YOLOv8模型来实现自动化建筑结构健康监测 建筑裂缝检测数据集的训练及应用 可用于建筑物 桥梁道路墙面
·
YOLOv8模型来实现自动化建筑结构健康监测 建筑裂缝检测数据集的训练及应用 可用于建筑物 桥梁道路墙面
文章目录
以下文字及diamond仅供参考学习使用。
数据集描述:
建筑- 裂缝检测数据集项目,含标注
共3360张 ,分辨率480×480
裂缝检测数据集按照一定规律进行了精细化标注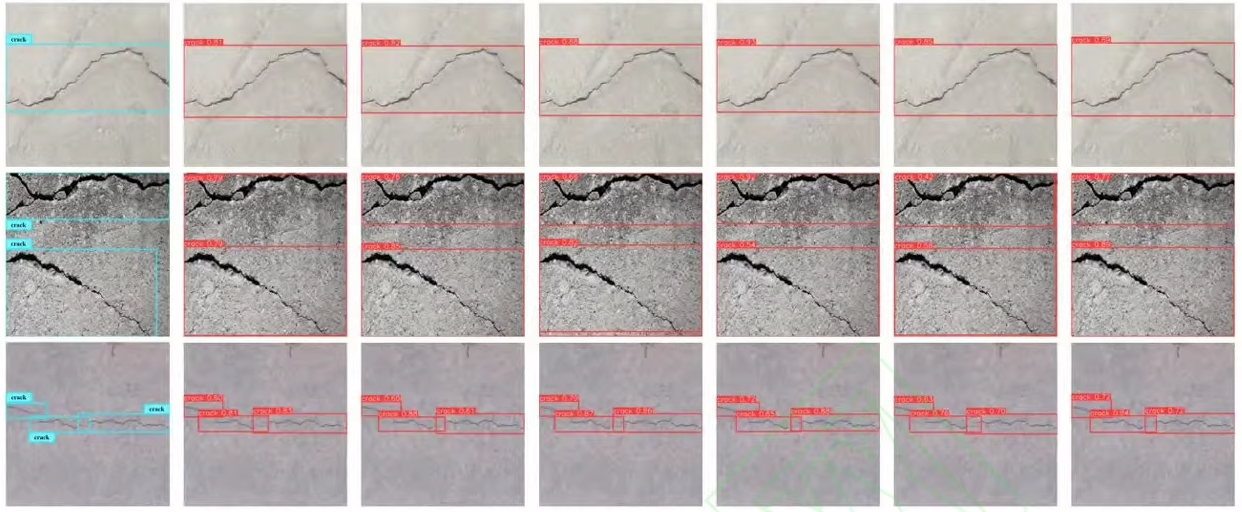
1
1
建筑裂缝检测数据集(3360 张图像,480×480 分辨率,VOC 格式标注)非常适合用于训练 目标检测模型(如 YOLOv8)来实现自动化建筑结构健康监测。以下是从 环境搭建 → 数据预处理 → YOLOv8 训练 → 推理 → 评估 → 部署 的完整流程,适用于裂缝识别、桥梁/墙体巡检、智能基建等场景。
✅ 一、系统环境搭建
1. 确认 CUDA 驱动(GPU 加速)
nvidia-smi
- 要求:NVIDIA GPU(建议 ≥ RTX 3060 / A100)
- CUDA 版本 ≥ 11.8(推荐 12.1)
若未安装,请前往 NVIDIA 官网 下载驱动。
2. 安装 Anaconda(Python 包管理器)
前往 https://www.anaconda.com/products/distribution 下载并安装。
3. 创建 Python 虚拟环境
# 创建名为 crack_detection 的环境
conda create -n crack_detection python=3.9
# 激活环境
conda activate crack_detection
4. 安装必要依赖
# 安装 PyTorch(以 CUDA 11.8 为例)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装 YOLOv8 官方库
pip install ultralytics opencv-python numpy matplotlib tqdm scikit-learn pandas pillow lxml tensorboard
# 验证 GPU 是否可用
python -c "import torch; print(torch.cuda.is_available())"
# 应输出 True
✅
lxml用于解析 XML(VOC 格式)
✅ 二、数据集结构与格式转换(VOC → YOLO)
YOLOv8 使用 YOLO 格式(.txt),需将 .xml 转为 .txt。
推荐目录结构
crack_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── annotations_voc/ # 原始 XML 文件
├── labels/ # 转换后的 YOLO .txt 文件
└── data.yaml
VOC → YOLO 转换脚本
# convert_voc_to_yolo.py
import os
import xml.etree.ElementTree as ET
from pathlib import Path
# 类别映射(建筑裂缝通常只有 1 类)
classes = {
'crack': 0,
'fissure': 0,
'cracks': 0
}
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
return (x * dw, y * dh, w * dw, h * dh)
def convert_annotation(xml_file, output_folder):
try:
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text.lower().strip()
if cls not in classes:
continue
cls_id = classes[cls]
xmlbox = obj.find('bndbox')
b = [float(xmlbox.find(x).text) for x in ['xmin', 'xmax', 'ymin', 'ymax']]
bb = convert((w, h), b)
txt_file = os.path.join(output_folder, Path(xml_file).stem + '.txt')
with open(txt_file, 'a') as f:
f.write(f"{cls_id} {' '.join(f'{x:.6f}' for x in bb)}\n")
except Exception as e:
print(f"Error processing {xml_file}: {e}")
# 执行转换
voc_dir = 'crack_dataset/annotations_voc'
yolo_dir = 'crack_dataset/labels'
os.makedirs(yolo_dir, exist_ok=True)
for xml_file in Path(voc_dir).glob('*.xml'):
convert_annotation(xml_file, yolo_dir)
print("✅ VOC to YOLO conversion completed.")
✅ 三、数据划分(train/val/test = 8:1:1)
# split_data.py
import os
import random
from pathlib import Path
import shutil
image_dir = 'crack_dataset/images_raw' # 原始图像目录
output_img_dir = 'crack_dataset/images'
label_dir = 'crack_dataset/labels'
output_lbl_dir = 'crack_dataset/labels'
for subset in ['train', 'val', 'test']:
os.makedirs(f'{output_img_dir}/{subset}', exist_ok=True)
os.makedirs(f'{output_lbl_dir}/{subset}', exist_ok=True)
images = [f for f in os.listdir(image_dir) if f.endswith(('.jpg', '.jpeg', '.png'))]
random.shuffle(images)
n = len(images)
train_files = images[:int(0.8*n)]
val_files = images[int(0.8*n):int(0.9*n)]
test_files = images[int(0.9*n):]
def copy_files(files, subset):
for img in files:
src_img = os.path.join(image_dir, img)
dst_img = os.path.join(output_img_dir, subset, img)
shutil.copy(src_img, dst_img)
label = Path(img).stem + '.txt'
src_lbl = os.path.join(label_dir, label)
dst_lbl = os.path.join(output_lbl_dir, subset, label)
if os.path.exists(src_lbl):
shutil.copy(src_lbl, dst_lbl)
copy_files(train_files, 'train')
copy_files(val_files, 'val')
copy_files(test_files, 'test')
print("✅ Data split completed: 8:1:1")
✅ 四、data.yaml 配置文件
# data.yaml
train: ./crack_dataset/images/train
val: ./crack_dataset/images/val
test: ./crack_dataset/images/test
# 类别数量
nc: 1
# 类别名称
names:
- crack
# 中文名(可选,用于可视化)
names_zh:
- 裂缝
✅ 五、调用 YOLOv8 官方预训练模型进行训练
推荐使用 YOLOv8m 或 YOLOv8l,提升对细小裂缝的检测能力。
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO('yolov8m.pt') # 推荐 medium 模型,平衡精度与速度
# 开始训练
results = model.train(
data='data.yaml',
epochs=200, # 建筑数据建议 150~300
batch=32, # 480x480 小图可增大 batch
imgsz=480, # 保持原始分辨率
optimizer='AdamW',
lr0=0.001,
weight_decay=0.0005,
momentum=0.937,
# 数据增强(对裂缝特别重要)
augment=True,
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
degrees=10.0, # 随机旋转增强泛化
translate=0.2,
scale=0.5,
flipud=0.0,
fliplr=0.5,
mosaic=1.0,
mixup=0.1,
# 正则化
dropout=0.2,
label_smoothing=0.05,
# 学习率调度
cos_lr=True,
# 保存
project='runs/train',
name='building_crack_yolov8m',
save=True,
save_period=10,
exist_ok=False,
# 缓存
cache=True
)
✅ 六、推理与评估代码
1. 单图推理
model = YOLO('runs/train/building_crack_yolov8m/weights/best.pt')
results = model('wall_crack_001.jpg', conf=0.25)
results[0].show()
2. 批量推理
model.predict(
source='crack_dataset/images/test',
save=True,
project='runs/detect',
name='crack_test_results',
conf=0.25,
imgsz=480
)
3. 模型评估
metrics = model.val(
data='data.yaml',
split='test',
batch=32,
imgsz=480,
save_json=True,
name='final_eval'
)
print(f"mAP@0.5: {metrics.box.map50:.4f}")
print(f"mAP@0.5:0.95: {metrics.box.map:.4f}")
print(f"Precision: {metrics.box.p:.4f}")
print(f"Recall: {metrics.box.r:.4f}")
✅ 七、模型导出(ONNX / TensorRT)
# 导出为 ONNX(支持部署到 Web / 移动端)
model.export(format='onnx', dynamic=True, opset=13, imgsz=480)
# 导出为 TensorRT(高性能边缘部署)
model.export(format='engine', half=True, dynamic=True, imgsz=480)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)