【PyTorch实战】从零搭建LeNet-5实现8类果蔬分类:踩坑记录与优化方案(附完整代码)
前言
本文记录了我从零开始使用PyTorch搭建LeNet-5模型,对8类蔬菜水果图像分类的完整过程。重点分享训练中遇到的类别混淆问题(苹果 vs 草莓,洋葱 vs 橙子)以及如何通过数据增强和辅助分类头将准确率从83.75%提升到96.25%。代码已开源,适合新手参考。
一、项目背景
最近接到一个考核任务:基于PyTorch实现LeNet-5模型,适配自定义数据集(类别数>5),完成训练、测试及可视化。我选择了8类常见的蔬菜水果:
-
类别:apple, banana, cucumber, nut, onion, orange, strawberry, tomato
-
数据量:每类训练50张,验证10张,总计480张(所有图片自己收集并清洗)
-
要求:不能使用MNIST、CIFAR等标准数据集
我的起点:有YOLO使用经验(目标检测),但PyTorch分类任务是首次接触。
二、环境配置
# 创建虚拟环境
conda create -n lenet5_env python=3.10 -y
conda activate lenet5_env# 安装PyTorch(GPU版本)
pip3 install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/cu128# 安装其他依赖
pip install matplotlib numpy scikit-learn seaborn pillow
项目结构:
Vegetable_Classification_LeNet5/
├── dataset/
│ ├── train/ # 8个类别文件夹,每类50张
│ └── val/ # 8个类别文件夹,每类10张
├── train.py # 训练脚本
├── evaluate.py # 评估脚本
└── run_xxx/ # 训练结果保存
三、LeNet-5模型搭建
LeNet-5原始结构是针对MNIST灰度图(1×32×32,10类)。我的适配修改:
class LeNet5(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.features = nn.Sequential(
# 修改1:输入通道从1改为3(彩色图)
nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0),
nn.Tanh(),
nn.AvgPool2d(2, 2),
nn.Conv2d(6, 16, kernel_size=5),
nn.Tanh(),
nn.AvgPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.Tanh(),
nn.Linear(120, 84),
nn.Tanh(),
# 修改2:输出从10类改为num_classes(8)
nn.Linear(84, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
四、第一次训练结果:83.75%但存在严重混淆
训练50轮,验证集准确率83.75%。看着还行?但一画混淆矩阵,问题暴露了:
混淆矩阵(初始)
| 真实\预测 | apple | banana | ... | strawberry | orange | tomato |
|---|---|---|---|---|---|---|
| apple | 6 | 0 | ... | 4 | 0 | 0 |
| onion | 0 | 0 | ... | 1 | 8 | 0 |
| 其他6类 | 10 | 10 | ... | 10 | 10 | 10 |
关键问题:
-
apple:10张只对了6张,4张被误认为strawberry(都是红色圆形)
-
onion:10张只对了1张,8张被误认为orange,1张被误认为strawberry(洋葱外皮橙黄,与橙子、草莓颜色相近)
教训:不能只看总体准确率,混淆矩阵才是诊断问题的金标准。
五、优化策略一:增强数据增强
原始transform只有Resize+ToTensor+Normalize。我增加了:
train_transform = transforms.Compose([
transforms.Resize(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=25),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.2, hue=0.1),
transforms.RandomAffine(degrees=15, translate=(0.1, 0.1), scale=(0.9, 1.1)),
transforms.RandomResizedCrop(32, scale=(0.8, 1.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
效果:
-
apple准确率:60% → 70%
-
onion准确率:10% → 80%
-
总体准确率:83.75% → 88%
但apple仍有2张被误认为strawberry,说明仅靠数据增强不够。
六、优化策略二:辅助分类头(针对易混淆类别)
核心思想:在模型中间层添加辅助分类器,专门让模型学习区分混淆对(apple, strawberry)和(onion, orange)。
实现代码:
class LeNet5WithAuxiliary(nn.Module):
def __init__(self, num_classes, confusing_pairs):
super().__init__()
# 主分支(特征提取+分类)
self.features = ... # 同原始LeNet-5
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120), nn.Tanh(),
nn.Linear(120, 84), nn.Tanh(),
nn.Linear(84, num_classes)
)
# 辅助分支:输入flatten后的特征,输出每个混淆对的2分类
self.auxiliary = nn.Sequential(
nn.Linear(16*5*5, 64),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(64, len(confusing_pairs)*2)
)
self.confusing_pairs = confusing_pairs # [(0,6), (4,5)] 对应(apple,strawberry)和(onion,orange)def forward(self, x, return_aux=False):
x = self.features(x)
x = torch.flatten(x, 1)
main_out = self.classifier(x)
if return_aux:
aux_out = self.auxiliary(x)
return main_out, aux_out
return main_out
组合损失:主损失(CrossEntropy)+ 辅助损失(仅对属于混淆对的样本计算二分类交叉熵),aux_weight=0.3。
训练过程:每步同时计算主损失和辅助损失,反向传播更新全部参数。
效果:
-
apple准确率:70% → 90%(9/10)
-
onion准确率:80% → 100%(10/10)
-
总体准确率:96.25%
-
唯一错误:1个apple仍被误认为strawberry(那个苹果特别红且形状圆润)
七、最终结果对比
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 总体准确率 | 83.75% | 96.25% |
| apple准确率 | 60% (6/10) | 90% (9/10) |
| onion准确率 | 10% (1/10) | 100% (10/10) |
| apple→strawberry混淆 | 4张 | 1张 |
| onion→orange混淆 | 8张 | 0张 |
混淆矩阵(最终)
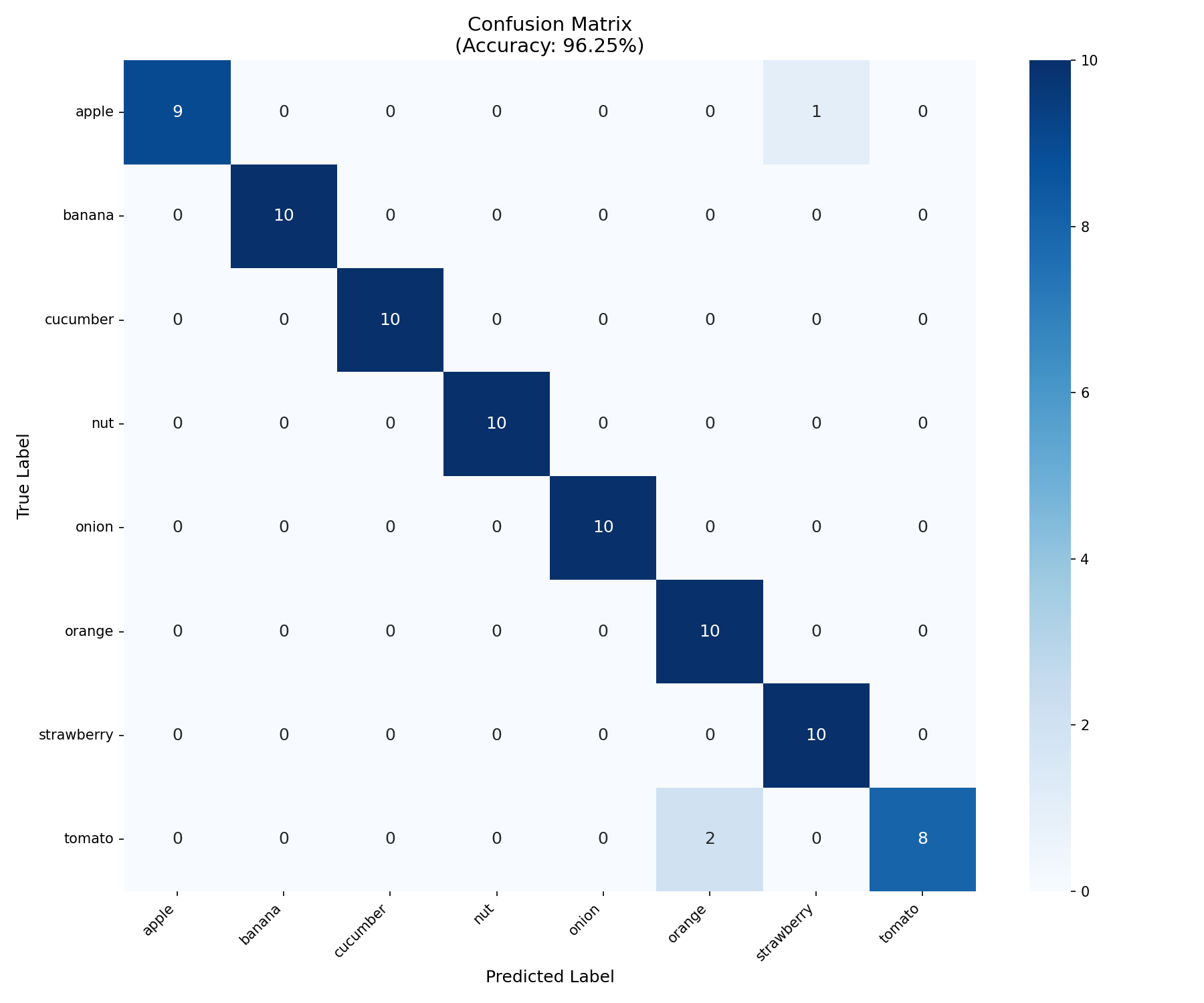
注:数据集来源于kaggle,训练集每类50张,验证集每类10张。
八、踩坑与解决汇总
| 问题 | 解决方案 |
|---|---|
| PyTorch安装失败 | 使用官方CPU安装命令,加--index-url |
| 卷积输出尺寸不匹配 | 打印每层shape,对照LeNet-5论文调整 |
| 总体准确率高但个别类很差 | 画出混淆矩阵,定位混淆对 |
| apple与strawberry混淆 | 数据增强+辅助分类头专门优化 |
| onion与orange混淆 | 同上 |
| 辅助损失权重怎么选 | 实验0.1/0.3/0.5,0.3效果最好 |
| 过拟合倾向 | 增加权重衰减(weight_decay=1e-4)+数据增强 |
九、完整代码
代码已上传至GitHub:点击查看
核心文件:
-
train.py:含数据增强+辅助分类头的完整训练脚本 -
evaluate.py:加载模型生成混淆矩阵和分类报告
十、总结与展望
收获:
-
从零跑通了PyTorch分类任务完整流程
-
学会了用混淆矩阵诊断模型问题,而不是盲目调参
-
理解了数据增强和辅助损失的实际应用场景
后续计划:
-
收集更多带叶子的苹果图片,进一步减少与草莓的混淆
-
尝试ResNet-18等现代网络对比效果
-
增加验证集数量(每类10张偏少,评估波动大)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)