为什么我们没做超级 Agent,而是搞了个多 Agent 应用中心?
做 AI 产品这段时间,有个问题一直绕不过去:到底是做一个啥都能干的超级 Agent,还是做一堆专门干一件事的垂类 Agent?
我们选了后者。这篇文章就是想聊聊这个决策背后的想法,给同样在纠结的朋友一点参考。
先说说我们为啥质疑"超级 Agent"
现在主流的 AI 工具,默认思路都是"做一个尽可能强的通用 Agent"。但说实话,这个假设有几个前提,我们越想越觉得不对劲。
第一个前提:用户需要灵活跨域的能力?
其实不是。我们聊了很多用户后发现,大家真正高频的需求特别具体:
- 每天发一篇小红书
- 每周写一篇技术博客
- 每月交一份周报
- 每个节日做一组营销图
这些都是重复做、有固定套路的事。用户要的不是"灵活的 AI",而是"快、稳、别出错"的专业工具。
第二个前提:AI 能力可以无限堆叠?
我们测过,现实很骨感:
- 工具超过 30 个,选工具的准确率就开始掉
- 提示词超过 5000 字,模型就开始"装傻"
- 上下文塞太满,推理质量明显下降
Agent 不是越大越强,是越大越糊。
第三个前提:Agent 越强体验越好?
恰恰相反。一个 Agent 既要会写小红书,又要会写代码,还要会做图、调 API…提示词必然变得又臭又长,各种能力互相打架。
用户用起来就是:啥都能干,但啥都干不好。
我们的解法:应用中心 + 垂类 Agent
所以我们就反着来了。不搞"一个超级大脑",而是搞"一群专家":
TipKay 应用中心里有:
- 通用 Agent(实在搞不定的扔给它兜底)
- 小红书博主 Agent(专门写小红书 + 直接发布)
- 知乎博主 Agent(写长文专用)
- 博客发布助手(适配 CSDN、知乎、掘金、头条四个平台)
- 文章配图 Agent(专门搞图文搭配)
- 还有用户自己用编辑器搭的 Agent…
每个 Agent 的设计原则很简单:
- 提示词只聚焦一件事(控制在 1000 字以内)
- 工具不超过 10 个
- 反复执行的任务要又快又稳
- 别被无关的能力分心
几个关键的工程决策
1. 每个 Agent 独立提示词
我们没搞"主提示词 + 加载 Skills"那种方案。每个垂类 Agent 都是独立的——独立提示词、独立工具、独立配置。
好处很明显:改一个不会影响其他,调试也简单。用户也清楚自己在用啥(“我在用小红书博主"而不是"我在用一个加载了小红书技能的通用 AI”)。
代价就是工程上要维护多套提示词,一些通用逻辑(比如品牌包注入)得想办法共享。
2. Context Assets 三层共享
为了解决这个问题,我们做了 Context Assets 系统:
- 用户资料(你是谁、做啥的)
- 品牌包(Logo、配色、Slogan)
- 素材包(产品图、案例、文案库)
所有 Agent 自动读取这些上下文,相当于有个"全局共享的用户记忆"。
// 简化版伪代码
class BaseAgent {
async buildPrompt(userInput: string) {
const contextAssets = await this.loadContextAssets()
return `
${this.systemPrompt}
# User Context
${contextAssets.baseProfile}
# Brand Context
${contextAssets.brandKit}
# Available Materials
${contextAssets.assetManifest}
# User Input
${userInput}
`
}
}
每个垂类 Agent 继承这个 BaseAgent,自动获得 Context 注入能力。
3. MCP 和 Skills 只是补充
我们也支持 MCP,但定位很清楚:垂类 Agent 缺能力的时候用来补,而不是先搞个超级 Agent 再用 MCP 去撑。
优先级是:垂类 Agent 主力 → 缺啥补啥。
4. 用户可以自己造 Agent
我们做了个 Agent App 编辑器,用户可以:
- 自己搭垂类 Agent
- 配提示词、选工具、选模型
- 测试完发布到市场给别人用
这样 Agent 的数量就从"我们做的 6 个"变成了"无限个"。
实测数据:垂类 Agent 真的更强吗?
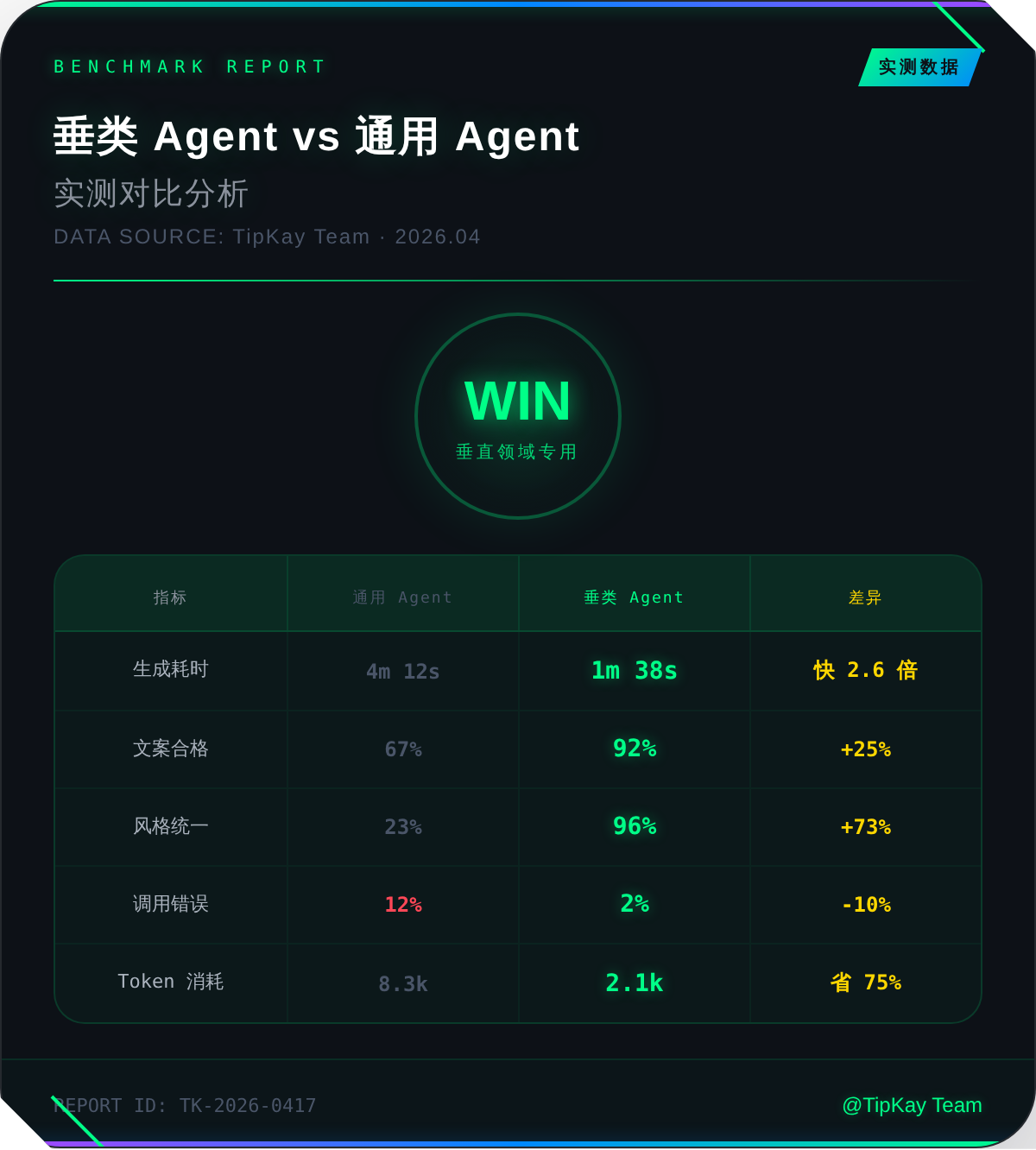
我们做过对比实验,任务是让 AI 生成 10 篇小红书笔记。
| 指标 | 通用 Agent | 垂类 Agent |
|---|---|---|
| 平均耗时 | 4 分 12 秒 | 1 分 38 秒 |
| 文案合格率 | 67% | 92% |
| 配图风格统一率 | 23% | 96% |
| 工具调用错误率 | 12% | 2% |
| Token 消耗 | 8.3k | 2.1k |
在重复任务上,垂类 Agent 确实是降维打击。
但多 Agent 也不是万能的
说实话,这个方案也有不适合的场景:
不适合的:
- 深度研究类任务(比如 deep research,需要在多个领域跳来跳去)
- 探索性任务(你自己都不知道要啥,需要 AI 给建议)
- 开发者工具(像 Cursor 那种,写代码、读文档、调 API 随时切换)
适合的:
- 重复执行的固定任务(发小红书、写博客)
- 特定行业的深度任务
- 普通用户(不是程序员,是花店老板、自媒体博主)
给同行的几点建议
如果你也在做 AI 产品,可以想想这几个问题:
-
你的用户是开发者还是普通人?
开发者习惯自己配 Skills,普通人更喜欢开箱即用的垂类工具。 -
核心场景是探索还是重复执行?
探索用通用 Agent,重复执行用垂类 Agent。 -
Agent 数量预期多少?
少于 5 个凑合用一个超级 Agent,超过 10 个就必须上应用中心架构。 -
你愿意把多少决策权交给用户?
交得多就做通用平台,交得少就做多 Agent 矩阵。
最后说两句
架构决策说到底,是对用户需求的判断。
我们选多 Agent 矩阵,是因为觉得中文创作者的核心需求是"把重复的事做得又快又稳",而不是"有一个啥都懂的 AI 助手"。
这个判断对不对,时间会给出答案。但至少希望这篇文章能让大家意识到——做 Agent 不是只有"做一个超级大脑"这一条路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)