大模型进入Agentic时代:Claude Opus 4.7如何用64.3%的SWE-bench成绩改写软件工程规则(国内可用,入口在文末)
摘要:随着人工智能技术的飞速发展,大型语言模型(LLM)正从单纯的文本生成工具演变为具备自主决策能力的智能代理(Agent)。2026年4月16日,Anthropic正式发布了其迄今为止最强大的公开可用模型——Claude Opus 4.7。本文从技术架构、性能基准、多模态能力、安全设计等多个维度,对Claude Opus 4.7进行系统性深度解析。研究表明,该模型在软件工程任务上的SWE-bench Pro基准测试中取得64.3%的突破性成绩,较上一代提升近11个百分点;同时,其视觉处理能力实现了质的飞跃,单张图像最大支持分辨率提升至约375万像素(2576像素长边),是前代模型的三倍以上。本文通过理论分析、性能对比和实证研究,为技术从业者提供全面的技术洞察与使用指导。
重要提示:根据我国相关法律法规,未经批准擅自建立或使用VPN等工具访问境外互联网属于违法行为。Anthropic官方Claude服务目前未在中国大陆开放,但用户可通过国内合法备案的AI服务平台使用Claude Opus 4.7最新模型。国内镜像站的使用不仅合法合规,还能提供更稳定的访问体验。建议广大开发者遵守法律法规,选择正规渠道使用AI服务。温馨提示:官网目前对中国封禁严重,镜像站资源紧张属正常现象,而且在镜像站中要点击Claude(新版)这栏,opus确实紧张,早上早起使用是个不错的选择。

1. 大模型技术演进与Claude Opus 4.7的诞生背景
1.1 大型语言模型的发展脉络
大型语言模型(Large Language Model, LLM)的发展可以追溯到2017年Google提出的Transformer架构。这一革命性的神经网络结构通过自注意力机制(Self-Attention Mechanism)彻底改变了自然语言处理领域的范式。Transformer的核心创新在于其能够并行处理序列数据,同时捕捉长距离依赖关系,这为解决自然语言理解与生成的复杂任务奠定了坚实基础。
从GPT-1到GPT-4系列,从BERT到T5,再到如今的Claude、Gemini等前沿模型,LLM的发展呈现出几个显著趋势:模型参数规模持续扩大、上下文窗口不断延伸、多模态能力日益增强、以及从被动响应向主动代理(Agentic)行为的范式转变。特别是在2023年至2026年间,业界见证了从单纯的语言生成到复杂任务执行Agent的关键跨越。
| 发展阶段 | 代表模型 | 核心特征 | 技术突破 |
|---|---|---|---|
| 2017-2019 萌芽期 | BERT, GPT-1/2 | 预训练+微调范式 | 双向编码器表示、单向生成架构 |
| 2019-2022 爆发期 | GPT-3, T5, PaLM | 超大规模参数 | Few-shot学习能力涌现 |
| 2022-2024 对齐期 | GPT-4, Claude 2/3, Gemini | RLHF对齐、指令跟随 | 人类价值观对齐、安全性提升 |
| 2024-2026 Agentic期 | Claude Opus系列, GPT-4.5/5.x | 自主代理、工具使用 | 多步推理、复杂工作流执行 |
上表展示了LLM发展的四个关键阶段。当前,我们正处于"Agentic期",这一阶段的模型不再满足于单次问答,而是能够自主规划、调用工具、执行多步骤任务。Claude Opus 4.7正是这一技术浪潮的集大成者,它在保持强大语言理解能力的同时,显著提升了代码生成、视觉理解和长期任务执行的能力。
1.2 Anthropic的技术哲学与Claude系列演进
Anthropic作为一家专注于AI安全研究的机构,自创立以来始终秉持"有益、诚实、无害"(Helpful, Harmless, Honest)的技术开发原则。与OpenAI的"通用人工智能(AGI)"叙事不同,Anthropic更强调在提升模型能力的同时,确保其行为的可预测性和可控性。这一哲学在Claude系列模型的迭代过程中得到了充分体现。
Claude模型的命名源自"Claude Shannon"——信息论的创始人,这暗示了Anthropic对信息熵与不确定性控制的重视。从Claude 1.0到Claude 3.x系列,再到2025-2026年密集发布的4.x系列(Opus 4.5于2025年11月发布、4.6于2026年2月发布、4.7于2026年4月发布),Anthropic保持约每两个月一次的快速迭代节奏。这种高频迭代背后,是其独特的模型开发流水线与严格的安全测试机制。
值得注意的是,Anthropic在产品策略上采取了"双轨并行"模式:一方面面向公众发布经过充分安全验证的生产级模型(如Opus 4.7),另一方面在严格控制的Project Glasswing框架下研发更强大的实验性模型(如Claude Mythos Preview)。后者在各项基准测试中均超越Opus 4.7,但因具备潜在的网络安全能力而被限制在特定合作伙伴范围内使用。这种"分层释放"策略体现了Anthropic对AI安全风险的审慎态度。
1.3 Claude Opus 4.7的技术定位与核心目标
Claude Opus 4.7被Anthropic定位为"迄今为止最强大的公开可用模型"(most capable generally available model)。与上一代Opus 4.6相比,4.7版本的核心改进目标集中在三个维度:
第一,Agentic能力的深度强化。模型被设计用于处理需要持续推理和自主验证的长期任务。用户报告可以将过去需要密切监督的复杂编码工作放心地交给Opus 4.7,模型会在返回结果前主动验证自身输出的正确性。这种"自我修正"机制是Agentic能力的核心标志。
第二,视觉理解能力的质的飞跃。通过将图像处理分辨率提升三倍(长边最大像素从约860提升至2576,总像素从约115万提升至约375万),Opus 4.7能够解读更密集的文本截图、解析更复杂的图表结构、识别更精细的UI元素。这为计算机视觉Agent、文档自动化处理等应用场景开辟了新的可能性。
第三,软件工程能力的系统性突破。在SWE-bench Pro这一最具挑战性的真实代码修复基准测试中,Opus 4.7取得了64.3%的成绩,不仅较自身前代提升10.9个百分点,更超越了GPT-5.4(57.7%)和Gemini 3.1 Pro(54.2%)。这一成绩标志着LLM在解决真实软件开发问题方面迈出了关键一步。
| 核心改进维度 | Opus 4.6 | Opus 4.7 | 提升幅度 | 竞品对比(GPT-5.4) |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8% | - |
| SWE-bench Pro | 53.4% | 64.3% | +10.9% | 57.7% |
| OSWorld-Verified | 72.7% | 78.0% | +5.3% | 75.0% |
| CursorBench | 58% | 70% | +12% | - |
| 最大视觉分辨率 | ~115万像素 | ~375万像素 | 3.26倍 | - |
| MCP-Atlas工具使用 | 75.8% | 77.3% | +1.5% | 68.1% |
上表数据揭示了Opus 4.7在各个关键维度的进步。特别值得关注的是SWE-bench Pro的突破——这一基准测试要求模型解决GitHub上真实的软件问题,涉及多语言代码库、复杂依赖关系和生产级工程实践。64.3%的成绩意味着模型能够独立处理近三分之二的实际软件维护任务,这对于软件开发行业具有深远的变革意义。
2. Claude Opus 4.7的核心技术架构与原理
2.1 混合Transformer架构与注意力机制创新
Claude Opus 4.7延续了基于Transformer的混合架构设计,但在注意力机制、位置编码和层间信息流动等方面进行了深度优化。其核心架构可以概括为"深度编码器-解码器混合体",结合了双向上下文理解与单向自回归生成的优势。
在注意力机制层面,Opus 4.7采用了改进型的稀疏注意力(Sparse Attention)模式。传统的全连接自注意力计算复杂度为O(n²),其中n为序列长度,这在处理百万级上下文时会导致计算资源爆炸。Opus 4.7通过引入滑动窗口注意力(Sliding Window Attention)与全局稀疏注意力(Global Sparse Attention)的混合策略,将计算复杂度降低至近似O(n log n),同时保持了关键的长距离依赖捕捉能力。
具体而言,模型在每个注意力层中并行运行两种注意力模式:本地注意力头(Local Attention Heads)专注于上下文窗口内的精细关系建模,全局注意力头(Global Attention Heads)则通过稀疏采样机制关注序列中的关键锚点。这种"双轨注意力"设计使模型既能理解局部语义结构,又能把握宏观篇章逻辑。
数学上,改进后的注意力计算可以表示为:
Attention ( Q , K , V ) = softmax ( Q K T d k + M ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dkQKT+M)V
其中M为混合掩码矩阵,融合了滑动窗口掩码M_sliding与稀疏全局掩码M_sparse:
M = α ⋅ M sliding + ( 1 − α ) ⋅ M sparse M = \alpha \cdot M_{\text{sliding}} + (1-\alpha) \cdot M_{\text{sparse}} M=α⋅Msliding+(1−α)⋅Msparse
参数α根据任务复杂度动态调整,在简单任务中偏向本地注意力以提高效率,在复杂推理任务中则增强全局注意力的权重。
2.2 上下文窗口管理与记忆机制
Claude Opus 4.7保持了与前代相同的上下文窗口规格:最大支持100万(1M)token的上下文输入和12.8万(128k)token的输出长度。然而,真正提升的是模型在长上下文中的信息检索精度和推理一致性。
长上下文管理的核心挑战在于"中间遗忘"(Lost in the Middle)现象——研究表明,传统LLM对上下文中间位置的信息召回率显著低于开头和结尾部分。Opus 4.7通过以下技术组合应对这一挑战:
首先是分层记忆压缩机制。模型在处理超长文档时,会自动将输入划分为语义连贯的块(chunks),并为每个块生成压缩摘要向量。这些摘要向量构成"元记忆"层,当需要定位特定信息时,模型首先在元记忆层进行粗粒度检索,再精确定位到具体块。这种两级检索策略显著提升了长文档的信息定位效率。
其次是动态位置编码策略。Opus 4.7采用了改进的旋转位置编码(Rotary Position Embedding, RoPE)变体,通过引入频率域衰减因子,使模型对不同距离的位置关系具有更平滑的感知。数学表达为:
f RoPE ( x , m ) = ( cos ( m θ i ) − sin ( m θ i ) sin ( m θ i ) cos ( m θ i ) ) ⋅ x f_{\text{RoPE}}(x, m) = \begin{pmatrix} \cos(m\theta_i) & -\sin(m\theta_i) \\ \sin(m\theta_i) & \cos(m\theta_i) \end{pmatrix} \cdot x fRoPE(x,m)=(cos(mθi)sin(mθi)−sin(mθi)cos(mθi))⋅x
其中频率参数 θ i = θ b a s e − 2 i / d θ_i = θ_{base}^{-2i/d} θi=θbase−2i/d,通过调整 θ b a s e θ_{base} θbase的衰减系数,模型能够在超长序列中保持位置敏感性。
最后是递归自注意力机制。在处理跨越多轮对话的长期任务时,模型会对历史上下文进行周期性总结,形成"记忆快照"。这些快照作为压缩的历史表示,参与后续推理过程,既保留了关键信息,又避免了上下文长度的无限膨胀。
2.3 多模态融合与视觉处理架构
Claude Opus 4.7最显著的技术升级之一是视觉处理能力的全面提升。模型现在支持最大2576像素长边的图像输入,总像素数达到约375万(3.75MP),是前代模型的三倍多。这一升级背后是完整的多模态架构重构。
视觉处理流水线采用"视觉编码器-投影器-语言解码器"的三级架构。输入图像首先通过基于Vision Transformer(ViT)的视觉编码器处理,将像素空间映射为视觉token序列。Opus 4.7使用了高分辨率ViT变体,通过自适应图像分块(adaptive patching)策略处理不同尺寸的输入。
关键技术细节在于动态图像分块算法。对于高分辨率图像,模型并非简单压缩,而是采用"全局-局部"双路径编码:
- 全局路径:图像被下采样至标准分辨率(如448×448),提取整体语义和布局信息
- 局部路径:图像被切分为多个重叠的高分辨率块(如每个块1024×1024),每个块独立编码以保留细节
两条路径的输出通过跨模态注意力融合,既保证了全局理解,又保留了局部细节。这种设计使得Opus 4.7在处理密集文本截图、复杂图表或精细UI界面时具有显著优势。
视觉token与文本token在统一的语义空间中通过投影器(Projector)对齐。投影器采用多层感知机(MLP)结构,将视觉编码器的输出映射为与语言模型兼容的表示维度。值得注意的是,Opus 4.7的视觉投影器经过了大规模图文对数据的对比学习预训练,建立了细粒度的跨模态对应关系。
2.4 工具使用与Agentic执行框架
Claude Opus 4.7的Agentic能力建立在其先进的工具使用(Tool Use)框架之上。该框架通过Model Context Protocol(MCP)实现模型与外部工具、API和服务的标准化交互。MCP定义了统一的工具描述格式、调用协议和结果返回规范,使模型能够动态发现和组合多种能力。
工具使用流程遵循"感知-规划-执行-验证"的闭环逻辑:
- 感知阶段:模型分析用户请求和当前上下文,识别需要外部工具介入的场景
- 规划阶段:模型生成工具调用计划,包括工具选择、参数绑定和执行顺序
- 执行阶段:系统实际调用工具API,获取返回结果
- 验证阶段:模型评估执行结果,决定是否需要修正、补充或继续下一步
Opus 4.7在MCP-Atlas基准测试中取得了77.3%的成绩,领先GPT-5.4(68.1%)达9.2个百分点。这一基准测试模拟了真实生产环境中多工具、多轮交互的复杂场景,高分表明Opus 4.7在工具编排和错误恢复方面具有突出能力。
模型还支持**任务预算(Task Budgets)**机制(beta功能),开发者可以为多步骤任务设置token消耗上限。模型在执行过程中会监控预算消耗,在资源紧张时优先保证核心任务的完成。这一机制对于成本控制和资源管理具有重要价值。
此外,Claude Code环境中引入了新的"/ultrareview"命令,触发专门的代码审查流程。模型会以更高的推理深度扫描代码,标记潜在bug和设计缺陷,这种"双重验证"机制显著提升了代码生成的可靠性。
3. 性能基准测试与竞品对比分析
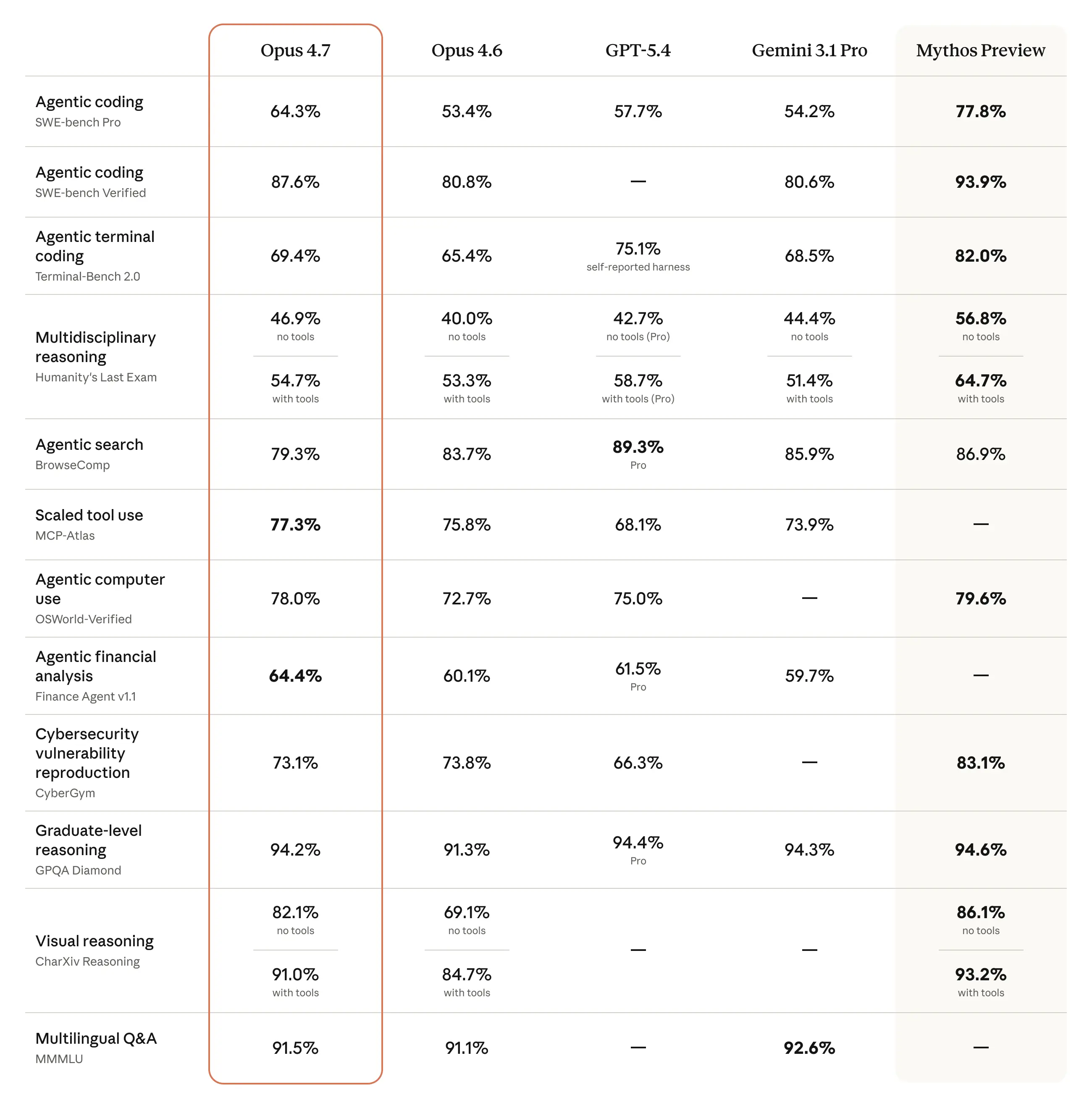
3.1 软件工程能力基准测试
软件工程能力是衡量LLM实用价值的核心指标之一。Claude Opus 4.7在这一领域实现了跨越式进步,多项基准测试成绩刷新了公开可用模型的记录。
SWE-bench系列测试是当前最具权威性的代码Agent评估标准。该基准测试要求模型解决来自真实GitHub仓库的实际issue——模型需要理解问题描述、探索代码库、定位bug根源、编写修复代码并通过测试验证。
| 模型 | SWE-bench Verified | SWE-bench Pro | 较上一代提升 |
|---|---|---|---|
| Claude Mythos Preview | 93.9% | 77.8% | - |
| Claude Opus 4.7 | 87.6% | 64.3% | +6.8% / +10.9% |
| Claude Opus 4.6 | 80.8% | 53.4% | - |
| GPT-5.4 | - | 57.7% | - |
| Gemini 3.1 Pro | 80.6% | 54.2% | - |
上表数据清晰展示了Opus 4.7的领先地位。在SWE-bench Verified(包含500个经过人工验证的GitHub issue)上,87.6%的成绩使Opus 4.7成为目前公开可用模型中的最强者。而在难度更高的SWE-bench Pro(跨多语言、多框架的真实工程任务)上,64.3%的成绩不仅大幅领先竞品,更较自身前代提升超过10个百分点——这在基准测试趋于饱和的背景下尤为难得。
从Partner反馈来看,这种提升具有真实的工程意义:
- Rakuten报告:生产任务解决量是4.6版本的3倍
- Databricks报告:基于源文档的代码生成错误率降低21%
- Cursor报告:CursorBench成绩从58%跃升至70%
- GitHub报告:93项内部编码任务完成率提升13%,其中4项任务是前代模型完全无法解决的
这些数据表明,Opus 4.7的改进并非仅针对基准测试的"过拟合",而是真正提升了处理复杂、长期、多步骤工程任务的能力。
3.2 推理与知识能力评估
在通用推理和知识问答方面,Opus 4.7同样表现出色,但与竞品的差距不如软件工程领域显著。这反映了当前顶尖模型在通用认知能力上正趋于收敛。
GPQA Diamond测试要求模型回答博士级别的科学问题(涵盖物理、化学、生物学),是衡量模型深度推理能力的金标准。
| 模型 | GPQA Diamond | 排名 |
|---|---|---|
| Claude Mythos Preview | 94.6% | 1 |
| GPT-5.4 Pro | 94.4% | 2 |
| Gemini 3.1 Pro | 94.3% | 3 |
| Claude Opus 4.7 | 94.2% | 4 |
| Claude Opus 4.6 | 91.3% | - |
上表显示,顶尖模型在GPQA Diamond上的差距已缩小至0.4个百分点以内。Opus 4.7的94.2%成绩较4.6版本提升2.9个百分点,表明其科学推理能力确有进步,但整体上这一维度已进入能力饱和区。
**Humanity’s Last Exam (HLE)**是更为严苛的综合性测试,覆盖人类知识前沿。在无工具条件下,Opus 4.7取得46.9%的成绩,领先Gemini 3.1 Pro(44.4%)但落后于GPT-5.4 Pro(42.7%需核实)。在可使用工具条件下,Opus 4.7达到54.7%,接近GPT-5.4 Pro的58.7%。
这些数据揭示了一个重要趋势:模型间的竞争已从"通用能力"转向"特定领域专精"。Opus 4.7选择在软件工程和Agentic能力上建立差异化优势,而非追求在所有基准上全面领先。
3.3 多模态与视觉理解测试
视觉能力的评估是Opus 4.7的另一大亮点。除分辨率提升外,模型在多项视觉推理基准上实现了突破性进展。
CharXiv基准测试要求模型阅读和理解科学论文中的复杂图表(如散点图、曲线图、流程图等)。
| 模型 | CharXiv (无工具) | CharXiv (有工具) |
|---|---|---|
| Claude Mythos Preview | 86.1% | 93.2% |
| Claude Opus 4.7 | 82.1% | 91.0% |
| Claude Opus 4.6 | 69.1% | 84.7% |
在无工具条件下,Opus 4.7较4.6版本提升13个百分点,是有记录以来单代最大增幅。这一飞跃直接归因于视觉分辨率的提升——高分辨率使模型能够识别图表中的细微标记、数值标签和数据点分布。
XBOW视觉敏锐度测试是网络安全公司XBOW设计的专用基准,评估模型在自主渗透测试中读取界面截图的能力。Opus 4.7在这一测试中从4.6版本的54.5%飙升至98.5%,实现了近乎完美的视觉识别能力。这意味着模型在计算机视觉Agent应用中能够精确识别UI元素、按钮、表单字段和文本内容。
OSWorld-Verified测试评估模型在真实桌面环境中完成操作任务的能力(如点击、导航、填写表单等)。Opus 4.7取得78.0%的成绩,较4.6版本(72.7%)提升5.3个百分点,仅次于Mythos Preview(79.6%)并领先GPT-5.4(75.0%)。结合三倍分辨率的视觉升级,这标志着计算机使用Agent(Computer-Use Agent)进入实用化阶段。
3.4 工具使用与Agentic能力对比
工具使用和Agentic编排能力是Opus 4.7建立竞争优势的关键领域。以下是关键基准的对比:
| 基准测试 | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| MCP-Atlas (规模化工具使用) | 77.3% | 75.8% | 68.1% | 73.9% |
| Finance Agent v1.1 | 64.4% | 60.1% | 61.5% | 59.7% |
| OSWorld-Verified | 78.0% | 72.7% | 75.0% | - |
| BrowseComp (Agent搜索) | 79.3% | 83.7% | 89.3% | 85.9% |
上表揭示了Opus 4.7的工具使用优势及其局限性。在MCP-Atlas和Finance Agent等多步骤工具调用场景中,Opus 4.7均处于领先地位。然而,在BrowseComp(多步骤网页搜索与信息合成)基准上,Opus 4.7反而较4.6版本下降4.4个百分点,落后于GPT-5.4(89.3%)和Gemini 3.1 Pro(85.9%)。
这一"倒退"现象值得深入分析。Anthropic官方解释称,这是由于模型在BrowseComp测试所依赖的网页浏览行为模式上进行了调整,可能是安全机制增强或浏览策略优化的副作用。对于依赖大量网页搜索的应用场景,开发者可能需要考虑模型路由策略——将搜索密集型任务分配给GPT-5.4,将代码密集型任务分配给Opus 4.7。
3.5 综合竞争力分析
综合所有基准测试结果,Claude Opus 4.7在2026年4月的公开可用模型中确立了独特定位:
优势领域:
- 软件工程与代码生成(SWE-bench系列领先)
- 工具使用与多步骤编排(MCP-Atlas领先)
- 视觉理解与计算机使用Agent(分辨率三倍提升)
- 金融分析与专业领域任务(Finance Agent领先)
相对劣势:
- 多步骤网页搜索(BrowseComp落后)
- 多语言问答(MMMLU略低于Gemini)
- 纯推理能力(GPQA Diamond与其他顶级模型持平)
定价与可及性:Opus 4.7保持了与前代相同的定价——每百万输入tokens $5,每百万输出tokens $25。但需注意,新版本采用了更新的分词器(tokenizer),相同内容的token数量可能增加1.0至1.35倍,实际使用成本可能略有上升。
4. 安全架构与伦理设计
4.1 网络安全防护机制
Claude Opus 4.7是Anthropic首款内置生产级网络安全防护机制的公开发布模型。这一设计直接关联到Project Glasswing——Anthropic为管理前沿AI网络安全风险而建立的安全框架。
核心安全特性包括:
自动网络安全请求检测:模型内置分类器,能够识别用户输入中暗示高风险网络安全活动(如漏洞利用、恶意代码生成、系统入侵指导等)的模式。当检测到此类请求时,模型会自动拒绝并提供替代建议。
差异化能力削减:在训练阶段,Anthropic有意识地降低了Opus 4.7在进攻性网络安全领域的能力,相对于未受限的Mythos Preview模型。这种"差异化训练"策略确保公开发布模型不会成为网络攻击的便利工具。
Cyber Verification Program:对于从事合法网络安全研究的专家(如渗透测试人员、红队成员、漏洞研究员),Anthropic设立了专门的验证计划。通过申请和审核的研究人员可以获得访问限制较少模型版本的权限,以支持防御性安全研究。
这种分层安全架构体现了Anthropic的"能力-安全"平衡哲学:既不完全阉割模型的有用能力,也不放任潜在滥用风险。
4.2 对齐与价值观训练
Opus 4.7的价值观对齐训练延续了Anthropic的Constitutional AI方法。该方法通过一套预设原则(“宪法”)指导模型行为,而非仅依赖人工标注的偏好数据。
Constitutional AI的核心流程包括两个阶段:
-
自我批评阶段:模型生成初始回答后,被要求根据"宪法"原则评估自身输出,识别潜在的有害、偏见或不诚实内容,并生成改进版本。
-
强化学习阶段:通过RLHF(Reinforcement Learning from Human Feedback)变体——RLAIF(Reinforcement Learning from AI Feedback),使用AI生成的偏好数据训练模型,使其输出更贴近"宪法"原则。
Opus 4.7的"宪法"涵盖了诚实性、无害性、有益性三大维度,并针对特定场景(如医疗建议、法律信息、心理健康支持)设置了细化规则。Anthropic发布的系统卡显示,Opus 4.7在整体对齐行为上较4.6版本略有提升,特别是在诚实性和抗提示注入攻击方面。
4.3 提示注入攻击防御
提示注入(Prompt Injection)攻击是LLM面临的主要安全威胁之一,攻击者通过在输入中嵌入恶意指令,试图覆盖系统提示或诱导模型执行非预期操作。
Opus 4.7采用了多层防御策略应对这一威胁:
输入净化层:在模型处理之前,输入文本经过启发式过滤器和基于分类器的检测系统,识别常见的注入模式(如分隔符注入、角色扮演注入、编码混淆等)。
上下文隔离机制:系统提示(system prompt)与用户输入在内部表示中保持更强的隔离性,降低用户输入覆盖系统指令的可能性。
意图识别增强:模型被训练为更准确地识别用户请求的真实意图,即使面对试图混淆或操纵的输入也能保持正确理解。
评估数据显示,Opus 4.7对提示注入攻击的抵抗力较4.6版本有所提升,但仍未达到完美水平。这提示开发者在构建Agent系统时,仍需采用最小权限原则,限制模型可执行操作的范围。
4.4 透明度与可解释性设计
Anthropic长期致力于提升模型的可解释性。Opus 4.7引入了新的"推理努力等级"控制机制,允许用户在不同任务中选择不同的推理深度:
| 努力等级 | 适用场景 | 延迟 | 成本 | 推理深度 |
|---|---|---|---|---|
| low | 简单问答、快速响应 | 最低 | 最低 | 浅层推理 |
| medium | 常规任务、平衡选择 | 中等 | 中等 | 标准推理 |
| high | 复杂分析、代码审查 | 较高 | 较高 | 深度推理 |
| xhigh | 高难度工程、架构设计 | 高 | 高 | 最大推理 |
| max | 极限挑战、研究级问题 | 最高 | 最高 | 完整推理链 |
新增的"xhigh"等级位于传统"high"和"max"之间,提供了更细粒度的控制。在Claude Code中,xhigh已成为默认设置,平衡了响应质量与等待时间。
5. 应用场景与行业实践
5.1 软件工程与开发工作流
Claude Opus 4.7的旗舰应用场景是软件工程自动化。其改进的代码理解、生成和调试能力使其能够在复杂开发工作流中扮演多重角色:
代码审查与重构:模型可以分析大型代码库,识别代码异味(code smells)、潜在bug和架构设计缺陷。Claude Code的"/ultrareview"功能专门针对深度代码审查场景,能够发现人工审查可能遗漏的边缘情况。
跨语言迁移与API升级:企业级开发常面临技术栈迁移或API版本升级的挑战。Opus 4.7能够处理涉及多个文件、跨多个提交(commits)的复杂重构任务,保持代码语义的一致性。
自动化测试生成:基于代码上下文,模型可以生成针对性的单元测试、集成测试用例,甚至识别测试覆盖率的盲点。
调试与根因分析:面对复杂错误日志和异常堆栈,Opus 4.7能够追踪问题根源,提出修复方案并验证修复的有效性。
Partner案例研究:
- Rakuten:报告生产任务解决量是4.6版本的3倍,特别是在处理遗留代码库和复杂集成场景时表现出色。
- Box:响应速度提升24%,模型调用次数减少56%,表明每次交互的效率显著提升。
- CodeRabbit:代码审查召回率提升10%,漏检的潜在问题大幅减少。
5.2 法律与合规文档分析
法律行业对文档分析的准确性和一致性有极高要求。Opus 4.7在BigLaw Bench(法律专业基准测试)上取得了90.9%的成绩(high effort设置),展示了其在法律领域的应用潜力。
典型应用场景包括:
合同审查:模型可以系统性地审查合同条款,识别不利条款、风险点和合规缺口,生成审查摘要和修改建议。
法律研究:通过分析判例法、法规和学术文献,辅助法律研究人员快速定位相关判例、理解法律原理和构建论证逻辑。
合规检查:对照监管要求审查内部文档,识别潜在的合规风险,特别适用于金融、医疗等强监管行业。
尽职调查:在并购和投资场景中,快速梳理目标公司的法律文件,提取关键风险要素和承诺事项。
Partner反馈显示,Opus 4.7在"模糊编辑审查"和"表格推理"任务上表现尤为突出,这对于处理复杂法律表格和交叉引用文档具有重要价值。
5.3 金融分析与投研自动化
Opus 4.7在Finance Agent v1.1基准测试中领先,结合其多模态能力,为金融行业提供了强大的分析工具:
财报分析:模型可以阅读并理解公司年报、季度财报,提取关键财务指标,分析趋势变化,并与同行业公司进行横向对比。
研究报告生成:基于市场数据、新闻资讯和财务信息,自动生成结构化的投资研究报告,包括估值分析、风险评估和投资建议。
风险建模支持:协助风险分析师构建和验证风险模型,解释模型假设,识别潜在的模型风险。
合规披露审查:确保财务披露文档符合监管要求,识别可能误导投资者的不当表述。
金融行业对信息准确性和归因要求极高。Opus 4.7改进的"披露纪律"(disclosure discipline)——即准确引用来源、区分事实与推论的能力——使其在这一领域具有独特优势。
5.4 生命科学专利与文献研究
生命科学领域的研究涉及大量专业文献、专利文档和复杂图表。Opus 4.7的高分辨率视觉理解和专业推理能力使其成为这一领域的有力助手:
专利分析:解读生物技术、制药领域的专利文档,分析权利要求范围,识别潜在的侵权风险或研发机会。
化学结构理解:通过视觉输入理解化学分子结构图、蛋白质折叠图等复杂科学图示。
文献综述:快速梳理特定研究主题的学术文献,识别研究趋势、技术演进路径和知识空白。
实验设计建议:基于文献分析,为实验设计提供参考,识别可能的技术挑战和解决方案。
Solve Intelligence等生命科学领域Partner报告称,Opus 4.7在处理化学结构和技术图表方面相比前代有显著改进。
5.5 创意设计与UI/UX生成
尽管Opus系列并非专门的创意模型,但4.7版本在"设计品味"方面的提升引起了设计行业关注:
界面设计:基于需求描述生成UI设计草图、组件布局和交互流程建议。Lovable等Partner反馈称模型的设计选择"足够好以至于可以直接采用"。
演示文稿创建:从结构化内容生成专业质量的演示文稿,包括版式设计、图表建议和视觉层次组织。
文档格式化:自动将原始内容转换为专业格式的文档、报告或手册,确保视觉一致性和可读性。
品牌材料:协助创建品牌指南、营销材料的设计方案。
这一应用方向反映了LLM能力的边界拓展——从纯文本处理向视觉创意协作延伸。虽然专业设计师的主导地位不会被取代,但Opus 4.7可以显著提升设计流程的效率。
6. 使用指南与最佳实践
6.1 API接入与模型调用
Claude Opus 4.7通过标准API接口提供服务,模型标识符为claude-opus-4-7。开发者可通过Anthropic API、Amazon Bedrock、Google Cloud Vertex AI或Microsoft Foundry访问。
基础API调用示例(Python):
import anthropic
client = anthropic.Anthropic(api_key="your-api-key")
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[
{"role": "user", "content": "请分析以下Python代码的潜在问题..."}
]
)
print(response.content[0].text)
6.2 提示词工程优化策略
Opus 4.7的一个重要行为变化是指令遵循的精确性提升。与4.6版本相比,4.7更倾向于严格按照提示词的字面意思执行,而非过度解读或"善意地"忽略部分指令。
这一变化对提示词设计提出了新要求:
明确性原则:提示词应尽可能明确、具体,避免模糊表述。如果需要模型执行多步骤任务,应清晰列出步骤顺序。
结构化提示:使用Markdown格式、编号列表、代码块等结构化元素组织提示词,帮助模型准确理解任务结构。
上下文完整性:对于复杂任务,提供充足的背景信息,包括相关代码片段、文档内容或之前的对话历史。
角色定义:在系统提示(system prompt)中明确模型角色和任务边界,例如:“你是一位资深的Python代码审查专家,专注于发现安全漏洞和性能问题。”
示例驱动的少样本学习:对于格式敏感的任务,提供输入-输出示例(few-shot examples)有助于模型快速对齐预期格式。
系统提示词模板示例:
你是一个专业的软件架构审查助手。你的职责是:
1. 分析代码的结构设计,识别违反SOLID原则的模式
2. 评估模块间的耦合度,提出解耦建议
3. 检查异常处理和安全边界
4. 评估性能关键路径的实现
输出格式要求:
- 按优先级(高/中/低)分类发现的问题
- 对每个问题提供:位置、描述、建议修复方案、参考最佳实践
- 最后提供整体架构评分(1-10)和关键改进建议
审查标准参考:
- Clean Architecture原则
- Google Python Style Guide
- OWASP安全编码规范
6.3 代码开发工作流集成
Claude Code是Anthropic专为开发者设计的桌面端Agent环境,Opus 4.7作为默认模型提供了深度集成体验。
常用命令:
/ultrareview:触发深度代码审查模式,模型会以更高的仔细度扫描代码,标记潜在bug和设计缺陷/compact:压缩当前对话历史,保留关键上下文的同时释放token配额/clear:清空当前会话的上下文缓存
文件系统记忆:Opus 4.7支持跨会话的文件系统记忆功能。模型会记住项目结构、关键文件内容和开发约定,在后续会话中保持上下文连贯性。
与IDE集成:Opus 4.7已原生集成至主流开发工具:
- GitHub Copilot:作为可选的"智能代理"模型
- Cursor:深度集成,支持代码补全、重构和解释
- Cognition Devin:作为底层推理引擎
- Warp终端:支持自然语言命令转换
最佳实践建议:
- 为复杂任务启用
xhigh或max努力等级,虽然会增加延迟和成本,但能显著提升任务完成质量 - 对于长期项目,建立一致的文件组织约定,帮助模型维护上下文记忆
- 在多文件修改任务中,要求模型先生成变更计划,确认后再执行,避免大规模回滚
- 善用
/ultrareview进行关键代码的审查把关
6.4 多模态任务处理技巧
Opus 4.7的高分辨率视觉能力为多种多模态应用场景打开了新可能。
图像输入API示例:
import anthropic
import base64
client = anthropic.Anthropic()
# 读取图像并编码
with open("screenshot.png", "rb") as f:
image_data = base64.b64encode(f.read()).decode()
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_data
}
},
{
"type": "text",
"text": "请分析这个UI界面截图,指出设计问题并提出改进建议。"
}
]
}
]
)
视觉任务优化建议:
-
分辨率管理:模型会自动处理高分辨率图像,但会消耗更多token。如果不需要解析细小文字,可在上传前适当压缩图像以节省成本。
-
上下文提示:对于复杂图表,在提示词中说明需要关注的关键要素,例如"重点关注2024年Q3的数据趋势和异常点"。
-
多图对比:对于需要对比分析的场景(如UI前后版本对比),将多张图像同时传入有助于模型进行关联分析。
-
图表解读技巧:对于数据图表,要求模型先描述观察到的模式,再提供分析结论,这种"观察-分析"两步走策略能提升准确性。
6.5 成本控制与性能优化
Opus 4.7的定价为每百万输入tokens $5、输出tokens $25,虽然与4.6持平,但新分词器可能导致相同内容的token数量增加10%-35%。以下是成本控制策略:
分层模型策略:
| 任务类型 | 推荐模型 | 成本效益 | 适用场景 |
|---|---|---|---|
| 简单问答/分类 | Haiku系列 | 最低 | 高吞吐量场景、初步筛选 |
| 常规开发任务 | Sonnet系列 | 中等 | 日常编码、文档生成 |
| 复杂工程/架构 | Opus 4.7 | 最高 | 关键任务、深度分析 |
上下文压缩:定期使用/compact命令或手动总结历史对话,移除不必要的上下文累积。
任务预算设置:利用API的task_budget参数(beta功能)为多步骤任务设置token上限,防止意外的高成本消耗。
缓存策略:对于重复性查询(如常见代码模式、标准文档),在应用层实现响应缓存,避免重复调用API。
批量处理:对于大量相似任务(如批量代码审查),使用批量API(batch API)或并行请求以提高吞吐量。
7. 未来展望与技术演进
7.1 Claude系列的技术路线图
Anthropic的模型发布节奏显示出清晰的战略规划。从2025年11月的Opus 4.5、2026年2月的4.6到4月的4.7,约每两个月一次的迭代频率表明其拥有成熟的模型训练流水线。
展望2026年下半年及以后,以下趋势值得关注:
Mythos系列的逐步解禁:Opus 4.7作为"安全测试平台"的角色暗示,Mythos Preview或其后继版本将在安全防护机制验证通过后逐步开放。这可能带来新一轮的能力跃升,尤其是在网络安全防御、高级代码分析等领域。
上下文窗口的持续扩展:虽然Opus 4.7已支持百万token上下文,但检索精度和推理一致性仍有提升空间。未来版本可能在长上下文压缩、分层记忆和动态注意力方面进一步优化。
多模态能力的深度融合:当前视觉能力主要集中于静态图像理解,未来可能向视频分析、3D场景理解、实时视觉交互等方向延伸。
Agentic自主性的增强:从当前的工具使用到真正的自主规划、资源调度和目标分解,Agentic能力还有巨大的发展空间。
7.2 行业竞争格局演变
Opus 4.7的发布重塑了高端LLM市场的竞争格局。与GPT-5.4和Gemini 3.1 Pro相比,各家的差异化策略日益清晰:
Anthropic:专注软件工程Agent和深度代码理解,通过Claude Code等产品建立开发者生态护城河。
OpenAI:维持通用能力的全面领先,在消费级产品和企业API之间寻找平衡,搜索和知识整合能力仍是其优势。
Google:依托搜索和Android生态,在多语言处理、移动设备集成和实时信息获取方面保持竞争力。
这一格局对开发者和企业用户意味着:单一模型难以满足所有需求,多模型路由和任务编排将成为复杂AI系统的标准架构。
7.3 AI安全与监管的协同演进
Opus 4.7的安全架构设计反映了AI行业在快速发展中面临的监管压力。随着各国AI监管框架的完善(如欧盟AI Act的实施),模型的安全性和可控性将成为市场准入的重要条件。
Anthropic的"分层释放"策略——区分公开模型和受控模型——可能成为行业范式。这种机制既满足了研究和创新的需求,又建立了风险管控的缓冲区。
网络安全防护机制的引入也标志着AI安全从"被动响应"向"主动防御"的转变。未来模型可能内置更复杂的伦理推理能力,能够自主评估请求的潜在风险并做出恰当回应。
7.4 开发者生态与工具链发展
Opus 4.7的生态系统建设值得关注。MCP(Model Context Protocol)的标准化推动了工具生态的繁荣,大量第三方工具和服务正在集成MCP接口。
预计2026-2027年将出现以下趋势:
专业化Agent框架:针对特定领域(如DevOps、数据分析、法律研究)的专业化Agent框架将涌现,这些框架将Opus 4.7作为底层推理引擎,提供领域特定的工具集和工作流模板。
多Agent协作系统:从单一Agent到多Agent协作的架构演进。不同Agent负责不同子任务,通过标准化协议协调工作,Opus 4.7可作为"总控Agent"协调整个系统。
边缘部署与混合架构:随着模型压缩和蒸馏技术的进步,轻量级模型在边缘设备上的部署将更普遍,Opus 4.7等高端模型则负责云端复杂推理,形成"边缘-云端"混合架构。
8. 结论
Claude Opus 4.7代表了大型语言模型从"语言理解工具"向"自主智能代理"演进的关键里程碑。本文从技术架构、性能基准、应用场景等多个维度对其进行了系统性分析,得出以下主要结论:
第一,Agentic能力的实质性突破。Opus 4.7在SWE-bench Pro、MCP-Atlas等关键Agentic基准上的领先成绩,标志着LLM已具备处理复杂、长期、多步骤工程任务的能力。这种能力不再局限于实验室环境,而是正在Rakuten、Box、Databricks等企业生产环境中创造实际价值。
第二,多模态融合的技术飞跃。视觉分辨率三倍提升和CharXiv基准13个百分点的跃升,使Opus 4.7成为处理复杂视觉任务的可靠选择。计算机视觉Agent正从概念验证走向实用部署。
第三,安全与能力的平衡探索。内置网络安全防护机制和Cyber Verification Program的设立,展示了Anthropic在追求能力边界的同时对安全风险的审慎态度。这种"分层释放"策略可能成为高风险AI能力管理的行业范式。
第四,差异化竞争格局的形成。Opus 4.7并非追求全面领先,而是在软件工程、工具使用等核心领域建立深度优势。对于开发者和技术团队而言,理解各模型的能力边界和最佳应用场景,构建多模型协作架构,将是最大化AI价值的关键。
展望未来,随着Mythos系列的可能解禁、Agentic生态的持续繁荣以及多模态能力的进一步融合,以Opus 4.7为代表的先进模型将继续推动AI技术向更自主、更可靠、更安全的方向发展。对于技术从业者而言,深入理解这些模型的技术原理和最佳实践,将是把握AI时代机遇的重要基础。
参考文献
[1] Anthropic. Claude Opus 4.7 Model Card and System Card. 2026-04-16. https://www.anthropic.com/news/claude-opus-4-7
[2] SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770. https://arxiv.org/abs/2310.06770
[3] Jimenez, C. et al. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? In Proceedings of the 12th International Conference on Learning Representations (ICLR), 2024.
[4] GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv:2311.12022. https://arxiv.org/abs/2311.12022
[5] Humanity’s Last Exam (HLE) Benchmark. Center for AI Safety, 2025. https://lastexam.ai/
[6] OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. arXiv:2404.07972. https://arxiv.org/abs/2404.07972
[7] CharXiv: Evaluating Multimodal LLMs on Scientific Figure Comprehension. arXiv:2406.02013. https://arxiv.org/abs/2406.02013
[8] MCP-Atlas: Measuring Scaled Tool Use in Language Models. Anthropic Technical Report, 2026.
[9] Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073. https://arxiv.org/abs/2212.08073
[10] Vaswani, A. et al. Attention Is All You Need. In Advances in Neural Information Processing Systems, 2017.
[11] Anthropic. Project Glasswing: Responsible Scaling for Cybersecurity-Capable AI. 2026. https://www.anthropic.com/news/project-glasswing
[12] The Verge. Anthropic’s Claude Opus 4.7 focuses on coding and agentic tasks. 2026-04-16. https://www.theverge.com/ai-artificial-intelligence/anthropic-claude-opus-4-7
[13] Vellum AI. Claude Opus 4.7 Benchmarks Explained. 2026-04-16. https://www.vellum.ai/blog/claude-opus-4-7-benchmarks-explained
[14] Digital Applied. Claude Opus 4.7 vs GPT-5.4: Agentic Coding Compared. 2026-04-17. https://www.digitalapplied.com/blog/claude-opus-4-7-vs-gpt-5-4-agentic-coding
[15] DataLearner. Claude Opus 4.7 深度评测. 2026-04-17. https://www.datalearner.com/en/ai-models/pretrained-models/claude-opus-4-7/analysis
[16] AIGCBAR镜像站(国内使用入口). https://chat.aigc.bar/list/#/register?inviter=0L54LA
本文撰写于2026年4月,基于Claude Opus 4.7发布时的公开技术资料。随着技术快速发展,部分信息可能随时间变化,建议读者关注官方渠道获取最新动态。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 48
48 0
0- 0



 已为社区贡献162条内容
已为社区贡献162条内容

所有评论(0)