英伟达Jetson Orin 运行Qwen大模型
Jetson Orin + CUDA12.6 + 64GB(内存显存共享)
参考官方
- 官方镜像仓库 (直接下载编译好的)
NVIDIA 官方维护了一个专门针对 Jetson 的 vLLM 镜像仓库,已经预编译好了 CUDA 和 TensorRT 加速。
镜像地址 (GitHub Container Registry):
ghcr.io/nvidia-ai-iot/vllm
标签说明:
latest-jetson-orin: 最新版,适配 Jetson Orin 系列。
latest-jetson-nano: 适配 Jetson Orin Nano。 - 官方文档与社区
NVIDIA Jetson AI Lab (核心资源):
这是 NVIDIA 专门为 Jetson 部署 AI 模型建立的实验室页面,里面有详细的 vLLM 部署指南。
地址: NVIDIA Jetson AI Lab - vLLM
官方论坛:
如果遇到报错,这里是全球开发者最活跃的地方。
地址: NVIDIA Developer Forums - Jetson Systems
加载模型方式比较
| 部署方式 | 易用性 | 性能潜力 | 资源控制 | 适用场景 |
|---|---|---|---|---|
| vLLM | 高 | 高 | 中 | 追求高性能、高并发的生产环境 |
| Ollama | 极高 | 中 | 低 | 快速上手、个人开发和原型验证 |
| llama.cpp | 中 | 中高 | 高 | 资源极度受限,需要精细调优 |
最终选择官方推荐的vllm
模型下载
模型不能用guff 的模型(注意哈)
在下载前,请先通过如下命令安装ModelScope
pip install modelscope
命令行下载
下载完整模型库
modelscope download --model Qwen/Qwen3.5-4B
最后下载到这里了
models/Qwen/Qwen3.5-4B-SJT
# 1. 升级 pip
echo "[1/5] 升级 pip..."
pip3 install --upgrade pip -q
# 2. 安装核心依赖
echo "[2/5] 安装 transformers 和加速库..."
pip3 install transformers accelerate bitsandbytes peft -q
echo "核心依赖安装完成"
# 3. 检查/安装 PyTorch (Jetson 专用)
echo "[3/5] 检查 PyTorch..."
if python3 -c "import torch; print(f'PyTorch {torch.__version__}')" 2>/dev/null; then
echo "PyTorch 已安装"
else
echo "安装 Jetson 专用 PyTorch..."
# Jetson Orin 需要从 NVIDIA 预编译包安装
pip3 install torch --index-url https://developer.download.nvidia.com/compute/redist/jp/v60/
fi
# 4. 下载模型
echo "[4/5] 下载 Qwen3.5 4B 模型..."
cd ~/models
# 模型名称
MODEL_NAME="Qwen/Qwen3.5-4B"
if [ -d "Qwen3.5-4B" ]; then
echo "模型已存在,跳过下载"
else
echo "使用 ModelScope 下载..."
pip3 install modelscope
python3 -c "from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3.5-4B', cache_dir='./')"
fi
针对vllm的jetson环境检查
nvcc: NVIDIA ® Cuda compiler driver
Copyright © 2005-2024 NVIDIA Corporation
Built on Wed_Aug_14_10:14:07_PDT_2024
Cuda compilation tools, release 12.6, V12.6.68
Build cuda_12.6.r12.6/compiler.34714021_0
检查项结果说明nvcc -VCUDA 12.6.68实际编译工具链版本nvidia-smiCUDA 12.6驱动支持的最高版本
关键发现:系统是 JetPack 5,这个内核版本明确表明你的 Jetson Orin 当前运行的是 JetPack 5.x 系列系统(L4TR35.x)。
cyber@ubuntu:~/models/Qwen$ uname -a
Linux ubuntu 5.15.148-tegra #1 SMP PREEMPT Thu Sep 18 15:08:33 PDT 2025 aarch64 aarch64 aarch64 GNU/Linux
请尝试使用以下专门为 JetPack 5 (L4T R35.x) 构建的镜像
镜像地址:
dustynv/vllm:r35.4.1
这个镜像来自 NVIDIA 开发者 dusty-nv 维护的 jetson-containers 项目,是社区和官方都认可的、用于在 JetPack 5 上运行 vLLM 的可靠选择。
docker run --rm -it \
--runtime nvidia \
--network host \
--shm-size=16g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-v /home/cyber/models:/models \
dustynv/vllm:r35.4.1 \
vllm serve /models/Qwen/Qwen3.5-4B-SJT \
--port 8000 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9
设备当前运行的是 JetPack 6 系统(具体为 L4T R36.4)。
这与你之前 uname -a 命令显示的 5.15 内核版本存在矛盾(JetPack 6 通常对应 6.x 内核)。这很可能意味着你的系统近期进行过升级,但尚未重启,因此当前仍在运行旧版本的内核。
cyber@ubuntu:~/models/Qwen$ cat /etc/nv_tegra_release
# R36 (release), REVISION: 4.7, GCID: 42132812, BOARD: generic, EABI: aarch64, DATE: Thu Sep 18 22:54:44 UTC 2025
# KERNEL_VARIANT: oot
TARGET_USERSPACE_LIB_DIR=nvidia
TARGET_USERSPACE_LIB_DIR_PATH=usr/lib/aarch64-linux-gnu/nvidia
需要的命令
```bash
docker run --rm -it \
--runtime nvidia \
--network host \
--shm-size=16g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-v /home/cyber/models:/models \
ghcr.io/nvidia-ai-iot/vllm:latest-jetson-orin \
vllm serve /models/Qwen/Qwen3.5-4B-SJT \
--port 8000 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9
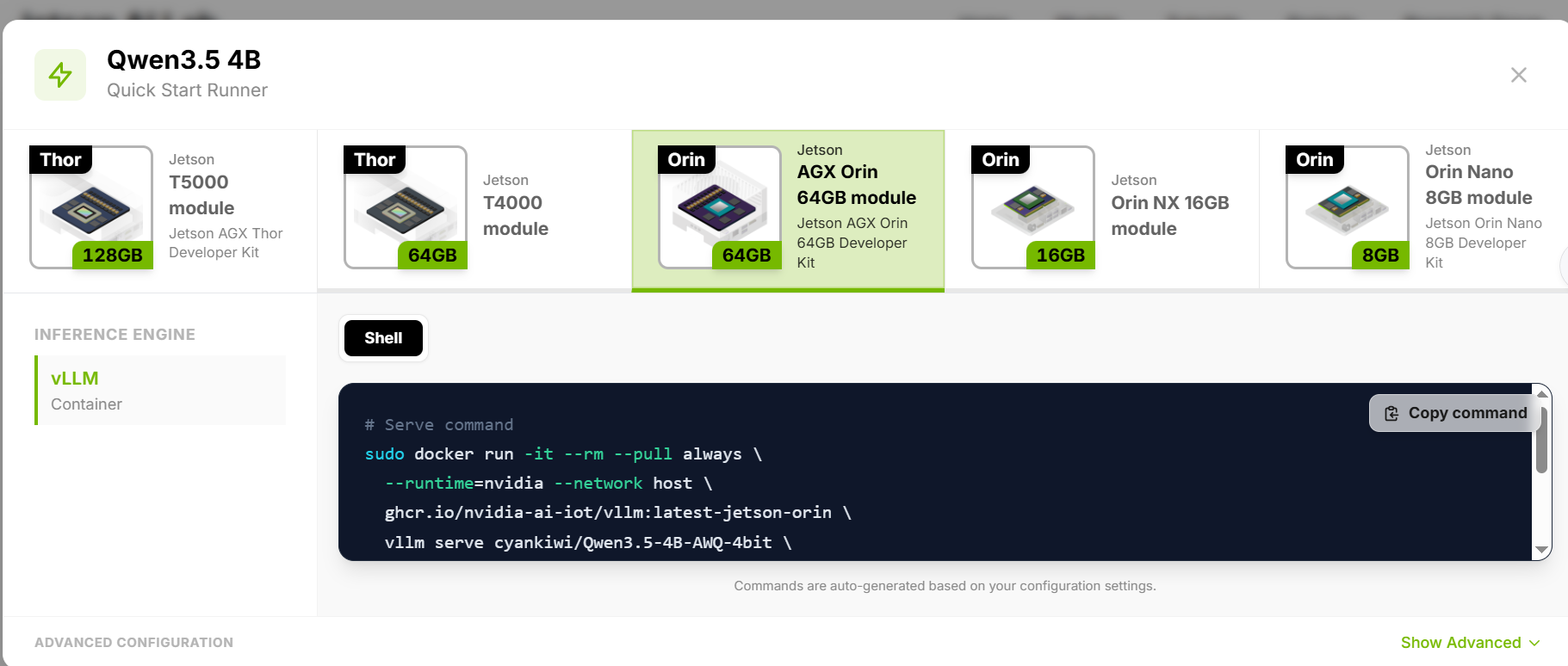
官方vllm 加模型直接运行
Jetson AI Lab 点我
Qwen3.5 4B
qwen
# Serve command
sudo docker run -it --rm --pull always \
--runtime=nvidia --network host \
ghcr.io/nvidia-ai-iot/vllm:latest-jetson-thor \
vllm serve cyankiwi/Qwen3.5-4B-AWQ-4bit \
--gpu-memory-utilization 0.8 \
--enable-prefix-caching \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
Qwen3.5 35B-A3B (MoE)

模型下载
https://www.modelscope.cn/models/nm-testing/Qwen3.5-35B-A3B-awq-w4a16
#Git模型下载
git clone https://www.modelscope.cn/nm-testing/Qwen3.5-35B-A3B-awq-w4a16.git
# Serve command
sudo docker run -it --rm --pull always \
--runtime=nvidia --network host \
ghcr.io/nvidia-ai-iot/vllm:latest-jetson-orin \
vllm serve Kbenkhaled/Qwen3.5-35B-A3B-quantized.w4a16 \
--gpu-memory-utilization 0.8 \
--enable-prefix-caching \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
vllm 镜像国内下载太慢了,找到了一个国内的
南京大学镜像站:一个公益的镜像代理,使用简单,无需注册。把原地址里的 ghcr.io 换成 ghcr.nju.edu.cn 就行。拉取命令如下:
docker pull ghcr.nju.edu.cn/nvidia-ai-iot/vllm:latest-jetson-orin
运行脚本改为
sudo docker run -it --rm --pull always \
--runtime=nvidia --network host \
ghcr.nju.edu.cn/nvidia-ai-iot/vllm:latest-jetson-thor \
vllm serve cyankiwi/Qwen3.5-4B-AWQ-4bit \
--gpu-memory-utilization 0.8 \
--enable-prefix-caching \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
一个想实际的启动脚本
sudo docker run -it --runtime=nvidia --network host --restart always --shm-size=16g -v /home/cyber/models:/models ghcr.nju.edu.cn/nvidia-ai-iot/vllm:latest-jetson-orin vllm serve /models/Qwen/Qwen3.5-4B-SJT --port 8090 --gpu-memory-utilization 0.8 --enable-prefix-caching --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder
启动失败 模型文件权限问题
sudo chmod -R 755 /home/cyber/models/Qwen/Qwen3.5-4B-SJT
启动失败 内存设置过大不行
–shm-size=8g
–gpu-memory-utilization 0.6
模型启动需要几分钟;启动好了测试下
http://192.168.1.156:8090/v1/models
{“object”:“list”,“data”:[{“id”:“/models/Qwen/Qwen3.5-4B-4bit”,“object”:“model”,“created”:1776749524,“owned_by”:“vllm”,“root”:“/models/Qwen/Qwen3.5-4B-4bit”,“parent”:null,“max_model_len”:16384,“permission”:[{“id”:“modelperm-852fa6d0c4ffa90c”,“object”:“model_permission”,“created”:1776749524,“allow_create_engine”:false,“allow_sampling”:true,“allow_logprobs”:true,“allow_search_indices”:false,“allow_view”:true,“allow_fine_tuning”:false,“organization”:“*”,“group”:null,“is_blocking”:false}]}]}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)