MoE 模型:让大模型学会分工合作
这几年,大模型的发展一直在追求一件事:让模型更强。最直接的办法当然是扩大参数量,因为参数越多,模型能容纳的知识和模式通常也就越多。但问题也很现实,参数变大之后,训练成本会更高,推理也会更贵。尤其在用户真正使用模型时,如果每次回答一个问题都要完整调用整个超大模型,那这种代价很快就会变得难以承受。
所以,大模型很快遇到了一个核心矛盾:我们想要更大的模型容量,但又不希望每次计算都把所有参数全部用上。换句话说,大家真正想要的不是“一个每次都全员出动的庞然大物”,而是“一个总能力很强、但遇到具体问题时能有选择地调动资源的系统”。MoE,也就是 Mixture of Experts,专家混合模型,就是在这个背景下重新变得重要的。
大模型为什么需要 MoE
传统的大模型大多是稠密模型,也就是 dense model。所谓稠密,指的是模型里的大部分参数在每次前向计算中都会被激活。无论你问的是数学题、代码问题,还是翻译、写作,模型的主体结构基本都会完整参与计算。这样的设计当然直接,也比较统一,但它有一个明显的问题:模型越大,每次推理的成本就越大。
这会带来两个后果。
第一个后果是效率问题。假设一个模型拥有非常大的参数规模,但每一次输入都要把这些参数全部跑一遍,那么它虽然能力可能变强了,使用成本却也会同步爆炸。对于部署来说,这不是一个可以无限持续的路线。
第二个后果是表达问题。现实里的任务本来就是多种多样的,有些输入更偏逻辑推理,有些更偏语言表达,有些更偏代码结构,还有些涉及多语言切换。让同一套参数始终同时负责所有事情,虽然可行,但并不一定高效。它相当于让一个庞大的统一团队去处理所有工作,而不是先分部门、再分任务。
所以问题其实可以浓缩成一句话:能不能让模型既拥有很大的总容量,又不需要每次都完整调用全部参数?
MoE 想解决的就是这个问题。
把“大模型”变成“专家团队”
MoE 的设计思路其实很直观。既然不是所有任务都需要整套参数一起工作,那不如把模型中的一部分计算层拆成很多个“专家”,然后让系统自己决定当前输入更适合交给哪些专家处理。
这里的“专家”并不是人类能直接命名的那种“数学专家”“翻译专家”,而是模型内部若干个并行的子网络。每个子网络都可以看作一个独立的参数模块,它们会在训练过程中逐渐学到不同的处理偏好。与此同时,模型还需要一个“路由器”,负责在输入到来时进行判断:这次该调用哪些专家。
这样一来,MoE 的整体结构就变成了两部分。
第一部分是很多个并行存在的专家模块。它们共同组成了一个很大的参数池,让模型拥有更强的总容量。
第二部分是路由机制。它不负责真正处理复杂语义,而是负责选择。也就是说,它先看当前输入的特征,再决定这次应该激活哪几个专家。
这种设计和传统稠密模型的区别就在于,稠密模型是“所有参数默认一起上”,而 MoE 是“先判断,再调度”。前者更像一个所有人永远同时工作的团队,后者则更像一个有分工、有调度的组织结构。
因此,MoE 的核心并不是单纯地“加更多参数”,而是把参数组织方式改掉了。它不再假设所有参数对所有输入都 equally necessary,而是允许模型内部形成某种动态分工。
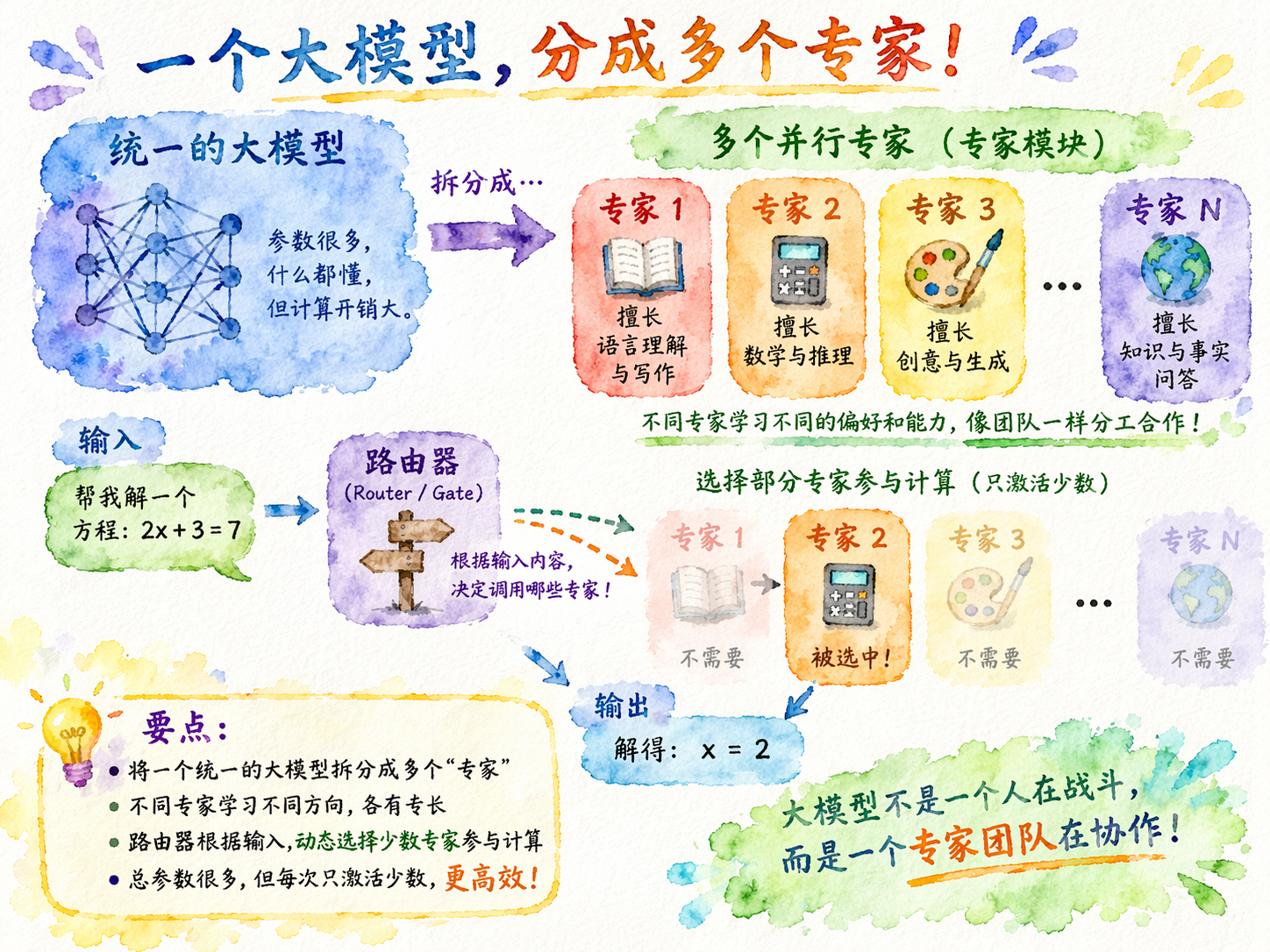
MoE 到底是怎么工作的
真正落到技术实现上,MoE 的关键不在于“专家很多”这件事本身,而在于它怎么让这些专家参与计算。现在主流的大模型里,MoE 通常不会把整个 Transformer 都改掉,而是主要替换其中的前馈网络,也就是 FFN 层。原因很简单:注意力机制主要负责 token 和 token 之间的信息交互,而 FFN 更像是对每个 token 做进一步加工,本身参数量大,也更适合拆成多个并行模块。因此,很多 MoE 模型的做法都是保留原来的注意力结构,只把部分 FFN 层改造成“多个专家并行存在”的形式。
当输入经过网络来到某个 MoE 层时,它不会像普通稠密层那样直接进入一个固定的前馈网络,而是先经过一个路由器,也就是 router 或 gate。这个路由器会根据当前 token 的表示,为所有专家打分,表示“这个 token 更适合由哪些专家处理”。随后,系统不会把它送给全部专家,而只会选出得分最高的少数几个专家,这就是常见的 top-k routing。比如一层里有 64 个专家,但每个 token 只激活其中 2 个,那么从总参数上看,这一层非常大;但从一次实际计算来看,真正参与运算的只是一小部分。
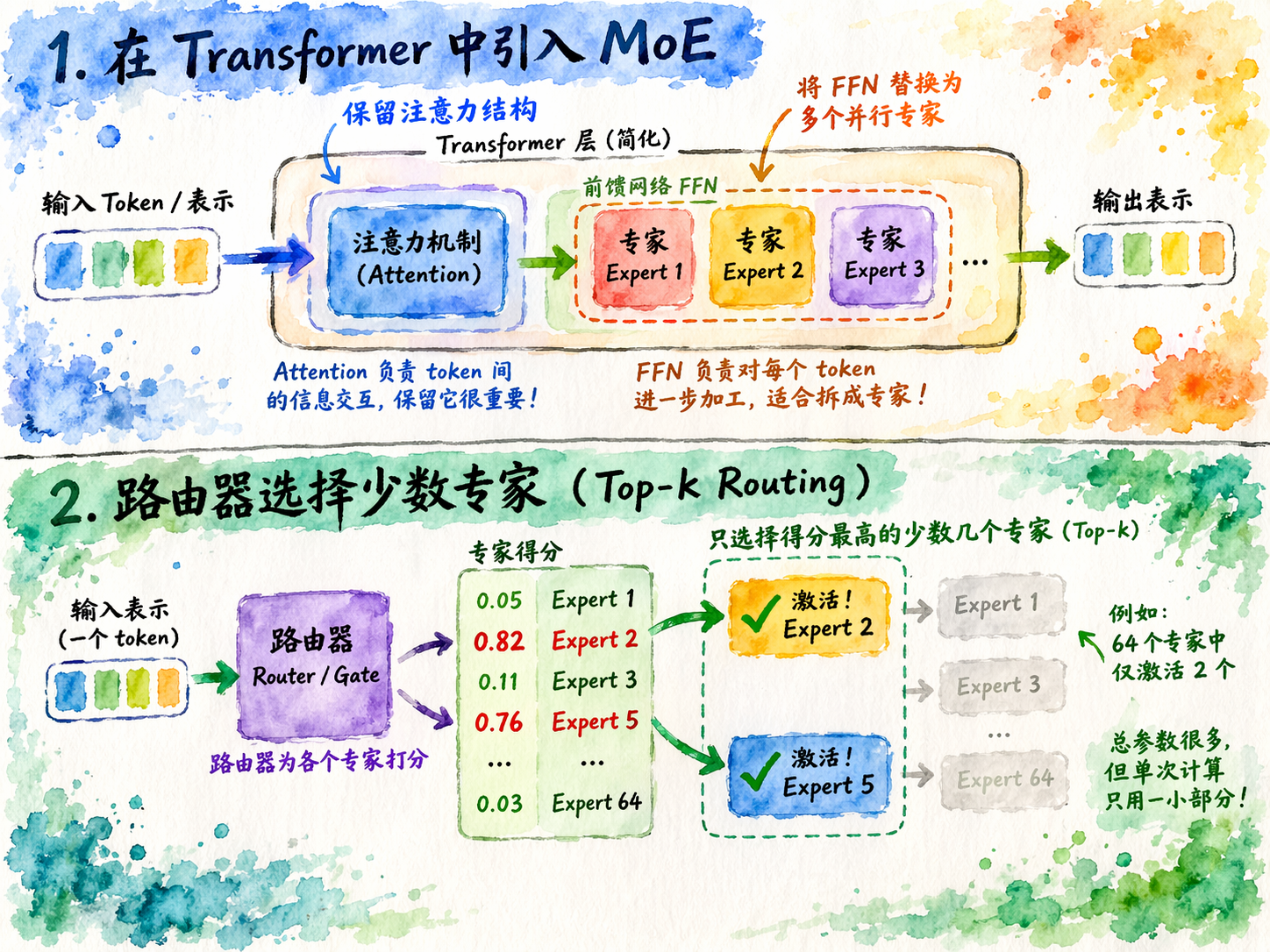
这就是 MoE 最核心的技术特点:总参数很多,但单次激活是稀疏的。也就是说,模型拥有一个很大的容量池,但并不是每次都把所有能力一起调用出来,而是先做选择,再局部计算。这样做的直接好处是,模型的总规模可以继续扩大,但单次推理的计算量不必和总参数量一起线性上涨。对于超大模型来说,这一点很关键,因为它提供了一种“继续做大,但不至于每次都全量计算”的路线。
不过,MoE 真正难的地方也恰恰在这里。理论上,只激活少数专家当然很高效;但训练时如果路由器学得不好,就会出现负载不均衡的问题。也就是说,模型可能会反复把大量 token 都送去少数几个专家,导致这些专家一直很忙,其他专家却长期几乎收不到输入。这样一来,那些常被调用的专家会越来越强,冷门专家则因为训练不足越来越弱,最后模型虽然形式上有很多专家,实际上真正发挥作用的只有少数几个。这就是人们常说的专家塌缩,或者内部专业化被削弱:专家没有形成理想中的分工系统,而是逐渐退化成“少数专家工作,大部分专家闲置”的状态。
为了解决这个问题,工程上通常会加入一些辅助机制。最常见的是负载均衡损失,也就是在主任务损失之外,再额外约束路由结果不要过度集中到少数专家上。它的目的不是让所有专家绝对平均,而是避免路由器过早形成“赢家通吃”的局面,给更多专家保留学习机会。除此之外,很多系统还会设置容量限制,也就是规定每个专家在一个 batch 中最多接收多少 token。这样做可以防止某些热门专家被塞得过满,也能迫使一部分 token 流向其他专家,从而缓解极端偏斜的问题。
除了训练稳定性,MoE 还有一个很现实的工程挑战,就是通信和部署。因为不同 token 可能会被路由到不同专家,而这些专家在大规模训练时往往分布在不同设备上,所以系统需要不断做数据分发、重排和聚合。这意味着 MoE 虽然在理论上节省了计算,但在真实系统里也引入了额外的通信成本。如果底层并行和调度做得不好,那么“省下来的计算”很可能会被“新增的通信开销”抵消掉。所以 MoE 不只是一个模型结构问题,它同时也是一个系统工程问题。
MoE 的意义不只是“省算力”
MoE 更重要的意义在于,它代表了一种新的模型组织方式。过去很多神经网络默认所有输入走同一条路径,所有参数一起工作;而 MoE 开始让模型具备一种更接近真实系统的能力:面对不同输入,动态分配不同资源,让不同模块承担不同任务。
这背后体现的是一种非常关键的思想变化。模型不再只是“越大越好”,而是开始追求“更有组织地变大”。不是盲目堆更多参数,而是让这些参数以专家分工的方式存在,并通过路由机制实现按需调用。
当然,MoE 也不是万能答案。它的训练更复杂,部署更困难,对工程能力要求更高。而且专家到底学到了什么、分工到底是否稳定,也并不总是容易解释。但即便如此,在大模型继续扩张的今天,MoE 依然提供了一条非常现实的路线:让模型容量继续增长,同时避免每次推理都付出同样夸张的代价。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)