【技术加速器】图像检测新范式:大小模型协同,从静态分工迈向动态调度
欢迎来到我们的 「每周技术加速器」 专栏!
每周五,我们都会围绕一个前沿技术主题,展开一场深度的内部技术分享会。不仅是为了团队内部的碰撞与成长,也希望通过这样的形式,将我们的思考与实践记录、沉淀、分享给更多同行者。
本周,我们探讨的主题是:图像检测业务中,传统小模型与视觉大模型的协同之道。
图像检测是我们业务中覆盖面极广、应用频次极高的核心场景。当前,我们在实际生产中既大规模部署了成熟、高效的传统小模型,也在积极探索视觉大模型在特定复杂场景下的应用潜力。然而,随着业务场景的不断扩展和复杂化,一个关键问题逐渐浮出水面:大模型和小模型并非简单的替代或升级关系,它们各自拥有截然不同的能力边界和适用场景。如何让二者从“静态分工”走向“动态协同”,在精度、延迟和成本之间找到最优平衡点?本次分享会,我们围绕一套“语义感知的自适应边缘云协同工业检测系统”进行了深入拆解,探讨了一种全新的技术范式。以下是本次讨论的核心内容。
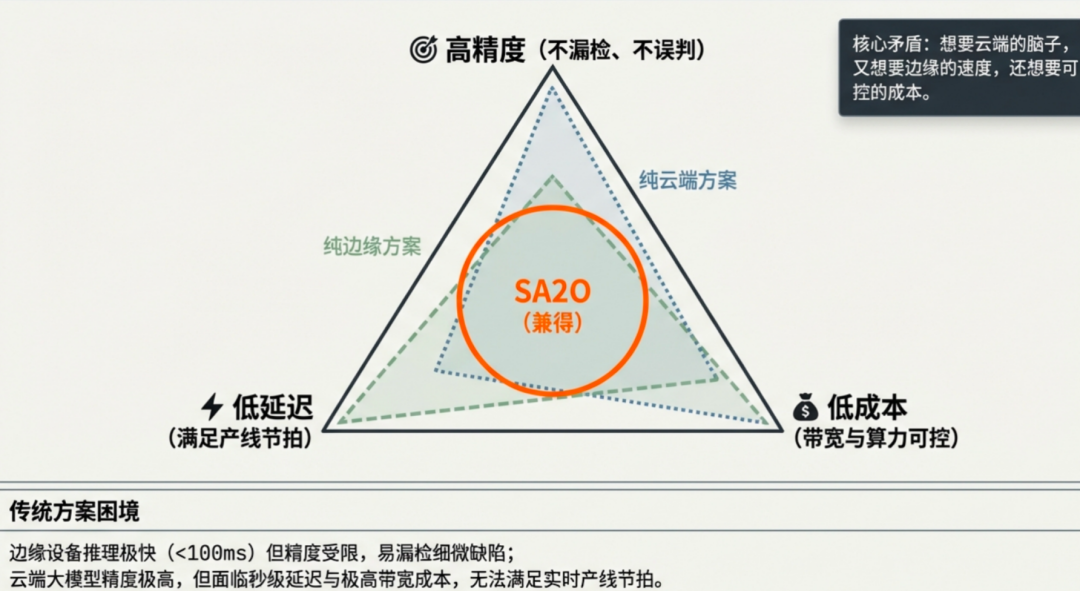
业务挑战:极速、高精、低廉的“不可能三角”
在工业质检、产线监测等真实业务场景中,图像检测面临着近乎苛刻的三重要求,这三者往往相互制约,形成了一道难以跨越的技术鸿沟。
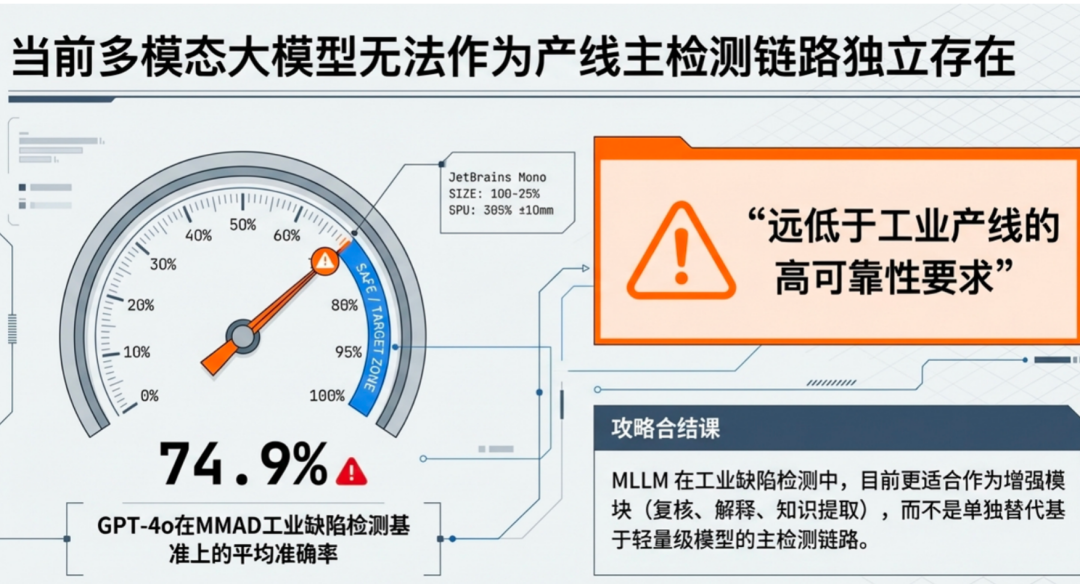
1.极速:毫秒级的实时性要求
工业生产线的运转速度极快,检测环节必须与产线节拍保持同步。任何超过允许范围的延迟都可能导致整条产线停摆,造成巨大的经济损失。这意味着,检测系统必须在极短时间内完成图像采集、处理、分析和结果反馈的全流程。对于边缘端设备而言,这要求模型必须具备极高的推理效率;对于云端协同方案,则需要考虑网络传输和云端排队带来的不确定性延迟。
2. 高精:识别罕见、细微缺陷的能力
工业质检的精度要求远超一般的图像分类任务。不仅要能准确检出常见的明显缺陷,更要具备识别罕见缺陷、细微瑕疵的能力。这些缺陷可能表现为极小的划痕、微弱的色差、形态多变的异物,或者在正常样本中占比极低的长尾问题。漏检一个这样的缺陷,可能导致不合格产品流入市场,引发质量事故和品牌声誉损失。
3. 低廉:算力、带宽、维护的综合成本约束
在实际业务中,技术方案不仅要效果好,还要具备经济上的可持续性。这包括:
-
算力成本:边缘端设备的算力有限,云端GPU资源昂贵。
-
带宽成本:海量高清图像上传云端需要消耗大量网络带宽。
-
维护成本:模型需要频繁迭代以适应新的产品线或缺陷类型,人力投入巨大。
现有方案的局限性
面对上述挑战,传统技术方案各有其难以突破的瓶颈:
-
纯边缘端小模型:虽然推理速度快、成本低,但受限于模型容量和训练数据,存在明显的“认知盲区”。当遇到复杂的背景干扰、光照变化,或是训练集中未曾出现过的罕见缺陷时,小模型容易出现漏检和误判,难以满足高精度要求。
-
纯云端大模型:视觉大模型凭借其强大的表征能力和泛化性,理论上具备更高的精度上限。但其推理延迟大、计算成本高昂,且极度依赖稳定的网络环境。一旦网络出现波动或超时,产线将面临停摆风险,这在工业场景中是难以接受的。
-
静态规则分工:传统“简单任务由边缘处理,复杂任务上云”的硬性分工策略,虽然逻辑简单,但无法应对图像复杂度的动态变化。一张看似“简单”的图像可能隐藏着细微缺陷,一张“复杂”的图像也可能只是正常样本。静态规则不仅导致资源浪费,也难以在不同产品线间复用,整体效率低下且脆弱。
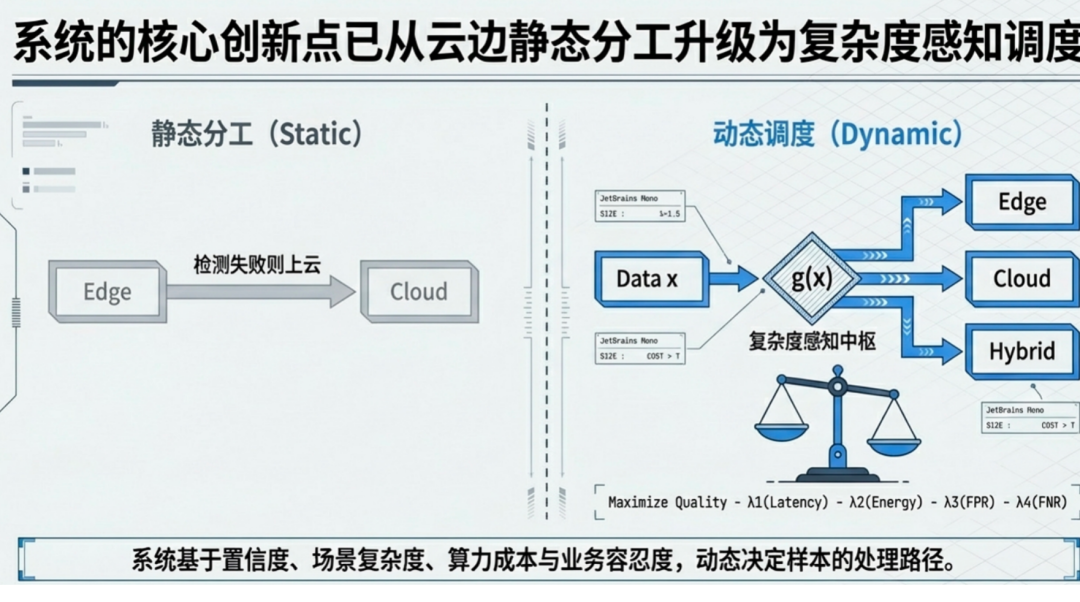
因此,我们亟需一种全新的架构,能够动态感知每张图像的检测复杂度,智能调度边缘端小模型和云端大模型的资源,在保证精度的前提下,实现延迟和成本的最优化。
破局之道:五层协同体系,让模型各司其职
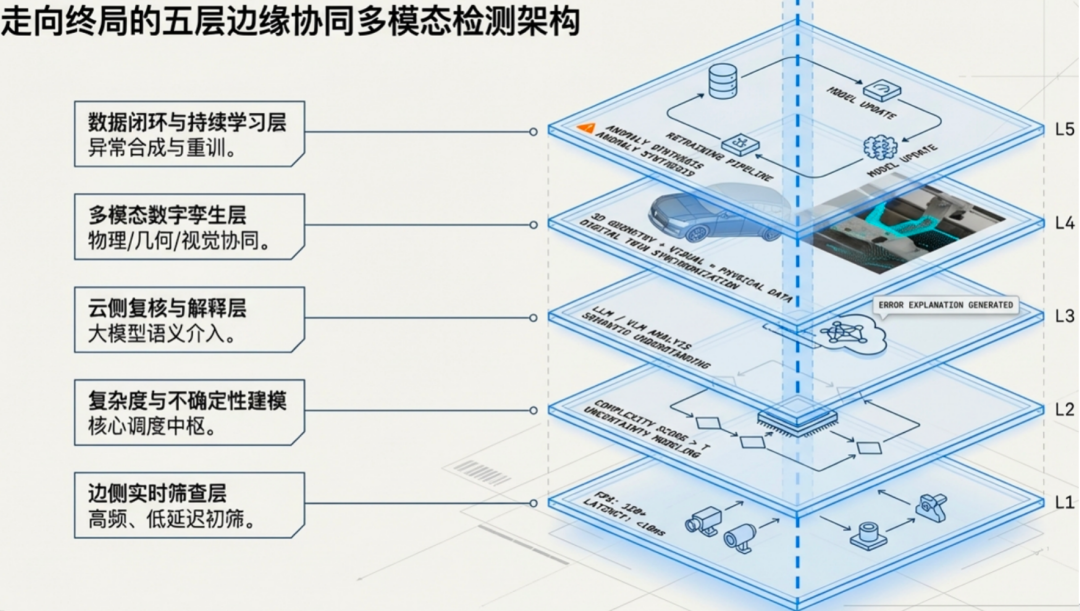
为解决上述难题,我们提出并构建了一套五层边缘云协同架构。这套架构的核心思路是:引入“复杂度感知中枢”和“多智能体”机制,将传统的静态分工升级为动态、自适应的智能调度。
体系构成与作用
整个体系通过语义介入和多智能体增强判断效果,设置算法根据边缘端的置信度动态引入大模型推理专家,选择合适的智能体策略。具体而言,它由五个层次构成,每一层都承担着独特且不可替代的角色。
各层功能详解
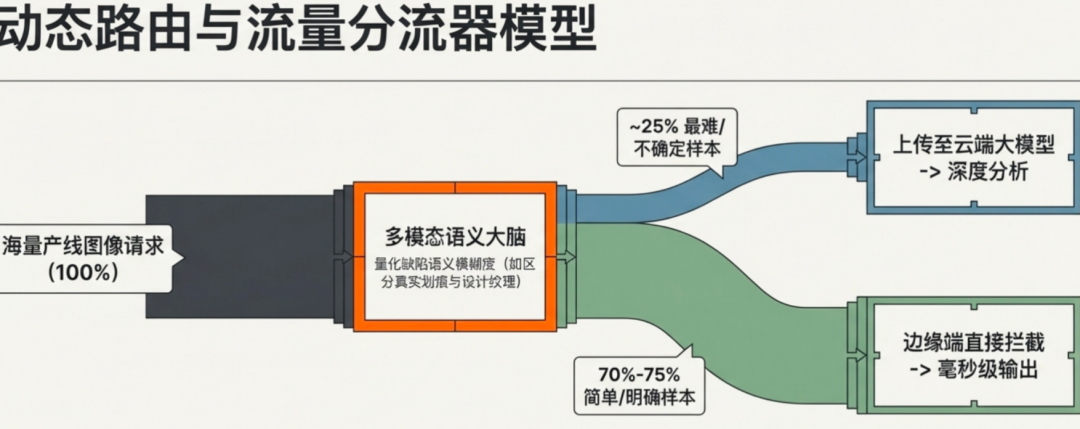
第一层:边侧高效筛查(解决80%以上的常规问题)
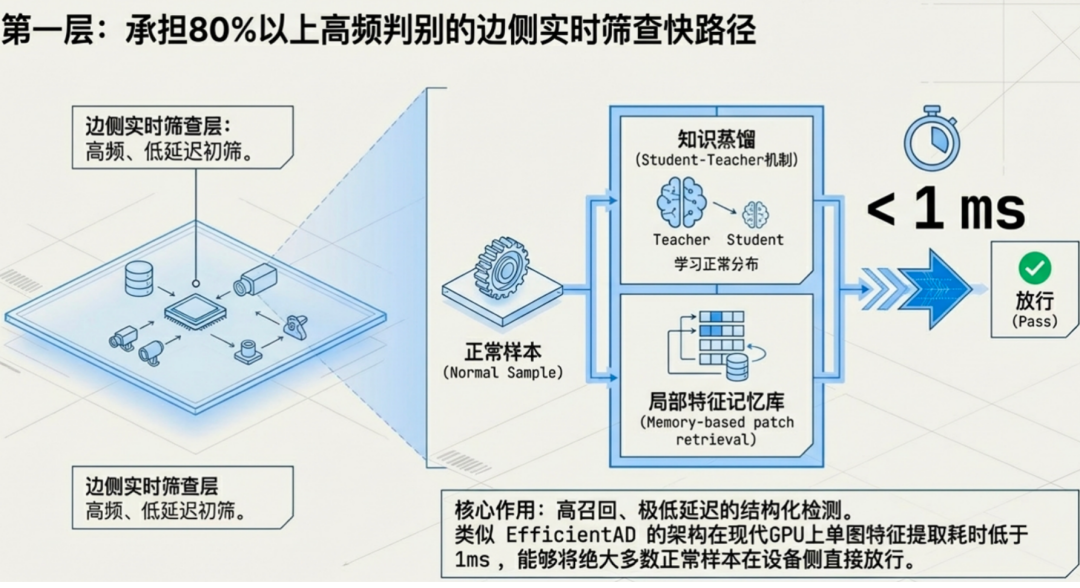
这是系统的第一道防线。我们利用轻量化模型(例如基于 efficient ad 架构的检测器)在边缘端GPU上进行快速、低功耗的初步筛查。这类模型经过专门优化,参数量小、推理速度快,功耗远低于云端模型。
在实际运行中,绝大多数(超过80%)的工业图像是正常的,或者包含的是模型已经非常熟悉的常见缺陷类型。这些样本完全可以由边缘端模型高效处理,直接输出检测结果,无需占用任何网络带宽和云端计算资源。这一层是整个系统实现流量节约和低延迟的基石。
第二层:复杂度感知中枢(动态调度决策)
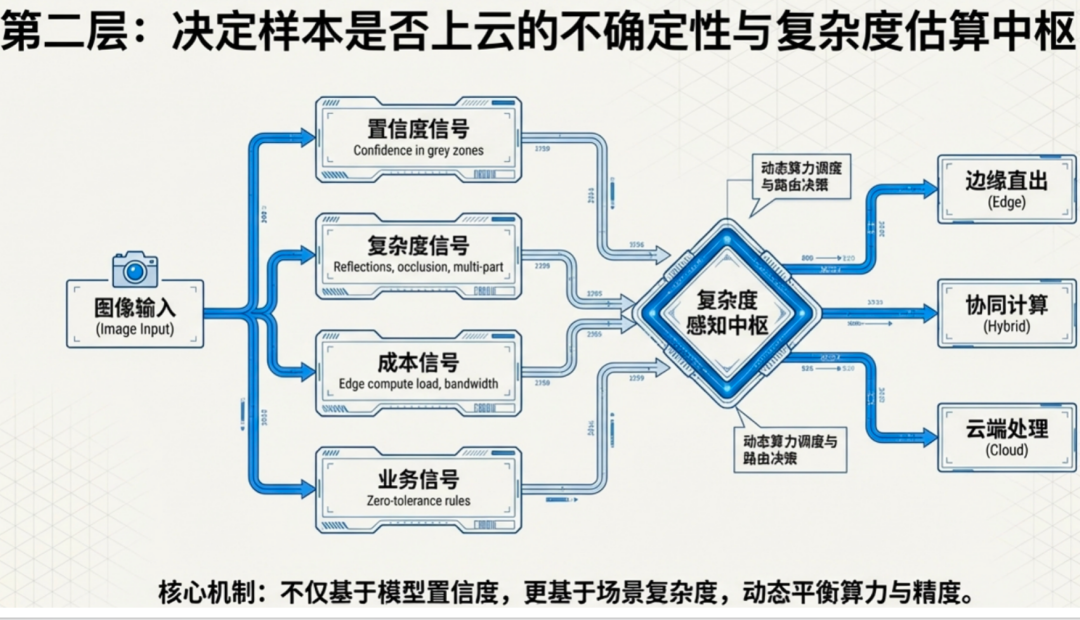
这是整个体系的“大脑”,也是最关键的核心组件。它不再根据预设的静态规则进行分流,而是实时评估每一张图像的检测复杂度。
具体来说,这个中枢会综合三个维度的信号做出决策:
-
图像置信度:边缘端模型对当前图像输出的置信度分数。当置信度很高时,说明样本简单,结果可靠;当置信度较低时,则表明样本可能复杂或处于边界状态。
-
成本信号:当前网络带宽的占用情况、云端算力的负载水平、以及调用大模型所需的经济成本。
-
业务信号:当前检测的产品批次是否为重点客户订单、是否为新产品线需要重点积累数据、或者历史数据表明该批次缺陷率较高等。
基于以上多维信息,复杂度感知中枢会动态决定该样本的处理路径:是直接信任边缘端结果并放行,还是需要上云请求大模型进行进一步分析。这实现了真正的“按需调度”和“成本敏感”的智能决策。
第三层:云端大模型推理(处理疑难杂症)
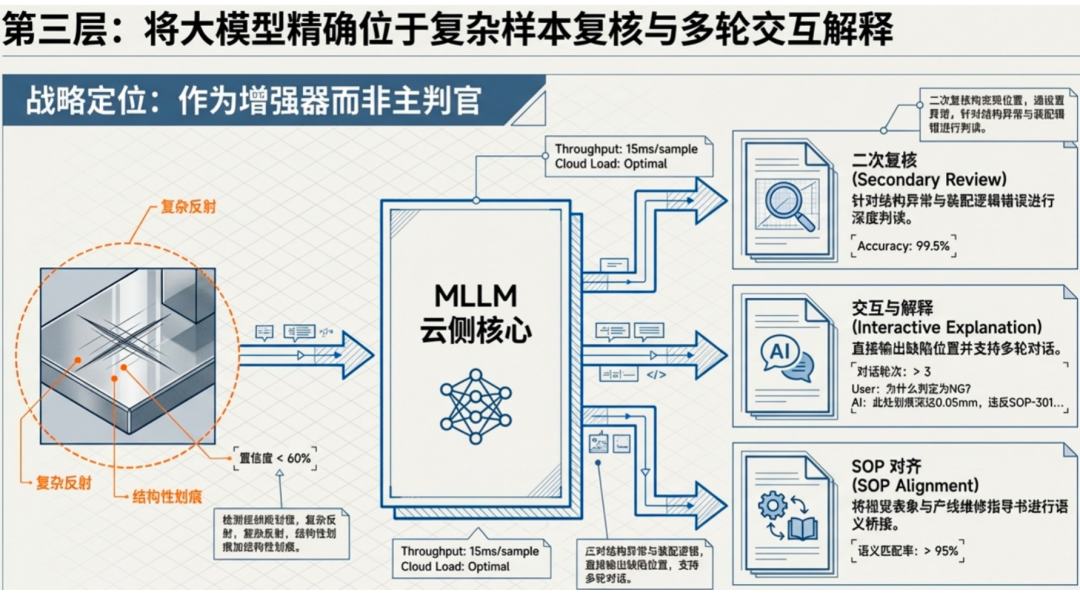
当复杂度感知中枢判定当前样本的置信度不够高,或其复杂度超出了边缘端模型的处理能力时,系统会动态地将该样本“上云”,并引入视觉大模型进行深度推理和二次复核。
在这里,大模型扮演了“专家会诊”的角色。它凭借其强大的上下文理解能力和泛化能力,能够处理那些包含罕见缺陷、复杂背景干扰、或细微纹理变化的“疑难杂症”样本。大模型的介入,精准地弥补了边缘端小模型在精度上的短板。
第四层:基于1P3A策略的多模态数字孪生跨维一致性校验
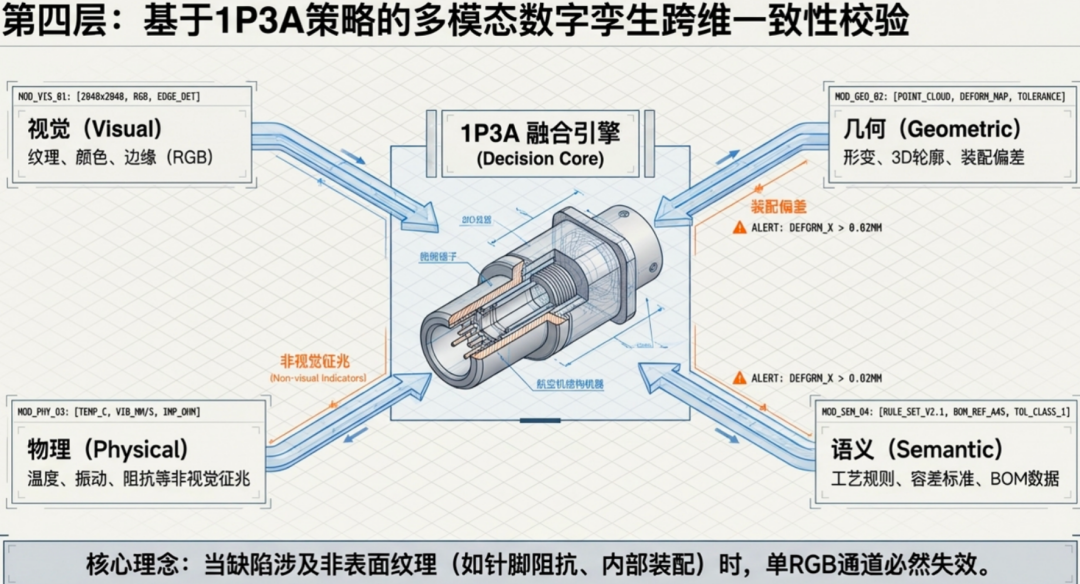
其核心是一个“1P3A融合引擎(Decision Core)”,它作为决策中枢,汇聚并处理来自四个维度的多模态数据:
-
视觉(Visual):处理纹理、颜色和边缘等RGB信息。
-
几何(Geometric):分析形变、3D轮廓及装配偏差。
-
物理(Physical):采集温度、振动、阻抗等非视觉征兆。
-
语义(Semantic):整合工艺规则、容差标准和BOM数据。
该架构的核心理念在于突破单一检测手段的局限。正如底部所述,当缺陷涉及非表面纹理(如针脚阻抗、内部装配)时,单靠RGB通道必然失效。因此,系统通过这四个维度的跨维一致性校验,利用多模态数据的互补性来实现更精准的边缘决策。
第五层:数据增强与模型进化(识别罕见缺陷)
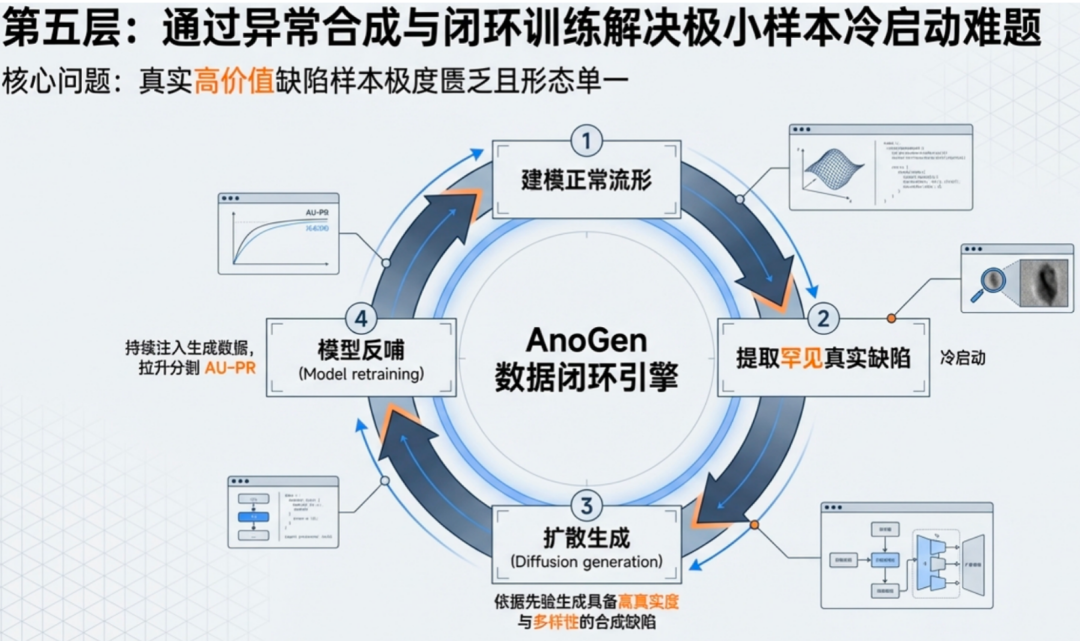
工业质检中最棘手的问题之一,就是罕见缺陷样本的匮乏。由于这类缺陷发生概率极低,真实数据难以大量获取,导致模型在遇到此类样本时表现不佳。
为了解决这个问题,我们借鉴了前沿的扩散生成模型技术,在第五层构建了数据增强能力。该层可以自动生成高质量、多样化的罕见缺陷数据,用于扩充训练集。通过这种方式,系统能够持续提升对长尾、罕见缺陷的识别能力,显著提高了AUPR(精确率-召回率曲线下的面积)这一关键指标,使模型在现实世界中更加健壮。
方案优势:精准分流,实现效果与效率的双赢
这套“动态调度”方案,通过将“观测”与“决策”解耦,交由多个智能体负责,并在四维空间(边缘、云端、语义感知加推理、全融合)内进行协同操作,在实际业务中展现出了显著优势。我们从延迟、缺陷检出率、带宽成本、网络鲁棒性、新场景适应能力等多个维度进行了评测,效果令人振奋:
-
流量节约75%:通过边缘端的精准拦截和复杂度感知中枢的智能分流,大量正常和简单样本无需上云,极大节省了网络带宽和云端算力成本。这是整个方案最直观的经济效益。
-
端到端延迟降低25%:由于减少了不必要的网络传输和云端排队时间,整体处理延迟得到了显著优化。对于产线而言,这意味着更高的安全边际和更稳定的生产节拍。
-
困难场景精确度提升7倍:在那些包含细微缺陷、罕见缺陷或复杂背景的“困难样本”上,通过大模型的精准介入和二次复核,检测精确度实现了质的飞跃。这是方案在核心业务价值上的关键突破。
-
极速收敛:得益于高效的协同机制和数据增强能力,系统仅需约200个样本就能快速适应新的产品线或检测场景。这意味着在新品上线或产线调整时,我们的AI检测能力能够以极快的速度完成冷启动和部署,极大提升了业务的敏捷性。
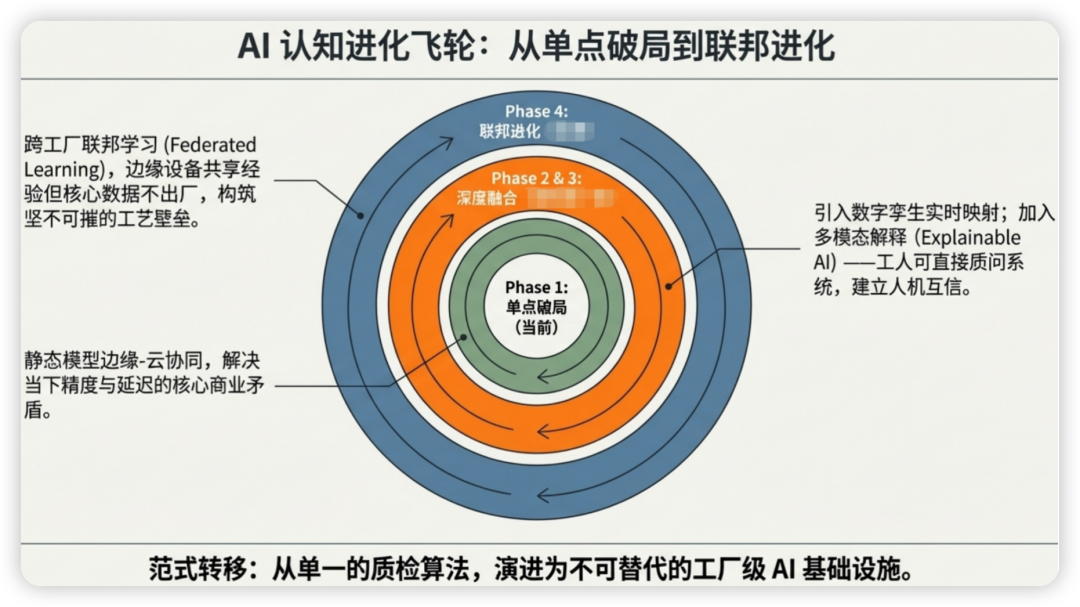
未来演进:从协同到融合,构建认知驱动的动态引擎
本次探讨不仅着眼于当前方案的落地价值,更展望了未来的演进方向。我们认为,理想的工业质检系统不应只是静态的“模型组合”,而应是“认知驱动”的、具备自我进化能力的动态引擎。未来的研究将重点围绕以下几个方向展开:
1. 结合联邦学习与数字孪生
-
联邦学习:在保护各产线数据隐私的前提下,实现跨节点、跨工厂的模型协同进化。不同产线积累的缺陷知识可以安全地汇聚,形成更强大的全局模型,再下发回各边缘端,实现共同进步。
-
数字孪生:在数字空间中构建与物理产线1:1映射的虚拟环境,可以对新的检测算法、调度策略进行低成本、高效率的仿真验证和优化,提前发现潜在问题,加速技术迭代。
2. 引入更复杂的智能体协同机制
未来的边缘端可以部署轻量级的CLIP等模型进行初步的语义认知判断。在联邦云节点,则可以根据不同情况,动态调度“多模态专家智能体”进行深度分析和决策。这些专家智能体可以分别专注于特定类型的缺陷(如划痕、异物、形变),或特定材料(如金属、塑料、玻璃),通过多智能体之间的协作与博弈,进一步提升整体系统的精准度和鲁棒性。
3. 生成式AI的常态化应用
利用扩散模型等生成式AI技术,持续、自动地补充稀缺的负样本(缺陷样本),构建一个“数据飞轮”。每次在实际检测中发现的罕见缺陷,都可以通过生成式模型进行扩增,用于迭代和强化边缘端模型的能力,形成一个“发现-生成-学习-提升”的闭环,使系统在部署后依然能够持续进化。
结语:从单一模型优化,到系统架构协同
图像检测的技术演进,正在从一个“模型选择”的问题,转变为一个“系统协同”的问题。
我们不再单纯追求某一类模型的极致精度,而是致力于构建一个精度、延迟、成本、鲁棒性多方联合优化的动态系统。大模型与小模型不再是替代关系,而是各展所长、互为补充的合作伙伴。大模型负责攻坚克难,提供高精度的“专家意见”;小模型负责日常巡检,保障实时性和经济性。
通过引入复杂度感知、动态分流、多智能体协同、数据增强与生成等机制,我们有望打破“极速、高精、低廉”的不可能三角。这不仅是一次技术架构的升级,更是我们应对日益复杂的业务挑战、实现从“可用”到“好用”再到“规模化应用”的一次重要思维跃迁。
未来,随着这套认知驱动的动态引擎不断演进,我们有理由相信,图像检测将变得更加智能、高效和可靠,为工业质检等核心业务场景创造更大的价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)