腾讯work buddy近万字实测:开发一套抖音短视频解析工具(附踩坑实录)
写在前面:这不是一篇"AI有多厉害"的成功学文章,而是一个真实记录——记录一个不懂代码的产品经理,怎么一步步把脑子里的想法变成线上跑着的系统,中间踩了哪些坑,又是怎么爬出来的。(底部有工具成果展示)
先交代一下背景
做这个系统的起因很简单:我发现市面上的舆情分析工具要么太贵,要么太难用,要么数据不准。我想做一个自己的工具,能采集抖音视频的评论、做情感分析、挖掘意向客户——而且要免费、简单、普通人也能用。
我的技能栈是这样的:
- ✅ 会写产品文档
- ✅ 会画原型图
- ✅ 懂业务流程
- ❌ 不会写代码
- ❌ 不会部署服务器
- ❌ 不会数据库
说白了,就是那种"需求评审时说得头头是道,真要自己动手就只能干瞪眼"的产品。
我之前用过扣子coze,后来都在说养虾养虾,于是我尝试使用腾讯 WorkBuddy 这个 AI 工具,试着用它来帮我写代码、搭系统。于是就有了以下的故事。
今天这篇文章,就把我这半个月来的完整经历记录下来,不吹不黑,有坑说坑。
首先说下踩坑细节
第一个坑:需求想清楚了,但不知道从哪开始写代码
1 那个最难的起步阶段
我到现在都记得第一天的状态:脑子里有一堆功能点,什么评论采集、情感分析、词云生成、PDF导出……但面对一个空白的代码编辑器,完全不知道从哪下手。
后来我想明白了:我不需要知道代码怎么写,我需要知道我要什么。
2 把需求拆解成"人类能说清楚的话"
我犯的第一个错误,就是把AI当成搜索引擎来用——直接问"怎么做评论采集",然后把答案复制过来。
结果当然不行。
正确的做法是:把自己的业务逻辑先理清楚,然后用自然语言描述给AI听。
举个例子,我想做"评论采集"功能,我给AI的描述是这样的:
我需要一个功能:用户输入一个抖音视频链接,系统自动采集这个视频的评论数据。
采集的字段包括:评论内容、用户昵称、点赞数、回复数、评论时间、IP属地。
采集完成后,支持导出为Excel文件。
评论数量至少采集400条。
你看,这段话没有任何技术术语,但任何一个程序员看完都知道要做什么。
第二个坑:前端和后端的数据字段对不上
1 症状:页面显示空白,但后端明明有数据
系统做了一段时间后,遇到了一个很奇怪的问题:
评论分析的结果,后端接口明明返回了数据,但前端页面愣是不显示。控制台也没有报错,就是一片空白。
我一开始以为是前端代码有问题,让AI帮我review了一遍,结果发现逻辑没问题。
后来才找到原因:前端请求用的字段名,和后端返回的字段名对不上。
举个例子,后端返回的是:
{
"task_id": "123456",
"detail_id": "789",
"video_title": "这是一个视频标题"
}
但前端代码里写的是:
const taskId = selectedTask.latest_task_id; // 这里用的是 latest_task_id
const detailId = selectedTask.detail_id;
问题就出在这里:latest_task_id 这个字段根本不存在!后端返回的是 task_id,不是 latest_task_id。
2 解决思路:建立字段对照表
吃了几次亏之后,我学会了一个方法——每次对接新接口之前,先跟AI确认字段名。
我会让AI帮我生成一个字段对照表:
| 后端返回字段 | 前端使用字段 | 备注 |
|---|---|---|
| task_id | id | 任务ID |
| detail_id | detail_id | 视频ID |
| latest_task_id | ❌ 不存在,删掉 | 这个字段是前端自己臆想的 |
3 教训总结
这个坑教会我一件事:AI写代码很厉害,但它不会帮你校验业务逻辑。
字段名对不上,不是AI的问题,而是我自己在设计接口时没有文档化、或者文档没有同步给AI。所以后来我养成了一个习惯:每次接口设计完,就让AI帮我生成一份接口文档,然后存到项目文档里。
第三个坑:LLM返回的JSON被截断了
1 症状:分析结果只有一半
做评论分析功能时,需要把大量评论数据发给大模型处理,然后让模型返回一个结构化的分析结果。
一开始很顺利,但后来评论数量多了之后,开始出现奇怪的问题:分析结果总是只有一半,后面一半就没了。
查日志发现,错误信息是:
Unterminated string starting at...
JSON parse error
意思是:LLM返回的JSON文本被截断了,不完整,导致无法解析。
2 排查过程
我以为是网络问题,让AI帮我加超时重试。结果没用,该截断还是截断。
后来仔细看了一下返回的内容,发现规律:每次截断的位置都差不多,大概在第2000个token左右。
这才反应过来:LLM单次返回的内容长度是有限制的。
3 解决方案:分批处理 + 智能修复
我让AI帮我实现了两个策略:
策略一:分批处理
把大量评论分成多个小批次(比如每批50条),分别发给LLM分析,最后合并结果。
策略二:智能修复被截断的JSON
即使分批处理,偶尔还是会出现截断问题。所以我让AI写了一个 fix_incomplete_json() 函数,能自动检测并修复不完整的JSON:
- 检查末尾是否有未闭合的字符串
- 智能补全缺失的括号
- 通过正则提取完整的JSON对象
这样双重保障,成功率大大提升。
第四个坑:差评被误判为情感共鸣
1 症状:同情评论被当成负面评论
做情感分析功能时,我发现一个很离谱的问题:有些明显是"共情"或"心疼"的评论,被错误地归类成了"负面评论"。
举个例子:
- “我是流泪看完了…可惜了这个孩子” → 被判为负面(实际是惋惜+同情)
- “全程泪流满面…真心疼你” → 被判为负面(实际是心疼+共情)
- “希望大家不要再骂她了” → 被判为负面(实际是呼吁理解)
这些评论虽然包含"可惜"、"难"这样的负面词,但整体语境是理解和同情,不应该被归为差评。
2 原因分析
问题出在prompt的设计上。
一开始的prompt很简单,就是让LLM判断"这条评论是正面的还是负面的"。但LLM做判断时,只看关键词,不看语境。
“可惜”=“负面”,“难”=“负面”——它不懂"可惜"放在"可惜了这个孩子"这句话里,其实是心疼的意思。
3 解决方案:详细规则 + 示例
我让AI帮我重新设计了prompt,加了三层保障:
第一层:添加情感共鸣排除规则
以下情况应排除(不归入负面):
- 表达同情、心疼、感动、理解
- 对人物现状的惋惜和关心
- 使用亲昵称呼("宝贝"、"孩子")
- 结构:描述困难 + 表达心疼
第二层:提供15个真实评论示例
每个示例都标注了"应该排除"或"应该归类为负面",让LLM学习判断标准。
第三层:强调语境优先于关键词
重要判断原则:
"即使包含负面词(如'可惜'、'抑郁'),但如果整体语境是同情理解,也应排除为情感共鸣,而非负面评论。"
改完prompt之后,准确率明显提升。
第五个坑:退出登录后页面不跳转
1 症状:点完"退出登录",还停留在个人中心
这个问题不大,但体验很差。
用户点了"退出登录"按钮,弹出提示"已登出",但页面还停留在个人中心页面,没有返回首页。
对于用户来说,这就会产生困惑——“我到底登出了没有?”
2 排查过程
我先问了AI:“退出登录的逻辑在哪?”
AI告诉我,退出登录的代码在 authContext.ts 里:
const logout = () => {
setUser(null);
setIsLoggedIn(false);
localStorage.removeItem('authUser');
};
看代码逻辑,logout 函数只做了清空用户状态和本地缓存的操作,没有任何页面跳转的逻辑。
3 解决:加一行跳转
我让AI帮我在 logout 函数里加了一句:
const logout = () => {
setUser(null);
setIsLoggedIn(false);
localStorage.removeItem('authUser');
// 退出登录后跳转到视频下载页
window.location.hash = '#/video';
};
就这一行,问题解决。
第六个坑:波峰检测阈值过低,产生伪波峰
1 症状:热度分析显示很多"波峰",但每个只有2-4条评论
做视频热度分析时,有一个"波峰检测"功能,目的是找出视频发布后哪些时间段热度最高。
但我发现一个问题:检测出来的"波峰"太多了,而且每个波峰只有2-4条评论。按照常识,一条视频的热度波峰,怎么可能只有几条评论?
2 原因分析
看了代码才发现,检测逻辑里没有设置最低评论数阈值。任何连续的时间段都会被判定为"波峰",哪怕只有2条评论。
这在数据量少的情况下,会产生大量"伪波峰"——不是真正的热度高峰,只是统计噪音。
3 解决方案:设置最低评论数阈值
我让AI帮我在波峰检测逻辑里加了一个参数 min_peak_comments = 10:
def detect_heat_peaks(self, comments, min_peak_comments=10):
# 只有评论数>=10的时间段,才被认为是有效波峰
...
这样,只有评论数量达到一定规模的时段,才会被标记为波峰。结果更加真实可信。
第七个坑:Prompt里的中文字段名导致判断失效
1 症状:某些分析维度总是返回空结果
做多维度评论分析时,我设计了一个分析选项列表,包含:情感分析、热点关键词、主题聚类、差评定位、意向客户挖掘……
用户勾选了某个分析维度后,系统应该只返回对应的分析结果。
但我发现:意向客户挖掘功能总是返回空结果,明明有评论数据。
2 排查过程
我让AI帮我review了分析逻辑,发现问题出在一个很离谱的地方:
代码里用的是中文字段名做判断条件,但实际变量是英文字段名。
# 判断用户是否选择了"意向客户"分析
if "意向客户" in required_fields: # ❌ 这里永远为False
result["intent_customers"] = ...
问题在于:required_fields 里存的是英文,比如 "intent_customers",但判断条件写的是中文 "意向客户",所以这个判断永远不成立,intent_customers 就永远不会被计算。
3 教训:前后端字段命名要统一规范
这个问题本质上不是AI的错,而是我在设计接口规范时,没有明确规定"字段命名用中文还是英文"。
后来我统一了规范:代码内部统一用英文,接口文档统一标注中英文对照。
第八个坑:登录弹框的文案把用户吓跑了
1 症状:网站每天有十几个人访问,但只用视频下载功能
系统上线一段时间后,我发现一个很尴尬的数据:
- 每天访问量:10-15人
- 使用视频下载的:100%
- 使用其他功能(评论分析、舆情监测)的:0%
也就是说,所有用户来了都只用一个功能,其他功能压根没人用。
2 排查:登录弹框里有个"威胁文案"
后来我发现,问题出在登录弹框里的一句话:
“近日有多人通过技术手段过载暴力使用网站功能。为避免此类情况,即日起需用户登录。敬请谅解!”
这段话的本意是解释为什么要登录,但实际上传递了一个信号:“我们网站被搞怕了,所以要限制你。”
这谁还想用啊?
3 解决方案:换成"利益导向"的文案
我把这段话删掉,换成了注册后的好处展示:
🎁 注册即享永久福利
✅ 视频无水印高清下载 - 永久免费
✅ 抖音热榜查看 - 永久免费
✅ 舆情监测AI分析 - 赠送额度
(评论采集下载+评论多维度分析+视频热度分析)
从"威胁"变成"利益",转化效果会好很多。
说真的,WorkBuddy 在这些地方帮了我大忙
光说踩坑不公平,也得聊聊 WorkBuddy 真正帮到我的几个地方。
第一次做"甩手掌柜":让它直接帮我建项目结构
最让我惊讶的是,有一次我只是跟 WorkBuddy 说了一句话:
“帮我把评论分析功能重构一下,代码在舆情洞察后端完整程序.py这个文件里。”
然后它就真的去读了这个文件,分析了代码结构,然后给出了重构方案。我确认之后,它一次性改了6个函数,改完还没报错。
你知道这对一个不会写代码的人来说意味着什么吗?
我不用知道那个文件里有多少行代码、哪个函数调用了哪个函数。 我只需要说清楚"我要什么",WorkBuddy 就会自己去读代码、理解代码、然后改代码。
这种感觉,就像有个程序员在你旁边随时待命,你说需求他写代码,你审核结果他再改。
跨文件搜索,比我翻IDE还快
有一次我遇到一个问题:有个变量名写错了,导致前端页面显示不出来。
如果是以前的我,估计得在 VSCode 里 Ctrl+F 一个一个找。但它的搜索功能直接可以搜整个代码库:
“帮我找一下哪里用了
latest_task_id这个字段”
它秒级就列出了所有引用这个字段的文件和位置,还标注了每个位置的具体上下文。
对于不会用代码的普通人来说,这个功能简直是救星。
遇到报错不再慌:它能帮我读日志
之前后端出了个bug,日志报错:
JSON parse error at position 1234
老实说,我看不懂这啥意思。但它能看懂。它帮我分析日志,定位到问题出在 LLM 返回的 JSON 被截断了,然后还帮我写了修复函数。
以前遇到报错,只能去百度搜、去看技术论坛。现在只需要把日志直接丢给它,它就能帮我分析原因。
代码写完自动检查,不用担心低级错误
它有一个 read_lints 功能,会在每次修改代码后自动检查语法错误。
有一次我让它帮我改了一个登录逻辑,改完之后它立刻提示:“有语法错误,第XX行少了一个分号”。
如果没有这个检查,我可能会把有bug的代码部署上去,然后花一整晚去debug一个低级错误。
10.6 多轮迭代,把代码改到满意为止
以前找程序员帮忙,有个很大的问题:人家有自己的工作节奏,你催太紧他不耐烦,你等太久你着急。
用它不一样。我想加个功能,跟它说;它给了第一版,我觉得某处不够好,跟它说"这里再优化一下";它改完我再提意见……来回几轮,直到我满意为止。
这个过程完全没有心理负担。 提需求不用看脸色,改错了可以回退,不用担心"问太多会不会显得我很烦"。
关于开发过程中的几个心得
AI工具适合做的事
根据这两个月的经验,我觉得AI工具最擅长的是:
| 场景 | 适合度 | 说明 |
|---|---|---|
| 写重复性代码 | ⭐⭐⭐⭐⭐ | 比如CRUD、数据校验,AI写得又快又好 |
| 代码review | ⭐⭐⭐⭐⭐ | AI能快速发现逻辑漏洞和潜在bug |
| 写技术文档 | ⭐⭐⭐⭐ | 接口文档、README,AI写得比我还规范 |
| 从0到1搭框架 | ⭐⭐⭐⭐ | 帮我想清楚项目结构,节省大量时间 |
| 解决陌生领域问题 | ⭐⭐⭐ | 搜索引擎+AI,比单独用搜索引擎效率高 |
AI工具不太适合做的事
| 场景 | 困难度 | 说明 |
|---|---|---|
| 理解模糊需求 | ⭐⭐⭐⭐⭐ | 需求没说清楚,AI就给不出正确答案 |
| 处理业务边界case | ⭐⭐⭐⭐ | 需要人拍板,这个AI替不了 |
| 保证数据准确性 | ⭐⭐⭐⭐ | AI可能一本正经地胡说八道,需要人工校验 |
| 创意类工作 | ⭐⭐⭐ | 给方向可以,直接出方案还是差点意思 |
最重要的一个心得
用AI工具的核心能力,不是写代码,而是"说清楚需求"。
我发现,同样一个问题,我用模糊的语言描述,AI给我的答案总是差点意思;但当我认认真真把业务逻辑、前提条件、预期结果都写清楚,AI的输出质量会高很多。
所以,我现在养成了一个习惯:每次跟AI沟通之前,先在脑子里或者纸上把自己的需求捋一遍,确保没有逻辑漏洞。
成果展示
经过半个月的浴血奋战,已经出具规模了,我给这个网站起名叫Umind酉脑短视频解析平台。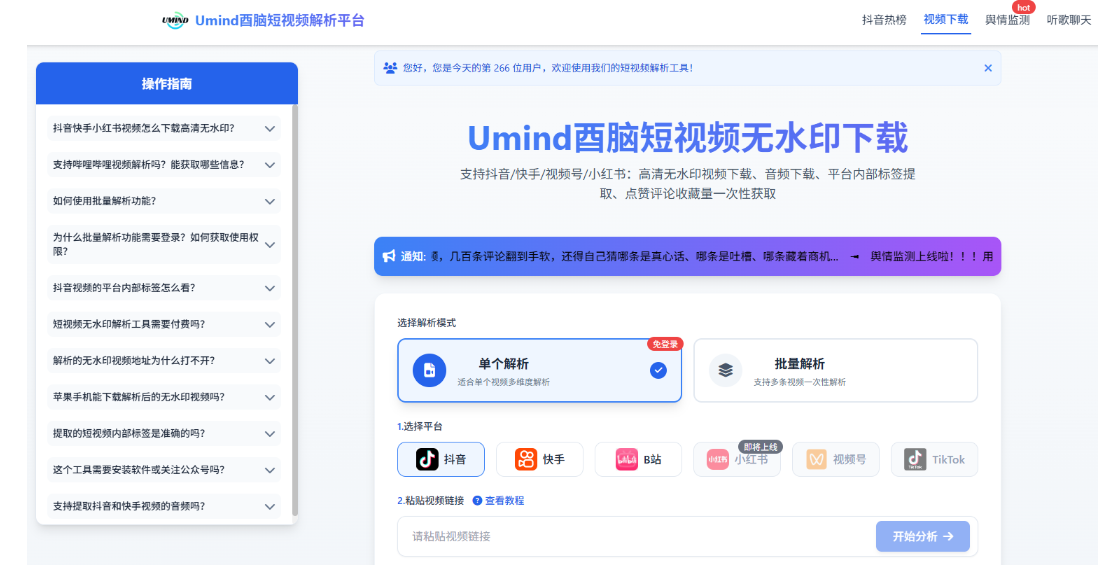
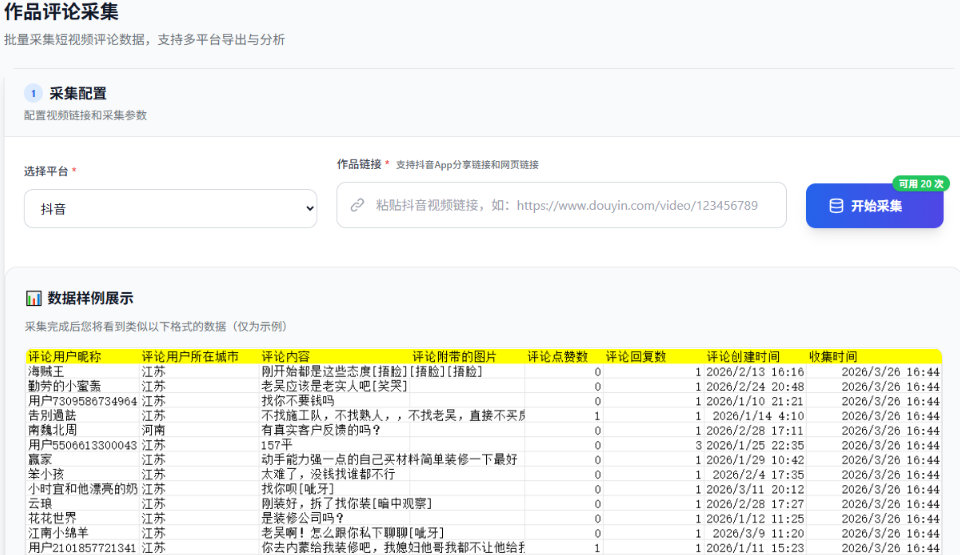
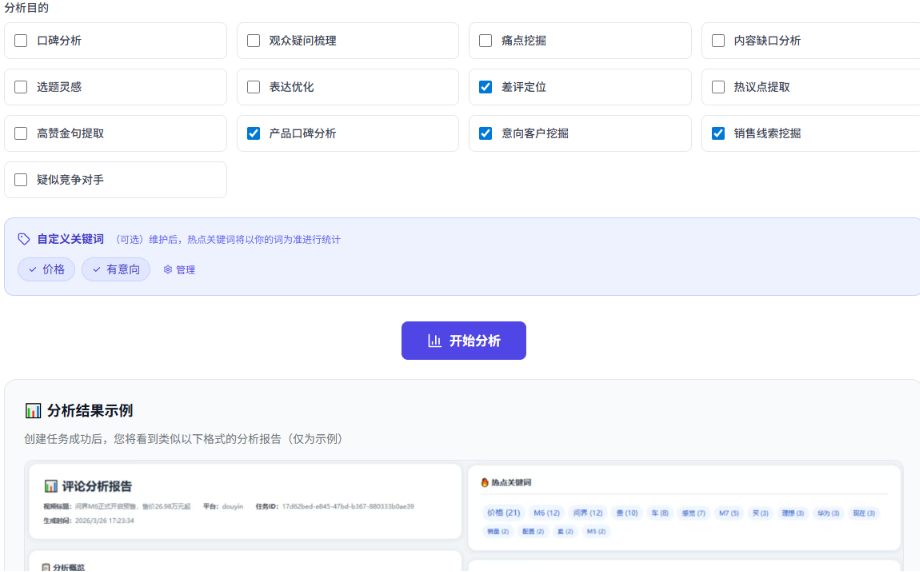
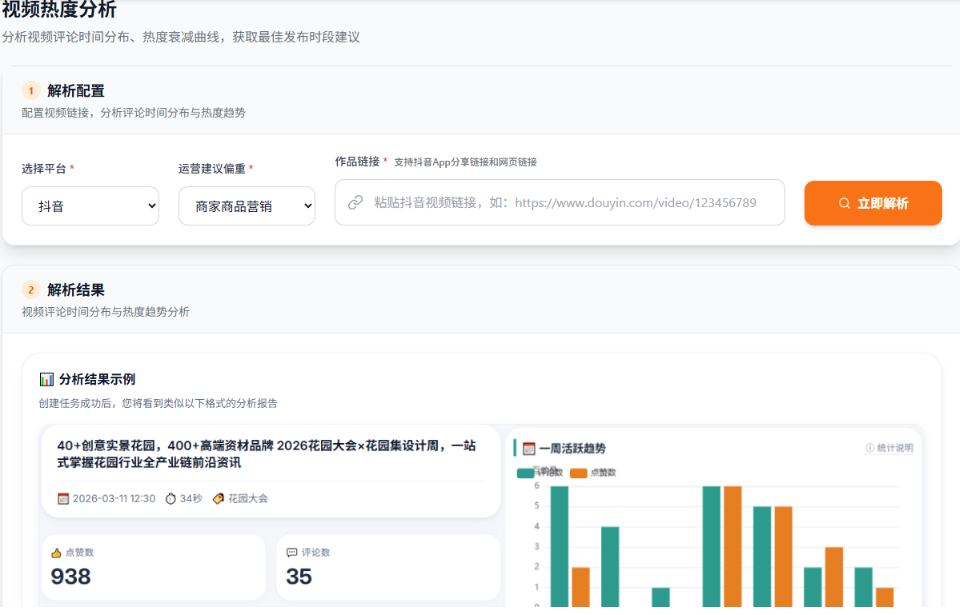
核心功能清单
- 视频无水印下载 - 支持抖音、快手、B站
- 评论数据采集 - 单次采集约400条评论
- 评论多维度AI分析 - 情感分析、热点关键词、话题聚类、差评定位、意向客户挖掘等20+维度
- 视频热度分析 - 波峰检测、最佳发布时间建议、地域分布分析
- PDF报告生成 - 一键导出完整分析报告
技术栈
- 前端:React + TypeScript + Vite + TailwindCSS
- 后端:FastAPI (Python)
- AI分析:本地规则引擎 + 大模型API混合架构
- 数据库:MySQL
写在最后
我不是来吹AI有多厉害的。
说实话,这两个月的开发过程,中间有好几次想放弃。因为你会发现,AI能帮你写代码,但它不能帮你做产品决策;AI能帮你review逻辑,但它不能替你理解用户。
最终决定系统成败的,还是产品经理自己的判断力。
所以,如果你是产品经理、运营、或者任何不懂代码但想用AI工具做点东西的人,我的建议是:
不要害怕。
你不需要成为技术专家,你需要的是:
- 清晰的需求描述能力
- 基本的逻辑判断能力
- 足够的耐心和细心
剩下的,交给AI去做。
系统目前仍在持续迭代中,如果你也有类似的经历或者想法,欢迎交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)