YOLOv8 vs YOLO26:输出张量大揭秘 —— 为什么你的后处理代码可以砍掉70%
#YOLO #目标检测 #模型部署 #边缘计算 #端到端推理
⚠️ 痛点直击:NMS 的 O(N²) 时间复杂度在边缘设备上是性能杀手。8400 个候选框的两两比较,CPU 上轻松吃掉 10-30ms。
阅读时间:约 10 分钟
两代模型,两种哲学
在深入张量格式之前,我们需要先理解一个根本性的设计分歧——YOLOv8 信奉"宁可多生成,后面再筛",而 YOLO26 选择"训练时就解决,推理时直接用"。
💡 比喻时间
想象你在快餐店点餐。YOLOv8 是那种把菜单上所有菜都端上来、让你自己挑的餐厅——上菜快,但挑菜(NMS)费时间。YOLO26 则是一位经验丰富的主厨,直接把你最想吃的几道菜精准端出来,不多不少。
YOLOv8 由 Ultralytics 于 2023 年初发布,采用 Anchor-Free 设计和解耦头(Decoupled Head)。它在三个尺度特征图上生成密集预测,通过分布焦点损失(DFL)优化边界框回归,最终需要 NMS 清理冗余检测。
YOLO26 则是 2026 年初的产物,核心卖点是端到端无 NMS 推理。通过双头训练架构(一对多头加速收敛 + 一对一头保证推理唯一性)、移除 DFL 模块、以及 STAL/ProgLoss 等训练策略,它在模型内部就完成了"去重"工作。
| 架构特性 | YOLOv8 | YOLO26 |
|---|---|---|
| 推理模式 | 传统模式 + 外部 NMS | 端到端,无需 NMS |
| 边界框回归 | DFL 分布焦点损失 | 直接回归浮点坐标 |
| 输出策略 | 密集预测,固定 8400 框 | 动态筛选 + 固定上限 |
| 目标设备 | 偏通用,GPU 友好 | 专为边缘 / CPU 优化 |
输出张量:到底长什么样?
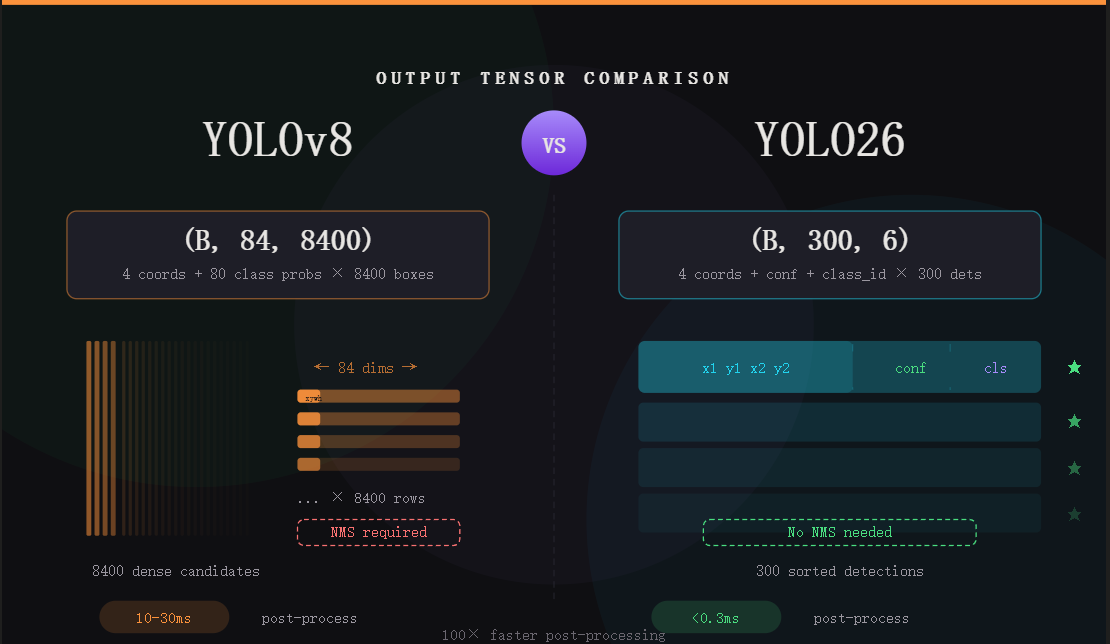
这是全文最核心的部分。两个模型的输出张量在形状、语义、可用性三个维度上截然不同。
一眼看懂
| YOLOv8 | YOLO26 | |
|---|---|---|
| 形状 | (B, 84, 8400) |
(B, 300, 6) |
| 含义 | 84 = 4坐标(xywh) + 80类别概率 8400 个候选框,需外部 NMS 筛选 | 6 = 4坐标(xyxy) + 1置信度 + 1类别ID 最多 300 个检测结果,已排序去重 |
YOLOv8:84 × 8400 意味着什么?
先看维度 84:前 4 个值是边界框的中心坐标和宽高 (cx, cy, w, h),全部是归一化值;后 80 个值是 COCO 数据集 80 个类别的概率分数,经过 softmax 归一化。你需要自己找到最大概率对应的类别,还要把 cx/cy/w/h 解码成像素坐标。
再看维度 8400:这些候选框来自三层特征图——P3(80×80,负责小目标)、P4(40×40,中等目标)、P5(20×20,大目标),每个网格点生成一个预测。绝大多数框是垃圾,重叠严重,必须靠 NMS 清理。
ℹ️ 注意转置陷阱:YOLOv8 输出形状是
(B, 84, 8400)而不是(B, 8400, 84),解析时需要先做转置操作,这是很多新手踩过的坑。
YOLO26:6 × 300 的极简哲学
YOLO26 的输出,每个检测结果只有 6 个数:x1, y1, x2, y2, confidence, class_id。坐标是左上角和右下角(xyxy 格式),直接缩放到原图尺寸就能画框;置信度是模型内部融合好的分数,无需额外计算;类别 ID 是整数索引,拿来就用。
300 个检测框已经按置信度降序排列,前面的框就是模型最有把握的检测结果。你只需要设一个置信度阈值(比如 0.25),把低于阈值的框丢掉,完事。
💡 比喻时间
再用一个比喻:YOLOv8 给你的是一整箱未分拣的快递(8400 个包裹),你得自己找、拆、扔;YOLO26 给你的是快递柜里按重要性排好的 300 个格子,打开前几个就是你要的东西。
全方位对比:一张表说清楚
| 维度 | YOLOv8 | YOLO26 |
|---|---|---|
| 输出形状 | (B, 84, 8400) |
(B, 300, 6) |
| 坐标格式 | 中心点+宽高 (xywh) | 对角点 (x1y1x2y2) |
| 置信度 | 需手动计算 | 直接输出 |
| 类别信息 | 80 维概率向量 | 1 维类别 ID |
| NMS | 必须 | 不需要 |
| 后处理步骤 | 4 步:解码→NMS→过滤→排序 | 1 步:阈值过滤 |
| 后处理复杂度 | O(N²) | O(N) |
| CPU 后处理延迟 | 10-30ms | <0.3ms |
| 跨框架兼容性 | 依赖各框架 NMS 实现 | 天然兼容大多数框架 |
代码说话:输出解析实战
光看表格不够直观,我们用一段可运行的代码来对比两个模型的完整后处理流程。你可以直接复制到本地跑一下,感受差距有多大。
import numpy as np
import time
# ═══════════════════════════════════════════════════
# 模拟数据:假设输入图像尺寸 640×640,COCO 80 类
# ═══════════════════════════════════════════════════
np.random.seed(42)
IMG_SIZE = 640
# YOLOv8 输出: (1, 84, 8400)
v8_output = np.random.rand(1, 84, 8400).astype(np.float32)
# YOLO26 输出: (1, 300, 6) — 坐标已归一化
v26_output = np.random.rand(1, 300, 6).astype(np.float32)
v26_output[..., 4] = np.random.rand(300) # 置信度 0~1
v26_output[..., 5] = np.random.randint(0, 80, 300) # 类别ID
# ═══════════════════════════════════════════════════
# YOLOv8 后处理(完整 4 步流程)
# ═══════════════════════════════════════════════════
def nms(boxes, scores, iou_thresh=0.45):
"""简易 NMS 实现"""
x1 = boxes[:, 0] - boxes[:, 2] / 2
y1 = boxes[:, 1] - boxes[:, 3] / 2
x2 = boxes[:, 0] + boxes[:, 2] / 2
y2 = boxes[:, 1] + boxes[:, 3] / 2
areas = (x2 - x1) * (y2 - y1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
inter = np.maximum(0, xx2 - xx1) * np.maximum(0, yy2 - yy1)
iou = inter / (areas[i] + areas[order[1:]] - inter + 1e-6)
inds = np.where(iou <= iou_thresh)[0]
order = order[inds + 1]
return keep
def postprocess_v8(output, conf_thresh=0.25, iou_thresh=0.45):
"""YOLOv8: 转置 → 解码 → 过滤 → NMS"""
preds = output[0].T # 步骤1: 转置 (84,8400) → (8400,84)
boxes = preds[:, :4] * IMG_SIZE # 步骤2: xywh 坐标解码
class_probs = preds[:, 4:] # 80 个类别概率
scores = class_probs.max(axis=1) # 取最大概率作为置信度
class_ids = class_probs.argmax(axis=1)
mask = scores > conf_thresh # 步骤3: 置信度过滤
boxes, scores, class_ids = boxes[mask], scores[mask], class_ids[mask]
keep = nms(boxes, scores, iou_thresh) # 步骤4: NMS 去重
return boxes[keep], scores[keep], class_ids[keep]
# ═══════════════════════════════════════════════════
# YOLO26 后处理(仅 1 步:阈值过滤)
# ═══════════════════════════════════════════════════
def postprocess_v26(output, conf_thresh=0.25):
"""YOLO26: 过滤低置信度框,完事"""
dets = output[0] # (300, 6)
mask = dets[:, 4] > conf_thresh # 仅需一步阈值过滤
dets = dets[mask]
boxes = dets[:, :4] * IMG_SIZE # xyxy 坐标缩放
scores = dets[:, 4] # 置信度直接可用
class_ids = dets[:, 5].astype(int) # 类别 ID 直接可用
return boxes, scores, class_ids
# ═══════════════════════════════════════════════════
# 性能对比
# ═══════════════════════════════════════════════════
N = 100
t0 = time.perf_counter()
for _ in range(N):
postprocess_v8(v8_output)
v8_ms = (time.perf_counter() - t0) / N * 1000
t0 = time.perf_counter()
for _ in range(N):
postprocess_v26(v26_output)
v26_ms = (time.perf_counter() - t0) / N * 1000
print(f"YOLOv8 后处理: {v8_ms:.2f}ms")
print(f"YOLO26 后处理: {v26_ms:.2f}ms")
print(f"加速比: {v8_ms/v26_ms:.1f}x")
跑一下你会发现,哪怕用纯 NumPy 模拟,YOLO26 的后处理也比 YOLOv8 快一个数量级以上。在真实的边缘设备上,这个差距会更加明显。
部署视角:NMS 是隐藏的"地雷"
很多人在选模型时只看 mAP 和 FPS,但真正到部署环节才发现——NMS 的跨框架兼容性是最大的坑。
ONNX Runtime、TensorRT、OpenVINO、CoreML、TFLite……每个推理框架对 NMS 算子的支持方式都不一样。有的原生支持,有的需要你用 C++ 手撸一个,有的干脆不支持。YOLOv8 在每个框架上都要处理这个兼容性问题,而 YOLO26 由于输出已经是最终结果,天然绕过了这颗地雷。
| 推理框架 | YOLOv8 | YOLO26 |
|---|---|---|
| ONNX Runtime | 需转置 + 外接 NMS | 直接可用 |
| TensorRT | 需手写 NMS Plugin | 端到端模式 |
| OpenVINO | 需处理 NMS 兼容 | 天然兼容 |
| CoreML / TFLite | 需适配 NMS 算子 | 端到端输出 |
| NCNN / RKNN | 不支持端到端 | 支持端到端 |
✅ 实战建议:如果你的项目需要在 3 个以上推理框架上部署同一个模型,YOLO26 的统一输出格式能帮你省下大量适配代码。
选型指南:你到底该选哪个?
没有绝对的好坏,只有适不适合。
选 YOLOv8 如果你……
-
需要极致 mAP 精度
-
GPU 资源充足,对延迟不敏感
-
需要自定义 NMS 策略
-
已有成熟的 v8 部署 pipeline
选 YOLO26 如果你……
-
部署在边缘设备(Nano / 树莓派)
-
实时性是硬指标(<30ms)
-
CPU 资源受限
-
需要快速上线、简化运维
写在最后
核心差异速记
-
形状:
(B, 84, 8400)vs(B, 300, 6)— 从"大而全"到"小而精" -
坐标:xywh(需解码)vs xyxy(直接可用)
-
NMS:必须外部执行 vs 模型内部已完成
-
延迟:后处理 10-30ms vs <0.3ms — 差距 100 倍
-
部署:每个框架单独适配 vs 天然跨平台兼容
YOLO26 的输出张量设计代表了目标检测领域的一个重要趋势——把复杂性从推理阶段前移到训练阶段。通过双头训练、改进损失函数等手段,让模型在训练时就学会输出干净、唯一、排序好的检测结果,从而在推理时实现真正的端到端。
当然,工程世界没有银弹。如果你的场景需要极致精度、需要灵活控制 NMS 策略、或者已经有成熟的 YOLOv8 pipeline 在生产环境稳定运行,也没必要为了追新而迁移。
但如果你正在启动一个新的边缘部署项目,YOLO26 值得作为首选方案认真评估。
如果这篇文章对你有帮助,点个赞让更多人看到 👍

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)