Python学习超简单第六弹:爬虫实操示例
爬虫实操
示例
requests模块下载和安装
requests模块在使用前需要先安装,可以在系统控制台下输入如下命令完成:
pip install requests -i http://pypi.douban.com/simple–trusted-host=pypi.douban.com
参数介绍
使用requests的get函数从指定网页上下载数据:
get(url, params=None, **kwargs)
作用:发送一个get请求。
url参数:指定要从哪个网址获取网页数据。
params参数:(可选)在请求时发送的字典、元组列表或字节类型的数据。
**kwargs参数:一些可选参数。
返回:Response类对象。
如:request=requests.get(url, timeout=30, headers=headersParameters)
headersParameters中保存了请求头的信息
headersParameters = {
‘Connection’: ‘Keep-Alive’, # Connection决定当前的事务完成后,是否会关闭网络连接。如果该值是“KeepAlive”,网络连接就是持久
'Accept’: ‘text/html, application/xhtml+xml, /’, #浏览器接收的媒体类型,text/html代表HTML格式,application/xhtml+xml代表XHTML格式,/ 代表浏览器可以处理所有类型
‘Accept-Language’: ‘en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3’, #浏览器申明自己接收的语言
‘Accept-Encoding’: ‘gzip, deflate’, #浏览器申明自己接收的编码方式:通常指定压缩、是否支持压缩、支持什么方式压缩(gzip/default)
‘User-Agent’: ‘Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko’ #告诉HTTP服务器客户端浏览器使用的操作系统和浏览器的版本和名称}
网页中提取信息
在浏览器下访问网页,按键盘上的F12功能键出现浏览器的调试工具查看页面上的元素,查看要获取元素的HTML代码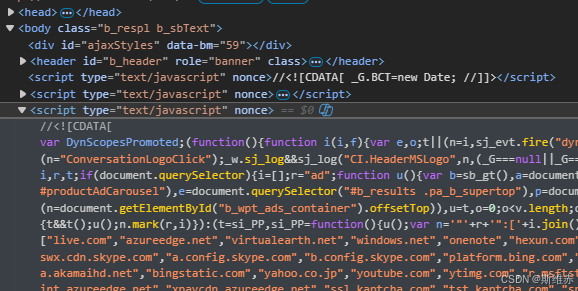
设计的正则表达式:
r'<h3 class="c-title">([\s\S]*?)</h3>'
通过re.sub函数去除title中多余的HTML标记,如
re.sub(r'<[^>]+>','',title) #去除title中的所有HTML标记
数据显示和文件保存
通过for循环将这些新闻标题显示在屏幕上,如:
no=1
for title in titles:
print(str(no)+':'+title)
no+=1
按类似的方法,也可以将新闻标题写入到filepath所对应的文件中,如:
with open(filepath, 'w') as f: #使用with语句,以使得文件操作完毕后文件能够自动关闭
no=1
for title in titles:
f.write(str(no)+':'+title+'\n')
no+=1
代码
import re
import requests
from urllib.parse import quote #导入quote方法对URL中的字符进行编码
class BaiduNewsCrawler: #定义BaiduNewsCrawler类
headersParameters = { #发送HTTP请求时的HEAD信息
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language':
'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent':
'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword, timeout): #定义构造方法
self.url='https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word=' + quote(keyword) + '&x_bfe_rqs=03E80&x_bfe_tjscore=0.002213&tngroupname=organic_news&pn='#要爬取的新闻网址
self.timeout=timeout #连接超时时间设置(单位:秒)
self.titles = []
def GetHtml(self, startIdx): #定义GetHtml方法
request=requests.get(self.url+str(startIdx),timeout=self.timeout,headers=self.headersParameters) #根据指定网址爬取网页
self.html=request.text #获取新闻网页内容
def GetTitles(self, recnum): #定义GetTitles方法
titles = re.findall(r'<h3 class="c-title">([\s\S]*?)</h3>',self.html) #匹配新闻标题
for i in range(len(titles)): #对于每一个标题
temp=re.sub(r'<[^>]+>','',titles[i]) #去除所有HTML标记,即<...>
self.titles.append(temp.strip()) #将标题两边的空白符去掉
if len(self.titles)==recnum:
break
def PrintTitles(self): #定义PrintTitle方法
no=1
for title in self.titles: #显示标题
print(str(no)+':'+title)
no+=1
def ExportToFile(self, filepath): #定义ExportToFile方法,将标题输出到文件中
with open(filepath, 'w', encoding='utf-8') as f:
no=1
for title in self.titles:
f.write(str(no)+':'+title+'\n')
no+=1
def GetTitlesNum(self): #定义GetTitlesNum方法,返回已获取的新闻标题数
return len(self.titles)
if __name__ == '__main__':
bnc = BaiduNewsCrawler('南开大学',30) #创建BaiduNewsCrawler类对象
oldStartIdx = startIdx = 0
recnum = 45 #要获取的新闻标题数
while startIdx<recnum:
bnc.GetHtml(startIdx) #获取新闻网页的内容
bnc.GetTitles(recnum) #获取新闻标题
startIdx = bnc.GetTitlesNum() #得到已获取的新闻标题数
print('已获取'+str(startIdx)+'条新闻标题')
bnc.PrintTitles() #显示新闻标题
bnc.ExportToFile('newstitlelist.txt') #将新闻标题保存到文件中
结尾
记录自己的快乐学习日志,也祝贺观看到这的小伙伴早日学有所成,财富自由💰💰。
记得点赞👍、收藏👋呀!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)