大语言模型输入流水线:从原始文本到最终嵌入的完整解析
本文深入解析了大语言模型输入的完整处理流程,从原始文本的分词、编码、滑动窗口构造训练样本,到使用DataLoader组织批量数据,再到将token ids转换为词元嵌入和位置嵌入,最终形成模型接收的输入表示。文章强调了输入流水线的稳定性和重要性,指出模型从未直接处理原始文本,而是处理经过严格组织的张量表示。通过理解这一流程,读者可以更好地掌握大语言模型的输入定义,为后续模型训练和开发奠定坚实基础。
背景导语 (Background)
大语言模型并不直接接收原始文本。模型真正处理的,是经过分词、编码、切片与嵌入之后的数值张量。换言之,所谓 “输入文本”,在进入模型计算图之前,已经被改写成一种结构明确、可批量处理、可参与数值运算的表示形式。只要这条输入流水线不稳定,后续训练、评估与推理都难以获得可靠结果。
因此,本章关注的不是所有可能的文本处理方法,而是一条足够清楚、足够稳定、能够直接落地到工程中的主路径:使用 GPT-2 分词器将原始文本编码为 token ids,利用滑动窗口构造语言模型训练所需的输入—目标序列对,借助 DataLoader 组织批次,并进一步将 token ids 转换为词元嵌入与位置嵌入,形成模型实际接收的输入表示。
从实战角度看,这一章的价值并不只是 “把文本切开”。更关键的是,它把后续模型训练所依赖的数据形态定义清楚了:原始文本如何转为离散索引,离散索引如何组织为样本,样本如何批量化,批量张量又如何被映射为连续向量。只有这条链路成立,模型层面的讨论才有坚实基础。
环境说明 (Environment)
建议使用如下环境完成本章实践。
- Python:3.10 及以
- PyTorch:2.0 及以上
- tiktoken:兼容 GPT-2 编码的稳定版本
- 操作系统:Windows、macOS 或 Linux 均可
- 硬件:具备常规开发能力的个人设备即可完成本章样例;若进一步扩大文本规模、上下文长度或批次大小,建议使用 GPU 以提升运行效率
- 文本文件:默认读取
data/raw_data/The-Verdict.txt
本章依赖较少,核心仅包括``pathlib、tiktoken、torch 与 torch.utils.data。这意味着读者不必先搭建复杂的训练框架,就可以直接进入文本输入流水线的核心实现。对于本章而言,重点不在训练大规模模型,而在于把 “原始文本如何被组织成模型输入” 这一过程走通,并且看清其中每一步的数据形态。
适用读者 (Target Audience)
本章适合三类读者。
第一类是已经具备 Python 和 PyTorch 基础,但尚未真正理解 “大语言模型输入到底长什么样” 的读者。对这类读者而言,本章最重要的收获不是记住若干 API,而是建立从原始文本到输入嵌入的完整认知链条。
第二类是正在实现小型语言模型、实验脚本或数据处理组件的开发者。本章提供的不是抽象概念,而是一条能够直接复现、便于扩展的实战路径。
第三类是希望从工程视角理解文本预处理的读者。许多问题并不出在模型主体,而是出在输入端,例如分词器不一致、滑动窗口越界、张量类型错误、设备不匹配或位置嵌入长度不足。本章会把这些问题前置到可控范围内。
导读 (Preface)
本章不从 “文本处理方法史” 展开,也不把重点放在手写分词器或规则设计上,而是围绕一条更贴近当前大语言模型实践的路径组织内容。我们从一份可运行的实现出发,但正文并不逐行解释代码,而是先把问题讲清楚,再让代码作为落地示例去支撑这些问题。
这条主线可以概括为:
原始文本 → token ids → 输入—目标序列对 → 批量张量 → 词元嵌入与位置嵌入 → 最终输入嵌入
整章的写作目标只有一个:让读者在读完之后,不仅知道模型输入需要 “先分词、再嵌入”,而且能够清楚地说出这条流水线中每一步的作用、边界和数据形态。
由于本章被设计为独立章节,因此正文不依赖其他章节的铺垫,也不承担后续章节的过渡任务。它必须依靠自身内部的逻辑闭环成立。
目录 (Table of Contents)
- 引言
- 从原始文本到 token ids
- 使用滑动窗口构造训练样本
- 使用 DataLoader 组织批量数据
- 从 token ids 到输入嵌入
- 完整代码
- 小结
- 引言
文本之所以不能直接输入模型,不是因为它 “不够高级”,而是因为它不满足神经网络计算所要求的数值形式。神经网络擅长处理的是张量,而不是字符串。对模型来说,一段原始文本必须先被离散化、索引化、批量化,再被映射到连续向量空间中,才真正具备进入模型主体的资格。
因此,本章处理的并不是 “文本本身”,而是 “文本进入模型前的全部转换过程”。在这条转换链路中,每一步都很重要,但各自承担的职责并不相同。分词器负责把文本切分成可编码的单位;编码器负责把这些单位映射成整数索引;滑动窗口负责从长序列中提取训练样本;DataLoader 负责将样本组织成批次;嵌入层则负责把离散索引变成连续表示。
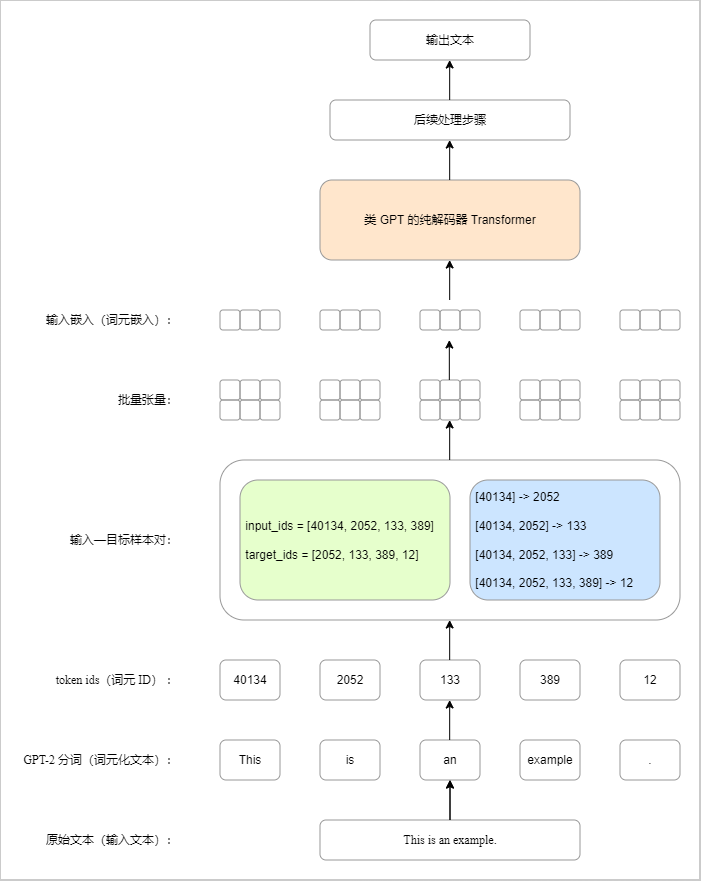
图 1:文本进入语言模型前的输入流水线。 原始文本首先经 GPT-2 分词器编码为 token ids;随后,滑动窗口从连续序列中构造输入序列与右移一位的目标序列;多个样本再由 DataLoader 组织为批量张量;最后,词元嵌入与位置嵌入共同生成模型实际接收的输入嵌入。该流程定义了文本从字符串形式进入神经网络计算图之前的标准表示路径。
这里最重要的一点是,模型从来没有 “看到原文”,它只看到了经过处理之后的张量。因此,理解这一章,实际上是在理解模型输入的真正定义。
- 从原始文本到 token ids
本章采用 GPT-2 分词器作为文本进入模型的第一道入口。这样做的理由并不复杂:它足够成熟、足够常见,而且能够避免把本章的重点拖入大量规则分词的细枝末节之中。
对于当前这一章而言,更重要的问题不是 “所有可能的分词方法有哪些”,而是 “我们如何得到一条稳定的 token id 序列”。一旦这条序列被建立起来,后面的样本构造、批量组织和嵌入计算才有统一的基础。
从实现上看,这一阶段至少包含两个清楚的动作。第一,读取文本文件,并确认路径与编码方式都有效;第二,使用 GPT-2 分词器将整段文本编码为整数序列。这里的整数不是普通数字,而是词表中的索引位置。它们本身不携带语义,但它们为后续嵌入查表提供了唯一入口。
表 1:文本输入流水线中的核心组件、输入输出与职责边界
| 组件 | 典型输入 | 典型输出 | 主要职责 | 对应实现 |
| 文本读取模块 | 文件路径 | 原始文本字符串 | 读取文本并完成路径有效性校验 | read_text_file |
| 分词与编码模块 | 原始文本字符串 | token id 张量 | 使用 GPT-2 分词器完成文本到整数索引的转换 | get_tokenizer 、encode_text_to_token_ids |
| 滑动窗口数据集 | token 序列、max_length、stride |
输入—目标样本对 | 从长序列中构造语言模型训练所需的窗口样本 | GPTSlidingWindowDataset |
| 批量加载模块 | 数据集、批次参数 | 批量张量 | 将样本组织为可直接送入训练循环的批次 | create_dataloader |
| 词元嵌入层 | token id 矩阵 | 词元嵌入张量 | 将离散 token 索引映射为连续向量表示 | create_embedding_layers 中的 token_embedding_layer |
| 位置嵌入层 | 位置索引 | 位置嵌入张量 | 为序列位置注入可训练的位置表示 | create_embedding_layers 中的 position_embedding_layer |
| 输入嵌入构造模块 | token id 矩阵、两类嵌入层 | 最终输入嵌入 | 组合词元嵌入与位置嵌入,形成模型输入 | build_input_embeddings 、create_input_embeddings |
注:表中 “典型输出” 指主要输出形式,不包括异常分支与校验逻辑;张量形状默认采用 batch-first 表示;代码标识符在排版中建议使用等宽字体。
在这一阶段,文本首先被读入内存,再通过 GPT-2 分词器编码为整数索引序列。这里的核心不是 “分词器有多复杂”,而是 “从这一刻开始,原始文本已经被稳定地改写为可计算对象”。后续所有数据集切分、批量加载和嵌入构造,都会建立在这条整数序列之上。
这里也可以用一个最小示例把输入—目标关系先建立起来。假设一段连续 token 序列为:
[40134, 2052, 133, 389, 12]
当上下文长度 context_size = 4 时,窗口级输入—目标样本对就是:
x= [40134, 2052, 133, 389]
y= [2052, 133, 389, 12]
如果进一步按 “给定前文,预测下一个 token” 的方式展开,那么它对应四组逐步预测关系:
[40134] ->2052
[40134, 2052] ->133
[40134, 2052, 133] ->389
[40134, 2052, 133, 389] ->12
这个例子看似简单,却很重要,因为它提前揭示了下一节中滑动窗口样本构造的核心逻辑:目标序列并不是另造的一份新数据,而是输入序列在原始 token 序列上整体右移一位后的结果。
- 使用滑动窗口构造训练样本
把整段文本编码成 token ids 之后,仍然不能直接拿来训练语言模型。语言模型并不是一次性读完整篇文章,而是在一个局部上下文中学习 “下一个 token 应该是什么”。这意味着,我们必须从整条 token 序列中不断提取长度固定的片段,并为每个片段配上对应的目标序列。
滑动窗口正是为此服务的。它的基本思想是:在整段 token 序列上取一个长度为 max_length 的窗口作为输入;然后把这个窗口整体向右平移一个位置,得到对应的目标序列。于是,输入和目标在形式上几乎相同,只是对齐位置不同。
例如,当输入序列为:
[t1, t2, t3, t4]
对应目标序列就是:
[t2, t3, t4, t5]
这种构造方式看似简单,却非常重要,因为它直接把 “预测下一个 token” 变成了一个可训练的监督学习问题。
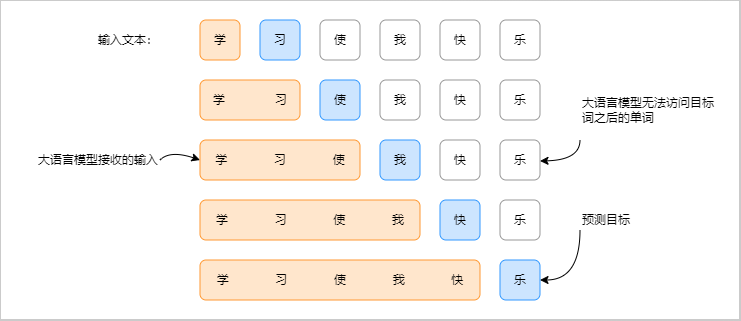
图 2:使用滑动窗口构造语言模型训练样本。 给定一段连续的 token 序列,长度为 max_length 的窗口被用作输入序列;目标序列由同一窗口整体向右偏移一个位置得到。参数 stride 决定相邻样本窗口的位移量,从而影响样本之间的重叠程度和数据利用方式。
在当前实现中,窗口的长度由 max_length 控制,窗口之间的位移由 stride 控制。二者共同决定了样本数量、样本重叠程度和数据利用方式。若 stride 小于 max_length,相邻样本会重叠;若二者相等,则形成非重叠窗口。当前章节示例更强调后者,因为它更容易观察与验证,但这并不意味着它在所有训练场景中都最优。
这一节的关键,不是记住切片细节,而是理解:语言模型训练样本本质上来自同一条长序列的局部对齐切片。输入与目标不是两份不同数据,而是同一份数据在时间上错开一个位置的两种视图。
- 使用 DataLoader 生成训练批次
有了输入—目标样本对之后,下一步并不是马上进入模型,而是要把这些样本组织成适合批量计算的形式。DataLoader 的作用,正是在数据集和训练循环之间建立这一层稳定接口。
从概念上说,DataLoader 解决的是三个问题。第一,如何把样本按批次输出;第二,是否要在每个 epoch 开始时打乱样本顺序;第三,是否要丢弃最后一个不足整批的批次。对于当前这一章而言,这些问题的重要性并不在于 “调到哪组参数最好”,而在于让读者看到,训练循环真正接收的数据已经不再是一条一维 token 序列,而是两个形状一致的二维张量。
也就是说,在这一阶段,输入和目标通常都会被组织成如下形状:
[batch_size, context_length]
其中每一行是一个独立样本,每一列对应窗口中的一个位置。到这里为止,模型接收的仍然只是整数索引,而不是向量。
从实战角度看,这一层还承担一个常被忽视的职责:提前暴露输入异常。如果文本太短,以至于无法构造任何训练样本,那么最合理的行为不是让训练阶段静默失败,而是在 DataLoader 构造阶段明确报错。这种处理方式会显著提升代码的可调试性,也更符合工程实现的边界控制原则。
如果沿用当前代码中的默认设置,即 batch_size = 8、context_length = 4,那么从 DataLoader 取出的一个批次,其输入与目标张量形状都会是:
torch.Size([8, 4])
这意味着一个批次包含 8 个样本,每个样本由长度为 4 的连续 token 序列构成。这里得到的是批量化的离散索引表示。它已经适合送入后续流水线,但还不是模型最终接收的连续向量输入。
- 从 token ids 到输入嵌入
token ids 仍然只是离散索引。要让模型真正开始计算,还必须经过嵌入层,把这些整数映射为连续向量。对大语言模型而言,这一步至少包括两部分:词元嵌入和位置嵌入。
词元嵌入回答 “当前 token 是什么”。它本质上是一张可训练的查找表:每个 token id 对应词表中的一行向量。位置嵌入回答 “当前 token 位于什么位置”。它同样是一张查找表,只不过查找键不再是 token id,而是序列中的位置索引。
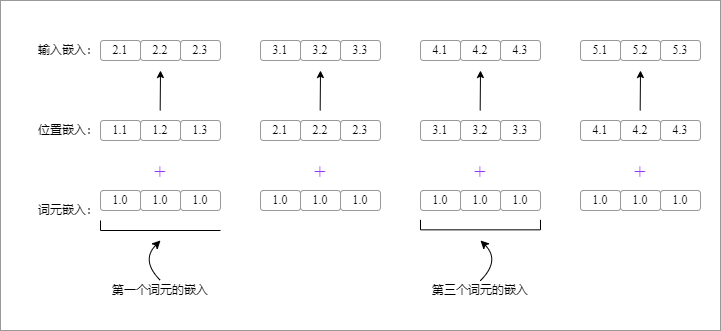
图 3 词元嵌入与位置嵌入的构成关系。 输入的 token ids 先经词元嵌入层映射为词元嵌入张量;位置索引经位置嵌入层映射为位置嵌入张量;位置嵌入在 batch 维上广播后,与词元嵌入逐元素相加,得到最终输入嵌入。该输入嵌入同时编码了 “当前 token 是什么” 和 “当前 token 位于什么位置” 两类信息。
在当前实现中,位置索引始终是从 0 到 context_length - 1 的连续整数序列。它们先被送入位置嵌入层,得到一组位置向量;随后与词元嵌入逐元素相加。这样做的含义很明确:同一个 token 在不同位置上,应当拥有不同的最终输入表示,因为模型不仅需要知道 “它是什么”,还需要知道 “它出现在什么位置”。
这里有一个非常重要的形状关系。词元嵌入的形状通常是:
[batch_size, context_length, embedding_dim]
位置嵌入的原始形状通常是:
[context_length, embedding_dim]
在加入 batch 维后,它会沿样本维度自动广播,从而与整个批次中的词元嵌入相加。最终输入嵌入的形状仍然是:
[batch_size, context_length, embedding_dim]
按照当前代码的默认设置,batch_size = 8,context_length = 4,embedding_dim = 256。因此,三个关键张量的典型形状为:
token_embeddings.shape == torch.Size([8, 4, 256])
position_embeddings.shape == torch.Size([1, 4, 256])
input_embeddings.shape == torch.Size([8, 4, 256])
这一步完成之后,模型才真正拿到了可以处理的连续向量表示。到这里,本章的输入流水线已经完整闭合:文本被切分、编码、切片、批量化,并最终变成了可送入模型主体的张量。
- 完整代码
下面给出本章对应的完整实现代码。正文部分已经说明了各组件在输入流水线中的职责,因此这里不再逐行展开,而是将代码作为本章主路径的可运行实现统一给出。下面的版本与您当前代码保持相同逻辑,仅将少量文档字符串与注释口径统一为本章行文风格。
# -*- coding: utf-8 -*-
"""
处理文本数据
功能
----
1. 使用 GPT-2 分词器将原始文本转换为 token ids。
2. 使用滑动窗口构造语言模型训练所需的输入-目标序列对。
3. 使用 DataLoader 批量生成训练批次。
4. 演示如何将 token ids 转换为词元嵌入与位置嵌入。
设计说明
--------
- 本文件主要用于教学演示,因此优先强调流程清晰与结构简洁。
- 在不大幅调整原有逻辑的前提下,补强如下能力:
1) 顶层常量统一管理;
2) 数据集与演示代码职责分离;
3) 参数校验更明确;
4) 命名、注释与类型标注更统一;
5) 避免在导入模块时直接执行演示逻辑;
6) 将嵌入层创建与输入嵌入构造解耦,便于教学说明;
7) 在关键流程处补充正确、清晰、专业、精炼的代码注释。
Author
------
Aiden Cao <zhinengmahua@gmail.com>
Date: 2025-12-29
"""
from __future__ import annotations
from pathlib import Path
import tiktoken
import torch
from torch import Tensor, nn
from torch.utils.data import DataLoader, Dataset
PROJECT_ROOT = Path(__file__).resolve().parents[3]
DATA_ROOT = PROJECT_ROOT / "data"
RAW_DATA_ROOT = DATA_ROOT / "raw_data"
# 默认演示文本文件。
DEFAULT_TEXT_FILE_PATH = RAW_DATA_ROOT / "The-Verdict.txt"
# 默认分词与嵌入配置。
DEFAULT_ENCODING_NAME = "gpt2"
GPT2_VOCAB_SIZE = 50257
DEFAULT_EMBEDDING_DIM = 256
DEFAULT_CONTEXT_LENGTH = 4
DEFAULT_BATCH_SIZE = 8
# nn.Embedding 支持整数索引;教学示例中统一接受 int32 / int64。
EMBEDDING_INDEX_DTYPES = (torch.int32, torch.int64)
def validate_positive_int(value: int, name: str) -> None:
"""
:param value: 待校验的整数值
:param name: 参数名称
:return: None
"""
# bool 是 int 的子类;这里显式排除,避免 True / False 误通过。
if isinstance(value, bool) or not isinstance(value, int):
raise TypeError(f"{name} 必须是 int 类型。")
if value <= 0:
raise ValueError(f"{name} 必须大于 0。")
def validate_non_negative_int(value: int, name: str) -> None:
"""
:param value: 待校验的整数值
:param name: 参数名称
:return: None
"""
if isinstance(value, bool) or not isinstance(value, int):
raise TypeError(f"{name} 必须是 int 类型。")
if value < 0:
raise ValueError(f"{name} 不能小于 0。")
def validate_non_empty_string(value: str, name: str) -> None:
"""
:param value: 待校验的字符串
:param name: 参数名称
:return: None
"""
if not isinstance(value, str):
raise TypeError(f"{name} 必须是 str 类型。")
if not value.strip():
raise ValueError(f"{name} 不能为空字符串。")
def validate_token_id_matrix(input_token_ids: Tensor, name: str = "input_token_ids") -> None:
"""
:param input_token_ids: 待校验的 token id 张量
:param name: 参数名称
:return: None
"""
if input_token_ids.ndim != 2:
raise ValueError(f"{name} 必须是二维张量,形状应为 [batch_size, context_length]。")
# Embedding 查表要求输入为整数索引。
if input_token_ids.dtype not in EMBEDDING_INDEX_DTYPES:
raise TypeError(f"{name} 必须是整型张量,推荐使用 torch.long。")
def get_tokenizer(encoding_name: str = DEFAULT_ENCODING_NAME) -> tiktoken.Encoding:
"""
:param encoding_name: tiktoken 编码器名称
:return: 对应的分词器对象
"""
validate_non_empty_string(encoding_name, "encoding_name")
return tiktoken.get_encoding(encoding_name)
def read_text_file(file_path: str | Path) -> str:
"""
:param file_path: 文本文件路径
:return: 读取到的完整文本内容
"""
path = Path(file_path)
if not path.exists():
raise FileNotFoundError(f"文件不存在:{path}")
if not path.is_file():
raise FileNotFoundError(f"路径不是有效文件:{path}")
return path.read_text(encoding="utf-8")
def encode_text_to_token_ids(text: str, tokenizer: tiktoken.Encoding) -> Tensor:
"""
:param text: 原始文本
:param tokenizer: 用于分词的编码器
:return: torch.long 类型的 token id 张量
"""
validate_non_empty_string(text, "text")
# 分词器先输出 Python 整数列表,再显式转换为 PyTorch 长整型张量,
# 以便后续直接送入 nn.Embedding 做索引查表。
token_ids = tokenizer.encode(text)
return torch.tensor(token_ids, dtype=torch.long)
class GPTSlidingWindowDataset(Dataset):
"""
基于滑动窗口的 GPT 训练数据集。
功能说明
--------
给定一段完整文本,先使用分词器将其转换为 token ids,
然后通过滑动窗口构造:
- input_ids: 当前窗口中的 token 序列
- target_ids: 相对 input_ids 向右偏移一位的目标序列
例如:
input_ids = [t1, t2, t3, t4]
target_ids = [t2, t3, t4, t5]
"""
def __init__(
self,
text: str,
tokenizer: tiktoken.Encoding,
max_length: int,
stride: int,
) -> None:
"""
:param text: 原始文本
:param tokenizer: 用于分词的编码器
:param max_length: 每个样本窗口的最大长度
:param stride: 滑动窗口步长
:return: None
"""
validate_positive_int(max_length, "max_length")
validate_positive_int(stride, "stride")
self.max_length = max_length
self.stride = stride
# 整段文本只分词一次;后续样本在 __getitem__ 中按窗口延迟切片,
# 可避免预先复制大量重叠子序列。
self.token_ids = encode_text_to_token_ids(text=text, tokenizer=tokenizer)
# 每个起始位置对应一个训练样本窗口。
self.sample_start_positions = self._build_sample_start_positions(
token_count=int(self.token_ids.numel()),
max_length=max_length,
stride=stride,
)
@staticmethod
def _build_sample_start_positions(
token_count: int,
max_length: int,
stride: int,
) -> list[int]:
"""
:param token_count: 文本分词后的 token 总数
:param max_length: 每个样本窗口的最大长度
:param stride: 滑动窗口步长
:return: 所有样本窗口起始位置列表
"""
# 构造一组 input_ids 和对应的右移 target_ids,
# 至少需要 max_length + 1 个 token。
if token_count <= max_length:
return []
# range 的右边界是排他的;这里刚好保证 target_ids 的最后一个位置仍然有效。
last_start_exclusive = token_count - max_length
return list(range(0, last_start_exclusive, stride))
def __len__(self) -> int:
"""
:return: 数据集样本数量
"""
return len(self.sample_start_positions)
def __getitem__(self, index: int) -> tuple[Tensor, Tensor]:
"""
:param index: 样本索引
:return: 指定位置的 input_ids 与 target_ids
"""
start = self.sample_start_positions[index]
end = start + self.max_length
# 输入序列使用当前窗口;目标序列整体右移一位,
# 对应“给定当前 token 预测下一个 token”的训练目标。
input_ids = self.token_ids[start:end]
target_ids = self.token_ids[start + 1:end + 1]
return input_ids, target_ids
# 兼容旧名称,尽量减少外部调用修改成本。
GPTDataset = GPTSlidingWindowDataset
def create_dataloader(
text: str,
batch_size: int = 4,
max_length: int = 256,
stride: int = 128,
shuffle: bool = True,
drop_last: bool = True,
num_workers: int = 0,
encoding_name: str = DEFAULT_ENCODING_NAME,
tokenizer: tiktoken.Encoding | None = None,
) -> DataLoader:
"""
用于批量生成输入-目标对的数据加载器。
:param text: 原始文本
:param batch_size: 批次大小
:param max_length: 每个样本窗口的最大长度
:param stride: 滑动窗口步长
:param shuffle: 是否在每个 epoch 开始时打乱样本顺序
:param drop_last: 是否丢弃最后一个不足 batch_size 的批次
:param num_workers: DataLoader 使用的工作进程数
:param encoding_name: tiktoken 编码器名称
:param tokenizer: 可选的外部分词器;为空时内部自动创建
:return: 构造完成的 DataLoader
"""
validate_non_empty_string(text, "text")
validate_positive_int(batch_size, "batch_size")
validate_positive_int(max_length, "max_length")
validate_positive_int(stride, "stride")
validate_non_negative_int(num_workers, "num_workers")
# 优先复用外部分词器,便于在教学或实验中保持编码器一致。
active_tokenizer = tokenizer if tokenizer is not None else get_tokenizer(encoding_name)
dataset = GPTSlidingWindowDataset(
text=text,
tokenizer=active_tokenizer,
max_length=max_length,
stride=stride,
)
if len(dataset) == 0:
raise ValueError("无法构造任何训练样本。请检查文本长度,并确保 token 数至少大于 max_length。")
return DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers,
)
def create_embedding_layers(
vocab_size: int,
embedding_dim: int,
context_length: int,
device: torch.device | None = None,
) -> tuple[nn.Embedding, nn.Embedding]:
"""
创建词元嵌入层与位置嵌入层。
:param vocab_size: 词表大小
:param embedding_dim: 嵌入维度
:param context_length: 上下文长度
:param device: 嵌入层所在设备
:return: 词元嵌入层与位置嵌入层
"""
validate_positive_int(vocab_size, "vocab_size")
validate_positive_int(embedding_dim, "embedding_dim")
validate_positive_int(context_length, "context_length")
# 词元嵌入层负责“token id -> 词向量”;
# 位置嵌入层负责“位置索引 -> 位置向量”。
token_embedding_layer = nn.Embedding(vocab_size, embedding_dim)
position_embedding_layer = nn.Embedding(context_length, embedding_dim)
if device is not None:
token_embedding_layer = token_embedding_layer.to(device)
position_embedding_layer = position_embedding_layer.to(device)
return token_embedding_layer, position_embedding_layer
def build_input_embeddings(
input_token_ids: Tensor,
token_embedding_layer: nn.Embedding,
position_embedding_layer: nn.Embedding,
) -> tuple[Tensor, Tensor, Tensor]:
"""
根据输入 token ids 和嵌入层构造词元嵌入、位置嵌入和最终输入嵌入。
:param input_token_ids: 输入 token ids,形状为 [batch_size, context_length]
:param token_embedding_layer: 词元嵌入层
:param position_embedding_layer: 位置嵌入层
:return: token_embeddings、position_embeddings、input_embeddings
"""
validate_token_id_matrix(input_token_ids, "input_token_ids")
embedding_device = token_embedding_layer.weight.device
if position_embedding_layer.weight.device != embedding_device:
raise ValueError("token_embedding_layer 与 position_embedding_layer 必须位于同一设备。")
# 将输入索引移动到嵌入层所在设备,避免设备不一致导致运行错误。
input_token_ids = input_token_ids.to(embedding_device)
context_length = int(input_token_ids.size(1))
if position_embedding_layer.num_embeddings < context_length:
raise ValueError("位置嵌入层的 num_embeddings 小于当前输入的 context_length,无法完成位置编码。")
# 位置索引始终是 [0, 1, ..., context_length - 1]。
position_indices = torch.arange(
context_length,
dtype=torch.long,
device=embedding_device,
)
# token_embeddings 形状: [batch_size, context_length, embedding_dim]
token_embeddings = token_embedding_layer(input_token_ids)
# position_embeddings 原始形状: [context_length, embedding_dim]
# unsqueeze(0) 后变为 [1, context_length, embedding_dim],
# 之后与 token_embeddings 相加时会沿 batch 维自动广播。
position_embeddings = position_embedding_layer(position_indices).unsqueeze(0)
# 最终输入嵌入 = 词元嵌入 + 位置嵌入
input_embeddings = token_embeddings + position_embeddings
return token_embeddings, position_embeddings, input_embeddings
def create_input_embeddings(
input_token_ids: Tensor,
vocab_size: int,
embedding_dim: int,
) -> tuple[Tensor, Tensor, Tensor]:
"""
兼容式封装:根据输入 token ids 直接创建嵌入层并生成输入嵌入。
:param input_token_ids: 输入 token ids,形状为 [batch_size, context_length]
:param vocab_size: 词表大小
:param embedding_dim: 嵌入维度
:return: token_embeddings、position_embeddings、input_embeddings
"""
validate_token_id_matrix(input_token_ids, "input_token_ids")
context_length = int(input_token_ids.size(1))
device = input_token_ids.device
token_embedding_layer, position_embedding_layer = create_embedding_layers(
vocab_size=vocab_size,
embedding_dim=embedding_dim,
context_length=context_length,
device=device,
)
return build_input_embeddings(
input_token_ids=input_token_ids,
token_embedding_layer=token_embedding_layer,
position_embedding_layer=position_embedding_layer,
)
def main() -> None:
"""
:return: None
"""
# 1. 读取原始文本。
raw_text = read_text_file(DEFAULT_TEXT_FILE_PATH)
# 2. 构造 DataLoader。
# 此处将 stride 设置为 context_length,便于演示“非重叠窗口”的基本效果。
# 同时关闭 shuffle,便于直接观察窗口切分后的顺序结果。
context_length = DEFAULT_CONTEXT_LENGTH
dataloader = create_dataloader(
text=raw_text,
batch_size=DEFAULT_BATCH_SIZE,
max_length=context_length,
stride=context_length,
shuffle=False,
drop_last=False,
)
# 3. 获取一个批次的输入-目标样本。
input_token_ids, target_token_ids = next(iter(dataloader))
print("Input token IDs:\n", input_token_ids)
print("\nTarget token IDs:\n", target_token_ids)
print("\nInputs shape:\n", input_token_ids.shape)
print("Targets shape:\n", target_token_ids.shape)
# 4. 创建词元嵌入层与位置嵌入层。
token_embedding_layer, position_embedding_layer = create_embedding_layers(
vocab_size=GPT2_VOCAB_SIZE,
embedding_dim=DEFAULT_EMBEDDING_DIM,
context_length=context_length,
device=input_token_ids.device,
)
# 5. 将 token ids 转换为词元嵌入、位置嵌入和最终输入嵌入。
token_embeddings, position_embeddings, input_embeddings = build_input_embeddings(
input_token_ids=input_token_ids,
token_embedding_layer=token_embedding_layer,
position_embedding_layer=position_embedding_layer,
)
print("\nToken embeddings shape:\n", token_embeddings.shape)
print("Position embeddings shape:\n", position_embeddings.shape)
print("Input embeddings shape:\n", input_embeddings.shape)
if __name__ == "__main__":
main()
从正文角度看,这份代码的价值不在于 “写法新”,而在于它把一条输入流水线拆成了几个职责清楚的组件:文本读取、分词编码、窗口数据集、批量加载、嵌入层构造与输入嵌入生成。对于一本实战型技术书而言,这种拆分比单纯把逻辑堆在一个脚本里更有价值,因为它更接近真实工程中可扩展、可调试、可复用的组织方式。
- 小结
本章完成了一条完整且可运行的文本输入流水线。原始文本先被读取并编码为 GPT-2 token ids,再通过滑动窗口构造为输入—目标样本对,随后由 DataLoader 组织成批量张量,最后通过词元嵌入与位置嵌入生成模型真正接收的输入嵌入。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)