说明 | |
|---|---|---|
true_w |
torch.tensor([2, -3.4]) |
真实权重(我们假装知道的“真相”) |
true_b |
4.2 |
真实偏置(截距) |
1000 |
int |
要生成多少条样本 |
③补充解释
1. d2l.set_figsize()
上面那一行d2l.set_figsize()是李沐封装好的的一个函数,其内部调用
matplotlib.pyplot.rcParams['figure.figsize'] = (x, y)如果我们默认不设置括号里面的值的话,Matplotlib 画的图会很小,看不清细节
不过如果想设定大小的话,可以这样调用函数
d2l.set_figsize((6, 4))顺带补充:
d2l是李沐的Dive into deeplearning里面提供的一个辅助库
2. d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)
这一行是绘图的核心代码。我们可以分解开来:
①d2l.plt——它是matplotlib.pyplot的别名,李沐为了统一接口,就把plt放在了d2l里面,等价于
import matplotlib.pyplot as plt
plt.scatter(...)②features[:, 1]——假设features是一个形状为(1000, 2)的张量(1000个张量,2个特征)那么[:, 1]表示取所有样本中的第二个特征(对应索引是1——从0开始计数),结果就是一个长度为1000的一维张量,比如[X1,2, X2,2, ..., X1000,2]
目的:看第二个特征跟标签值之间的关系是否解决线性
③detach()——毕竟features很可能是带有梯度计算历史的张量(比如参与过模型训练或者自动求导什么的),PyTorch默认会记录张量计算图(用于反向传播更新参数),但Matplotlib不能直接出来这种“带梯度”的张量,所以detach的作用激素切断该张量于计算图的连接,返回一个不需要梯度的新张量。
如果不加这个,可能会有如下报错:
Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.④numpy()——可将PyTorch张量(tensor)转换为NumPy数组,因为matplotlib.pyplot.scatter只能够接收NumPy数组或Python列表,不能直接用torch.Tensor
流程如下:
![]()
⑤s = 1——s的意思是scatter plot中点的大小,s = 1表示画非常小的点,避免点因为直径过大而挤在一起
综上,d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)这行代码的意思是:绘制散点图,横轴是所有样本的第 2 个特征值,纵轴是对应的标签值,每个点非常小(s=1),以便观察整体分布趋势。
| 代码 | 含义 |
|---|---|
synthetic_data(...) |
生成人工数据(返回 (X, y) 元组) |
features, labels = ... |
解包赋值,分别拿到特征和标签 |
| 必须两个变量接收 | 否则会把 tuple 当成一个整体,导致后续 .detach() 报错 |
③常见报错及其原因
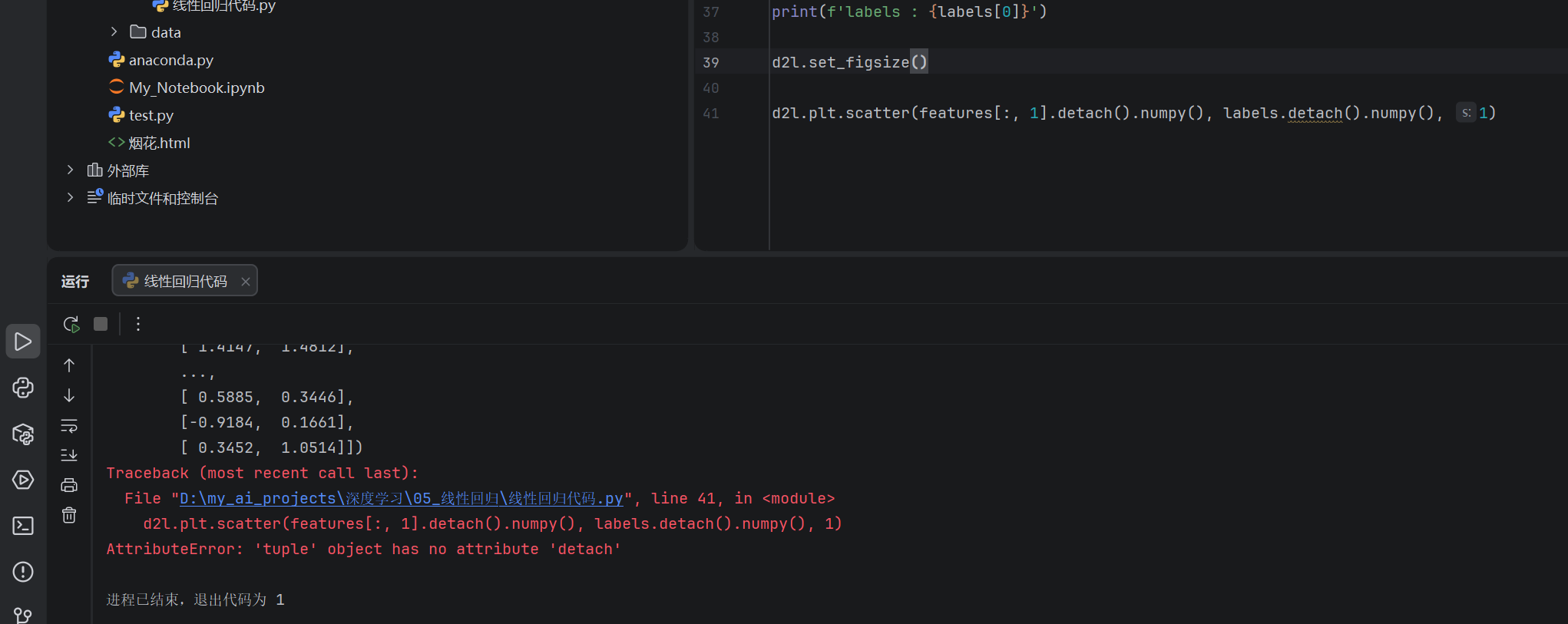
这是因为在原来的代码里面,我没有用两个变量去接收synthetic_data(true_w,true_b,1000)的计算结果。其中输出的features(特征)中的每一行都包含一个二维数据样本,labels(标签)中的每一行都包含一维标签值(一个标量)
④具体机制解释(data_iter函数以及主函数里的部分)
import random
import torch
from d2l import torch as d2l
def data_iter(batch_size, features, labels):
"""
还记得全局以及局部变量吗——你这样定义其实没什么,只是同名而已,作用不同的——毕竟这里的features】labels只是形参而已
"""
num_examples = len(features)
indices = list( range(num_examples) )
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = indices[i:min(i + batch_size, num_examples)]
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for x, y in data_iter(batch_size, features, labels):
print(x, '\n', y, '\n')
break| 参数 | 类型 | 说明 |
|---|---|---|
batch_size |
int |
每次返回多少条样本(如 10) |
features(局部变量) |
torch.Tensor |
全部输入特征,形状 (N, d) |
labels(局部变量) |
torch.Tensor |
全部标签,形状 (N, 1) |
第一步:确定数据样本的长度——
num_examples = len(features)取features的第零维内容(1000)(len(features)其实等价于features.shape[0])比如:
features.shape = (1000, 2)第二步:创建索引并打乱
indices = list( range(num_examples) )
random.shuffle(indices)为什么要打乱?
·防止模型“记住顺序”(比如前100个都是高 y 值)
·随机性有助于梯度下降跳出局部最优
·是训练神经网络的标准实践
注意:random.shuffle 是 in-place 操作,直接修改 indices 列表
in-place 操作是直接改变给定线性代数、向量、矩阵(张量)的内容而不需要复制的运算。
——Python教程
第三步:分批遍历(核心循环)
for i in range(0, num_examples, batch_size):第四步:取当前batch(中文意思是——批次)索引
batch_indices = indices[i:min(i + batch_size, num_examples)]为什么用min?
· 防止越界,因为最后的batch可能不足batch_size,比如num_examples = 1005, batch_size = 10(不断以10为一组分组之后,最后一组只有5个而不足10个)
更常见的写法是i : i + batch_size其实,因为python会自动处理越界(懒人式写法),不过显示写min也完全正确,适合新手理解原理
第五步:返回一个batch(使用yield)
yield features[batch_indices], labels[batch_indices]首先解释一下什么是yield

它的优点是:内存高效,不需要一次性把所有的batch存在内存里面。可以节省空间。
yield后的代码行为解释:
features[batch_indices]会按照batch_indices中的顺序取对应行,比如batch_indices = [342, 78, 12] ➡ 返回第342、78、12行
⑤补充解释
batch_size = 10
for x, y in data_iter(batch_size, features, labels):
print(x, '\n', y, '\n')
break执行过程——
1. 调用data_iter(10, features, labels)
2. 函数内部打乱索引,进入循环
3. 第一次yield返回第一个batch(10个一组)
4. x 是(10, 2)的tensor,y是(10, 1)的tensor
5. break退出循环,只打印第一批
接下来解释为什么x 是(10, 2)的tensor,y是(10, 1)的tensor:
回到一开始的代码——
def synthetic_data(w, b, num_examples):
x = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(x, w) + b
y += torch.normal(0, 0.01, y.shape)
return x, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4]) # len(w) = 2
features, labels = synthetic_data(true_w, true_b, 1000)
最后一步就是输出结果。
⑥回归模型函数
def linreg(X, w, b):
"""
线性回归模型
"""
return torch.matmul(X, w) + b
"""
定义、初始化模型参数
"""
"""
这里是我们给模型的值,模拟模型一开始“猜”
"""
w = torch.normal(0, 0.01, size = (2, 1),requires_grad=True)# w是从正态分布里面取值
b = torch.zeros(1, requires_grad=True)注意:这里的w、b是我们给模型的随机值——模拟模型一开始会猜,然后不断通过梯度下降去更新。前文所叙的true_w,true_b是“正确答案”
⑦损失函数
"""
损失函数
"""
def squared_loss(y_hat, y):
return ( y_hat - y.reshape(y_hat.shape) ) ** 2 / 2
"""
小批量随机梯度下降
"""
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()问个小问题:
说是均方损失,那均方损失具体的体现去哪了?
答:藏在了这一行:
param -= lr * param.grad / batch_size里的batc_size里了。
具体机制解释:
小批量随机梯度下降是执行一次随机梯度下降(SGD)更新:用当前梯度调整模型参数,并清零梯度,为下一次迭代做准备。以上的sgd函数是从零开始实现的优化器,替代了torch里面的torch.optim.SGD
| 参数 | 类型 | 含义 |
|---|---|---|
params |
list of torch.Tensor |
要优化的参数列表,比如 [w, b] |
lr |
float |
学习率(learning rate),控制更新步长 |
batch_size |
int |
当前小批量的样本数 |
调用这个函数的方式会是:
sqd([w, b], lr=0.03, batch_size=10)第一步:
with torch.no_grad():我的解释:由于小批量随机梯度下降需要用当前的梯度去调整参数并且清零梯度,所以优化器需要“刹车”(断开梯度追踪)去调整参数。而且梯度更新(param -=...那一行代码)是优化步骤,而不是模型前向计算的一部分。
| 步骤 | 操作 | w.grad 的值 |
|---|---|---|
| 第1次 backward | 计算梯度 | [1.2] |
| 第2次 backward | 再次计算 | [1.2 + 新梯度] ⬅ 错了! |
如果不关掉的话,torch会试图去记录“参数更新”这个操作的梯度,并导致如下灾难:
· 内存爆炸
· 计算图无限增殖
· 报错/训练失败
而且,我们在更新参数时,还是建议清空梯度,这样的话模型下次进行更新时就可以忘掉之前的“误差”而专注于当下的更新
总结来说就是这个意思:
| 动作 | 作用 | 类比 |
|---|---|---|
| 用梯度调整参数 | 让模型更接近真实规律 | 往山下走一步 |
| 清零梯度 | 避免历史梯度干扰 | 扔掉旧地图,用新地图 |
| 为下一次准备 | 确保下次更新基于最新状态 | 准备好下一次感知 |
第二步:
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()遍历所有要优化的参数,然后根据数学中的梯度下降公式去更新参数
以w为例——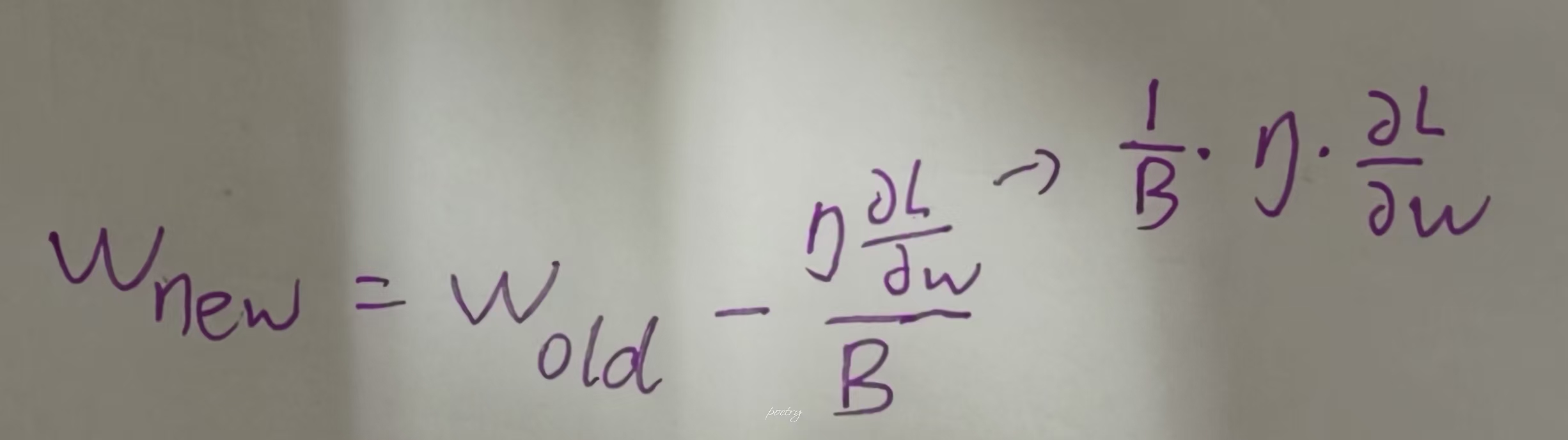
⑧训练过程
"""
训练过程
"""
lr = 0.03
num_epochs = 3# 全部数据扫描3遍
net = linreg# 给函数起别名
loss = squared_loss# 给函数起别名
for epoch in range(num_epochs):
for x, y in data_iter(batch_size, features, labels):
l = loss(linreg(x, w, b), y)
l.sum().backward()
sgd([w, b], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')具体解释:
第一步:设置超参数(学习率lr、循环次数num_epochs)
第二步:给函数起别名——方便后续修改函数(不需要每次都敲linreg、squared_loss那么长)
第三步:开始循环(外层)
第四步:开始循环(内层)——每次返回一个batch(设定为10个)的特征(shape = (10, 2))以及标签(shape = (10, 1))
第五步:计算当前batch批量的损失
l = loss(linreg(x, w, b), y)第六步:反向传播
l.sum().backward()为什么用 l.sum()?
答:l 是 (10, 1),不能直接 .backward()——shape对不上——PyTorch 要求反向传播的起点是一个标量(scalar),所以先求和(或用 .mean())变成一个数
第七步:执行参数更新
sgd([w, b], lr, batch_size)具体优化器(sgd)代码如下——(回顾一下)
"""
小批量随机梯度下降
"""
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()第八步:评估模型性能
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')补充:这里的 : f 的意思是:以默认的浮点数格式输出(默认保留后6位)
逐行解释:
1. with torch.no_grad():评估时不需要计算梯度,节省内存
2. net(features, w, b):用全部数据做线性回归预测,shape (1000, 1)
3. loss(..., labels):计算每个样本的损失,shape (1000, 1)
4. print(...):打印标量平均损失(因为有mean)
具体解释一下为什么shape是(1000, 1):
一、回顾数据(已生成的):
1. 全局变量
(具体推导见前文,此处不再赘述)
# features → (1000, 2) # labels → (1000, 1)
2. 模型参数:
# w → (2, 1) # b → (1,)
二、net(features, w, b)的计算过程
先看linreg函数具体代码
"""
回归模型函数
"""
def linreg(X, w, b):
"""
线性回归模型
"""
return torch.matmul(X, w) + b现在如此调用:
train_l = loss(net(features, w, b), labels)然后我们来看形状的变化过程:
首先在linreg函数里,因为返回torch.matmul(X, w) + b,又因为此时features.shape = (1000, 2),并且w.shape = (2, 1)(视角切换到“如此调用” + “一、1.模型参数w.shape”处),根据matmul函数的要求——矩阵计算(也就是我们常说的“降维打击”)——原本shape是(1000, 2)的features,因计算之后,形状变成了(1000, 1)
画图解析如下——(注:仅是举例子以便于描述,而不是带入具体真实数据在计算!)

最后的计算结果就化成了1000行、1列的二维列向量→shape = (1000, 1)
最后依旧再统一广播以加上b,不改变形状
综上——net(features, w)返回的形状就是(1000, 1)
# labels → (1000, 1)
三、train_l = loss(net(features, w, b), labels)的shape的变化过程:
"""
损失函数——均方损失版
"""
def squared_loss(y_hat, y):
return ( y_hat - y.reshape(y_hat.shape) ) ** 2 / 2为了方便表述,我们记net(features, w) = y_pred,那么原式便等价于:
train_l = loss(y_pred, labels)
即:squared_loss( (1000, 1), (1000, 1) )(这里的squared_loss写loss(...)也行)
最后的计算结果的shape依旧是(1000, 1)
损失函数里其他的涉及到计算的部分比如**2 以及最后的 / 2其实都不影响形状——因为这些计算是针对“元素”进行修改而不是针对形状

⑨比较真实参数跟通过训练学到的参数来评估训练的成功程度
"""
比较真实参数跟通过训练学到的参数来评估训练的成功程度
"""
print(f"w的估计误差: {true_w - w.reshape(true_w.shape)}")
print(f"b的估计误差: {true_b - b}")八、线性回归的简洁实现
数据预处理部分:
我们的目标是利用 PyTorch 内置的 DataLoader 和 TensorDataset,替代我们自己写的 data_iter 函数,实现更标准、更高效的数据加载
"""
直接调用d2l里的工具
"""
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
"""
调用框架中现有的API来读取数据
"""
def load_array(data_arrays, batch_size, is_train = True):
"""
构造一个PyTorch数据迭代器
"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
print( next( iter(data_iter) ) )我们整个函数的要实现的功能就是可以“自动分配批次(batch)并按指定批次大小读取数据、在训练时自动打乱要训练的数据”,返回一个可迭代的数据加载器对象
| 参数 | 类型 | 含义 |
|---|---|---|
data_arrays |
tuple of tensors |
比如 (features, labels) |
batch_size |
int |
每批多少样本 |
is_train |
bool |
是否打乱顺序(训练时打乱,测试时不打乱) |
具体机制解释:(load_array函数)
第一步:
首先来解释一下什么是TensorDataset——它是一个将多个张量打包成数据集的工具,要求所有的张量的第零维(即样本数)相同——自己按行打包数据,并且支持索引
其次data_arrays是什么意思—— * 是python的解包操作符,相当于data.TensorDataset(deatures, labels),它就相当于创建一个Dataset对象,并且TensorDataset还支持索引,比如Dataset[0]会返回(features[0], labels[0])
第二步:
return data.DataLoader(dataset, batch_size, shuffle=is_train)首先解释一下什么是DataLoader(...)——它是PyTorch的标准数据加载器,用于高效加载数据的核心类,它不直接存储数据,而是包装一个Dataset对象。功能包括:
1. 自动分batch
2. 自动打乱(shuffle = True)
3. 多进程加载(num_workers)
4. 自定义采样
……
具体解释:
第一步:data.DataLoader(...),解释如上。
第二步:dataset,它是上面创建的TensorDataset里的
第三步:batch_size = 10——无需多言,就是一个批次里有10组数据
第四步:返回值——是返回一个可用于后续调用时迭代的对象(代码示例如下)
for x, y in data_iter(batch_size, features, labels):
print(x, '\n', y, '\n')
break第三步:
batch_size = 10
data_iter = load_array((features, labels), batch_size)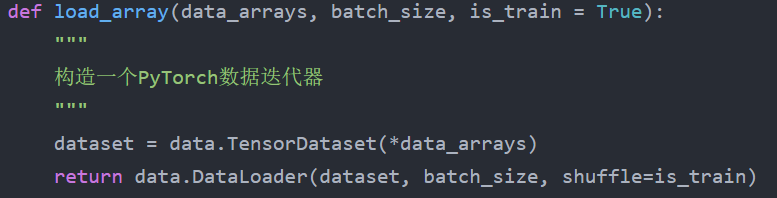
结合之前的load_array函数来看,(features, labels)被作为了一个data_arrays传入,batch_size不变,is_train就不必多言了。然后经过load_array函数处理,返回一个DataLoader对象data_iter
第四步:
查看一个batch的数据
print( next( iter(data_iter) ) )具体解释:
第一步:iter(data_iter)——把DataLoader转成迭代器

第二步:next(...)取第一个batch的数据
线性回归函数设置:
我们的目标是用PyTorch的nn.Sequential 和nn.Linear 构建一个线性回归模型,代替我们自己写的linreg函数——正式进入“深度学习框架时代”
具体机制解释:
第一步:导入神经网络模块(Neural Networks——神经网络)
from torch import nnnn包含:
1. 全连接层(Linear)
2. 顺序容器(Sequantial)
3. 激活函数(ReLU、Sigmoid)
4. 损失函数(Loss)
……
第二步:使用nn.Sequantial函数
net = nn.Sequential( nn.Linear(2, 1) )具体解释:
1. nn.Linear(2, 1)
· 输入维度:2(每个样本有2个特征)
· 输出维度:1(预测一个标量值)
总结:它实现的是y = <X T w> + b
2. nn.Sequantial()
· 它是一个顺序容器,把多个层按顺序堆叠起来。不过这里只有一层,所以效果上等价于括号里的nn.Linear(2, 1)——直接就是线性回归模型
但我们为了统一,所以还是把这个单层神经网络(线性回归)放到了Sequential函数里。
第三步:初始化参数
为啥要初始化?

net[0].weight.data.normal_(0, 0.01)具体解释:(目的是避免初始值太大导致梯度爆炸或者太小导致梯度消失)
1. net[0]:前文已有叙述表明Sequential函数的输出是列表式结构,第一层是net[0]
2. .weight:获取该层的权重参数(w),形状跟之前一样,依旧是(2, 1)
3. .normal_(0, 0.01):原地(in-place)用“均值=0、标准差=0.01”的正态分布填充
net[0].bias.data.fill_(0)具体解释:(目的是让初始预测值接近0,类似实现“0基础”预测)
1. .bias:获取偏置参数(b),形状(1,)
2. .data.fill_(0):原地把所有元素设为0
计算误差函数设置:
我们的目标是用PyTorch内置的损失函数和优化器,替代我们自己写的squared_loss和sgd函数,实现更简洁、标准的训练流程
"""
计算损失
计算均方误差用的是MSE loss类,即L2范数
"""
loss_2 = nn.MSELoss()
"""
实例化SGD实例
"""
trainer = torch.optim.SGD(net.parameters(), lr=0.03)loss_2 = nn.MSELoss()具体解释:
1. 创建一个均方误差(Mean Squared Error, or called MSE)损失函数的实例
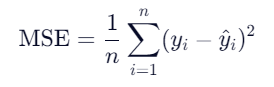
它返回的是标量,可直接用于.backward()函数(反向传播),会自动处理张量形状、求导等细节。
2. 创建一个随机梯度下降优化器(stochastic gradient descent, or called SGD),用于更新模型参数(好处——不需要自己手动传w、b的形状,框架会自动管理)
①这里的net.parametrs()实际上等价于这样的代码—
net.parametrs()实际上会自动返回模型中所有可学习参数:
→ weight( shape = (2, 1) )
→ bias( shape = (1,) )
②torch.optim.SGD是PyTorch内置的优化器类,实现了标准SGD更新规则,符合如下公式(以w为例):
训练模型过程设置:
用PyTorch的高级API(nn, optim)完成模型训练,与“从零实现”的逻辑完全一致,但更简洁、更标准
"""
训练模型过程
"""
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f"epoch {epoch}, loss {l : f}")具体解释:
第一步:依旧是设置训练轮数
第二步:依旧是对每次epoch(轮数)进行循环
第三步:计算w、b
for X, y in data_iter:data_iter来源如下——
data_iter = load_array((features, labels), batch_size)这个循环每次返回一个batch的w、b
第四步:前向计算预测值
1. net(X):将当前batch的特征输入模型中,得到预测值y_hat或者说y_pred,然后输出形状(batch_size, 1)
2. loss(...):计算预测值和真实值之间的损失——用MSE这个形式
3. 用L(小写的)这个标量存储计算结果
"""
等价写法
"""
l = loss(linreg(x, w, b), y)第五步:清空当前梯度
具体为什么,不再赘述了。

第六步:计算梯度
l.backward()自动计算所有可学习参数的梯度——.sum()而不是.mean()!
第七步:更新参数
trainer.step()第八步:评估整体性能
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:.f}')这里计算的就是整体的平均损失
完整代码呈现:
"""
直接调用d2l里的工具
"""
# import numpy as np
from torch import nn # nn是神经网络的缩写
import torch
from torch.utils import data
from d2l import torch as d2l
from GPU_utils.warm_GPU import warmup_gpu
warmup_gpu()
"""----------------1. 数据准备----------------"""
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
"""
调用框架中现有的API来读取数据
"""
"""----------------2. 数据迭代器----------------"""
def load_array(data_arrays, batch_size, is_train = True):
"""
构造一个PyTorch数据迭代器
"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
if __name__ == "__main__":
"""----------------3.1 加载数据----------------"""
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# print( next( iter(data_iter) ) )
"""----------------3.2 定义模型----------------"""
"""
使用框架的预定义好的层
"""
net = nn.Sequential( nn.Linear(2, 1) )
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
loss = nn.MSELoss()
"""
计算损失
计算均方误差用的是MSE loss类,即L2范数
"""
loss_2 = nn.MSELoss()
"""
实例化SGD实例
"""
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
"""
训练模型过程
"""
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f"epoch {epoch}, loss {l : f}")
"""
画图
"""
# 画 y 关于 x₂ 的散点图 + 拟合直线(标准做法)
"""
由于如果考虑x1的话,会导致图变为3D——不能直接在同一个二维图里同时画两个特征,所以我们选择只考虑x2
"""
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].numpy(), labels.numpy(), s=1)
# 下面的意思是表示在图上展示出来我们预测的值
# plt.plot(features[:, 1].numpy(), net(features).detach().numpy(), 'r-', linewidth=0.5)
d2l.plt.scatter(features[:, 1].numpy(), net(features).detach().numpy(), s=1, c='red')
d2l.plt.show()九、画图
①非包装成模块版
为了实现直观展现线性回归结果,我们选择用d2l里面的plt——d2l里实际上已经封装好了matplotlib的
"""
由于如果考虑x1的话,会导致图变为3D——不能直接在同一个二维图里同时画两个特征,所以我们选择只考虑x2
"""
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].numpy(), labels.numpy(), s=1)
d2l.plt.plot(features[:, 1].numpy(), net(features).detach().numpy(), 'r.', markersize=1)
d2l.plt.show()具体机制解释:
第一步:
d2l.set_figsize()这行代码的意思是:我们设置matplotlib图形的默认大小(宽高),d2l.set_figsize()是李沐d2l库中的一个辅助函数,默认将图形设为(3.5, 2.5)英寸(比较紧凑)
第二步:
d2l.plt.scatter(features[:, 1].numpy(), labels.numpy(), s=1)这行代码的意思是:画出真实数据的散点图——默认是蓝色的点
features[: , 1]:取所有样本的第二个特征(即x2),shape = (1000,)
numpy():把PyTorch张量转成NumPy数组——因为底层的matplotlib需要
labels:真实标签y,shape(1000, 1)→转numpy后可自动广播
s = 1:点的大小设为1(适合大量的点)
第三步:
d2l.plt.scatter(features[:, 1].numpy(), net(features).detach().numpy(), s=1, c='red')这行代码的意思是:用红色小点画出模型预测值——换句话说就是模型自己的答案
具体机制解释:
第一步:d2l.plt.scatter:它跟d2l.plt.plot的用法有一点不同:scatter只画点而不连线,适合无序数据——比如我们这次自己搞出来的那些人工数据。——表示我要画一个散点图
第二步:features[:, 1]:提取特征里的所有行里的第二列(在计算机里面默认从0开始计数),提取出来一个形状为(1000,)的数据——类比C语言里的数组这个概念就好理解些
第三步:.numpy():这个不再赘述了,就是为了兼容matplotlib所需要的数据的格式
第四步:net(features):也就相当于损失对features的所有x2进行线性回归函数的计算,经过计算后,结果就是shape = (1000, 1),每一行里就是一个模型输出的预测值
第五步:.detach():切断计算图,防止梯度回传——
1. 我们要把模型的输出值作为纵坐标里的指标,所以我们不能让模型输出的预测值带有梯度甚至继续梯度下降——毕竟我们要的是y_hat(模型输出的预测值)本身,而不是它梯度下降的结果。
2. 从另一个角度解释就是,我们在此阶段(画图)是不希望梯度下降这个进程继续跑的,所以我们为了让自己的评估过程生效,选择了切断梯度下降以及反向传播。就类似质检员在工厂里抽样调查时,会选择切断生产线的运转以便于ta就这些批次的产品进行抽样调查以减少误差。
不过需要注意的一点是:带有梯度的张量无法直接转成numpy
第六步:s = 1:这里我澄清一下:
1. 它表示的意思不是直径/半径为1去画出来一个点,而是表示画一个面积是1的点(也就是像素值为1的点,或者说是画一个占1个像素点的点,这一个像素点就表示了它的面积)
2. 在样本数量很多的情况下,尽可能把s设置小些
第七步:c = 'red':这里的c的意思是color,red是我们自己选的颜色——为了跟真实数据的蓝色区分,当然我们也可以换成其他颜色,这个不影响最终的画图,纯看个人喜好。
第四步:展示
d2l.plt.show()
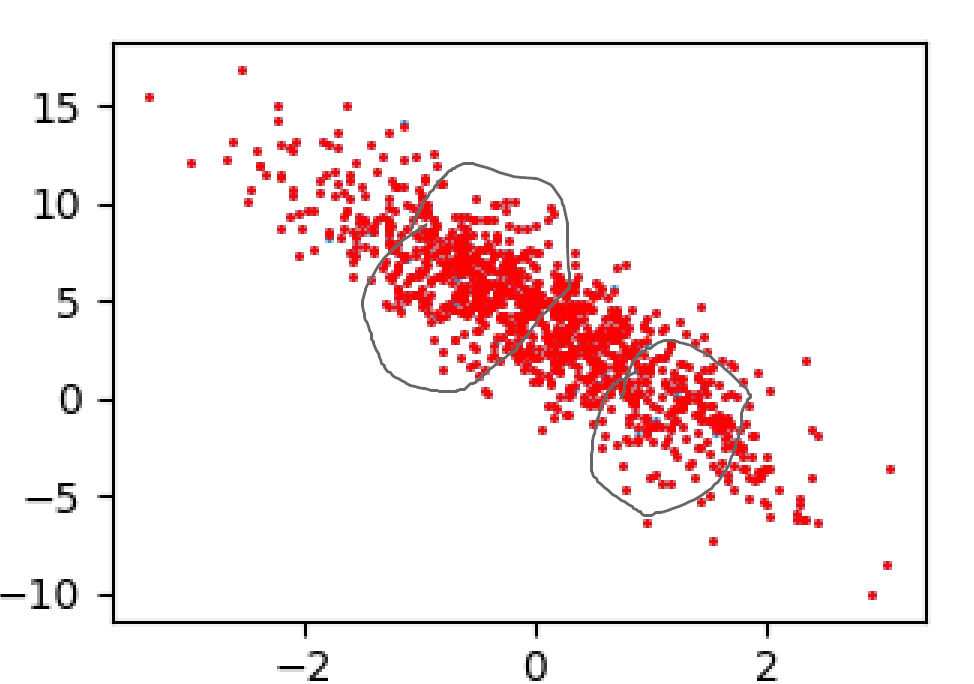
总结:
1. 如果图片效果显示红蓝重合度非常高的话,就说明你的模型学习的效果非常好
2. 不过因为我们加入了随机的“噪声”,所以如果存在未能完全拟合的点也是可以接受的,毕竟在实际生活中,我们都知道不可能存在绝对零误差。比如在下图中的黑圈处就是未能完全拟合好的部分(当然只是举例子,实际上下图未能完全拟合好的点远不止这些)
拓展:
实际上在画模型的输出时,有很多种画法,我们选择的是
d2l.plt.scatter(features[:, 1].numpy(), net(features).detach().numpy(), s=1, c='red')画出来的效果如下:
这里我着重辨析一下'r.'跟'r-':
1. 'r.'/'ro':它的意思是描点但不连线,作用等价于我们直接写plt.scatter(...),不过scatter功能更丰富,所以大家更偏向用scatter
2. 'r-':它的意思是描点并且连线,'-'就表示连线
按照'r-'画出来的结果:
plt.plot(features[:, 1].numpy(), net(features).detach().numpy(), 'r-', linewidth=0.5)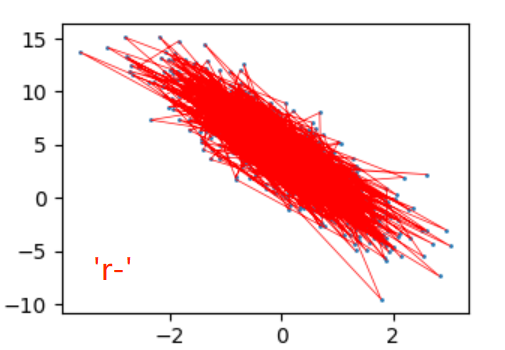
按照'r.'/'ro'画出来的结果:
plt.plot(features[:, 1].numpy(), net(features).detach().numpy(), 'r.', linewidth=0.5)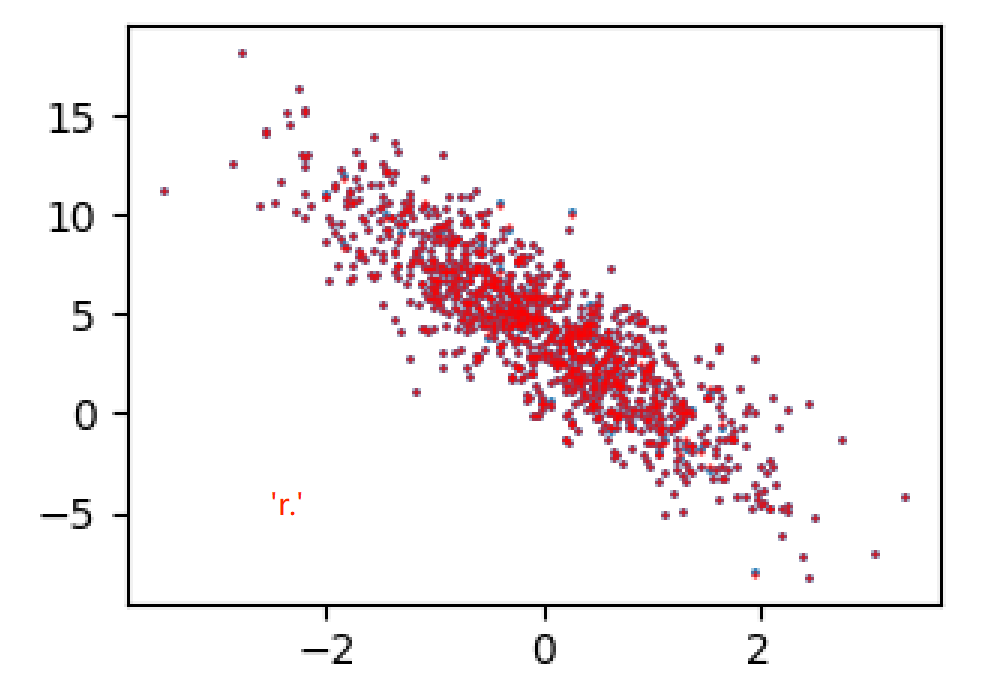
但其实效果都不如直接用scatter美观
②包装成模块版
import matplotlib.pyplot as plt
def plot_scatter_2d(features, labels, feature_idx=1, figsize=(6, 4), title="Scatter Plot"):
"""
绘制二维散点图(适用于线性回归等)
参数:
features (Tensor): 形状为 (N, D) 的特征矩阵
labels (Tensor): 形状为 (N, 1) 或 (N,) 的标签
feature_idx (int): 要绘制的特征列索引(默认第1列,即 features[:, 1])
figsize (tuple): 图像大小
title (str): 图标题
"""
# 自动处理张量到 numpy
x = features[:, feature_idx].detach().cpu().numpy()
y = labels.detach().cpu().numpy()
plt.figure(figsize=figsize)
plt.scatter(x, y, s=1, alpha=0.7)
plt.xlabel(f"Feature {feature_idx}")
plt.ylabel("Label")
plt.title(title)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()具体机制解释:
第一步:
我们定义在这个模块里面定义一个函数,叫如上的名字(懒得再打一遍了),其所涉及到的形参解释如下:
1. features:不必多言,就是输入的特征
2. labels:一样不必多言,就是输出的标签
3. features_idx = 1:默认画第1列的特征(其实也就是x2)
4. figsize = (6, 4):pycharm的默认图像大小:宽6英寸,高4英寸
5. title = "Scatter Plot":图像标题,默认为它
第二步:开始处理张量到numpy上面
请注意:如果你把运算放到了GPU上,那么需要先把数据转到CPU上,不然无法转成可兼容Numpy的格式。(这就解释了为什么处理xy这样的数据时会有个.cpu)
第三步:创建展示图像的窗口,我们指定其大小为figsize(具体由传入的实参决定)
第四步:绘图
具体参数解释:1. x, y:我们传入的features、模型输出的labels,s = 1的意思就是表示点的面积是1,alpha = 0.7表示透明度为70%。
第五步:写图例
①x轴的图例会写成Features x2(以我们一直唠叨的x2为例),y轴则是直接写成模型的输出Labels
②值得注意的是,x轴的f"Features {feature_idx}"会动态显示列号,比如Feature 1……
③然后打印图表的标题——Scatter Plot
第六步:画辅助线——网格线grid(本身就是全称——网格线的意思)
主要目的就是让读者可以更清晰地意识到点对应的具体数值
| 部分 | 作用 |
|---|---|
plt.grid(True) |
打开网格线(False 就是关掉) |
linestyle='--' |
网格线用虚线(而不是实线,避免太抢眼) |
alpha=0.5 |
透明度 50%,让线“淡一点”,不遮挡数据点 |
第七步:显现出来(在pycharm/vs等脚本环境里)
后续的导入(使用方法)则不再赘述
十、Softmax回归
在讲Softmax回归的代码前,我们需要厘清我们用的是什么样的图像分类的数据集——
你可能会说是MNIST数据集;虽然MNIST数据集是图像分类中广泛使用的数据集之一(于1986年左右提出,可见其年代感),但它作为基准数据集太过于简单,我个人建议使用类似的但更复杂的Fashon-MNIST数据集
数据处理代码部分:
先给大家展示一下Fashion-MNIST里面的图片究竟长啥样(仅举一张图片为例)

第一步:导入相关模块
import torch
import torchvision
from torch.utils import data # 方便读取数据的一些小批量函数
from torchvision import transforms # 导入将数据进行操作的模块
from d2l import torch as d2l # 函数实现好之后导入到d2l里
d2l.use_svg_display()# 表示用svg来显示图片第二步:数据预处理
# 然后通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中
# 读取数据集
trans = transforms.ToTensor() # 将图像数据转换为张量(从PIL类型转换成自带32位浮点数的格式)然后除以255使得所有像素的数值均在0~1之间
mnist_train = torchvision.datasets.FashionMNIST(root='../data', train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root='../data', train=False, transform=trans, download=True)
"""
这里需要注意一点:../data的意思其实是自己安装Fashion-MNIST的内容下载到指定的路径里面,实际安装时需要自己指明安装路径
"""具体解释:
mnist_train是用来训练的部分,对应train = True,而mnist_test则是用来测试的部分,二者彼此独立、互不冲突,非常标准。
我们在拿到下载好的数据之后可以这样验证——
print(mnist_test[0][0].shape)
"""
输出示例如下:
torch.Size([1, 28, 28])
"""具体解释:
首先,我们拿到的Fashion-MNIST是一个大数据集,我们分为了用于训练的以及用于测试的两部分,然后我们取train的部分(总共60000张图)中的[0]部分(表示取第一个样本)
(补充解释:在mnist_train里面,每个样本分为2个部分,第一部分是图像——Tensor格式,第二部分是标签——整数2格式。而我们要的是图像本身的那个格式,于是便有了接下来的操作)
然后取mnist_train[0]中的[0],我们看它的形状是什么样的(等价于查看图片的情况)
然后我们看输出示例:
首先,1表示黑白(1所在的位置表示的是channel,值为1表示通道/channel只有1个)【拓展:要是取值显示为3则表示有RGB三个通道】
接着,28表示宽度为28英寸
最后,28表示高度为28英寸
第三步:数据预处理:
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']# 官方定义的顺序,改不得
return [text_labels[int(i)] for i in labels]# 将标签转化为文本
"""
返回值等价于它:
result = []
for i in labels:
result.append(text_labels[int(i)])
return result
"""
"""
上面这个函数的作用是将图片里的标签转换成人类能看懂的标签如t-shirt、trouser等。
之所以要转成int类型而不是直接用i,是因为labels可能是PyTorch张量比如tensor([3])或者NumPy数组,
而在列表的索引里面,必须是Python原生整数才能被编成索引,于是我们用int(i)将张量或数组中的元素转换成Python原生整数。
"""重点讲下面这个函数:
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""
plot a list of images. 按照行和列来显示图片
"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
"""
以上函数常用于:展示数据集样本、模型预测结果对比等
"""具体机制解释:
第一步:传入形参
imgs:要显示的图片列表(可以是Tensor或者PIL图像)
num_rows、num_cols:显示几行几列
title = None:我们可以选择性展示每张图的标题,这无所谓
scale = 1.5:每张图的缩放比例(控制整体大小)
第二步:计算图像总尺寸——确定尺寸
figsize = (num_cols * scale, num_rows * scale)figsize的全称是figure size,表示画布的尺寸(包括宽高),假设是2行5列(对应num_cols = 5, num_rows = 2),那么算出来的结果就是figsize = (7.5, 3)——scale = 1.5
第三步:创建画布以及子图(计算平均大小只是副产品)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)这行代码实际上等价于如下代码(代入例子以辅助理解)
_, axes = d2l.plt.subplots(2, 5, figsize=(7.5, 3.0))# 先补充一点:axes的意思是子图
在这行代码里,matplotlib出于副作用会去计算每个子图的大小,计算原理实际上等价于算平均数:7.5 / 5 = 1.5,3 / 2 = 1.5(依旧要先列后行,这没办法,matplotlib的底层设定就是如此反人类)
拓展:如果你想延续【人类直觉】,我觉得可以这样定义一个函数
def my_subplot(num_rows, num_cols, scale = 1.5):
fig_size = (num_cols * scale, num_rows * scale)
return plt.subplots(num_rows, num_cols, figsize = fig_size)具体机制解释:它这样的存在就是为了把figsize的计算【隐藏】起来到我们封装好的函数里面,实际在show_images函数里直接写先行后列就行——符合人类直觉。
在show_images函数调用的时候就这样写:
_, axes = my_subplot(num_rows, num_cols,scale)# 代替原来的figsize
"""scale保持一致,避免产生误会"""(这部分如有疑问可以在评论区交流~)
好了,言归正传——讲到了axes那部分
_代表的是fig这个对象(画布本身),但我们关心的其实是具体的格子而不是画布本身,所以用它占位但不起作用
axes表示这是一个包含了所有子图坐标轴对象的数组,若是1行1列,那么axes就是一个单独的Axes对象,如若是多行多列,axes则是一个二维的numpy数组,形状是[num_rows, num_cols]
第四步:将多维数组(二维矩阵)压平成一维数组
axes = axes.flatten()flatten默认按照【先遍历第一行再遍历第二行】的顺序去遍历内容
比如如果是2行2列的[[ax00, ax01], [ax10, ax11]],结果flatten处理,结果会变成[ax00, ax01, ax10, ax11]
作用:这样的话我们就可以通过简单的for循环去配合图片列表imgs,依次把图片按【从左到右,从上到下】的顺序填入画布中分好的格子里面
第五步:打包数据
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy(),cmap='gray')
else:
# PIL图片
ax.imshow(img, cmap='gray')首先来解释一下zip(axes, imgs)——它表示的是将格子列表和图片列表搞成一个压缩包,这样的话我们第一次循环就拿到(第一个格子,第一张图)……
然后为了取标题方便,我们给加上一个计数器i(通过enumerate)来循环
如果图片数量小于格子数量,循环会在图片用完时自带停止而不会报错
其次来解释一下安全性——if-else语句部分
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)torch.is_tensor()这个函数是在判断这个img是不是张量,如果是,强制转换成numpy数组;如果不是,那么直接展示
注:
1. 因为在matplotlib里面,matplotlib.pyplot.imshow()原生支持Numpy数组以及PIL图片,但不直接支持tensor/张量
2. 因为是灰度图,我们最好显性指定gray(灰色)主调,以防万一IDE给我们渲染成其他奇奇怪怪的颜色
第六步:解决图片显示尺寸痛点
都知道【自适应】吧?有时候你应该会因为系统的【好心】(指的是给你/你自己设定自适应)而导致图片被拉伸,最终使得图片变型影响美观,下面这行代码就是在解决系统自动选择自适应的痛点——
ax.set_aspect('equal')这行代码的意思是:我们强制设定坐标轴的纵横比是1:1,效果的话就是无论格子被分成什么形状,图片都会保持原始比例而不会因为自适应而改变
效果:如果格子太“扁”,图片两边不会迁就格子样式,会直接留白;格子太高同理
第七步:美化界面
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)我们要隐藏好X轴以及Y轴的刻度线、【数字】标签(比如10、20……)。毕竟我们是在看衣物的图片,我们看的是模型识别的衣物标签是否准确,所以我们需要隐藏掉其他无关的信息
第八步:动态标题
if titles:
ax.set_title(titles[i])这一步是在检查是否有titles列表用于索引,如果没有,那么就利用我们先前加的计数器,取出对应的标题(eg:'t-shirts'),设置在当前子图上方,如果未传入titles则跳过(意思就是连通过i索引都无法补救的话,就不救了)
第九步:返回处理结果axes
return axes返回处理好的axes对象列表。如果我们在利用python画完图之后,还需要在特定的格子上加一些标注(比如画红框什么的),我们可以调用show_images这个函数,用它之后返回的结果继续操作子图
第四步:分数据
if __name__ == '__main__':# 如果是直接运行这个文件,那么就执行以下代码
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))具体机制解释:
第一步:利用DataLoader这个“搬运工”分配数据
——它支持打乱(shuffle)等功能
我们把mnist_train里这些用于训练的数据集(一共60000个)按每个批量=18分开(一次拿18张)。至于为什么是18,答案藏在下一行里面的【2, 9】——2行9列共18个(暗示我们在设置batch/批次时应当也考虑清楚自己接下来到底要设定几行几列)
第二步:正式分批——batchsize = 18
把DataLoader搬运来的数据变成一个迭代器(Iterator),这样我们就可以实现让模型准备好一个批次一个批次地取数据
第三步:开始取数据——next(...)
意思就是取下一批次的数据(最开始时,我们是不是处于“准备接货”的状态?那么我们目前手上就是空的,需要从下一批次里取数据)
结果就是:它会返回一个元组——(features, labels)
【这属于是Debug手段,偷偷看一下数据长什么样】
第四步:解包赋值
我们在接了货之后,需要“送出去”(收货然后发货),这个过程就是“解包”,我们的“发货目的地”就是X, y(X之所以大写,是因为X有可能是矩阵,前文已有所叙,不再赘述)
针对这里面的参数解析我做个讲解:
首先先说X的——
1. 18:batch
2. 28:weight
3. 28:height
【注:原来是[18, 1, 28, 28]的,但因为就只有一个通道,于是便省略掉了——这就解释了为什么会对X有调用reshape函数。之所以我们不用squeeze,是因为squeeze会自动去掉所有长度为1的维度,如果不小心,可能会把某些特殊形状的数据改错】
其次是y的——
titles=get_fashion_mnist_labels(y)这里的意思是我们把我们刚才取到的数据里的标签从冷冰冰的数字标签转换成字符串标签,目的就是让我们可以更直观地看见图片的标签
第五步:读取一小批量大小为batch_size的数据
def get_dataloader_workers():
return 4
train_iter = data.DataLoader(
mnist_train,
batch_size=batch_size,
shuffle=True,
num_workers=get_dataloader_workers()
)
timer = d2l.Timer()
for X, y in train_iter:
continue
print(f'{timer.stop():.2f} seconds used')具体解释:
一、get_dataloader_workers()函数的解释:
在DataLoader里面,有个参数叫做num_workers,它决定了“用几个进程来同时读取数据”,换句话说就是子进程的个数
如果num_workers = 0,相当于没有子进程帮忙,主进程自己读取,有个非常明显的缺点就是非常慢,不过非常稳定
如果num_workers = 4,相当于有4个子进程帮忙,速度自然而然就提上去了,适合大数据集(数据量非常多的时候)
二、为什么需要自己定义一个函数?
1. 针对Linux/Mac OS系统,它们使用fork创建子进程,子进程直接复制父进程的内存状态,效率非常高,几乎不需要额外的配置
2. 针对Windows系统,它使用spawn创建子进程,子进程需要自己重新启动全新的python解释器,然后重新导入我们的代码
3. 自己定义一个函数,后续维护时只需要改一处地方即可,非常方便
通过以上解释可以看出——针对Windows系统,如果我们是在jupyter notebook里或者交互式命令行(如虚拟环境)里面写的而没有保存为【.py文件】或者没有【if__name__=='__main__'】保护的话,那么Windows系统的子进程在尝试重新导入代码时会【找不到入口】或者【无限递归】导致报错:
RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase...或者程序直接卡死
【或者换种解释方式】……
可以跑通的情况:(直接沿用如上的代码的话)
1. Linux用户
2. Windows用户中的
1. 写了 if __name__ == '__main__': 的
2. 未写if __name__ == '__main__': 但python检测到是Windows系统然后【return 0】的(这种情况跑的速度会慢些,但好歹能跑通,能带给初学者自信心——别小看这一点自信心)
不可以跑通的情况:
1. 是Windows系统但直接在jupyter notebook里面跑的
补充:【经查资料】
| 场景 | 推荐 num_workers |
原因分析 |
|---|---|---|
| 调试代码阶段 | 0 | 此时我们需要快速看到报错信息。多进程会让报错堆栈变得极其复杂(子进程报错很难追踪),且启动进程本身有开销,小步快跑时单进程更方便调试。 |
| 小数据集 (如 MNIST) | 0 或 2 | 数据量太小,硬盘读取瞬间完成。开启多进程的通信开销(进程间传递数据)可能比读取时间还长,反而变慢(负优化)。 |
| 大数据集 (如 ImageNet) | 4 ~ 8 | 图片大、预处理复杂(裁剪、翻转等)。此时 CPU 是瓶颈,必须多开进程让 GPU 别闲着。通常设置为 CPU 核数的一半。 |
| 内存受限机器 | 0 或 1 | 每个 worker 进程都会复制一份 Python 环境和部分数据。如果内存只有 8GB,开 4 个 worker 可能导致 OOM (Out Of Memory) 直接崩溃。 |
| Windows + Jupyter | 0 | 绝对禁区! 除非我们非常清楚自己在做什么并配置了复杂的启动方法,否则在 Notebook 里开多进程必挂。务必保存为 .py 文件并加 if __name__ == '__main__':。 |
三、后续进程的解释
这四个进程(按照如上代码的话)会并行地从硬盘里去读取图片,然后transform一下(转tensor转Numpy或者归一化),然后把处理好的数据放入到一个共享队列里面(Queue)。接下来主进程只需要从这个共享队列里面pop数据然后投喂给GPU进行并行处理即可
四、启动计时器
作用是记录代码开始运行的时间
print(f'{timer.stop():.2f} seconds used')第六步:彻底封装操作数据过程以实现重用
def load_data_fashion_mnist(batch_size, resize=None):
trans = []
if resize:
trans.insert(0, transforms.Resize(resize))
trans.append(transforms.ToTensor())
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root='D:/my_ai_projects/深度学习/data',
train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root='D:/my_ai_projects/深度学习/data',
train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train,
batch_size,
shuffle=True,
num_workers=
get_dataloader_workers()),
data.DataLoader(mnist_test,
batch_size,
shuffle=False,
num_workers=get_dataloader_workers()))
之所以这样先写trans = []后写transforms.ToTensor()而不是按照这样写:
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
是因为报错了
是的,你没听错,报错了

原因:

具体机制解析:
第一步:形参的解析
resize = None的意思是默认不缩放
第二步:初始化变换列表trans
为了不报错,仅此而已,如果不报错可按照另一种方式继续写,这无所谓
第三步:判断是否需要缩放
如果需要缩放,则在trans这个列表里面插入Resize的操作
第四步:将ToTensor操作追加到列表末尾
注意:ToTensor必须是最后一个操作,因为一旦在遍历时检测到ToTensor,那么后续将无法使用Resize、Rotate等操作
ToTensor的作用其实还有把像素值自动从[0, 255]缩放到[0.0, 1.0]【查资料得】
第五步:组合成变换流水线
trans = transforms.Compose(trans)作用:把trans列表里的所有操作串起来,变成一个整体的变换函数(compose的中文是组合)
好处:后续我们在写代码的时候如果需要调用trans(image),就会自动按照顺序执行所有操作
(就好像我们在一张清单上写清楚要执行的操作,执行者就会自动按照清单上的顺序执行操作,然后交给我们最终成品)
第七步:开始训练/测试
中间的过程不再过多赘述,唯一需要注意的点是这里
transform=trans这里的意思是——我们在执行了刚才的“列清单”操作之后,我们要复用到训练以及测试上——这才是我们最终的目的
第七步:创建DataLoader并返回值
return (data.DataLoader(mnist_train,
batch_size,
shuffle=True,
num_workers=
get_dataloader_workers()),
data.DataLoader(mnist_test,
batch_size,
shuffle=False,
num_workers=get_dataloader_workers()))
我们用DataLoader包装好数据集用于训练+测试(test_data),其他的不再赘述
完整代码展示:
"""
这部分代码还不是真正在训练模型,而是在“造工具”
"""
import matplotlib.pyplot as plt
import torch
import torchvision
from torch.utils import data # 方便读取数据的一些小批量函数
from torchvision import transforms # 导入将数据进行操作的模块
from d2l import torch as d2l # 函数实现好之后导入到d2l里
d2l.use_svg_display()# 表示用svg来显示图片
"""----------------1. 数据准备----------------"""
# 然后通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中
# 读取数据集
batch_size = 256
trans = transforms.ToTensor()
"""将图像数据转换为张量
(从PIL类型转换成自带32位浮点数的格式)
然后除以255使得所有像素的数值均在0~1之间"""
mnist_train = torchvision.datasets.FashionMNIST(
root='D:/my_ai_projects/深度学习/data',
train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root='D:/my_ai_projects/深度学习/data',
train=False,
transform=trans,
download=True)
# 两个可视化数据集的函数
"""----------------2. 可视化工具----------------"""
def get_fashion_mnist_labels(labels):
text_labels =
['t-shirt',
'trouser',
'pullover',
'dress',
'coat',
'sandal',
'shirt',
'sneaker',
'bag',
'ankle boot']# 官方定义的顺序,改不得
return [text_labels[int(i)] for i in labels]
# 将标签转化为文本
"""
返回值等价于它:
result = []
for i in labels:
result.append(text_labels[int(i)])
return result
"""
"""
上面这个函数的作用是
将图片里的标签转换成人类能看懂的标签如t-shirt、trouser等。
之所以要转成int类型而不是直接用i,
是因为labels可能是PyTorch张量比如tensor([3])或者NumPy数组,
而在列表的索引里面,
必须是Python原生整数才能被编成索引,
于是我们用int(i)将张量或数组中的元素转换成Python原生整数。
"""
def my_subplot(num_rows, num_cols, scale = 1.5):
fig_size = (num_cols * scale, num_rows * scale)
return plt.subplots(num_rows, num_cols, figsize = fig_size)
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""
plot a list of images. 按照行和列来显示图片
"""
# _, axes = d2l.plt.subplots(num_rows, num_cols, fig_size=fig_size)
_, axes = my_subplot(num_rows, num_cols,scale)# 代替原来的figsize
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy(),cmap='gray')
else:
# PIL图片
ax.imshow(img, cmap='gray')
ax.set_aspect('equal')
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
"""
以上函数常用于:展示数据集样本、模型预测结果对比等
"""
"""
接下来是主函数部分
"""
"""----------------3. 数据加载器----------------"""
def get_dataloader_workers():
return 4
def load_data_fashion_mnist(batch_size, resize=None):
"""加载MNIST数据集"""
trans = []
if resize:
trans.insert(0, transforms.Resize(resize))
trans.append(transforms.ToTensor())
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root='D:/my_ai_projects/深度学习/data', train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root='D:/my_ai_projects/深度学习/data', train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers()))
train_iter = data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:
continue
if __name__ == '__main__':
"""测试数据加载"""
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))
plt.show()
"""创建数据迭代器"""
train_iter = data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=get_dataloader_workers())
"""测试读取速度"""
timer = d2l.Timer()
for X, y in train_iter:
continue
print(f'{timer.stop():.2f} seconds used')
从零开始实现代码部分:
第一步:导入相关模块
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)在这里我们就直接读取fashion_mnistd的数据用于训练以及测试
第二步:展平每个图像
num_inputs, num_outputs, num_epochs, lr = 784, 10, 10, 0.1
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)1. 784的来源其实是28 * 28 = 784。(原来是28 * 28的图片嘛,现在被拉伸成行数/高度为784,列数/宽度为1的向量了)
2. 因为我们的数据集有10个类别,所以网络输出维度为10
3. 训练轮数为10(epoch)
4. 学习率为0.1(对于简单的线性模型,这是一个比较大胆但有效的步长)
第三步:开始softmax回归:
先来从数学的角度上回忆一下softmax的计算公式:
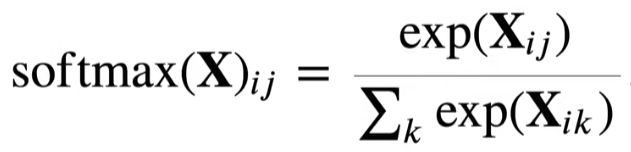
补充一下:这里的exp的意思是取指数——目的是放大差距
这里我举个例子以证明softmax对于“质检员”来说的重要性:
 可以看出经过softmax计算之后,模型输出的它预测的标签结果之间的差距是非常大的
可以看出经过softmax计算之后,模型输出的它预测的标签结果之间的差距是非常大的
代码实现:
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制验证:

是否有感觉到【不对劲】?是的——X_prob.sum(1)的输出不应该是2行1列的吗?为什么输出结果却是1行2列?是不是我们知识点记错了?
答案是:或许是的。不过更准确来说应当是因为在我们计算X_prob.sum(1)时,我们并没有说明要【keepdim】(也就是维持维度不变),PyTorch就觉得“嗯,既然你都把第1维(按照行的维度)都加没了,那么这一维度也就不存在了吧,我就把它删掉算了”于是最后计算出来的维度,原来是(2, 5)的【2行5列】,最后变成了(2,)【注意!这里的(2,)的意思不是2行1列!因为它根本没有“列”这个概念!它就单纯只是一个1维的张量】不过计算sum的过程还是按照维度为1来计算的(每一行内部相加)
第四步:定义softmax回归模型(前导传播):
def net(X):
return softmax( torch.matmul( X.reshape( (-1, W.shape[0]) ), W ) + b)——这里我们定义的函数把线性变换跟非线性激活都串在一起了
数学公式原理是——![]()
中间的细节不再赘述,前文已有所叙。最后X被reshape成一个(256, 784)的矩阵
第五步:创建数据y_hat(检验效果——仅作教学而非实际项目部分)
y_hat也就是![]() (注:以下部分仅作为讲解,非正式编写模型代码部分)
(注:以下部分仅作为讲解,非正式编写模型代码部分)
假设其包含2个样本在3个类别中的预测概率,我们使用y作为y_hat在概率中的索引
"""
以下部分仅作为讲解,非正式编写模型代码部分
y = torch.tensor([0, 2])⬅我们指定的【正确答案】
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
对于y_hat([0, 1], y)的输出应该是这样的:
tensor([0.1000, 0.5000])
"""注意:要想理解为什么例子里的输出结果之所以是这样的,
我们需要先澄清两个相近的概念:
索引跟切片。
1. 切片的语法如下:(以上面的例子为例)
y_hat[0:2, 0:3](左闭右开区间,先行后列)
2. 索引的语法如下:(以上面的例子为例)
y_hat[ [0,1], [0, 2] ](表示我要取第0行的第0列的,以及第1行的第2列的内容)
y = torch.tensor([0, 2])(表示一维张量,shape = (2,),元素共3个。其中我们取第0个以及第2个索引下的值。至于为什么用tensor,其实已经说了很多遍了。我们是为了在后续的计算中跟PyTorch兼容)
总结:为了区分,我们可以按照如下方法记索引的语法——碱基互补配对法则
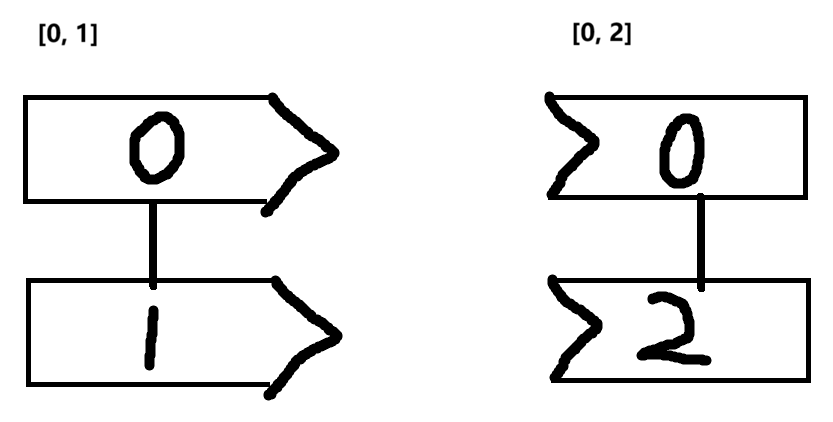
其次,我们是在假设一种情况以助于理解——
我们有2个样本(比如2张图片),每个样本里面,模型预测了有3个结果(3个标签分别的概率——图像是这个标签的概率),假设我们知道这2个样本的真实标签是第0类以及第2类(即y = [0, 2])那么我们想知道模型对于这两个标签的预测值是多少(就相当于我们拿着正确答案去看模型的答案怎么样以评估训练结果),于是我们就写了y_hat[ [0,1], [0, 2] ],然后我们print一下这个结果我们就知道模型的答案是多少了。
第六步:实现交叉熵损失函数
数学公式/原理如下:
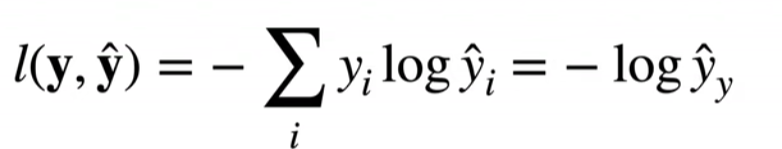
我们用交叉熵来判断预测对不对,再求梯度,告诉模型该怎么改参数
def cross_entropy(y_hat, y): # y_hat的形状是(1, n_class),y的形状是(n, 1)
return - torch.log(y_hat[range(len(y_hat)), y])首先说明一下数学的“理想”以及代码中的“实用”:
在数学里面我们可以随便写内容——让正确答案的标签值为1,其余为0;但在计算机里面,计算机的内存存在物理限制,不能存那么多“垃圾值”(指的就是那些0。虽然在数学里面不算是垃圾值),于是工程师们想到一个方法——既然我只有一个值是有用的,那我何必浪费空间去存那些无用的值呢?直接把答案拿出来不就好了?
于是便有了如上的写法。具体机制解释:
第一步、理解len(y_hat)的“长度”:(为了讲解方便,我便将之前的内容摆到这里来)
y_hat的形状很明显是(2, 3),y的形状是(2,)(这里还是解释一下——y_hat的样本量其实是2,只是在每个样本里面模型有针对3个标签分别给出预测值)
"""
例子α
y_hat = torch.tensor(
[0.1, 0.3, 0.6],
[0.3, 0.2, 0.5]
)
"""∴len(y_hat) = batch_size = 2→推出range(2) = [0, 1]——行索引
第二步、理解y_hat[range(...), y]的含义
——又回到高级索引的知识点了
先把背后象征的形式摆出来吧:y_hat[range(...), y] = y_hat[ [0, 1], [0, 2] ]
你当然很熟悉对不对?这就是我们刚讲没多久的——碱基互补配对法则!
为了直观展示结果,我们直接使用刚才的例子α——输出的结果就是tensor([0.1000, 0.5000])——我们要的模型真实类别的预测概率
第三步、理解-torch.log(...):这其实就相当于——
![]()
然后我们根据这个正确答案去算局部交叉熵损失

我们算出来的是tensor([2.3026, 0.6931]),我们假设就是局部的交叉熵(损失)计算结果——差距确实非常大
最后我们再算平均损失——这才是全局的交叉熵损失!
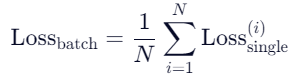
这里N = 2。我们计算出来的结果是1.49785——真正的损失——很大,然后我们就需要通过梯度下降然后反向传播去减小误差
第七步:计算预测正确的数量——教学版本
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
"""
举个例子:以上面的为例,算accuracy(y_hat, y) / len(y) 的结果是0.5,即有一半是预测正确的
"""具体机制解释:
第一步:判断y_hat是不是多维数组(y_hat.shape = (2, 3)——表示y_hat的维度为2 > 1)并且y_hat.shape[1] = 3 > 1——作用是:如果模型输出的是概率分布,我们则需要检查输出的这个结果的列数是否大于1(因为(2, 3)的索引是从0开始到1,分别对应2跟3)
第二步:通过argmax(axis = 1)取每一行内部的最大值的索引。(直接看最大值——模型最有信心的预测标签结果,我们看是不是正确答案)取出来的结果是tensor([2, 2])
第三步:我们检查答案是否准确。但在比较前,我们需要转格式(y_hat.type(y.dtype))——把y_hat的格式转得跟y一样(dtype的全称是data type)。然后我们先逐个结果进行比较,然后返回一个bool值(True / False)
![]()
cmp = y_hat.type(y.dtype) == y( 其中的比较结果如下:
1. 2 == 0?答案是否定的,返回False
2. 2 == 2?答案是肯定的,返回True
)最后tensor([2, 2])转成tensor([False, True])
第四步:把比较结果修改成浮点数类型——便于后续计算准确率
return float(cmp.type(y.dtype).sum())这行代码表示的是cmp的数据类型要转成跟y一样的数据类型(在PyTorch里面,False用0表示,True用1表示),然后求和——结果为2,最后把2转成浮点数类型——1.0000
第五步:验证准确率。我们取了2个正确答案,模型预测对的有1个,那么准确率易知是0.5(1 / 2 = 0.5)
总结:

第七步:计算预测正确的数量——工程版本
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = d2l.Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]具体机制解析:
第一步:检查net(比如softmax回归、CNN网络……)是否是标准的PyTorch神经网络模块
(防止传入普通的数学函数以浪费算力——防御性编程)再仔细点解析就是(查资料之后)——有的层在训练时的行为跟在测试时的行为是不一样的——如果不写.eval(),会导致准确率不可信
Dropout层:训练时会随机丢弃神经元(说是为了防止过拟合),但在测试的时候我们必须保留所有神经元,不然结果就会不稳定——训练时肯定是要尽可能适应各种【突发情况】的,以增强模型的鲁棒性
BatchNorm层:训练时会使用当前批次的均值方差,测试时使用全局统计的均值误差——全副武装上阵参加考核,背负上训练时的所有经验
第二步:备好计分板
Accumulator是李沐在d2l里自定义的一个类,用来累加数据,其参数2表示我们要累加2个数值,其中一个是猜对的个数,另一个是总共猜了多少个。我们可以类比for循环 / while循环里的计数器cnt,我们经常这样写:(本质上就是在分别计算一批批运进来的数据的准确率,然后记录结果,最后求均值误差)
cnt++
cnt+=1
第三步:循环【阅卷】(说得通俗易懂点)
with torch.no_grad():
for X, y in data_iter:
metric.add(d2l.accuracy(net(X), y), y.numel())我们来一步步解析——
首先是with语句:在比较新的PyTorch/最佳实践中,我们在评估模型时通常会加一行with torch.no_grad():,目的就是告诉PyTorch【别给我计算梯度!也别给我因为计算梯度了去画计算图!】,好处在于【节省算力】以及【节省内存空间】。
那有的读者可能就疑惑了——既然加上这句这么好,那为什么李沐就没有加上去呢?
答案是——在李沐的语境中,net.eval()这个函数已经默认关闭了Dropout等层,并且回溯我们学过的知识点,是不是.backward()这个函数表示求梯度呀?李沐在后续的代码里也并没有写这个函数。综上就不需要写with这行代码了(不写也不会报错),不过写上会更规范、高效
其次是循环的开头语句:参数X表示特征(图像数据本身),y依旧是模型输出的标签,data_iter就是【运数据的“货车”】
然后是循环的内部语句:
1. metric.add(...)表示记录总分——把我们算得的[本批次的预测正确数量, 本批次样本总数]记录到记分板上
2. d2l.accuracy(net(X), y)表示【给小题分】——把模型在每个批次内部预测正确的样本数记录起来,其中net(X)表示把图片X这个样本,y表示的意思不变——是模型预测的标签,这个函数会去比对是否正确,如果正确则【+=1】
3. y.numel()表示统计y里有多少个元素,计算结果会比如是256(之所以不用len(y),我个人觉得是因为y有可能如前文所叙出现类似y = [0.2, 0.3, 0.5]的情况,类似这种情况直接用len()明显不对)
第三步: 计算成绩
return metric[0] / metric[1]还记得我们一开始说的内容吗——

没错,在metric这个数据容器里,索引为0的位置下,存储的数据是【模型猜对的数据样本总数】;索引为1的位置下,存储的数据是【模型猜的数据样本总量】,经过如上代码的算法处理,得出的便是准确率。
【拓展】介绍一下Accumulator这个类的具体结构
class Accumulator:
"""用于统计多个变量并累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]首先解释一下为什么会出现[0.0] * n的形式——
1. 为什么会是[0.0] 的格式:原因是这是一个只包含一个元素0.0的列表,而 * n是python里的列表乘法操作符,会把列表重复n次(换句话说就是把列表的长度拓宽至长度为n),把所有计数器归零,准备用于累加
1. n = 2
2. [0.0] * 2 # 结果是[0.0, 0.0],对应[正确预测数, 总预测数]
3. n = 3
4. [0.0] * 3 # 结果是[0.0, 0.0, 0.0],对应[损失值总和, 正确预测数, 总数]
5.
6. n = 5
7. [0.0] * 5 # 结果是[0.0, 0.0, 0.0, 0.0, 0.0]
2. 为什么写0.0而不是0:这是因为我们要算的是跟准确率相关的数值,如正确总数、样本总数……【经查资料得:为了通用性以及避免浮点数类型错误,我们统一用浮点数更安全】,并且add函数也用了float(b),保持数据类型一致】
其次解释一下add函数里的代码——
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]1. zip【中文意思有拉链】函数( zip(self.data, args) )的作用等价于之前的【碱基互补配对原则】的行索引跟列索引的配对,只是将其包装成了一个函数直接调用——为了简洁
2. for语句就是遍历每一组数据(每一对a——对应self.data;以及每一对b——对应args)
3. 整行代码的等价形式:self.data = self.data + float(args)【最后的self.data的形式是一个列表】
最后解释一下为什么李沐在课上说最后算出来的结果是随机值——
这是因为在他的课中,他原来是在将evaluate_accuracy函数的。但!此时我们只是在听如何实现softmax回归,还并未开始训练模型,所以模型只能去【猜】,又因为在FashionMNIST里有10个类别的数据,理论上来说,准确率应该是在1 / 10 = 0.1左右,实际上来说准确率应当在这个数字附近,不会超出太多
# 第八步:正式训练——一轮版
def train_epoch_ch3(net, train_iter, loss, updater):
if isinstance(net, torch.nn.Module):
net.train() # 将模型设置为训练模式
metric = d2l.Accumulator(3) # 损失,正确预测数,样本数
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer): # 如果传入了优化器
updater.zero_grad() # 梯度清零
l.backward() # 反向传播
updater.step() # 更新参数
metric.add(
float(l) * len(y), d2l.accuracy(y_hat, y), y.size().numel()
)
else: # 如果传入了更新函数
l.sum().backward()
updater(X.shape[0]) # 调用更新函数
metric.add(float(l.sum()), d2l.accuracy(y_hat, y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]具体机制解析:
1. 形参及函数介绍(简略介绍):
1. net:自己的神经网络(此处为softmax回归)
2. train_iter:可以理解为“题库”,是数据的迭代器
3. loss:损失函数(此处为交叉熵)
4. updater:更新器,可是PyTorch自带的优化器(如资料中所述的torch.optim.SGD),抑或是自己写的梯度下降函数
5. _ch3:表示此函数是第三章专用的,后续章节会出现_ch4,_ch5……但差别不会太大
2. 逐行代码解析:
if isinstance(net, torch.nn.Module):
net.train()
作用:检查net是否是标准的PyTorch模型+让模型进入训练模式
metric = Accumulator(3)
作用:不再赘述。是3的原因是:我们要尽可能全面地记录数据
1. 累积损失的总和——很明显用于计算平均损失
2. 累积正确预测数——用于算准确率
3. 累积样本总数——用于归一化(简单来说就是让所有的参数数据都在一定的取值范围内,防止模型自主决策导致“偏心”,否则模型梯度下降时有可能会不断震荡)
for X, y in train_iter: # X.shape =
y_hat = net(X)
l = loss(y_hat, y)
前导传播——据前文所叙,此处很明显就是在让模型去开始训练
if isinstance(updater, torch.optim.Optimizer): # 如果传入了优化器
updater.zero_grad() # 梯度清零
l.backward() # 反向传播
updater.step() # 更新参数——公式早已讲过,如w = w - lr* grad
metric.add(
float(l) * len(y), d2l.accuracy(y_hat, y), y.size().numel()
)
else:
l.sum().backward()
updater(X.shape[0]) # 调用更新函数
最后再讲解一下l.sum.backward()以及updater.step(X.shape[0]):
1. 为什么要算上sum,是因为backward要标量,而loss有可能返回【每个标量的损失——向量】,我们通过求和【降维打击】之后,不就可以去反向传播然后更新参数了吗
2. updater(...)【为了兼容两种写法】是我们调用我们自己定义的更新函数,比如sgd(prams, lr, batch_size)……
【经查资料,李沐在课程前期会手写sgd,但后期直接调用torch.optim.SGD】
metric.add(float(l) * len(y), d2l.accuracy(y_hat, y), y.size().numel())的意思是将学习成果如同写笔记一样写入metric(中文意思是测度)中,如同更新日志一样

最后的返回值的解析就无需多言了
1. return metric[0] / metric[2], metric[1] / metric[2]
参考上图,metric[0] 等价于损失值总和,metric[1]等价于正确预测数,metric[2]等价于总数
那么,这个函数返回的值也就2个,第一个是平均损失(损失值总和 / 总数),第二个是准确率(正确预测数 / 总数)
【李沐封装的画图的类不讲了,感兴趣的自己去查找资料理解,非本课程重点】
第九步:正式训练——正式写入项目版(完整)
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
train_metrics = (0.0, 0.0)# 仅仅是为了消除可能出现的IDE警告
animator = Animator(
xlabel='epoch',
xlim=[1, num_epochs],
ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc']
)
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
# assert train_loss < 0.5, train_loss
"""以上一行只适合用于教学, 实际生产中绝对不能写"""先来解释一下为何我会针对assert那一行代码说那样的话——
首先,在教学中,写这行代码是为了“有个保底”,仅此而已,目的是强制让程序中断,提醒我们代码写错了
其次,在实际项目中,要是写了这行代码,真实的训练有可能导致本来在训练的程序直接中断,导致我们本来跑了比如一周的训练直接因为assert那一行代码的作用导致前功尽弃
其次解析一下animator那一行中的一些小细节:
1. xlim=[1, num_epochs]意思是从第一批开始到第nun_epopchs批
2. ylim = [0.3, 0.9]目的是让y轴的取值范围小一些,防止图像乱跳,legend表示要画3张图——训练损失、训练准确率、测试准确率
3. animator.add(epoch + 1, train_metrics + (test_acc,)):就是把我们得到的数据(legend里的训练损失、训练准确率、测试准确率)画在图上,之所以写epoch+1,是因为在人类的角度习惯从1开始而不是0train_metrics + (test_acc,)的意思是把两个数的元组和单个数(test_acc)拼接在一起(类似python中print语句里将""引用的内容跟后续的变量接在一起输出)形成一个整体元组,对应图例的三条线
最后
train_loss, train_acc = train_metrics是取出最后的epoch里的数据,为了后续做总结以及考虑处理方案
"""
小批量随机梯度下降来优化模型的损失函数——体现李沐直接使用sgd函数
"""
def updater(batch_size, lr = 0.1):
return d2l.sgd([W, b], lr, batch_size)完整版代码展示:(包括线性回归的两种实现方式都已展示完整代码以辅助理解)
import torch
# from IPython import display】
from GPU_utils import warm_GPU
warm_GPU.warmup_gpu()
from d2l import torch as d2l
from d2l.mxnet import Animator
"""----------------1. 数据准备----------------"""
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
"""----------------2. 模型参数与定义----------------"""
num_inputs, num_outputs, num_epochs, lr = 784, 10, 10, 0.1
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
def net(X):
return softmax( torch.matmul( X.reshape( (-1, W.shape[0]) ), W ) + b)
"""
以下部分仅作为讲解,非正式编写模型代码部分
y = torch.tensor([0, 2])⬅我们指定的【正确答案】
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
对于y_hat([0, 1], y)的输出应该是这样的:
tensor([0.1000, 0.5000])
"""
"""
y_hat = torch.tensor(
[0.1, 0.3, 0.6],
[0.3, 0.2, 0.5]
)
"""
"""----------------3. 损失函数----------------"""
def cross_entropy(y_hat, y): # y_hat的形状是(1, n_class),y的形状是(n,)
return - torch.log(y_hat[range(len(y_hat)), y])
# def accuracy(y_hat, y):
# """计算预测正确的数量"""
# if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
# y_hat = y_hat.argmax(axis=1)
# cmp = y_hat.type(y.dtype) == y
# return float(cmp.type(y.dtype).sum())
"""
举个例子:以上面的为例,算accuracy(y_hat, y) / len(y) 的结果是0.5
"""
"""----------------4. 评估准确率----------------"""
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = d2l.Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
"""
解释一下Accumulator的来源
class Accumulator:
用于统计多个变量并累加
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
"""
"""
接下来开始正式训练——包装成一个函数—— 一轮的
"""
"""----------------5. 单轮训练----------------"""
def train_epoch_ch3(net, train_iter, loss, updater):
if isinstance(net, torch.nn.Module):
net.train() # 将模型设置为训练模式
metric = d2l.Accumulator(3) # 损失,正确预测数,样本数
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer): # 如果传入了优化器
updater.zero_grad() # 梯度清零
l.backward() # 反向传播
updater.step() # 更新参数
metric.add(
float(l) * len(y), d2l.accuracy(y_hat, y), y.size().numel()
)
else: # 如果传入了更新函数
l.sum().backward()
updater(X.shape[0]) # 调用更新函数
metric.add(float(l.sum()), d2l.accuracy(y_hat, y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
"""
接下来开始正式训练——包装成一个函数——全部的
"""
"""----------------6. 多轮训练(主循环)----------------"""
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
train_metrics = (0.0, 0.0)# 仅仅是为了消除可能出现的IDE警告
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9], legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
# assert train_loss < 0.5, train_loss
"""以上一行只适合用于教学, 实际生产中绝对不能写"""
"""
小批量随机梯度下降来优化模型的损失函数——体现李沐直接使用sgd函数
"""
"""----------------7. 优化器----------------"""
def updater(batch_size, lr = 0.1):
return d2l.sgd([W, b], lr, batch_size)
"""----------------8. 预测并可视化----------------"""
def predict_ch3(net, test_iter, n=6):
"""这用于预测标签"""
X, y = None, None
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true + '\n' + pred for true, pred in zip(trues, preds)]
# 实际等价效果——titles = [true + '\n' + pred | for true, pred in |zip(trues, preds)]注:|表示分隔
d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
# 这里的1, n的意思是——将贴好的标签结果展示为1行n列
"""----------------9. 主程序入口----------------"""
if __name__ == "__main__":
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, num_epochs])
"""----------------10. 开始训练----------------"""
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
"""----------------11. 预测并可视化----------------"""
predict_ch3(net, test_iter)简洁实现部分代码:
"""
通过深度学习框架的高级API来简化softmax的实现
"""
import torch
from torch import nn
from d2l import torch as d2l
"""----------------1. 数据准备----------------"""
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
"""----------------2. 配置环境----------------"""
d2l.use_svg_display()# 使用矢量图展示
"""----------------3. 定义模型----------------"""
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
"""作用是利用Flatten层将28 * 28 的图片拉平784维(1行784列)的行向量"""
"""PyTorch不会隐式调整输入的形状,因此我们需要定义展平层(flatten)以在线性层前调整网络输入的形状"""
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
"""----------------4. 初始化模型参数----------------"""
net.apply(init_weights)
"""----------------5. 定义损失函数----------------"""
loss = nn.CrossEntropyLoss()
"""----------------6. 定义优化算法----------------"""
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
"""----------------7. 训练模型----------------"""
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
# train_ch3适合多层感知机、CNN等![]()
补充——如果在编译时遇到类似这样的报错

则我们可以把我们写的这部分代码给复制粘贴到d2l那个模块包里面(注:以上代码来自李沐的《Dive into deeplearning》电子书中的torch版代码,但为了方便大家就不麻烦大家了,直接展示可以复制粘贴的版本以救急)
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc特别说明:(针对如下代码)
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
本作者建议大家写成如下形式:
1. GPU版torch:
metric.add(float(l.sum().item()), accuracy(y_hat, y), y.numel())
2. CPU版torch:
metric.add(float(l.sum().detach), accuracy(y_hat, y), y.numel())
可能的错误二:针对如下的代码的报错
from d2l.mxnet import Animator
我们改成这样的导包方式:
from d2l.torch import Animator
做出以上选择后,可能会出现这样的警告:

这仅仅是【无关紧要】的警告,想仔细研究的也可以去研究,在此不再赘述
【作者建议:一般情况下尽量不要动自己好不容易搞好的解释器以及虚拟环境!!!另外,自己应当使用自己虚拟环境里的解释器。具体方式如下:】
打开自己的pycharm,我们要找的就是在我们当前所处的目录/虚拟环境下的解释器,路径格式一般如下:
![]()
十一、感知机
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
"""---------------------1. 初始化模型参数---------------------"""
num_inputs, num_outputs, num_hidden = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hidden, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hidden, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hidden, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
"""---------------------2. 定义激活函数---------------------"""
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
"""---------------------3. 定义模型---------------------"""
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b2
"""---------------------4. 定义损失函数---------------------"""
loss = nn.CrossEntropyLoss(reduction='none')
"""---------------------5. 定义优化算法---------------------"""
updater = torch.optim.SGD(params, lr=0.1)
"""---------------------6. 训练模型---------------------"""
num_epochs, lr = 10, 0.1
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.predict_ch3(net, test_iter)
"""---------------------7. 可视化---------------------"""
d2l.plt.show()具体机制解析:
1. 初始化模型参数部分
1) nn.Parameter(...):
①作用:将张量包装为模型参数,使得它能被nn.Module识别为可训练参数
②为何使用它:默认情况下,torch.Tensor不会被优化器(比如李沐用的SGD)更新。nn.Parameter是Tensor的子类,也带有require_grad = True标志,并且当它作为nn.Module的属性时,会自动加入model.parameters()中。这样在optimizer.step()中这些参数就会被更新
2) torch.randn(num_inputs, num_hidden, requires_grad=True) * 0.01:【这里只介绍 * 0.01,因为其他的先前都已介绍过或李沐在理论课中已介绍过(通过变量命名可得)。】
①作用:生成一个形状为(num_inputs, num_hidden, requires_grad = True)的符合标准正态分布的随机张量,数学上定义为(均值为0, 标准差为1)(麻烦好好对照下面的“死去的”知识点进行对比、回忆、解析、理解)
再来回顾一下之前讲过的知识点:
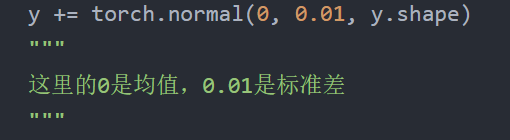
②原因:之所以 * 0.01,是因为我们要把整个权重矩阵缩小为原来的1 / 100,也就是0.01倍。以防止初始权重太大导致激活值过大导致其进入sigmoid / tanh的饱和区(梯度≈0),引发梯度消失。
3) 为何不直接使用nn.Linear?原因是:在这里仅仅是为了让我们看清每一步的参数结构和初始化方式,所以没有直接使用nn.Linear。
简洁实现版本:
import torch
from torch import nn
from d2l import torch as d2l
"""---------------------1. 模型定义---------------------"""
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
"""---------------------2. 损失函数---------------------"""
loss = nn.CrossEntropyLoss(reduction='none')
"""---------------------3. 优化器---------------------"""
trainer = torch.optim.SGD(net.parameters(), lr=0.1)# 与课本上的写法等价
"""---------------------4. 训练---------------------"""
batch_size, lr, num_epochs = 256, 0.1, 10
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)十二、模型选择、过拟合、欠拟合
我们通过李沐举的一个案例来探讨一下这个现象
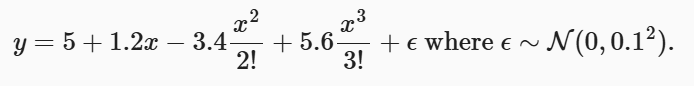
我们想要实现的,是通过这个式子(跟之前线性回归等本质相同——通过数学公式来生成标签,本质上就是把数学里的计算过程“翻译”成了编程)来生成训练+测试的标签并检测输出的标签拟合程度跟如上的式子相比如何【你看,跟之前讲过的线性回归、softmax等如出一辙】
完整代码展示:
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
"""---------------------1. 生成数据集---------------------"""
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 真实权重
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(0, 1, (n_train + n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # 归一化->gramma(n) = (n-1)!
labels = np.dot(poly_features, true_w)# Labels的维度:(n_train)
labels += np.random.normal(0, 0.1, size=labels.shape)
"""---------------------2. 定义损失函数---------------------"""
def evaluate_loss(net, data_iter, loss):
metric = d2l.Accumulator(2) # 损失总和,样本数量
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
"""---------------------3. 定义训练函数---------------------"""
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss(reduction='none')
input_shape = train_features.shape[-1]
# 不设置偏置,因为我们已经在多项式中实现了它
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:# 每隔20轮(从0开始计数)就记录一次
animator.add(epoch + 1,
( evaluate_loss(net, train_iter, loss), evaluate_loss(net, test_iter, loss) )
)
"""
epoch + 1作为x轴,y含有2个元素,对应2条线
"""
print('weight:', net[0].weight.data.numpy())
"""---------------------4. 主函数---------------------"""
if __name__ == '__main__':
# 先全部转成 Tensor
true_w_tensor, features_tensor, poly_features_tensor, labels_tensor = [
torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]
]
print("前两个样本:")
print("features:", features_tensor[:2])
print("poly_features:", poly_features_tensor[:2, :])
print("labels:", labels_tensor[:2])
# 分割训练/测试集(用 Tensor)
train_features = poly_features_tensor[:n_train, :4] # 只取前4维
test_features = poly_features_tensor[n_train:, :4]
train_labels = labels_tensor[:n_train]
test_labels = labels_tensor[n_train:]
# 调用训练
train(train_features, test_features, train_labels, test_labels)
d2l.plt.show()这里针对X,y的出现却不报错作个解析:(以下是等价形式)
pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
for num, letter in pairs:
print(num, letter)这是python的基本语法:序列解包,X,y只是我们临时定义的、为了承接住data_iter里的数据的变量,不需要提前定义。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)