Python: 基于ResU-Net的颈动脉超声图像分割算法研究
0 引言
心血管疾病是全球范围内导致死亡和残疾的主要原因之一[1]。颈动脉作为连接心脏与大脑的关键血管,其健康状况直接反映了全身动脉粥样硬化的程度[2]。通过颈动脉超声图像评估颈动脉内中膜厚度(Intima-Media Thickness, IMT)及斑块负荷,是临床早期诊断脑卒中风险、冠心病风险以及评估治疗效果的重要手段[3-4]。然而,准确地将颈动脉结构从超声图像中分割出来,是进行上述量化分析的前提与步骤。
近年来,以深度学习为代表的卷积神经网络(Convolutional Neural Network, CNN)技术在医学图像分割领域取得了突破性进展[5-6]。其中,U-Net及其变体凭借其对称的编码器-解码器结构和跳跃连接,能够有效融合浅层位置信息与深层语义信息,成为医学图像分割的主流框架[7]。然而,标准U-Net在处理复杂超声图像时仍面临挑战:随着网络深度增加,容易出现梯度消失或退化问题,导致网络难以充分提取颈动脉超声图像中微妙的边界特征和细节信息。
为解决上述问题,本文提出了一种基于ResU-Net模型[8]的颈动脉超声图像分割算法。Res-UNet通过引入残差模块替代U-Net中的普通卷积块,使得网络能够更有效地学习从噪声背景中分离出颈动脉结构。实验结果表明,本文所提算法能够实现更精确、稳定的颈动脉区域分割,为后续的临床定量分析与自动化诊断提供了可靠的技术支持。
目录
1 数据
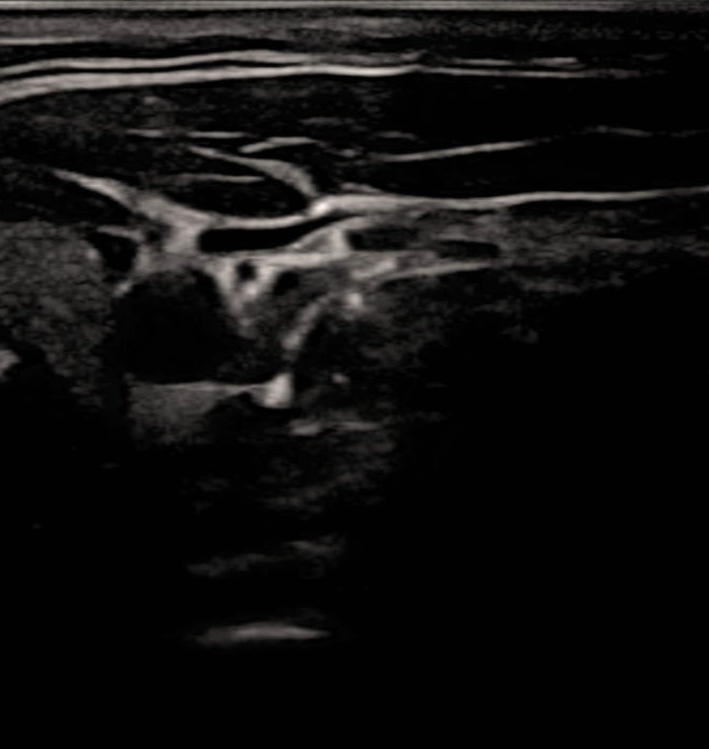
本文实验所用颈动脉超声图像均来源于Kaggle公开平台,该数据集共包含2200张高质量超声图像,数据采集自11名不同受试者,每名受试者均完成至少双侧颈部(左右两个部位)的超声检查,数据集整体分为两个文件夹,其中超声图像文件夹包含1100张图像,每名受试者对应采集100张颈动脉超声图像,为分割任务提供原始输入数据,专家标注掩码文件夹包含1100张掩码图像,该类掩码由专业技术人员制作,并经临床专家审核验证,可作为颈动脉分割任务的标准参考标签,为模型训练与性能评估提供依据;所有超声图像均采用Mindary UMT-500Plus超声机搭配L13-3s线性探针拍摄采集,在11名受试者中,2人采用血管法进行超声检查,8人采用颈动脉法完成检查,原始采集的时间序列DICOM格式图像经预处理转换为PNG格式,该数据集图像基本特征为:分辨率709×749×3(RGB三通道彩色图像),存储格式为PNG,数据量总计2200张(含1100张原始超声图像、1100张专家标注掩码)。如图1和图2所示,一名受试者的原始超声图像和对应的掩码。
数据连接:Carotid Ultrasound Images

2 Res-UNet模型
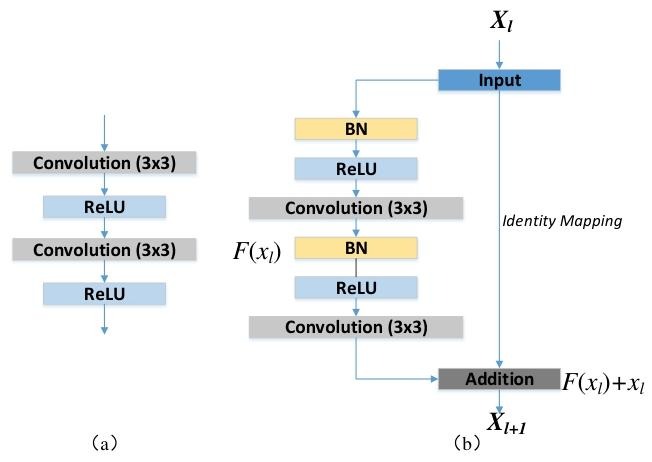
Zhang等人[8]将残差连接与U-Net结构融合,提出ResU-Net模型,用于高分辨率遥感图像中的道路区域分割。主要是用残差单元替换 U-Net 普通卷积块,解决深层网络训练难、梯度消失问题,同时保留 U-Net 跳跃连接的多尺度信息融合优势。如图3所示,图 (a)为普通卷积单元(U-Net 原始结构),结构为:输入 → 3×3 Conv → ReLU → 3×3 Conv → ReLU → 输出,这种结构简单,随着网络加深,容易出现梯度消失和爆炸,导致深层参数更新缓慢甚至无法收敛;且信息只能单向传递,容易丢失底层细节特征。图 (b)为预激活残差单元(ResU-Net 核心模块),结构为:输入→BN → ReLU → 3×3 Conv → BN → ReLU → 3×3 Conv → 得到 F(Xₗ);F(Xₗ) + Xₗ → 输出。其公式如下:
其中,是残差块输入,
是残差函数(卷积层学习的特征),
是恒等映射(直接传递输入信息),
是激活函数。相比原始结构,进一步增加了BN层,即为批量归一化(Batch Normalization,BN)。BN层的核心思想是对每一批次的数据进行归一化处理[9]。具体步骤如下:
(1)计算均值和方差:
其中, 是批次大小,
是第
个样本的特征向量,
是批次的均值,
是批次的方差。
(2)标准化:
这里,是一个小的常数(通常设为
),用于防止除零错误。
是标准化后的特征值。
(3)缩放和平移:
其中,(偏移因子:用于调整数据的位置)和
(缩放因子:用于恢复数据的尺度)是可学习的参数,分别用于缩放和偏移归一化后的数据。
总的来说,预激活残差单元相比普通卷积单元来说,起着缓解梯度消失,保留原始特征,避免卷积丢失细节作用。
3 实验设置
3.1 数据预处理
实验采用颈动脉超声图像数据集(第1节所叙述),包含超声原图与标注的掩码。图像与标签按文件名一一对应,数据总量为1100名受试者。按照 8:2 比例随机划分为训练集与测试集,保证数据分布一致。数据预处理流程如下:(1)读取超声图像,将像素值归一化至 [0,1];(2)分割标签采用灰度图读取,将前景像素值 255 映射为 1,背景为 0,构建二分类标签;(3)将图像与标签转换为张量格式,并调整通道顺序以适配 PyTorch 输入格式。
3.2 网络结构
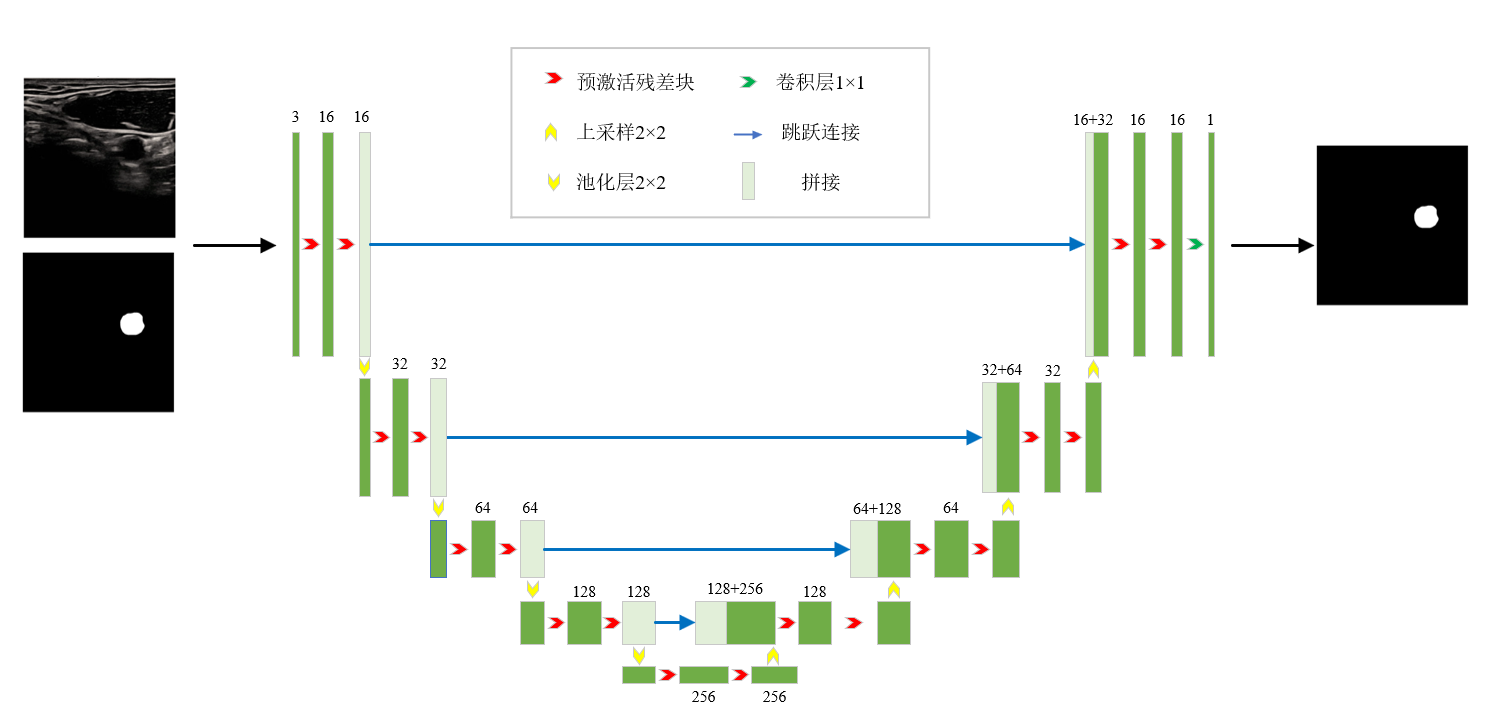
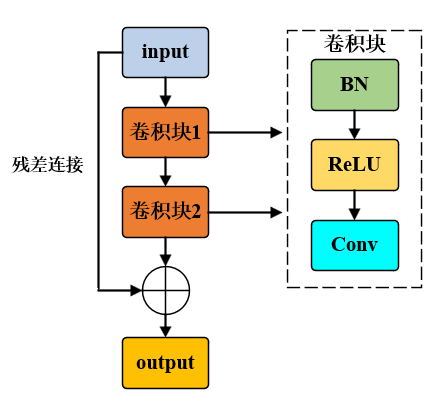
本实验采用改进的残差 U-Net(ResU-Net)模型,以经典 U-Net 为基础架构,将原始双卷积块替 换为预激活残差卷积块。网络包含编码器、解码器与跳跃连接三部分。编码器通过 4 次下采样逐步提取多尺度深层特征,解码器通过 4 次上采样逐步恢复分辨率,并通过跳跃连接融合底层细节信息。网络结构详见图5。核心残差块如图6所示,遵循BN→ReLU→Conv→BN→ReLU→Conv 的预激活结构,并引入残差连接缓解梯度消失,提升网络训练稳定性。实现颈动脉超声图像分割任务。
3.3 实验参数
ResU-Net模型的训练批次大小为 4,共训练 50 轮,采用 AdamW 优化器,初始学习率为 1×10⁻⁴,学习率随余弦退火策略动态调整。损失函数采用交叉熵损失与 Dice 损失的混合函数,以提升目标分割效果。定义如下[6]:
其中,交叉熵损失计算公式为:
Dice损失用于缓解类别不平衡,其公式为:
其中,pred 为模型预测的分割结果集合;true 为金标准(真实标注)的分割结果集合;∣pred∩true∣ 为预测与真实区域的交集像素数;∣pred∣+∣true∣ 为预测与真实区域的总像素数之和。
评价指标包括 Dice、IoU、精确率、召回率与 F1 分数。分别定义如下[10-11]:
其中,A:模型预测的分割区域集合;B:真实标注(金标准)的分割区域集合;TP(True Positive):真正例,预测为正、实际为正的样本数;FP(False Positive):假正例,预测为正、实际为负的样本数;FN(False Negative):假负例,预测为负、实际为正的样本数。
4 实验结果与讨论
4.1 训练损失曲线
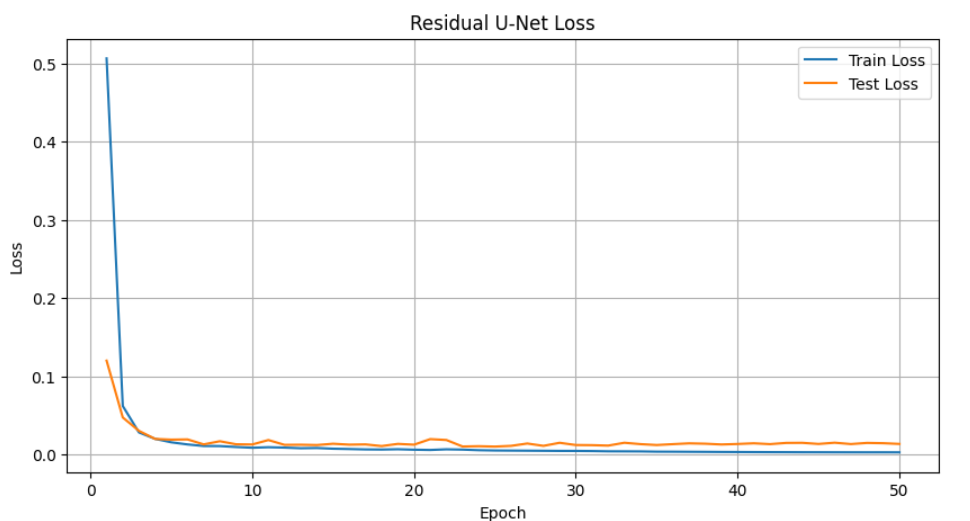
如图7所示,ResU-Net 模型的训练损失曲线整体表现出较好的收敛状态:训练损失与测试损失在前 5 个 epoch 内均快速下降,随后趋于稳定并最终维持在接近 0 的水平,且两条曲线全程基本贴合,未出现明显分离或测试损失反弹现象,表明模型收敛速度快、拟合充分且未发生过拟合,展现出良好的泛化能力,训练过程稳定有效。
4.2 定量分析结果
如表1所示, 在与先前的工作 ConvNeXt-Transformer 模型的对比中,本文提出的 ResU-Net 在各项指标上均展现出优势:其 Dice 系数、IoU、Precision 及 F1 分数分别达到 0.9525、0.9104、0.9732 和 0.9525,均优于对比模型,仅 Recall 指标略低 0.0069,表明 ResU-Net 不仅分割精度更高,且在预测时假阳性更少,对目标区域的识别更为精准,整体性能优于 ConvNeXt-Transformer,验证了残差结构在颈动脉超声图像分割任务中的有效性。

4.3 可视化结果
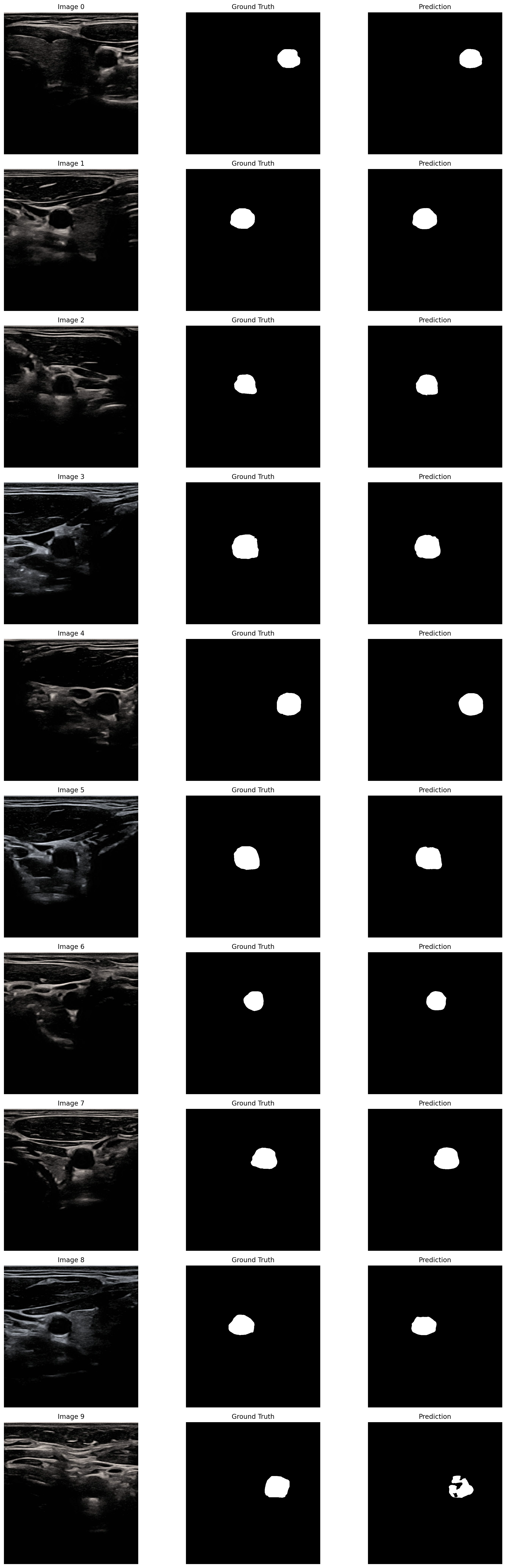
如图7所示,从定性分割结果来看,ResU-Net 在绝大多数颈动脉超声图像中都能预测目标区域的轮廓与位置,预测掩码与真实标签吻合,对边界的捕捉清晰完整;仅在第 9 张图像中,模型预测出现了少量孔洞与边缘偏差,整体而言,该模型对颈动脉目标区域的识别能力强,分割结果稳定可靠,验证了其在医学超声图像分割任务中的有效性。
本文提出的 ResU-Net 模型在颈动脉超声图像分割任务中展现出优异的性能,定量指标与定性结果均验证了其有效性。与 ConvNeXt-Transformer 模型相比,ResU-Net 在 Dice 系数、IoU、Precision 及 F1 分数上均取得了更优表现,说明残差结构的引入有效缓解了深层网络训练过程中的梯度消失问题。然而,存在一定局限性:首先,在少数边缘复杂或图像质量较差的样本中,模型预测仍出现少量孔洞与边缘偏差,这可能与超声图像的噪声干扰等有关,后续可通过引入注意力机制或多尺度特征融合策略进一步提升边界分割精度;其次,研究仅在颈动脉超声数据集上进行了验证,模型在其他模态或其他解剖结构分割任务中的泛化能力仍需进一步验证。
参考
[1] Ibrahim B, Jafari R. Cuffless blood pressure monitoring from an array of wrist bio-impedance sensors using subject-specific regression models: Proof of concept[J]. IEEE transactions on biomedical circuits and systems, 2019, 13(6): 1723-1735.
[2] 马祎欣,杨雅博,徐胜军,等.基于超声超高帧率时空滤波图像的颈动脉血管壁运动追踪[J].生物医学工程研究,2021,40(04):366-372.
[3] 基于 Savitzky-Golay滤波器的超声图像运动分析方法-CSDN博客
[4] 王琨.基于超声图像的人体颈动脉管壁内中膜分割及其运动估计研究[D].云南大学,2022.
[5] 曹步勇.基于卷积神经网络与活动轮廓模型的脑组织影像分割方法研究[D].齐鲁工业大学,2025.
[6] 基于 ConvNeXt-Transformer 的颈动脉超声图像分割算法研究-CSDN博客
[7] 孙超.基于改进U-Net的医学图像分割方法研究[D].南京信息工程大学,2025.
[8] Zhang Z, Liu Q, Wang Y. Road extraction by deep residual u-net[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(5): 749-753.
[9] 神经网络中BN(Batch Normalization)层的原理与作用 BN层计算公式详解_聚合数据
[10] 论文中常用的图像分割评价指标-附完整代码 - 知乎
[11] 基于EEGNet网络的脑电信号对阿尔茨海默与额颞叶痴呆的辅助诊断研究-CSDN博客
注:若有侵权部分,请留言将会删除。
个人观点 ,仅供参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)