时序数据库实测对比:KaiwuDB 3.1.0 vs TDengine 3.3.8 写入与查询性能全解析
最近因为一些业务需要,一直在研究国产时序数据库,刚好顺便出一些测评。
第一轮选中了 TDengine 和 KaiwuDB 先试试。
TDengine 确实知名度比较高,开源生态成熟,在时序数据库中还是比较有代表性的;
KaiwuDB 我也是才知道不久。24年才正式开源的国产新生代力量,在墨天轮时序库榜单上升势头极快,且去年在 benchANT 性能榜单评测中拿下第一,性能表现看上去也算是在第一梯队了。
本次测试我用 TSBS 标准跑了一组完整对比,覆盖单机 / 分布式写入、多场景查询时延,今天把结果整理出来分享给同样在选型的朋友们,仅供参考。
一、测试环境与流程说明
本次测试所有数据库进程均部署于Docker容器, Kylin Linux Advanced Server release V10 (Halberd),内核版本为 4.19.90-89.11.v2401.ky10.x86_64。硬件资源如下:
- 2 颗 Intel Xeon Gold 6240 CPU(2.6GHz 基础频率,最高 3.9GHz),共 72 逻辑核(18 核 / 颗 ×2,超线程开启),2 个 NUMA 节点
- 通过 Docker 限制单节点仅使用 16 核
- 总容量 394.8GB(MemTotal: 394835452 kB),支持 DirectMap4k / DirectMap2M / DirectMap1G 页映射
- 通过 Docker 限制单节点内存上限为 32GB
- 每个容器(节点)绑定单个 1.8TiB Intel NVMe 硬盘
测试工具与数据处理:
- TDengine:使用开源 TSBS 工具>> https://github.com/taosdata/tsbs
- KaiwuDB:使用开源 TSBS 工具>> gitee.com/kwdb/kwdb-tsbs
- 查询时间范围统一通过开源工具调整>>https://gitee.com/KiweeL/tsbs_query_modifier
二、写入性能详细对比
写入部分使用 import_speed 作为吞吐指标,单位为 rows/s,数值越高越好。
1. 单机写入吞吐量
| 场景 | TDengine(rows/s) | KaiwuDB(rows/s) | KaiwuDB相对提升 |
|---|---|---|---|
| 场景一 | 2335510.23 | 3006478.08 | +28.7% |
| 场景二 | 1824812.90 | 2961473.92 | +62.3% |
| 场景三 | 1057568.12 | 2825616.69 | +167.2% |
| 场景四 | 348140.28 | 1626088.47 | +367.1% |
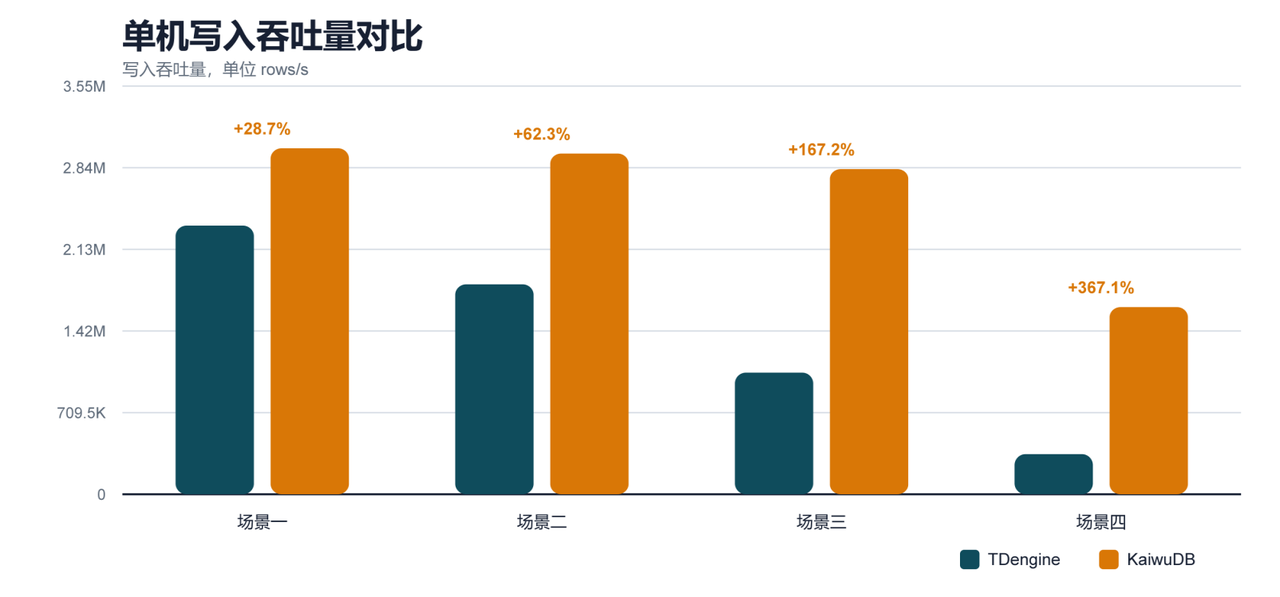
图 1:单机场景写入吞吐量对比。
单机场景下,KaiwuDB 领先,最大提升超 3.6 倍,数据规模越大优势越突出。
2. 分布式写入吞吐量
| 场景 | TDengine(rows/s) | KaiwuDB(rows/s) | KaiwuDB相对提升 |
|---|---|---|---|
| 场景一 | 2355539.30 | 1995710.07 | -15.3% |
| 场景二 | 1818971.71 | 2138717.90 | +17.6% |
| 场景三 | 1049025.07 | 1813444.69 | +72.9% |
| 场景四 | 329753.39 | 1143143.50 | +246.7% |
![[图片]](https://i-blog.csdnimg.cn/direct/0044267e7fa647cc925146c1ba7bfd5a.png)
图 2:分布式场景写入吞吐量对比。
分布式场景下,KaiwuDB 场景一落后,后续场景快速反超,最大提升超 2.4 倍。
三、查询性能详细对比
查询性能计算公式:(TDengine 延迟 - KaiwuDB 延迟)/TDengine 延迟
- 正值:KaiwuDB 时延更低,性能更优
- 负值:TDengine 时延更低,性能更优
1. 整体查询表现统计
| 部署方式 | Worker数 | KaiwuDB领先数 | 平均提升 | 最佳查询项 | 最弱查询项 |
|---|---|---|---|---|---|
| 单机 | 1 | 47/60 | +35.0% | lastpoint(+91.0%) | double-groupby-5(-41.9%) |
| 单机 | 8 | 54/60 | +62.6% | lastpoint(+94.0%) | double-groupby-1(-15.8%) |
| 分布式 | 1 | 50/60 | +26.7% | lastpoint(+88.0%) | double-groupby-5(-12.6%) |
| 分布式 | 8 | 51/60 | +50.6% | lastpoint(+91.4%) | double-groupby-1(-53.3%) |
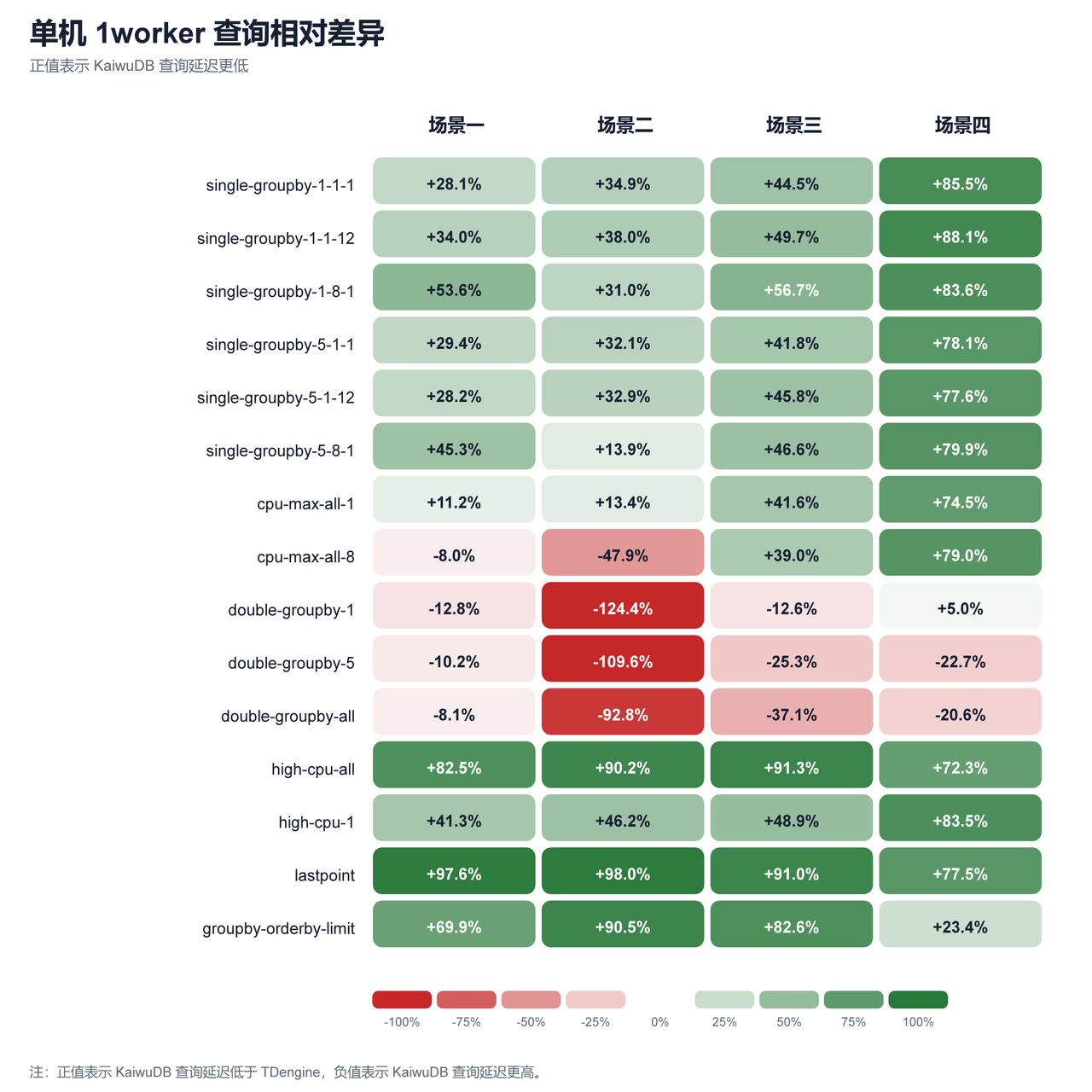
图 3:单机 1worker 查询延迟相对差异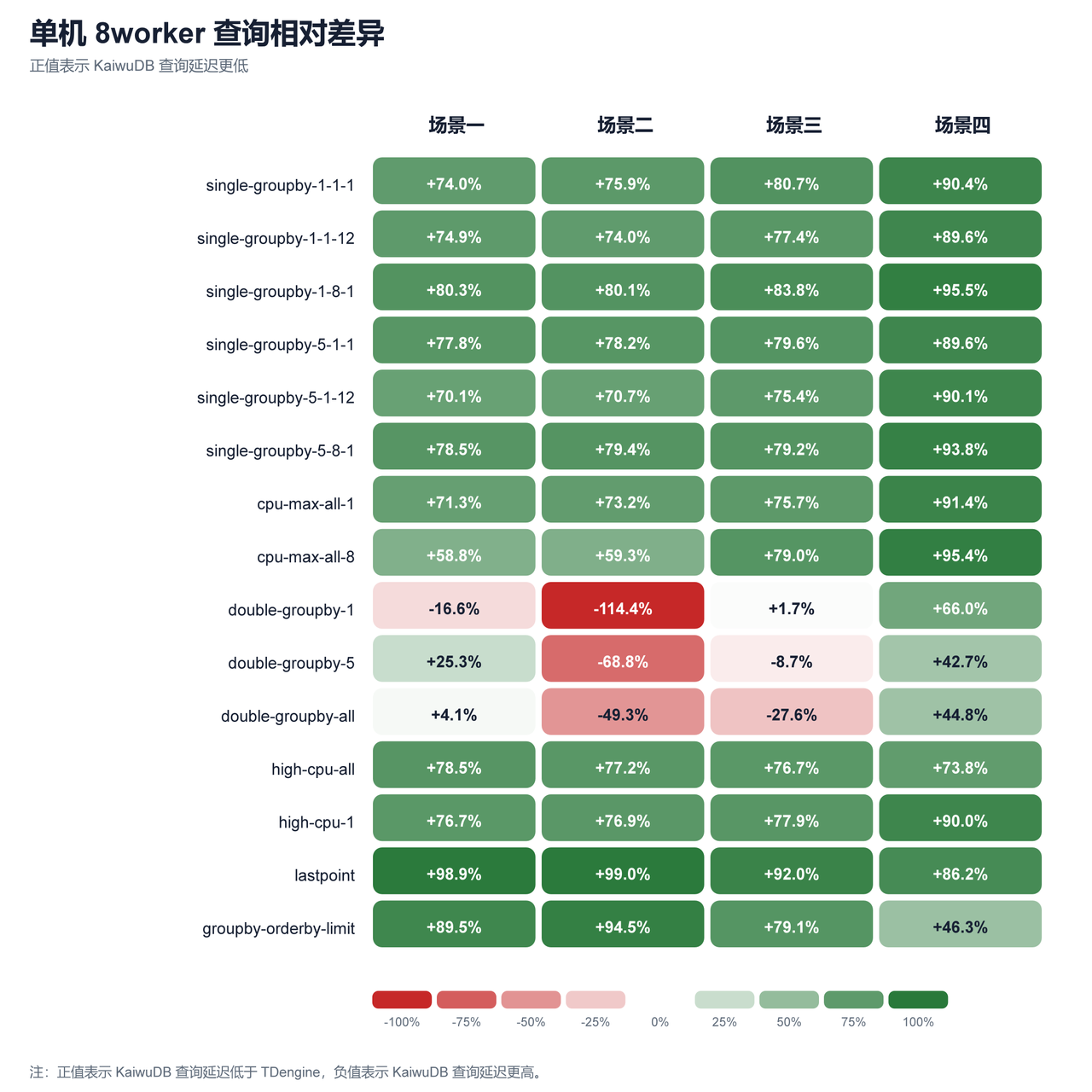
图 4:单机 8worker 查询延迟相对差异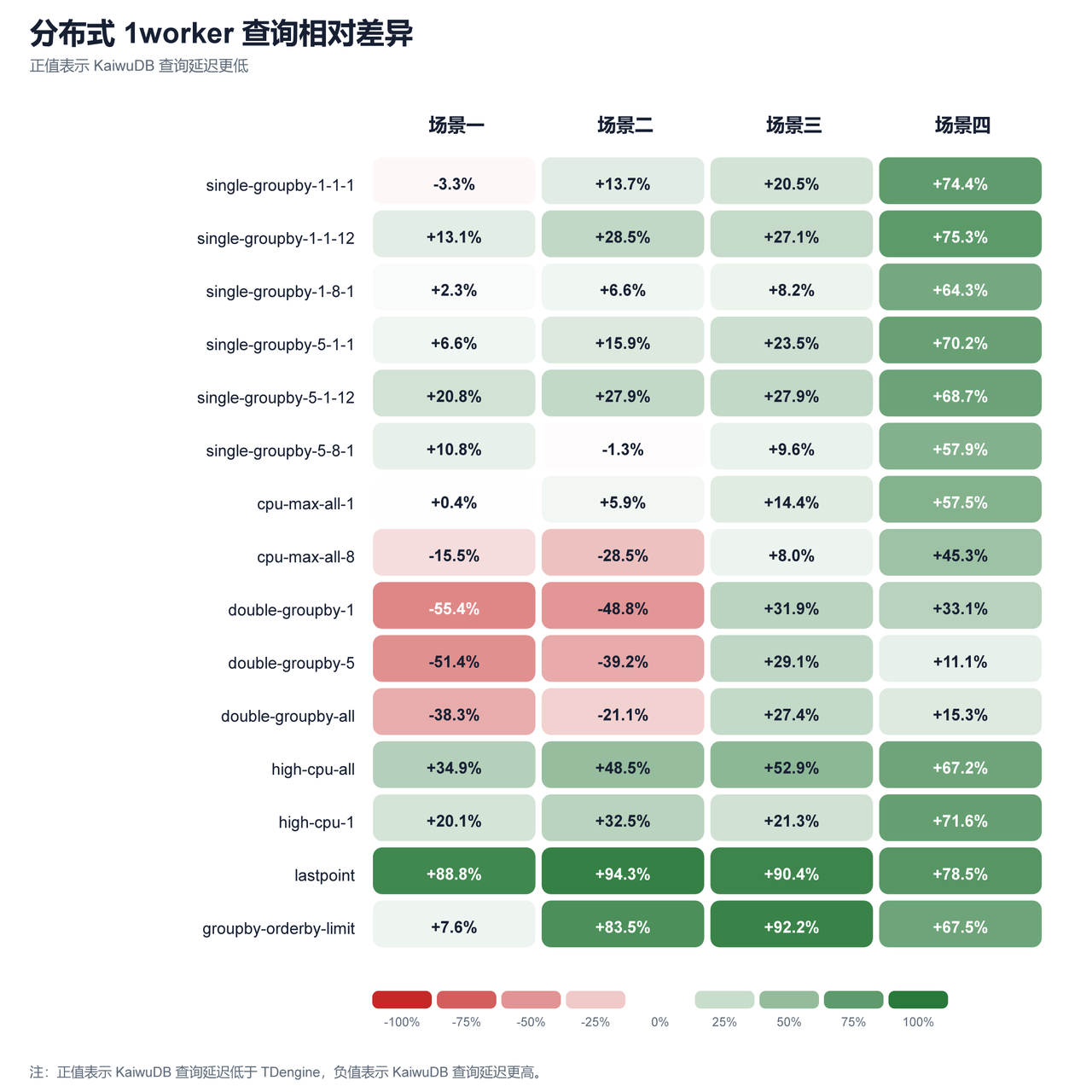
图 5:分布式 1worker 查询延迟相对差异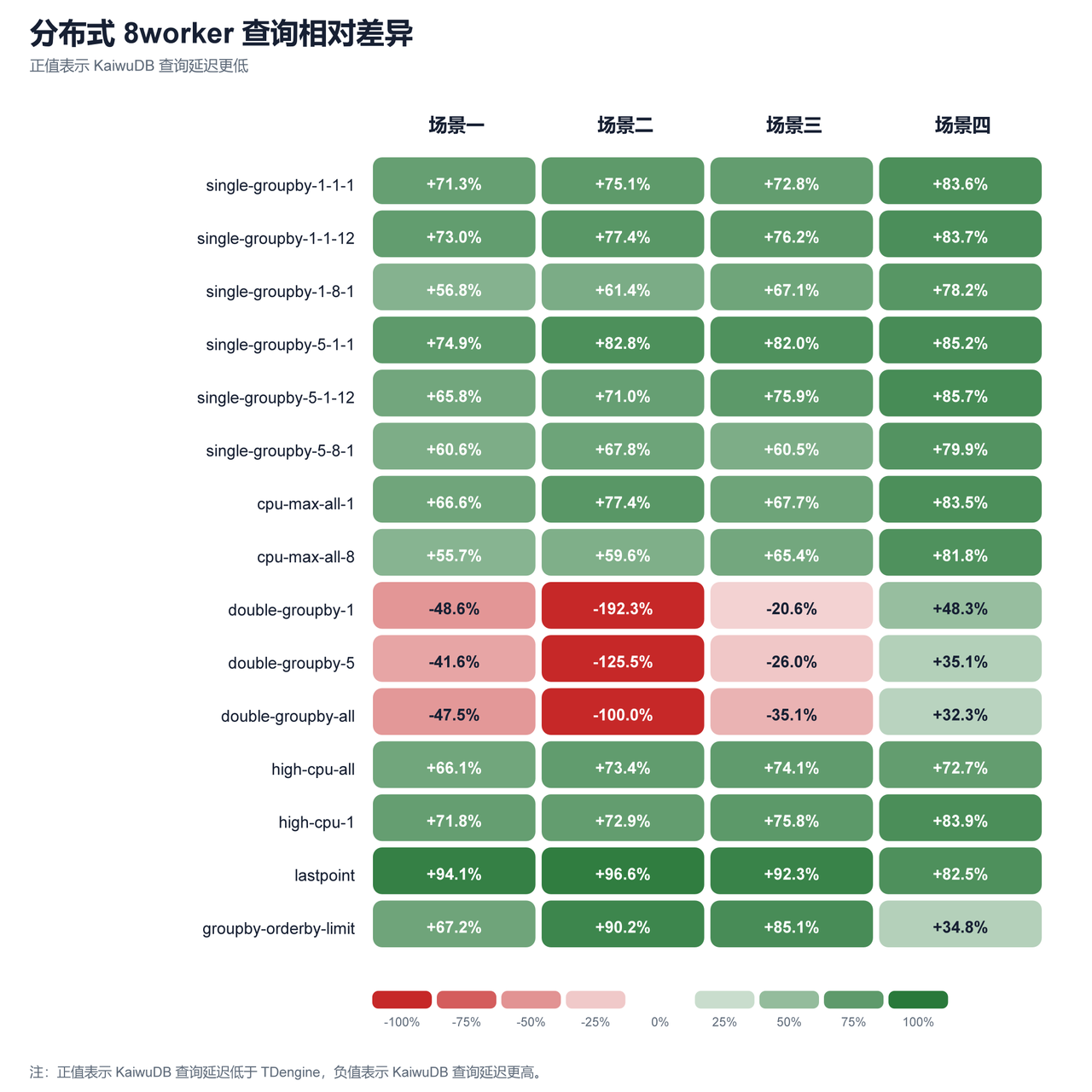
图 6:分布式 8worker 查询延迟相对差异
2. 关键场景查询表现
- 单机场景下,KaiwuDB 的写入性能在四个场景全部领先,且场景越大优势越明显。查询侧,lastpoint、high-cpu-all、single-groupby-* 等短查询改善明显,但 double-groupby-1/5/all 整体仍弱于 TDengine。
- 分布式场景下,KaiwuDB 在场景一写入略逊于 TDengine,但从场景二开始明显反超。查询方面,lastpoint、groupby-orderby-limit 和多数 single-groupby 仍然占优,double-groupby-* 在 8worker 下回退较为明显。
四、核心测试结论回顾
- 单机写入:KaiwuDB 在 4/4 个场景领先 TDengine,且随着场景规模提升,优势明显扩大。
- 分布式写入:KaiwuDB 在 3/4 个场景领先,场景一略落后,场景二至四显著反超。
- 查询性能:KaiwuDB 在 lastpoint、high-cpu-all、single-groupby 等短查询场景优势明显。
- 风险点:double-groupby-1/5/all 尤其在分布式 8worker 下仍弱于 TDengine。
五、选型建议
综合本次 TSBS 测试结果:
- KaiwuDB:写入性能全面占优,单机/大规模分布式场景优势极强;短查询、点查时延极低,适合高吞吐写入+高频简单查询的时序业务,比如产线设备实时运行监控、光伏/风机状态采集
- TDengine:在double-groupby类重聚合查询上保持稳定优势,更适合以复杂聚合计算为核心的业务场景,比如能耗管理、报表核算、负荷预测之类的
选型建议:
- 业务侧重大规模数据写入、低时延短查询 → 优先选择KaiwuDB
- 业务侧重高并发复杂聚合查询 → 建议结合实际业务模型进一步验证
大家平时用哪款时序数据库更多?欢迎在评论区交流使用经验,一起学习进步!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)