模型开发利器:打造高效 Harness 工程的九步策略
Harness 工程是模型开发中不可或缺的一环,它涵盖了模型权重之外的所有工程基础设施,包括设计环境、表达意图、构建反馈循环等。本文总结了构建 Harness 工程的理论知识点,提出了九步策略,帮助开发者打造高效的 Harness 工程。首先,将代码仓库作为唯一的事实来源,确保知识靠近代码,并使用标准化的入口文件。其次,利用 ACID 原则管理 agent 状态,保证原子性、一致性、隔离性和持久性。第三步,将指令拆分到不同文件中,避免上下文预算被吃掉,并使用专题文档按需加载。第四步,让跨会话的任务保持上下文连续,使用进度文件和决策日志记录关键信息。第五步,让 agent 每次工作前先初始化,包括搭建基础环境、验证命令和项目结构。第六步,给 agent 划清每次任务的边界,避免过度延伸和不足完成,并使用 WIP 限制和完成证据要求。第七步,使用功能清单约束 agent 该做什么,确保功能状态是机器可读的。第八步,防止 agent 提前宣告完成,使用三层终止校验和可操作的错误消息。第九步,跑通完整流程才算真正验证,包括单元测试、集成测试和端到端测试。最后,让 agent 的运行过程可观测,包括运行时可观测性和过程可观测性,并做好每次会话结束前的交接工作,保证清洁状态和会话完整性。
首先,什么是 Harness?大概的含义是模型权重之外的一切工程基础设施。OpenAI 把工程师的核心工作概括为三件事:设计环境、表达意图、构建反馈循环。Anthropic 直接把 Claude Agent SDK 称为"通用 agent harness"。所以这篇文档, 结合网络上的各种材料,整理了一些关于构建 Harness 工程的理论知识点汇总。
第一步:让代码仓库成为唯一的事实来源
OpenAI 在他们的 harness engineering 文章里把这个问题说得非常直白:仓库里不存在的信息,对 agent 来说等于不存在。 他们把这称为"仓库即规范"原则——仓库本身就是最高权威的规范文档。
怎么画好这张地图
原则 1:知识靠近代码。 一条关于 API 端点认证的规则,应该放在 API 代码旁边,而不是藏在一个巨大的全局文档里。每个模块目录下放一个简短的文档,说清楚这个模块的职责、接口和特殊约束。就像图书馆的书架标签——你想找历史类书籍,直接去标着"历史"的书架,不用把整个图书馆翻一遍。
原则 2:用标准化的入口文件。AGENTS.md(或 CLAUDE.md)是 agent 的"着陆页"。它不需要包含所有信息,但必须能让 agent 快速回答"这是什么项目"、“怎么跑”、"怎么验证"这三个问题。50-100 行就够了。
原则 3:最小但完备。 每条知识都应该有明确的使用场景。如果你删掉某条规则不影响 agent 的决策质量,那这条规则就不应该存在。但冷启动测试中的每个问题都必须有答案。这是一个精妙的平衡——不多不少,刚好够用。
原则 4:和代码一起更新。 把知识更新跟代码变更绑定在一起。最简单的方法:把架构文档放在对应的模块目录里。改代码的时候自然会看到文档,改代码之后 CI 提醒你检查文档是否需要更新。
具体的仓库结构:
project/├── AGENTS.md # 入口:项目概览、运行命令、硬约束├── src/│ ├── api/│ │ ├── ARCHITECTURE.md # API 层的架构决策│ │ └── ...│ ├── db/│ │ ├── CONSTRAINTS.md # 数据库操作的硬约束│ │ └── ...│ └── ...├── PROGRESS.md # 当前进度:做了什么、在做什么、被什么阻塞└── Makefile # 标准化的操作命令:setup、test、lint、check
用 ACID 原则管理 agent 状态
这个类比来自数据库的事务管理——你可能觉得这是在把简单的事情搞复杂,但实际上它给了你一个非常实用的框架:
- 原子性:每次"逻辑操作"(比如"添加新端点并更新测试")用一个 git commit 原子化。中途挂了就
git stash回滚。要么全做,要么不做,没有"做了一半"。 - 一致性:定义"一致状态"的验证谓词——所有测试通过、lint 无报错。Agent 每次操作后跑验证,不一致的中间状态不要 commit。
- 隔离性:多个 agent 并发工作时,状态文件要避免竞争条件。简单方案:每个 agent 用独立的进度文件,或者用 git 分支隔离。
- 持久性:关键的项目知识用 git 跟踪的文件持久化。临时状态可以只在会话内存里,但跨会话必须的知识必须写到文件里
第二步:把指令拆分到不同文件里
问题的根源:一个恶性循环
- 上下文预算被吃掉了。 Agent 的上下文窗口是有限的。假设你的 agent 有 200K tokens 的窗口(Claude 的标准),一个膨胀的指令文件可能占掉 10-20K。看起来还有不少余量?但一个复杂的任务可能需要读几十个源文件、工具执行的输出也占上下文、对话历史也在累积。到真正需要理解代码的时候,预算已经不够了
- 中间迷失。 “Lost in the Middle"这篇论文(Liu et al., 2023)清楚地证明了:LLM 对长文本中间部分的信息利用效率显著低于两端。你的 AGENTS.md 有 600 行,第 300 行写的是"所有数据库查询必须用参数化查询”——这是安全硬约束。但它被埋在中间,agent 几乎一定会忽略它。
- 优先级冲突。 文件里混合了不可违反的硬约束(“不得使用 eval()”)、重要的设计指导(“优先使用函数式风格”)、和某个特定场景的历史教训(“上周修了一个 WebSocket 内存泄漏,注意类似的模式”)。这三条规则的重要性完全不同,但在文件里看起来一模一样。Agent 没有可靠的信号来区分
- 维护衰减。 大文件天生难维护。指令过时了没人删——因为删除的后果不确定(“也许别的地方依赖这条规则?”),但加新指令是无成本的。结果文件只增不减,信噪比持续下降
- 矛盾累积。 不同时期加的指令之间开始出现矛盾——一条说"用 TypeScript 严格模式",另一条说"某些遗留文件允许用 any"。Agent 每次随机选一条遵循
指令文件架构
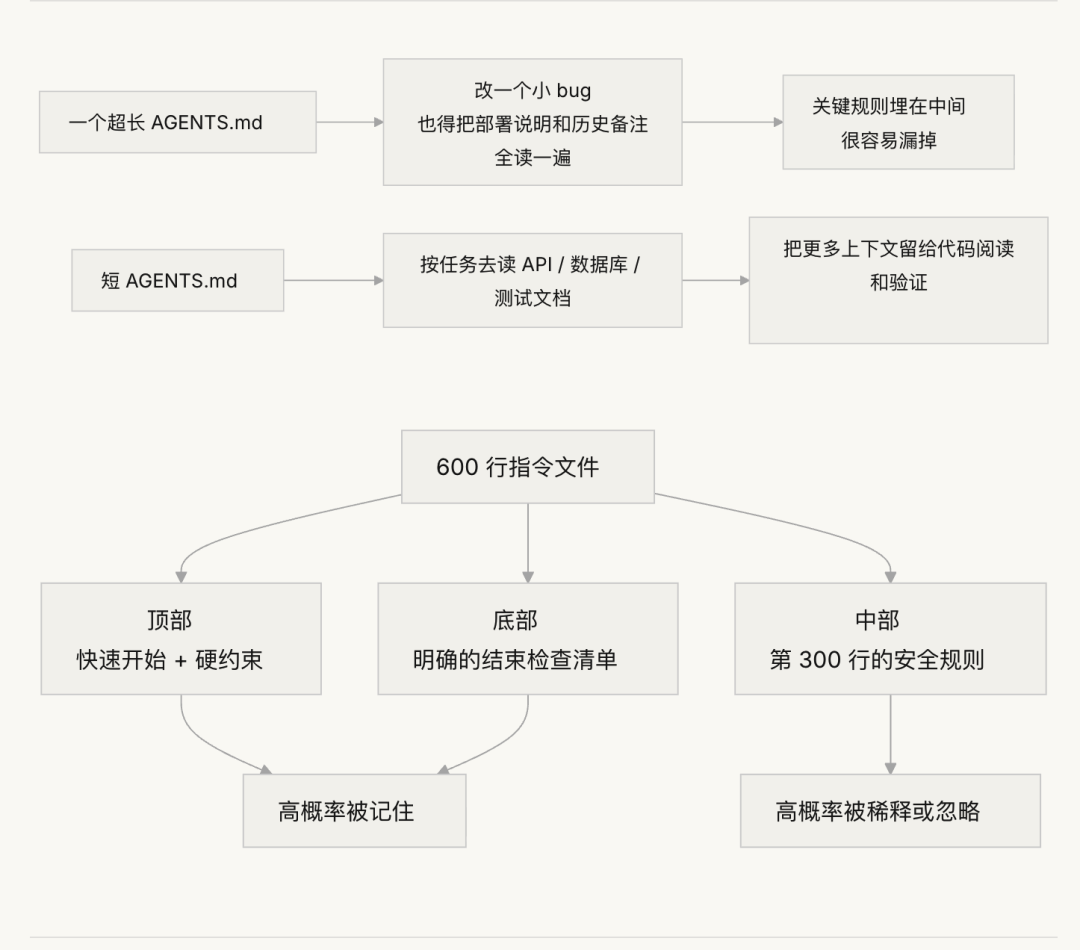
拆分思路
核心原则:常用信息放手边,偶尔用的收起来,用不上的别带。
入口文件 AGENTS.md 控制在 50-200 行,只放最常用的东西——项目概览(一两句话说清楚这是什么)、首次运行命令(make setup && make test)、全局硬约束(不超过 15 条不可违反的规则)、指向专题文档的链接(一行描述 + 适用条件)。
# AGENTS.md## 项目概览Python 3.11 FastAPI 后端,PostgreSQL 15 数据库。## 快速开始- 安装:`make setup`- 测试:`make test`- 完整验证:`make check`## 硬约束- 所有 API 必须走 OAuth 2.0 认证- 所有数据库查询必须用 SQLAlchemy 2.0 语法- 所有 PR 必须通过 pytest + mypy --strict + ruff check## 专题文档- [API 设计规范](docs/api-patterns.md) — 添加新端点时必读- [数据库操作约束](docs/database-rules.md) — 涉及数据库修改时必读- [测试标准](docs/testing-standards.md) — 编写测试时参考
每个专题文档 50-150 行,按主题放在 docs/ 目录下或对应模块目录旁。Agent 只在需要时才去读。
如果某条指令必须在入口文件里,放顶部或底部——不要放中间。"中间迷失"效应告诉我们,LLM 对长文本中间部分的信息利用效率显著低于两端。但更好的做法是把指令放到专题文档里,让 agent 按需加载。
第三步:让跨会话的任务保持上下文连续
没有连续性工件的时候,每个新会话都是一场灾难:
有连续性工件的时候,新会话能快速接上: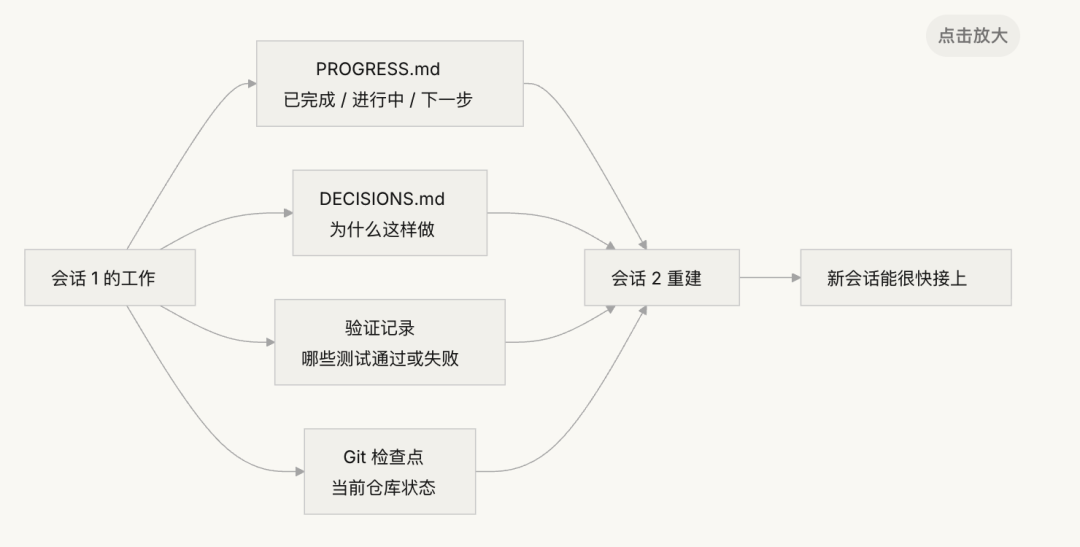
核心概念
- 上下文窗口是有限的:不管模型吹多大的窗口(128K、200K、1M),长任务总会用完。用完之后要么压缩(丢信息),要么重置(开新会话)。两种方式都会丢东西。
- 连续性工件:持久化的状态文件,让新会话能无歧义地恢复到上次离开的地方。最基本的形式:进度日志 + 验证记录 + 下一步行动。就是那个工匠的日记本。
- 重建成本:新会话恢复到可执行状态所需的时间。好的 harness 能把重建成本从 15 分钟压到 3 分钟。
- 漂移(Drift):agent 的理解跟代码仓库实际状态之间的偏差。每次会话边界都会引入漂移,不加控制会越漂越远。
- 上下文焦虑:Anthropic 观察到的现象——agent 在接近上下文限制时表现异常,过早结束任务以避免信息丢失。是一种非理性的资源焦虑。
- 压缩 vs 重置:压缩是在同一个会话里把上下文摘要化(保留"是什么",可能丢了"为什么");重置是开新会话从持久化状态重建(干净但依赖工件完备性)
连续性断了以后会发生什么
多会话协作的最大风险是决策失忆。上个会话花费大量分析选定方案 B,新会话因不了解这个过程,可能基于不完整信息重新决策,甚至选择方案 A。
缺乏状态记录会导致三个核心问题:
- 重复劳动——无法确认工作是否已完成,或发现与已有实现冲突而返工
- 目标漂移——各会话对项目目标理解略有偏差,累积后可能严重偏离原始需求
- 验证缺口——测试状态未持久化,每次都要重新诊断,浪费上下文预算
解决方案是结构化状态持久化。OpenAI 的 harness engineering 文章建议将仓库作为"操作记录",Anthropic 的 long-running agents 文档则推荐使用包含当前状态、已知问题和下一步行动的"交接文件"。
给失忆工匠的日记本
核心思路:把 agent 当成一个会失忆的超级工程师来管理。 每次它要"下班"之前,必须把关键信息写下来,让下一个"接班"的 agent 能快速上手。
工具 1:进度文件(PROGRESS.md)。这是最基本的连续性工件——日记本的核心部分:
# 项目进度## 当前状态- 最新 commit: abc1234 (feat: add user preferences endpoint)- 测试状态: 42/43 通过 (test_pagination_edge_case 失败)- Lint: 通过## 已完成- [x] 用户模型和数据库迁移- [x] 基础 CRUD 端点- [x] 认证中间件集成## 进行中- [ ] 分页功能 (90% - 边界条件测试失败)## 已知问题- test_pagination_edge_case 在空结果集时返回 500- 需要确认是否要在列表中包含已删除用户## 下一步1. 修复分页边界条件 bug2. 添加"是否包含已删除用户"的查询参数3. 更新 API 文档
工具 2:决策日志(DECISIONS.md)。记录重要的设计决策和原因。不需要详细的设计文档,只需要"什么决策、为什么、什么时候做的"——这是日记本里的备忘:
# 设计决策## 2024-01-15: 使用 Redis 缓存用户偏好- 原因: 读取频率高(每次 API 调用都需要),数据量小- 否决方案: 用 PostgreSQL 物化视图(变更频率高,物化视图维护成本不划算)- 约束: 缓存 TTL 设为 5 分钟,写入时主动失效
工具 3:git 提交作为检查点。 每完成一个原子工作单元就提交。commit message 要说清楚做了什么和为什么。这是免费的、自动版本化的状态快照。
工具 4:init.sh 或 harness 的初始化流程。 在 AGENTS.md 里写明每天"上班"和"下班"的流程:
## 每次会话开始时(上班打卡)1. 读 PROGRESS.md 了解当前状态2. 读 DECISIONS.md 了解重要决策3. 跑 make check 确认仓库处于一致状态4. 从 PROGRESS.md 的"下一步"部分继续工作## 每次会话结束前(下班打卡)1. 更新 PROGRESS.md2. 跑 make check 确认一致状态3. 提交所有已完成的工作
混合策略:不需要每次都重置上下文。短任务(30 分钟以内)可以在同一个会话里完成。长任务(跨会话)必须用进度文件和决策日志来维持连续性。判断标准:如果任务需要的上下文超过窗口的 60%,就开始准备交接。
上下文焦虑的深层分析
Anthropic 在 2026 年 3 月发布的研究进一步揭示了上下文焦虑的具体表现:在 Sonnet 4.5 上,当上下文接近窗口限制时,agent 会表现出强烈的"过早收敛"行为。这就像考试时发现时间快到了,赶紧随便填选择题。
针对这个现象,有两种策略:
压缩(Compaction):在同一个会话里把早期对话摘要化。优点是保留连续性,agent 能看到"是什么"。缺点是"为什么"经常在摘要中丢失——为什么选了方案 B 而非 A,为什么跳过了某个优化。更关键的是,压缩并不能消除上下文焦虑——agent 知道上下文曾经很大,心理上仍然倾向于加速收尾。
重置(Context Reset):完全清空上下文,开一个新会话,从持久化工件重建。优点是干净的心理状态——新会话没有"我快没时间了"的焦虑。缺点是依赖交接工件的完备性。如果日记本里漏了关键信息,新会话可能在错误方向上浪费时间。
Anthropic 的实际数据:对于 Sonnet 4.5,上下文焦虑足够严重,以至于压缩单独不够用,上下文重置成为 harness 设计的关键组件。但对于 Opus 4.5,这种行为大幅减弱,可以不依赖重置而靠压缩管理上下文。这意味着:harness 设计需要对目标模型有具体的理
来源:Anthropic: Harness design for long-running application development
第四步:让 agent 每次工作前先初始化
你开了一个新的 agent 会话,让它"帮我加个搜索功能"。它上来就开始改代码。改了 20 分钟发现测试框架没配好,又花 10 分钟搞测试框架,然后发现数据库迁移脚本格式不对,又折腾了一会儿。最后搜索功能倒是加了,但整个会话的效率很低——大部分时间花在了"搞清楚这个项目怎么运作"上,而不是写搜索功能。
更好的做法是:在让 agent 开始干活之前,先用一个独立的阶段把基础环境搭好、验证命令跑通、项目结构搞清楚。
地基和墙:两种完全不同的工作
初始化和实现的目标不同:前者为后续工作铺路,后者交付可见功能。混为一谈时,agent 自然优先选择"看得见"的功能代码,而忽视基础设施——这种短视会在后续引发系统性问题。
初始化生命周期

核心概念
- 初始化阶段:agent 生命周期中的第一个阶段,不做功能实现,只建立后续所有实现阶段的执行前提。输出不是代码,而是基础设施。
- 自举契约:一个项目能被全新 agent 会话无歧义操作的条件——能启动、能测试、能看进度、能接手下一步。四个条件缺一不可。
- 冷启动 vs 热启动:冷启动是从空目录开始,agent 要猜项目结构;热启动是从模板或已有项目开始,基础设施已经就位。热启动的效果远好于冷启动——就像在有水电的工地上开工,比在荒郊野岭从头搞起快得多。
- 交接就绪性:项目在任何时刻都处于"可以被全新 agent 接手"的状态。不需要口头解释,只看仓库内容就能接着干。
- 首次验证时间:从项目开始到第一个功能点通过验证的时间。这是衡量初始化效率的核心指标。
- 下游可用性:初始化质量的最佳衡量标准——后续会话不需要依赖隐式知识就能成功执行任务的比例。
怎么做好初始化
把初始化当作一个独立的阶段来执行。 第一个会话只做初始化,不写任何业务功能代码。初始化的产出是:
1. 可运行的环境。 项目能启动、依赖都装好、没有环境问题。地基浇好了,没裂缝。
2. 可验证的测试框架。 至少有一个示例测试能通过。这证明测试框架本身是配对的——就像地基上立了一根柱子,证明地基能承重。
3. 自举契约文档。 一个明确的文档告诉后续会话:
# 初始化契约## 启动命令- 安装依赖:`make setup`- 启动开发服务器:`make dev`- 运行测试:`make test`- 完整验证:`make check`## 当前状态- 所有依赖已安装并锁定- 测试框架已配置(Vitest + React Testing Library)- 示例测试通过(1/1)- Lint 规则已配置(ESLint + Prettier)## 项目结构- src/ — 源代码- src/components/ — React 组件- src/api/ — API 客户端- tests/ — 测试文件
4. 任务分解。 把整个项目拆成有序的任务列表,每个任务有明确的验收标准:
# 任务分解## Task 1: 用户认证基础- 实现 JWT 认证中间件- 添加登录/注册端点- 验收标准:pytest tests/test_auth.py 全部通过## Task 2: 用户资料页面- 实现用户资料 CRUD- 添加资料编辑表单- 验收标准:pytest tests/test_profile.py 全部通过## Task 3: 搜索功能- ...
5. Git 提交作为检查点。 初始化完成后提交一个干净的 checkpoint。后续所有工作都从这个 checkpoint 开始。
热启动策略:不要从空目录开始。用一个项目模板(create-react-app、fastapi-template 等)预置好标准的目录结构、依赖配置和测试框架。把通用的初始化步骤预置到模板里,只留下项目特有的初始化工作。就像在有通水通电的工地上开工,比从荒郊野岭开始强一万倍。
初始化的完成条件:不是"写了多少代码",而是自举契约的四个条件都满足了——能启动、能测试、能看进度、能接手下一步。用这个检查清单验收初始化:
## 初始化验收清单- [ ] `make setup` 从零开始能成功- [ ] `make test` 至少有一个测试通过- [ ] 新的 agent 会话能只看仓库回答"怎么跑"和"怎么测"- [ ] 任务分解文件存在且有至少 3 个任务- [ ] 所有内容已提交到 git
第五步:给 agent 划清每次任务的边界
你让 Claude Code “给这个项目加上用户认证功能”,结果它同时开始改数据库 schema、写路由、改前端组件、还顺手重构了错误处理中间件。两个小时后你一看——12 个文件被修改,800 行新代码,但没有一个功能是端到端跑通的。
Anthropic 在 “Effective harnesses for long-running agents” 工程博客中明确指出:当提示太宽泛时,agent 倾向于"同时启动多件事"而非"先做完一件事"。OpenAI 在 Codex 工程实践中也发现,没有显式范围控制的任务,完成率会暴跌。这不是模型的问题——是你没有在 harness 里给它划清边界。
注意力是有限的资源
这不是比喻,是数学。假设 agent 的上下文容量为 C,同时激活 k 个任务,每个任务平均获得 C/k 的推理资源。当 C/k 低于完成单个任务所需的最小阈值时,所有任务都做不完。这就像你的胃就那么大——同时塞十个包子进去,不是一个都消化不了,而是十个都消化不良。
Claude Code 的真实行为很说明问题。你让它"添加用户注册功能",它很可能这样做:
- 创建 User model
- 写注册路由
- 发现需要邮箱验证,于是加邮件服务
- 看到密码需要加密,于是引入 bcrypt
- 注意到错误处理不统一,于是重构全局错误中间件
- 看到测试文件结构不清晰,于是重组目录结构
6 步之后,每一个都是半成品。没有端到端验证,代码之间耦合复杂,下一个会话来接手时会一脸懵。就像一个人同时炒六道菜,每道菜都下了锅但没有一道出锅——全糊了。
Anthropic 的实验数据直接支持这一点:使用"小下一步"策略(等价于 WIP=1)的 agent,任务完成率比使用宽泛提示的 agent 高 37%。更有意思的是,agent 生成的代码行数和实际完成的功能数量呈弱负相关——写得越多,完成得越少。贪多嚼不烂,数据为证。
核心概念
- 过度延伸(Overreach):agent 在一次会话中激活的任务数量超过最优值。它不是主观判断,而是可量化的——同时做 5 个功能但 0 个跑通,就是 overreach。
- 不足完成(Under-finish):已启动的任务中,通过端到端验证的比例低于阈值。写了代码但没跑通测试,就是 under-finish。
- WIP 限制(Work-in-Progress Limit):来自 Kanban 方法论。核心思想:限制同时在进行的任务数量。对于 agent,WIP=1 是最安全的默认值——做完一个再做下一个。就像自助餐厅不要一次拿太多盘子,吃完一盘再去拿下一盘。
- 完成证据(Completion Evidence):一个任务从"进行中"变成"已完成"必须满足的可验证条件。没有这个,agent 会用"代码看起来没问题"代替"行为通过测试"。
- 范围表面(Scope Surface):一个 DAG 结构,每个节点是一个工作单元,边是依赖关系。状态只有四种:未开始、进行中、阻塞、已通过。
- 完成压力(Completion Pressure):harness 通过 WIP 限制和完成证据要求共同产生的约束力,迫使 agent 先完成当前任务再开始新任务。
怎么做才对
1. 强制 WIP=1
这是最直接有效的方法。在你的 harness 里,明确告诉 agent:任何时刻只允许一个任务处于"进行中"状态。 在 Claude Code 的 CLAUDE.md 或 Codex 的 AGENTS.md 里写:
## 工作规则- 每次只做一个功能点- 当前功能点端到端验证通过后,才能开始下一个- 不要在实现功能 A 时"顺便"重构功能 B
2. 给每个任务定义显式的完成证据
完成不是"代码写完了",而是"行为验证通过了"。在你的功能列表里,每个条目都要有验证命令:
F01: 用户注册 验证: curl -X POST /api/register -d '{"email":"test@example.com","password":"123456"}' | jq .status == 201 状态: passing
3. 把范围表面外部化
用一个机器可读的文件(JSON 或 Markdown)记录所有任务的状态。任何新会话都能直接读这个文件,知道:哪个任务在做?什么行为算完成?已经通过了什么验证?
4. 监控验证完成率
harness 应该持续跟踪 VCR(Verified Completion Rate)= 已通过验证的任务数 / 已启动的任务数。VCR < 1.0 时,阻止新任务启动。
第六步:用功能清单约束 agent 该做什么
你让 agent 做一个电商网站,跑完之后它告诉你"做完了"。你打开代码一看——用户认证有了,但购物车的结算按钮点了没反应,支付流程根本没接上。问题是:你从来没告诉它"做完"的标准是什么,所以它用自己的标准——“代码写了不少,看起来挺完整”。
功能清单(feature list)在很多人眼里就是个备忘录——写下来怕忘了,写完扔在一边。但在 harness 的世界里,功能清单不是给人看的备忘录,而是整个 harness 的脊梁骨。调度器靠它选任务,验证器靠它判完成,交接器靠它生成报告。脊梁骨断了,全身都瘫。
Anthropic 和 OpenAI 都强调:工件必须外部化。功能状态必须是仓库里机器可读的文件,不能是对话里的非结构化描述。
Agent 不知道"做完"是什么意思
Claude Code 和 Codex 都不会自动知道你心目中的"做完"是什么意思。你说"加一个购物车功能",模型的理解可能是"写一个 Cart 组件和 addToCart 方法"。而你的意思是"用户能从浏览商品到下单支付完整走通"。
看看这种常见的进度记录:
做了用户认证、购物车基本完成了、还需要做支付
新的 agent 会话看到这个记录,能回答以下问题吗?“基本完成"意味着什么?购物车通过了哪些测试?支付的阻塞条件是什么?答案都是"不知道”。就像你看病时跟医生说"我肚子疼,最近还行",医生能开出什么药来?
结果是:新会话花 20 分钟推断项目状态,最终可能重复实现已完成的功能。Anthropic 的工程实践数据表明,好的进度记录可以减少 60-80% 的会话启动诊断时间。
核心概念
- 功能清单是 harness 原语:它不是"可选的规划工具",而是其他所有 harness 组件依赖的基础数据结构。就像数据库里的表结构——你不能说"要不我们省掉主键吧",省掉了整个系统就散架了。
- 三元组结构:每个功能项是
(行为描述, 验证命令, 当前状态)的三元组。缺了任何一项,这个功能项就不完整。行为描述告诉 agent 做什么,验证命令告诉它怎么算做完,状态告诉它现在到哪了。 - 状态机模型:每个功能项有四种状态——
not_started、active、blocked、passing。状态转移由 harness 控制,不是 agent 想改就能改。 - 通过状态门控:功能从
active变成passing的唯一方式是验证命令执行成功。这是不可逆的——passing了就不能退回去。就像考试及格了就是及格了,不能事后改成分数。 - 单一权威来源:项目里关于"该做什么"的所有信息,必须从一个功能清单派生。不能出现功能清单和对话记录矛盾的情况。
- 反向压力:还没通过的功能项数量就是 harness 对 agent 施加的压力。压力归零 = 项目完成。
为什么功能清单必须是"原语"
文档是给人看的,原语是给系统用的。文档可以被忽略,原语不能被绕过。类比数据库的触发器约束和应用层的检查逻辑:前者由数据库引擎强制执行,任何 SQL 都无法跳过;后者依赖于应用代码的正确性,可能被意外绕过。功能清单作为 harness 原语,就是数据库级别的约束——agent 不能绕过它。
具体来说,功能清单服务四个 harness 组件:
- 调度器:读状态,选下一个
not_started的功能。就像工厂的排产系统——看完订单才知道下一步做什么。 - 验证器:执行验证命令,判断是否允许状态转移。就像质检——不是你说合格就合格,得通过检验。
- 交接报告器:从功能清单自动生成会话交接摘要。就像换班时自动生成的交接表——不用手写,系统自己出。
- 进度追踪器:统计各状态分布,提供项目健康度指标。就像仪表盘——一眼看出项目走到哪了。
怎么做
1. 定义一个最小化的功能清单格式
不需要复杂的系统,一个结构化的 Markdown 或 JSON 文件就够了。关键是每个条目必须有三元组:
{ "id": "F03", "behavior": "POST /cart/items with {product_id, quantity} returns 201", "verification": "curl -X POST http://localhost:3000/api/cart/items -H 'Content-Type: application/json' -d '{\"product_id\":1,\"quantity\":2}' | jq .status == 201", "state": "passing", "evidence": "commit abc123, test output log"}
2. 让 harness 控制状态转移
agent 不能直接把状态改成 passing。它只能提交验证请求,harness 执行验证命令,根据结果决定是否允许状态转移。
3. 在 CLAUDE.md 里写清楚规则
## 功能清单规则- 功能清单文件: /docs/features.md- 每次只激活一个功能项- 功能项验证命令必须通过才能标为 passing- 不要修改功能清单的状态——由验证脚本自动更新
4. 粒度校准
每个功能项应该是"一次会话能完成"的范围。太粗了做不完,太细了管理开销大。"用户可以添加商品到购物车"是一个好粒度,"实现购物车"太粗了,"创建 Cart 模型的 name 字段"太细了。就像切牛排——不能整块啃,也不能切成肉沫。
第七步:防止 agent 提前宣告完成
你让 agent 实现"密码重置"功能。它改了数据库 schema、写了 API 端点、加了邮件模板,跑了单元测试(全部通过),然后自信地告诉你"做完了"。你实际一跑——密码重置链接发不出去(邮件服务配置缺失)、数据库迁移半途失败(schema 不一致)、端到端流程根本没走过一遍。
Guo 等人 2017 年在 ICML 上的经典论文证明:现代神经网络系统性地过度自信——模型自报的置信度显著高于实际准确率。AI 编码 agent 也一样:它"觉得"做完了,但实际上差得远。你的 harness 必须用外部化的、基于执行的验证来替代 agent 的"感觉"。
滑坡效应
过早完成声明几乎总是一样的套路:代码看着还行——语法正确、逻辑似乎合理,静态检查没有明显错误。但 harness 没有强制要求全面执行验证,agent 跳过了实际运行或只跑了部分测试。跑了单元测试但跳过集成测试,跑了测试但没检查覆盖率。最后"代码看起来没问题"就被当作了"功能已完成"的证据。交卷了。
每一步都在丢失信息。从任务规范到代码实现到运行时行为,每次转换都可能引入偏差,而每次跳过的验证都加剧了信息不对称。
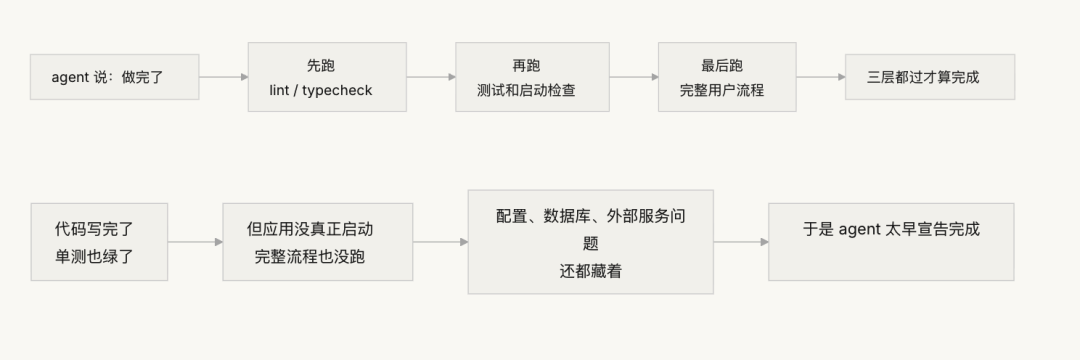
三层终止检查
核心概念
- 过早完成声明:agent 断言任务完成,但实际上存在未满足的正确性规范。核心问题:agent 依据代码层面的局部信心做判断,系统级正确性需要全局验证。
- 置信度校准偏差:agent 自报的完成信心与实际完成质量之间的系统性差距。对复杂多文件任务,这个偏差显著为正——agent 总是比实际做得更自信。就像学生考完试估分总是偏高。
- 终止标准:一组明确的、可执行的判定条件,定义在 harness 里。agent 必须满足所有条件才能声明完成。"完成"从主观判断变成了客观判定。
- 验证-确认双闸门:第一层验证检查"代码是否正确实现了指定行为";第二层确认检查"系统级行为是否满足端到端需求"。两层都通过才算完成。
- 运行时反馈信号:来自程序执行的日志、进程状态、健康检查。这是 harness 判定完成质量的客观基础。
- 完成优先级约束:先验证功能正确性,再处理性能,最后管风格。核心功能没验证通过之前,不许做重构。
单元测试通过 ≠ 任务完成
这是最常见的陷阱,也是最危险的一个。agent 写了代码,跑了单元测试,全部绿色,然后说"做完了"。但单元测试的设计哲学——隔离被测单元、模拟依赖——恰好使其无法检测跨组件问题:
接口不匹配:渲染进程传给预加载脚本的文件路径是相对路径,但预加载脚本期望绝对路径。各自的单元测试都用了 mock,都通过了。只有端到端跑通时才发现问题。
状态传播错误:数据库迁移改了表结构,但 ORM 的缓存层还持有旧结构的缓存条目。单元测试每次都是全新的 mock 环境,不会暴露这种跨层状态不一致。
环境依赖性:代码在测试环境(一切 mock)行为正确,在真实环境因配置差异、网络延迟、服务不可用而失败。
"顺便重构"是完成判定的毒药
Claude Code 有一个常见行为模式:在核心功能还没验证通过时就开始重构代码、优化性能、改进风格。Knuth 说的"过早优化是万恶之源"在 agent 场景中有了新含义——重构会改变已完成验证和未完成验证之间的边界,可能破坏之前隐式正确的代码路径。就像你数学大题还没做完,就跑去把前面选择题的答案重新抄一遍格式.
自我评价的系统性偏差
Anthropic 在 2026 年的研究中发现了一个更深层的失败模式:**当 agent 被要求评估自己的工作时,它系统性地过度正面评价——即使人类观察者认为质量明显不达标。
这个问题在主观任务(如设计审美)上尤其严重——"布局是否精致"是一个判断题,agent 可靠地偏向正面。即使在有可验证结果的任务上,agent 也会因为判断失误而影响表现。
解决方案不是让 agent “更客观”——同一个模型既生成又评估,内在地倾向对自己慷慨。解决方案是把"干活的人"和"检查的人"分开。 就像考试不能让学生自己批改自己的卷子——得有个独立的阅卷老师。
一个独立的评估 agent,经过专门调校为"挑剔"之后,比让生成 agent 自我评估有效得多。Anthropic 的实验数据:
| 架构 | 运行时长 | 成本 | 核心功能是否可用 |
|---|---|---|---|
| 单 agent 裸跑 | 20 分钟 | $9 | 否(游戏实体无法响应输入) |
| 三 agent(planner + generator + evaluator) | 6 小时 | $200 | 是(游戏可以正常游玩) |
这是同一个模型(Opus 4.5),同一段提示词(“做一个 2D 复古游戏编辑器”)。区别只在 harness——从"裸奔"到"planner 扩展需求 → generator 逐功能实现 → evaluator 用 Playwright 实际点击测试"。
来源:Anthropic: Harness design for long-running application development
怎么防止提前交卷
1. 外部化终止判定
完成判定不应该由 agent 自己做。harness 独立执行终止校验,输入是运行时信号,不是 agent 的置信度。在 CLAUDE.md 里写清楚:
## 完成定义- 功能完成 = 端到端验证通过,不是"代码写完了"- 必须运行的验证层级: 1. 单元测试通过 2. 集成测试通过 3. 端到端流程验证通过- 在第 1 层没通过时,不许进入第 2 层- 在第 2 层没通过时,不许进入第 3 层
2. 构建三层终止校验
- 第一层:语法与静态分析。成本最低,信息量最小,但必须通过。这是最低限度的检查——字都没写错才能往下看。
- 第二层:运行时行为验证。测试执行、应用启动检查、关键路径验证。这是核心完成证据。不仅要写了,还要能跑。
- 第三层:系统级确认。端到端测试、集成验证、用户场景模拟。防止过早声明的最后一道防线。不仅要能跑,还要跑对。
3. 为 agent 设计好的"红笔批注"
OpenAI 在 Codex 实践中提出了一个特别有效的模式:给 agent 写的错误消息要包含修复指导。不要像阅卷老师只画个大红叉,要像好老师一样在旁边写上"这里应该怎么改"。不要用 "Test failed",而用 "Test failed: POST /api/reset-password returned 500. Check that the email service config exists in environment variables. The template file should be at templates/reset-email.html." 这种具体的、可操作的反馈让 agent 能自我修正,而不需要人类介入。
4. 捕获运行时信号
有效的运行时信号包括:
- 应用是否成功启动并达到就绪状态?
- 关键功能路径在运行时是否执行成功?
- 数据库写入、文件操作等副作用是否正确?
- 临时资源是否被清理?
第八步:跑通完整流程才算真正验证
问题场景:给 Electron 应用加文件导出功能。渲染进程、预加载脚本、服务层的单元测试全部通过,但实际点击导出——路径格式错误、进度条无响应、大文件内存泄漏。5 个组件边界缺陷,单元测试零发现。
Google 测试金字塔:大量单元测试是基础,但止步于此会系统性地漏掉组件交互问题。AI agent 倾向于只跑最快测试然后宣告完成,只有端到端测试能证明系统级缺陷不存在。
1. 为什么单元测试不够
单元测试的哲学是隔离——模拟依赖,专注被测单元。这种隔离制造了系统性盲区:
| 盲区 | 表现 | 单元测试为何发现不了 |
|---|---|---|
| 接口不匹配 | 渲染进程传相对路径,预加载期望绝对路径 | mock 数据各自适配,真实交互才暴露 |
| 状态传播错误 | 表结构已改,ORM 缓存仍持旧结构 | 每次测试都是全新 mock 环境 |
| 资源生命周期 | 句柄/连接/套接字跨组件获取释放 | 每个测试独立创建销毁资源 |
| 环境依赖性 | 测试环境正常,真实环境因配置/延迟/服务失败 | mock 掩盖真实环境问题 |
2. 端到端测试改变编码行为
当 agent 知道工作必须通过端到端测试时:
- 考虑组件交互——关注"这个接口和上游怎么对接"
- 尊重架构边界——被迫遵守边界规则
- 处理错误路径——测试包含的故障场景迫使考虑异常
3. 审查反馈循环
端到端运行路径(穿过真实系统):
点击渲染层按钮 → Preload 桥 → 服务层 → 文件系统 → 真实导出文件
单元测试范围(各自孤立):
渲染层测试 | Preload 测试 | 服务层测试
反馈循环示例:
发现 renderer 直接 import fs ↓加 direct fs import 检查 ↓报错告诉 agent:把文件访问移到 preload ↓检查加入 harness ↓以后再犯第一时间报错
OpenAI:为 agent 写的错误消息必须包含修复指导。
- ❌
"Direct filesystem access in renderer" - ✅
"Direct filesystem access in renderer. All file operations must go through the preload bridge. Move this call to preload/file-ops.ts and invoke it via window.api."
4. 核心概念
| 概念 | 定义 |
|---|---|
| 组件边界缺陷 | 各组件单元测试通过,但交互产生错误行为 |
| 测试充分性梯度 | 单元 ⊆ 集成 ⊆ 端到端(检测能力递增) |
| 架构边界执行 | 把架构规则变成可执行检查 |
| 审查反馈提升 | 把重复的审查意见转化为自动化测试 |
| 面向 agent 的错误消息 | 什么问题 + 为什么 + 怎么修 |
5. 实践步骤
5.1 先定架构边界
端到端测试的前提是系统有清晰边界。架构是一团面条,端到端测试只能证明"这团面条整体能跑"。
OpenAI 经验:架构约束必须是第一天就建立的早期前置条件。agent 会复制仓库中已有的模式,没有约束会在每次会话中引入偏差。
分层领域架构:
Types → Config → Repo → Service → Runtime → UI
依赖方向严格向前,跨领域通过显式 Providers 接口。
原则:执行不变量,不微管实现。要求"数据在边界解析",但不规定用哪个库。
来源:OpenAI: Harness engineering
5.2 包含端到端层
## 验证层级- 层级 1: 单元测试 (必须通过)- 层级 2: 集成测试 (必须通过)- 层级 3: 端到端测试 (跨组件修改时必须通过)- 跳过任何必须层级 = 未完成
5.3 架构规则可执行化
# 检查渲染进程是否直接调用 Node.js APIgrep -r "require('fs')" src/renderer/ && exit 1 || echo "OK"
5.4 设计可操作的错误消息
ERROR: Found direct import of 'fs' in src/renderer/App.tsx:12WHY: Renderer process has no access to Node.js APIs for securityFIX: Move file operations to src/preload/file-ops.ts and call via window.api.readFile()
5.5 建立反馈提升流程
每次审查中发现新类型的 agent 错误,转化为自动化检查。一个月后 harness 会比月初强得多。
第九步:让 agent 的运行过程可观测
你让 agent 做一个功能,它跑了 20 分钟,改了一堆文件,然后告诉你"做完了但有两个测试失败"。你问它为什么失败,它说"不太确定,可能是时序问题"。你问它改了哪些关键路径,它说"让我看看代码……"。
没有可观测性,agent 在不确定状态中做决策,评估变成主观判断,重试变成盲目摸索。 OpenAI 和 Anthropic 都将可靠性定义为证据问题——harness 必须以可指导下一步决策的形式暴露运行时行为和评估信号。
可观测性缺失的真实代价
当 harness 缺乏可观测性时,四类问题系统性出现:
- **无法区分"正确"和"看似正确"**:一个函数在代码审查时看起来完全正确——语法对、逻辑通。但运行时因为边界条件处理错误,在特定输入下产生了不正确结果。只有运行时追踪能揭示实际执行路径偏离了预期。
- 评估变成玄学:没有评分标准和验收条件时,评估者(人或 agent)依赖隐式假设。同一个输出,不同评估者可能给出截然不同的评价。质量评估不可复现。
- 重试变成盲猜:agent 不知道为什么失败时,重试方向是随机的。它可能在错误的方向上反复尝试——修复了不相关的代码路径而忽略真正的故障根源。就像你开车发现车跑偏了,但你没有仪表盘——你猜是轮胎的问题换了轮胎,实际是方向盘的 alignment 出了问题。每次盲重试都消耗 token 和时间。
- 会话交接信息断崖:当未完成的工作移交给下一个会话时,缺乏可观测性意味着新会话必须从零诊断系统状态。Anthropic 的长期运行 agent 观察表明,这种重复诊断可能占会话总时间的 30-50%。
双层可观测性
 **运行时可观测性**:系统层的信号——日志、追踪、进程事件、健康检查。回答"系统做了什么"。这是你车上的仪表盘——速度、油量、发动机温度。
**运行时可观测性**:系统层的信号——日志、追踪、进程事件、健康检查。回答"系统做了什么"。这是你车上的仪表盘——速度、油量、发动机温度。
过程可观测性:harness 决策工件的可见性——计划、评分标准、验收条件。回答"为什么这个变更应该被接受"。这是你的导航系统——不光知道现在在哪,还知道为什么走这条路。
核心概念
- 运行时可观测性:系统层的信号——日志、追踪、进程事件、健康检查。回答"系统做了什么"。
- 过程可观测性:harness 决策工件的可见性——计划、评分标准、验收条件。回答"为什么这个变更应该被接受"。
- 任务轨迹:一个任务从开始到完成的完整决策路径记录,类似分布式系统中的请求追踪。agent 的每一步操作及其上下文都被记录。就像黑匣子——出了问题可以回放完整过程。
- 冲刺合同:编码开始前协商的短期协议——明确任务范围、验证标准、排除项。是过程可观测性的核心工具。
- 评估评分标准:把质量评估从主观判断变成基于证据的结构化评分。使不同评估者对同一输出产生相似结论。就像体操比赛的评分标准——有了它,十个裁判的分才不会差太远。
- 双层可观测性:系统层和过程层同时设计、相互增强。运行时信号解释行为,过程工件解释意图。
为什么 agent 自己解决不了这个问题
你可能在想:“agent 不能自己打日志吗?” 问题在于:
- agent 不知道它不知道什么——它不会主动记录自己没意识到需要的信号。
- 日志格式不统一——不同会话用不同的日志格式,无法做系统化分析。就像十个司机各写各的交接记录,格式都不一样,下一个司机看不懂。
- 过程可观测性不是日志能解决的——冲刺合同和评分标准是结构化的工件,需要 harness 层面的支持。不是多 print 几行就能搞定的。
怎么装仪表盘
1. 在 harness 里内置运行时信号采集
不要依赖 agent 自己打日志。harness 应该自动采集以下信号:
- 应用生命周期:启动、就绪、运行、关闭各阶段状态
- 功能路径执行:关键路径的执行记录,包括入口、检查点和出口
- 数据流:数据在组件间的流转记录
- 资源利用:异常的资源使用模式(如内存持续增长)
- 错误和异常:完整的错误上下文,不只是错误消息
2. 实施冲刺合同
在每个任务开始前,生成者和评估者(可能是同一个 agent 的不同调用)协商一份合同——就像施工队开工前签的施工协议:
# 冲刺合同: 暗色模式支持## 范围- 修改主题切换组件- 更新全局 CSS 变量- 添加暗色模式测试## 验证标准- 每个组件的视觉回归测试通过- 主流程端到端测试通过- 无样式闪烁 (FOUC)## 排除项- 不处理打印样式- 不处理第三方组件暗色模式
3. 建立评估评分标准
把"好不好"变成可量化的评分——就像给体操比赛定评分标准:
# 评分标准| 维度 | A | B | C | D ||------|---|---|---|---|| 代码正确性 | 所有测试通过 | 主流程通过 | 部分通过 | 编译失败 || 架构合规 | 完全合规 | 轻微偏离 | 明显偏离 | 严重违反 || 测试覆盖 | 主流程+边缘 | 仅主流程 | 仅有骨架 | 无测试 |
4. 用 OpenTelemetry 标准化
为每个 harness 会话创建一个 trace,每个任务创建一个 span,每个验证步骤创建子 span。使用标准属性标注关键信息。这样可观测性数据可以和标准工具链(Jaeger、Zipkin)集成。
Anthropic 的三 agent 架构实验
Anthropic 在 2026 年 3 月发布了一项系统性的 harness 实验。他们用三种架构跑同一个任务(“用 Web Audio API 做一个浏览器端 DAW”),记录了详细的阶段数据:
| Agent 和阶段 | 时长 | 成本 |
|---|---|---|
| Planner(规划者) | 4.7 分钟 | $0.46 |
| Build 第 1 轮 | 2 小时 7 分钟 | $71.08 |
| QA 第 1 轮 | 8.8 分钟 | $3.24 |
| Build 第 2 轮 | 1 小时 2 分钟 | $36.89 |
| QA 第 2 轮 | 6.8 分钟 | $3.09 |
| Build 第 3 轮 | 10.9 分钟 | $5.88 |
| QA 第 3 轮 | 9.6 分钟 | $4.06 |
| 总计 | 3 小时 50 分钟 | $124.70 |
三个 agent 各司其职,每个都有明确的可观测性角色:
Planner(规划者):接收一段 1-4 句话的用户需求,扩展成完整产品规格。被要求"大胆设定范围"并且"专注于产品上下文和高层技术设计,而不是详细的技术实现"。原因是:如果 planner 过早指定了粒度技术细节且搞错了,错误会级联到下游实现。更好的做法是约束交付物,让 agent 在执行中自己找到路径。就像建筑设计师只画效果图和结构图,不规定每块砖怎么砌。
Generator(生成者):按 sprint 逐个功能实现。每个 sprint 前和 evaluator 协商一份 sprint 合同——约定这个功能块"做完"的标准。然后按合同实现,自评后交给 QA。按合同施工,不按感觉施工。
Evaluator(评估者):用 Playwright MCP 像用户一样点击运行中的应用,测试 UI 功能、API 端点和数据库状态。对每个 sprint 按四个维度评分——产品深度、功能性、视觉设计和代码质量。每个维度有硬性阈值,任一不达标则 sprint 失败,generator 收到详细反馈后修复。就像验收工程师拿着验收标准逐项检查——不达标就打回去重做。
QA 第 1 轮反馈的示例——“这是一个视觉上令人印象深刻的应用,AI 集成工作良好,但核心 DAW 功能有几个是展示性的,没有交互深度:剪辑不能拖拽/移动,没有乐器 UI 面板(合成器旋钮、鼓垫),没有视觉效果编辑器(EQ 曲线、压缩器仪表)”。这些不是边缘情况——它们是让 DAW 可用的核心交互。具体的、有证据的反馈,不是"感觉不对"。
Evaluator 不是一开始就这么强。早期版本会识别出合理的问题,然后说服自己这些问题不严重,最终批准工作。调校方式是:读 evaluator 的日志,找到它的判断和人类判断分叉的地方,更新 QA 的 prompt 解决那些问题。经过几轮这种开发循环,evaluator 的评分才变得合理。就像训练一个新验收工程师——一开始他太宽容,出了几次事故后学会了严格。
来源:Anthropic: Harness design for long-running application development
第十步:每次会话结束前都做好交接
问题场景:agent 跑了下午,改了 20 个文件,会话结束。下一个会话开始——构建失败、测试红的、临时文件到处都是、进度不清楚。新会话的前 30 分钟全花在"搞清楚上一个会话干了什么"。
OpenAI 和 Anthropic:长期可靠性取决于操作纪律,不仅是单次运行的成功。
为什么交接检查是必须的
OpenAI 的 5 个月 Codex 实验发现:agent 会复制仓库中已有的模式——即使那些模式是次优的。不加管理,技术债务会指数级累积。
他们的解决方案:
| 策略 | 做法 | 效果 |
|---|---|---|
| 原则编码化 | “优先用共享工具包”、“不要 YOLO 猜数据结构” | 具体、机械、可自动检查 |
| 周期性清理 | 后台任务扫描偏差,开重构 PR | 大多数 1 分钟内自动合并 |
| 品味持续化 | 审查意见 → 文档更新 → 代码规则 | 规则从软约束变硬约束 |
来源:OpenAI: Harness engineering
清洁状态:不只看地上有没有垃圾
清洁状态不是单一的"代码能编译"。代码能无错构建——这是最基本的,下一个会话不应该先修构建错误。就像你搬出去的时候水电不能是断的。所有测试也得通过,包括会话之前就存在的测试——会话有责任不破坏已有功能。而且要在 CI 环境验证,不是"在我机器上通过"。
功能工作已完成 ↓┌─────────────────┐│ 构建通过? │──否──→ 先修好再退出└─────────────────┘ ↓ 是┌─────────────────┐│ 测试通过? │──否──→ 先修好再退出└─────────────────┘ ↓ 是┌─────────────────┐│ 更新功能清单 ││ 清理临时工件 │└─────────────────┘ ↓┌─────────────────┐│ 标准启动可用? │──否──→ 先修好再退出└─────────────────┘ ↓ 是 干净交接 ✓
清洁状态检查清单:
| 条件 | 具体内容 |
|---|---|
| 构建通过 | 代码能无错构建,CI 环境验证 |
| 测试通过 | 所有测试通过,包括已有测试 |
| 进度已记录 | 功能清单更新为机器可读格式 |
| 无过期工件 | 清理调试日志、临时文件、注释代码 |
| 启动路径可用 | 新会话能无人工干预开始工作 |
好的进度记录可减少 60-80% 的会话启动诊断时间。
核心概念
| 概念 | 定义 |
|---|---|
| 清洁状态 | 构建通过 + 测试通过 + 进度记录 + 无过时工件 + 启动路径可用 |
| 会话完整性 | 类比数据库事务——要么全提交,要么回滚,没有中间地带 |
| 质量文档 | 对每个模块质量等级做持续记录的活跃工件 |
| 清理循环 | 定期维护会话,系统性减少代码库熵 |
| harness 简化 | 随模型能力提升,定期移除不再必要的 harness 组件 |
| 幂等清理 | 清理操作执行多少次都产生相同结果 |
"以后再清理"是永远不清理
正反馈循环:
混乱 → 新会话花30分钟诊断 → 在乱上加乱 → 更混乱 ↑___________________________________________↓
12周项目数据对比:
| 周数 | 无清洁策略 | 有清洁策略 |
|---|---|---|
| 构建 / 测试 / 启动时间 | 构建 / 测试 / 启动时间 | |
| 第 1 周 | 100% / 100% / 5min | 100% / 100% / 5min |
| 第 4 周 | 95% / 92% / 15min | 99% / 98% / 6min |
| 第 8 周 | 82% / 78% / 35min | 98% / 97% / 8min |
| 第 12 周 | 68% / 61% / 60+min | 97% / 95% / 9min |
差距:12周后构建通过率差 29%,启动时间差 85%。
实践步骤
5.1 清洁状态是完成的必要条件
会话完成 = 任务通过验证 AND 清洁状态检查通过
## 会话退出检查清单- [ ] 构建通过 (npm run build)- [ ] 所有测试通过 (npm test)- [ ] 功能清单已更新- [ ] 无调试代码残留 (console.log, debugger, TODO)- [ ] 标准启动路径可用 (npm run dev)
``````plaintext
## 会话退出检查清单- [ ] 构建通过 (npm run build)- [ ] 所有测试通过 (npm test)- [ ] 功能清单已更新- [ ] 无调试代码残留 (console.log, debugger, TODO)- [ ] 标准启动路径可用 (npm run dev)
5.2 双模式清理策略
| 模式 | 频率 | 内容 | 类比 |
|---|---|---|---|
| 即时清理 | 每个会话结束时 | 清理临时工件、更新功能清单、确保构建测试通过 | 引用计数式——用完即清 |
| 定期清理 | 每周一次 | 全系统扫描、结构性问题、更新质量文档、基准测试 | 追踪式——定期大扫除 |
5.3 维护质量文档
质量文档是对每个模块持续评分的活跃工件:
# 质量文档## 用户认证模块 (质量: A)- 验证通过: 是- agent 可理解: 是- 测试稳定性: 稳定- 架构边界: 合规- 代码规范: 遵循## 支付模块 (质量: C)- 验证通过: 部分(支付回调未测试)- agent 可理解: 困难(逻辑分散在 3 个文件)- 测试稳定性: 不稳定(2 个 flaky 测试)- 架构边界: 有违规- 代码规范: 部分遵循
新会话读文档就知道优先处理哪里——质量评分最低的模块先修。
5.4 定期简化 harness
harness 组件存在的理由:模型当前无法独立做好某事。但随模型改进,假设会过时。
Anthropic 实验:
- 最初 harness 包含 sprint 拆分机制(为 Sonnet 4.5)
- Opus 4.6 发布后,模型已能自主分解工作,sprint 构造成了不必要开销
- 移除后,builder agent 能连续工作超两小时不跑偏
但 evaluator 不同:即使 Opus 4.6,在任务接近能力边界时,evaluator 仍能捕获遗漏功能和存根实现。是否保留取决于任务难度 vs 模型能力。
推荐做法:每月挑一个 harness 组件,暂时禁用,跑基准任务:
- 结果没退化 → 永久移除
- 结果退化 → 恢复或用更轻量替代
原则:随着模型改进,harness 的有趣组合不是变少,而是移动了。AI 工程师的工作是持续找到下一个有价值的组合。
5.5 清理操作必须幂等
清理脚本要能安全地重复执行:
# 幂等的清理操作rm -f /tmp/debug-*.log # -f 确保文件不存在时不报错git checkout -- .env.local # 恢复到已知状态npm run test # 验证清理未破坏功能
5.6 高吞吐量改变 merge 哲学
当 agent 产出远超人类审查能力时,merge 哲学需要调整:
OpenAI 经验:agent 每天开 3.5+ 个 PR 的环境里,最小化阻塞式 merge gate 是正确的。
- PR 应该短命
- 测试 flake 用后续运行解决,而非无限期阻塞
- 修正成本很低、等待成本很高 → 快速前进 + 快速修正 > 缓慢确认
⚠️ 注意:此策略仅适用于高产出环境。低产出环境里使用是不负责任的。
判断标准:修正 bug 的平均成本 < 等待审查的平均成本 → 快速合并
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献144条内容
已为社区贡献144条内容

所有评论(0)