影像生成模型的数学原理
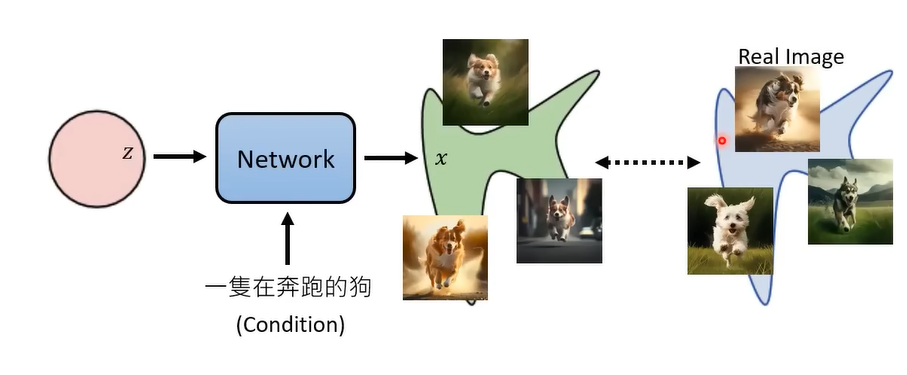
1.z是生成一个feature(特征)
2.Network相当于是一个函数G(z)=x,通过输入z特征来生成x(目标图)
注意:输入network中的z不一定是向量,图片,可以是任何形式,因为最后都会通过encoder来提取特征,输入到模型中。
3.最后这个x(预测值)要与真实的图片(real image)进行对比,看二者之间的差距。
注意:feature是通过real image提取出来的,然后通过提取出来的特征来预测原来的real image.
测量model 预测出来的Image与实际的Image之间的差距:
Maximum Likelihood Estimation(极大似然估计),这里的x是feature(特征)
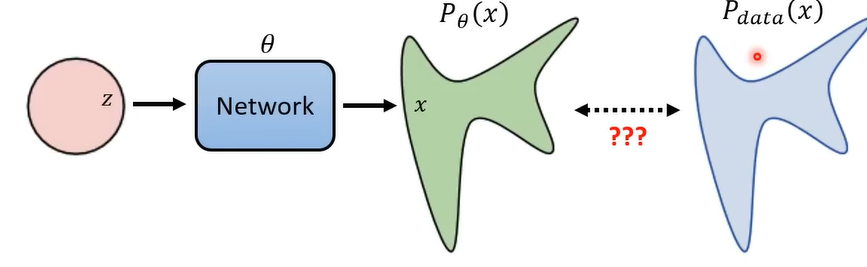
θ是model , Pθ(x)是特征经过model后生成出来的东西 , Pdata(x)是real image中的图片
1. 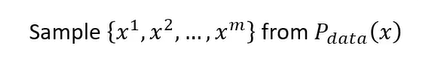
从真实图中提取几张图片
2.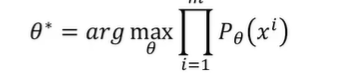
计算θ(model)可以生成出目标真实图的概率,然后相乘,看最后有多大概率就是对θ的评价。
θ*就是那个生成原图相似度最高的那个network,就是最优的model(有点像SDG)记录保存最好的那个model。
一些对θ*的数学推导,推导到KL散度
1.
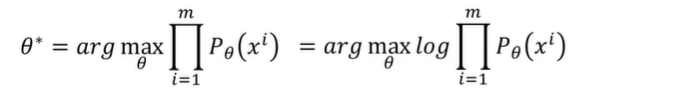
原来的θ*的量级有点高,所以将其下降量级到log。
2.
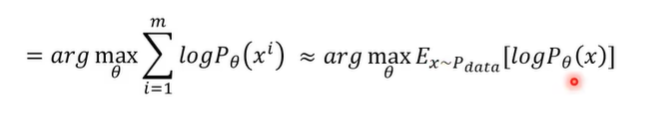
第一个等号:log(ab)=loga+logb
第二个约等号:相加就是在算期望E,Ex~Pdata的意思是从Pdata(真实值)中取出x,Pθ(x)是用θ去预测x,最后取期望。
3.
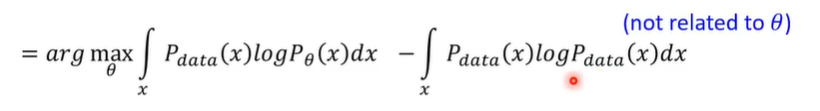
前半部分:期望的定义(积分的形式),后半部分:完全与θ(model)无关,对模型的性能评价是没有关系的,只与拿到的原始数据有关,而这一步的原因是为了合并两项(loga-logb=loga/b)
4.
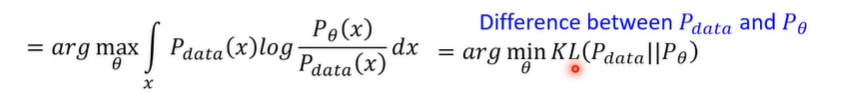
这两项合并后就是KL散度(在对预测的数据对的积分下,用原始数据的概率乘以log下x经过模型的概率除以原始数据的概率),KL散度就是评价真实值与预则值之间不一样的程度。
5.

所以从推导的形式上看,极大似然估计是找出预测效果最好的那个model,KL散度的找出预测的图片与实际图片相近的那个model.
VAE : 计算Pθ(x)
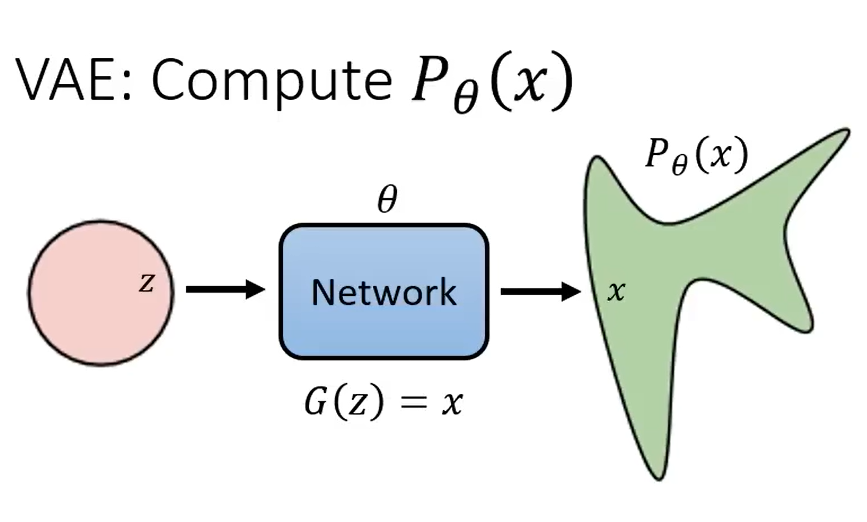
逻辑也是与上面生成类影像的模型差不多。
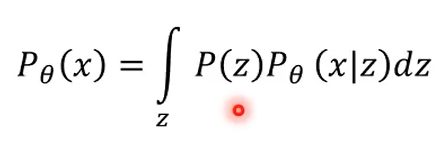
预测模型的公式就是这样,相当于求期望,x是feature
问题在于:

这个Pθ(x|z)要看G(x)的表现,如果预测出来的图片与真实的图片一样,才会设置为1,否则为0.这种过于严苛的设定,会导致评价模型的指标经常为0,所以要适当放宽要求。
所以 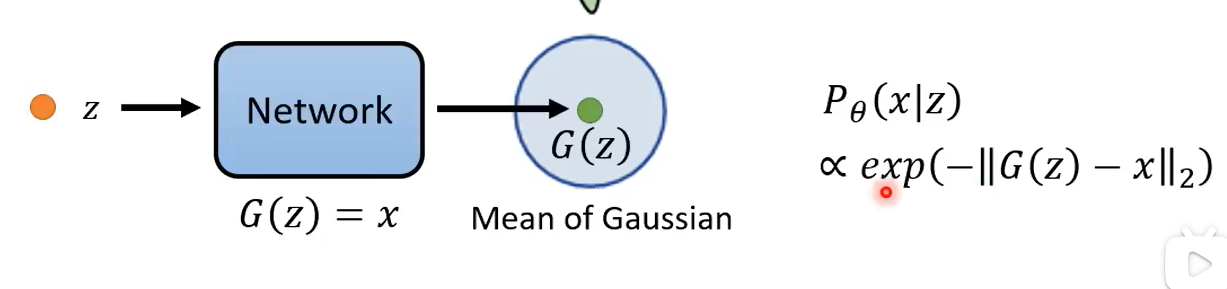
从0,1的函数分布转向求预测值G(x)与真实值x之间的距离(也就是期望)。
VAE的指标评价--用logP(x)[logP(x)是VAE评价指标的下限,但可以通过提高其下限来提高VAE的总体水平]
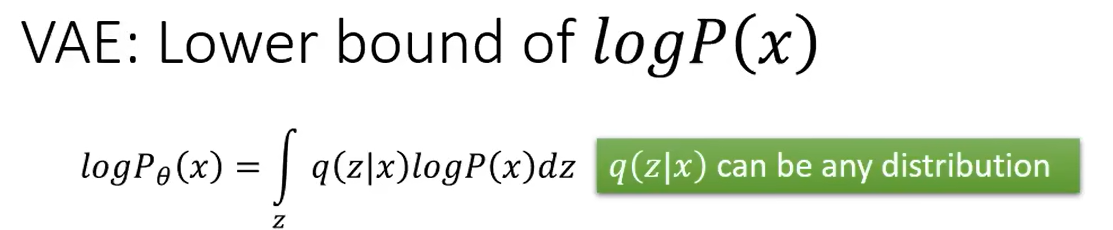
转化:
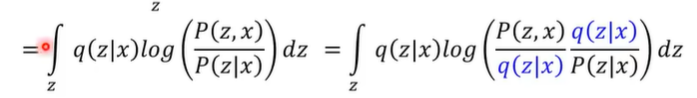
第一步是经过贝叶斯定理 【P(A|B)=P(AB)/P(B)--在B发生的概率下发生A=在发生B的概率下同时发生A和B】
第二步是为了拆开log(logab=loga+logb)
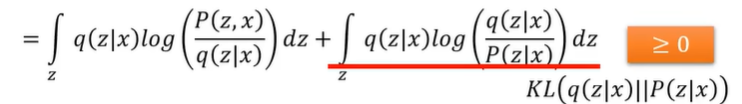
此时,后面这一项是KL散度,并且KL散度的大于0的,所以说:
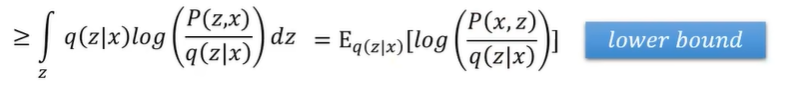
这里的下限就是这个期望,而这个Eq(z|x)就是encoder,本质就是为了提高这个lowe bound,从而提高整体的logP(x)。
DDPM:计算Pθ(x)
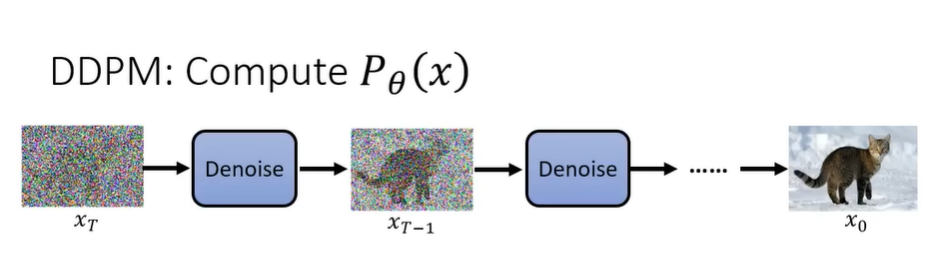
扩散模型的rever process就是将噪声图一次次去噪,从而生成出与原图相近的预测图。
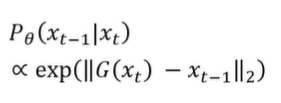 在模的前面少一个负号。
在模的前面少一个负号。
评价的方式与VAE类似,就是计算预测值与真实值之间的距离,也就是期望。
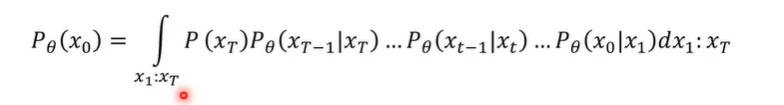
这里的x1:xT就是指x1到xT之间的所有图片,而这个公式就是马尔可夫链,只看当下对未来的影响,而不看过去对未来的影响。
这里要明确:P是反向传播[变清晰](从模糊xT->原图x0),q是前向处理[变模糊](从原图x0->模糊xT)
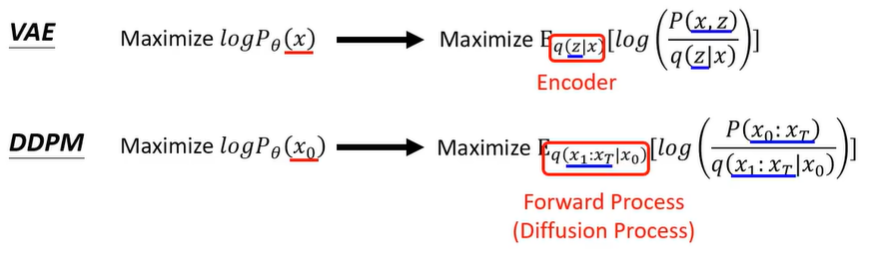
而DDPM评价指标的提高方式也是与VAE的一样,都是通过提高其下限来提高整体的性能。
同时,DDPM的评价指标是在Forward Process中产生的,也就是在从原图生成噪声的过程中。
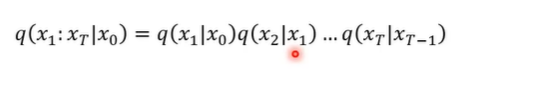
在计算前向的过程中,主要计算的是q(x1:xT|x0)【意思是在x0原图的基础上,去生成x1到xT】,而这里是全连接的转化,从x0到xT相当于是从x0到x1到x2.....到xT。
而这里的每一步前向处理就是以一定的权重将清晰图与噪声图相加,合成为一张模糊图。
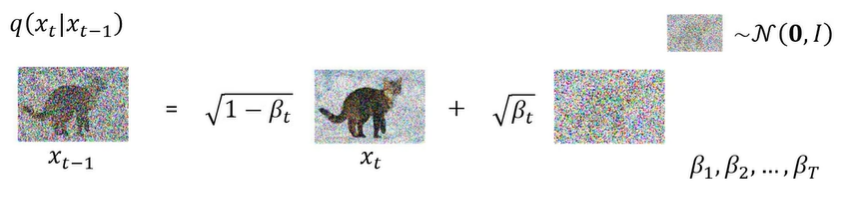
(这里的两张图片标反了,生成出来的是XT(因为越往xT越模糊))
而理论上,x0到xT就是一步步串行的生成。

将每一步分解一下:
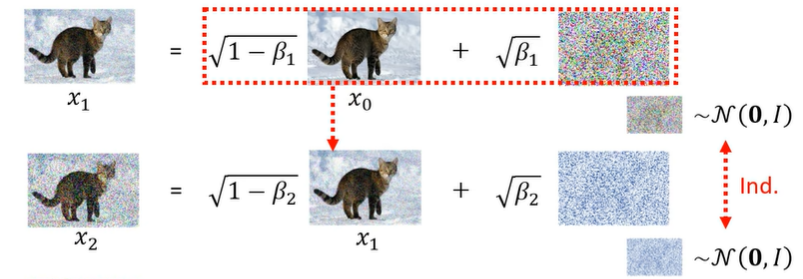
每一次的生成都是用不同的β,同时每一个噪声图的正态分布N也是不同的。
如此,将1式的x1带入到2式的x1中,就可以变成这样:
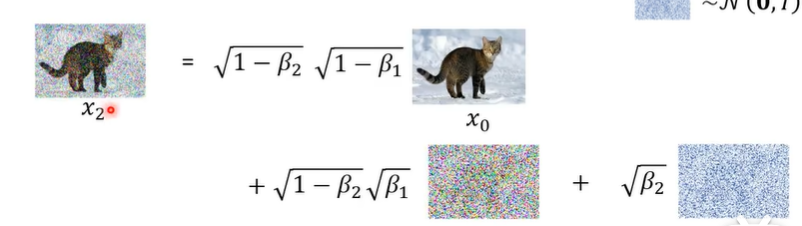
这样的好处在于:可以只用一个噪声图就可以完成前面两步的工作。
继续推导延续:

最后的XT就只是X0乘以一个参数加上噪声图乘以另一个参数。
这里的所有β相乘可以直接用一个α来代替,这样参数量也可以减少。
这就是为什么理论上要多步完成,但是实际操作则只需要一步就可以完成。
DDPM的下限:
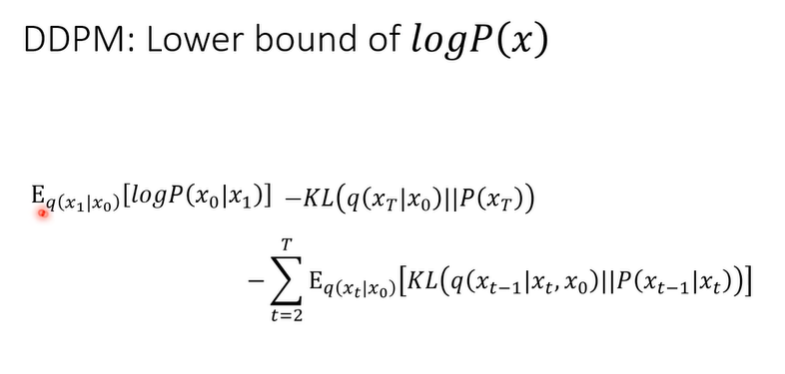
第一项的计算容易,但是x1hi是需要netwoek(model)来预测的,但只需要预测一次。
第二项的KL散度,x0是原图,xT是噪声图,一头一尾是已经定义好的了,与要训练的network(model)无关,所以可以无视。
第三项是最重要的也是最难计算的,因为Xt-1是需要network来训练的。

而这一项的重点在于这个q(xt-1|xt,x0),理解一下:q是前向传播加Noise的过程(就是以一定比例将xt和高斯分布混合得到xt+1),但是这里是从xt去推xt-1(这本来应该是P反向传播的过程,因为是从噪声图变成无噪声图的过程,相当于去噪)。

而前向的过程中,我们是这道这三项的关系的。

所以,如图,就是要通过x0与xt通过贝叶斯公式,回头计算出xt-1的关系。
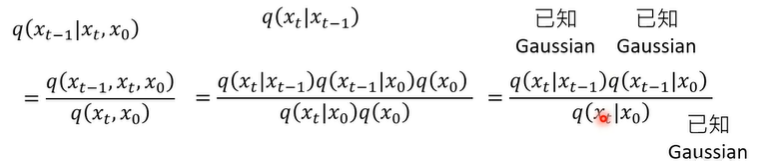
这里的前两项主要是通过条件概率的定义,链式法则,还有马尔可夫链的定义来转化的。


而且这里的Xt-1,Xt,X0在使用链式法则的时候可以不管前后的关系,也就是可以无视谁前谁后的问题,可以解决Xt-1在Xt之前的问题。

可以无视掉Xn往后的所有元素(Xn-1--X0)。
所以,变成这个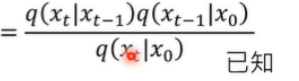 后,就可以经过数学推导推出其distribution(xt-1),而这个分布的mean(均值)和Variance(方差)
后,就可以经过数学推导推出其distribution(xt-1),而这个分布的mean(均值)和Variance(方差)
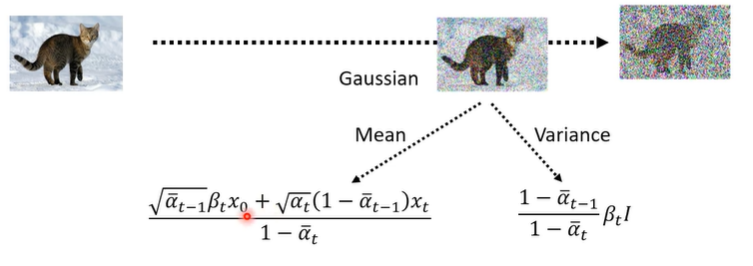
需要记住的是,这里的Mean的αt-1,x0,βt都是已经设定好的了(fixed),是不需要训练的了。(也就是与X(network)无关)。
但是我们好回到这里的总目标: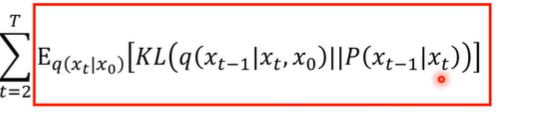
我们是要计算q(xt-1|xt,x0)与P(xt-1|xt)这两个的KL散度。第一项已经确定,mean与variance都不动。而第二项是反向传播(去噪)。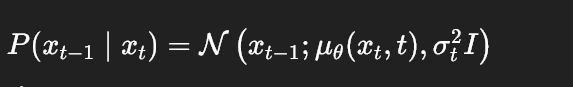
这里的u(均值)是受t步长的影响的,但是这个方差是不变的。
所以,总体来说,这两个分布(q和p)之后p的Mean是会改变的,其余的三项都是不变的。
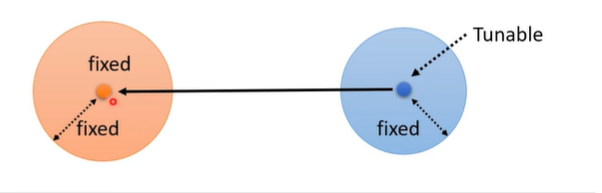
所以,唯一能让KL散度下降的方式就是将P的均值项q的均值的方向靠近,就可以让KL散度下降了。
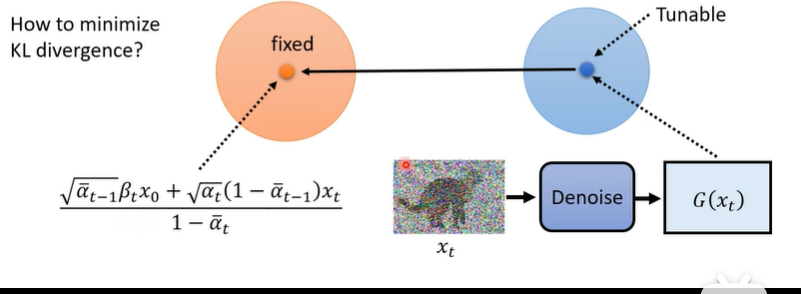
而让P的mean下降的方式就是优化Denoise,因为Denoise是反向去噪的关键训练的对象。
总体解释Sampling(去噪过程的推导)
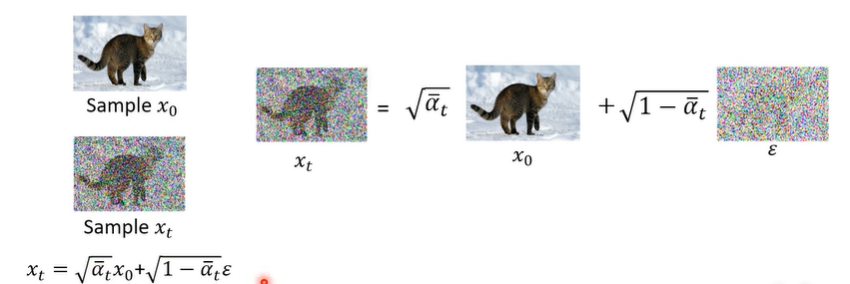
记住下面这个式子,需要后续的推导。
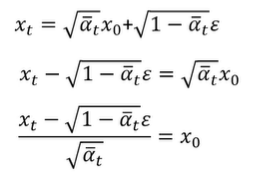 可以通过上面的式子可以求出X0(原图)是多少,用Xt.,α等来表示。
可以通过上面的式子可以求出X0(原图)是多少,用Xt.,α等来表示。![]() 是噪声图的意思。
是噪声图的意思。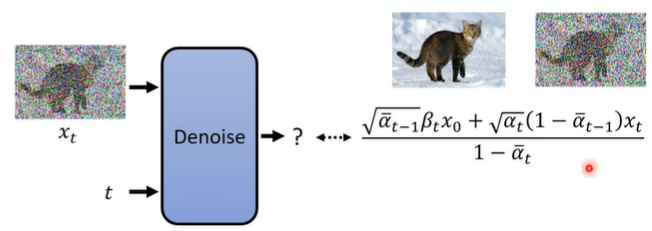
在全面计算q(Xt-1|xt,x0)的分布时,这个时候就是算出的Mean就是整一个去噪过程中,每一步去噪过程的Mean。
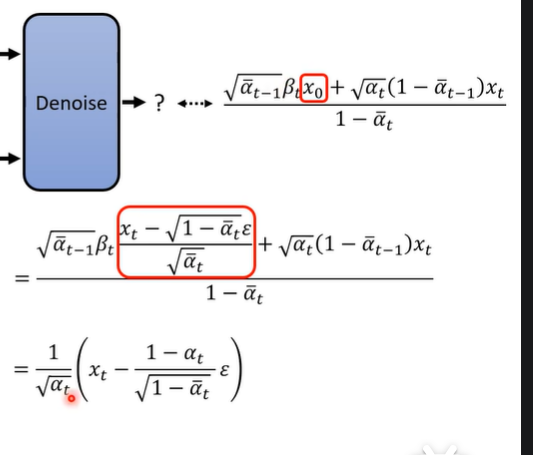
最后把转化出来的x0带入到这个分布的Mean中,然后经过一些转化,就可以得到最后的均值的表达式。。而这个式子中,α,β都是手动一次次试出来的,在Sampling(去噪)的过程中,实际只有![]() 是需要network来训练predict的,也就是说,network只需要train噪声图即可,这也与最出理论学习原理的时候一样。
是需要network来训练predict的,也就是说,network只需要train噪声图即可,这也与最出理论学习原理的时候一样。

最后所推导出来的就是每一个去噪后,图片的数学表达式,一次次从Xt铜通过此公式推导到X0.
最后加noise项的原因(猜测)
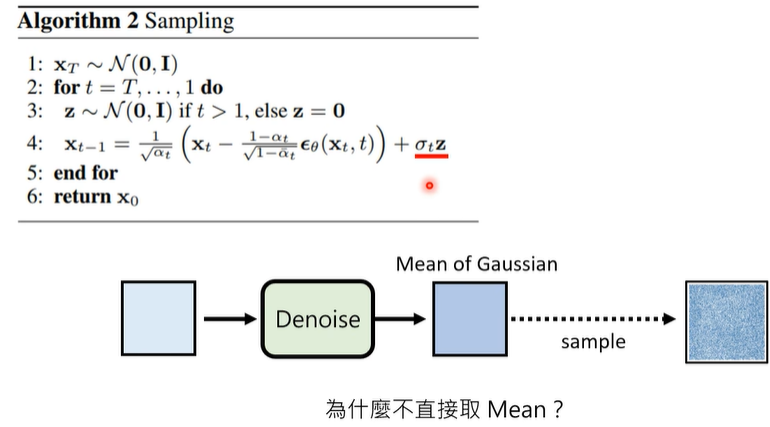
正常来说,直接取到Mean就是model最好状态下的形态了(也就是此时生成正确结果概率最高的Model了),但为什么最后还要再加一个噪声项noise![]() 呢。
呢。
主要是因为 “概率越大,但是效果不一定越好!”
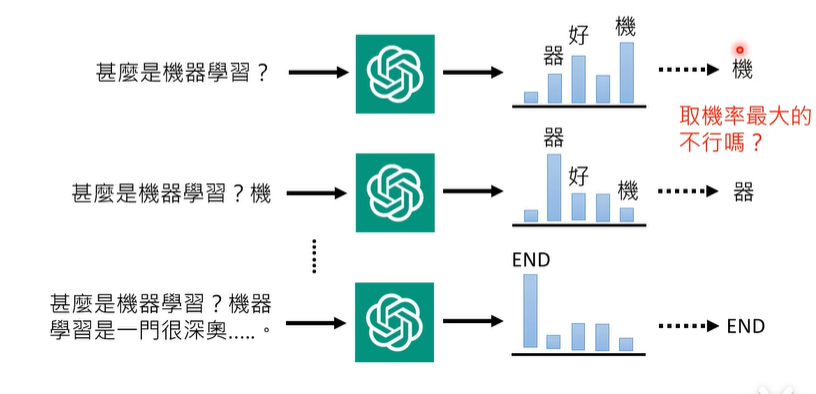
比如:

Beam Search就是选取概率最大的那个输出,但是问题在于当其输出完第一句后,就会因为学习了第一句话的内容,所以会导致在下一句的输出的时候,会重复输出上一句话一样的内容。
所以,应该要使用有随机性的Pure Sampling来作为输出,这样就可以让输出结果具有随机性,同时也避免了因为学习之前特征后所导致重复输出的情况。
其实这里面的本质原理就是“解决过拟合”,一般来说,处理过拟合的方式就是dropout(在训练的时候减少数据,在测试的使用增加数据“。这个方法一般是在训练模型的阶段才会使用,而测试的时候是不会使用的。但是在此处,他们把dropout用在了测试上面,结果反而效果更好。(这就有点像是less is more)。
而过拟合的本质就是增加model的灵活性,让模型有更多可以发挥的空间。同理,加噪声也如此,让模型多一点随机性,这样使得模型不会一直生成同一个词语。
同时,加noise的地方也会因为模型的不同,导致noise加的地方也不同。
比如:VAE 会在latent space(潜空间)中加noise
Diffusion-LM 会在Word embedding(分词器)中加noise
Mask-predict
这是Diffusion model的一个重要的精髓。
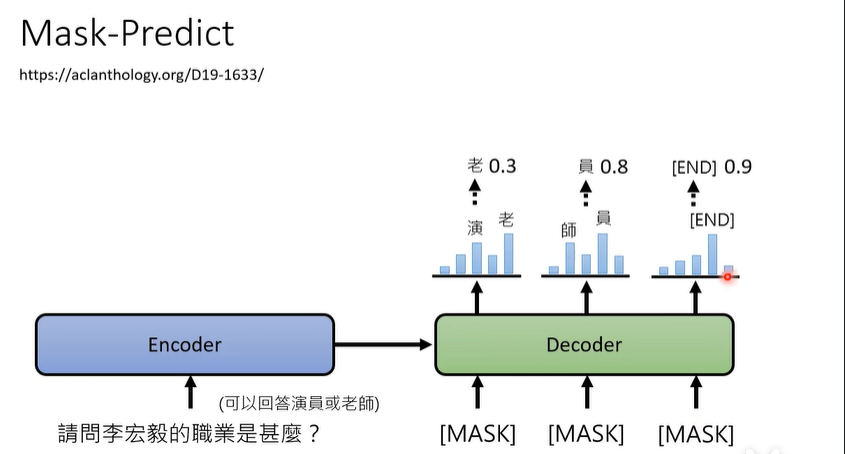
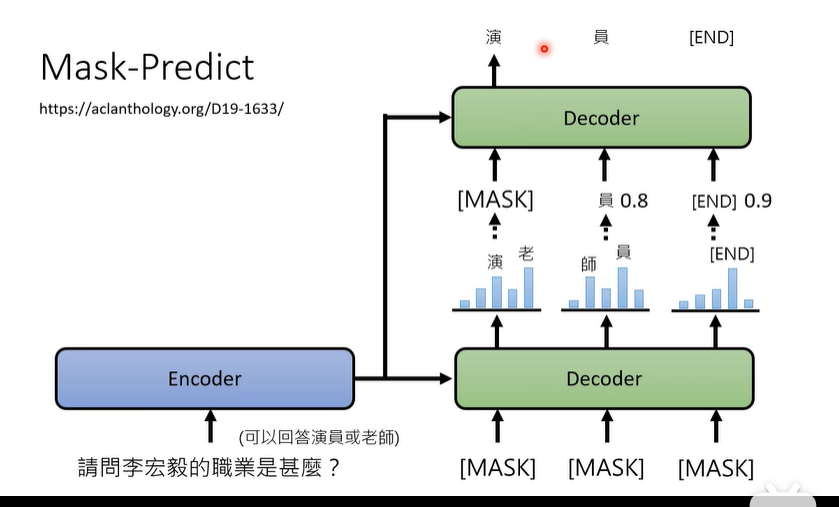
在首次生成的结果中,把概率较小的那个词给Mask掉,然后与其他相对高概率的结果再一次进行decoder,这样可以修复第一次生成导致概率小结果不好的问题(也就是可以反复修正)。
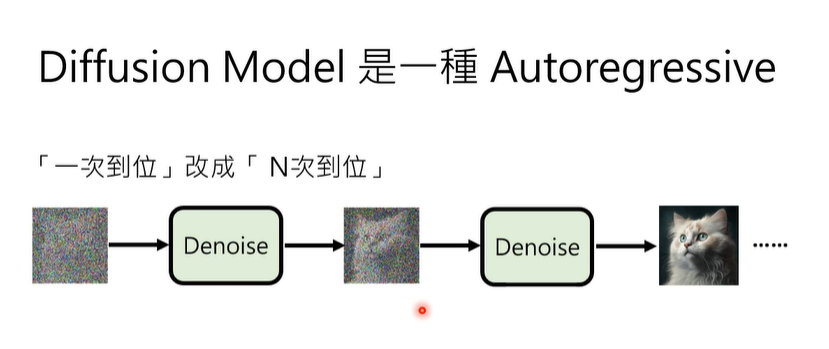
Autoregression(自回归)
diffusion model也会用自回归来生成。这样可以在一次次的生成中用denoise来不断修正最后的结果。虽然在前面的理论推导中确实可以一步到位,但是在实践中还是胡hi通过慢慢的修正来实现更加精确的结果

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)