从 LLM 到 Agent Skill,带你打通底层逻辑!
一、基础核心概念(LLM生态底层,支撑所有高阶能力)
1. LLM(大语言模型,Large Language Model)
LLM是整个AI技术体系的核心引擎,也是所有后续概念的基础,核心细节如下:
-
底层架构:几乎所有大模型均基于Transformer架构构建,该架构由Google团队于2017年提出,对应论文《Attention Is All You Need》,虽由Google发明,但由OpenAI将其规模化应用并引爆全球。
-
核心本质:本质是“文字接龙”游戏,即逐词预测下一个概率最高的词汇,输出过程中会将已生成的词汇重新追加到输入中,循环预测直至输出结束标识符,这也是大模型逐词输出的核心原因。
-
发展历程与现状:2022年底,GPT-3.5问世,成为第一个真正达到“可用级”的大模型;2023年3月,GPT-4发布,大幅提升AI能力天花板;目前GPT-5.4仍是业界标杆,同时赛道已进入多厂商竞争阶段,Cloud、Gerin、A等后起之秀在各自领域与OpenAI同台竞技。
2. Token(令牌)
Token是大模型处理文本的最小基本单元,是连接人类文字与模型数学运算的关键,核心细节如下:
-
核心作用:大模型本质是庞大的数学函数,仅能处理数字,无法直接识别文字,Token就是文字与数字(Token ID)之间的转换载体,由Tokenizer(令牌器)负责处理。
-
Tokenizer的工作流程:分为编码(文字→数字)和解码(数字→文字)两步。编码时先将文本切分为最小片段(即Token),再将每个Token映射为唯一的Token ID(一对一绑定);解码时仅需将Token ID反向映射为文字,无需再次切分(因模型每次仅输出一个Token)。
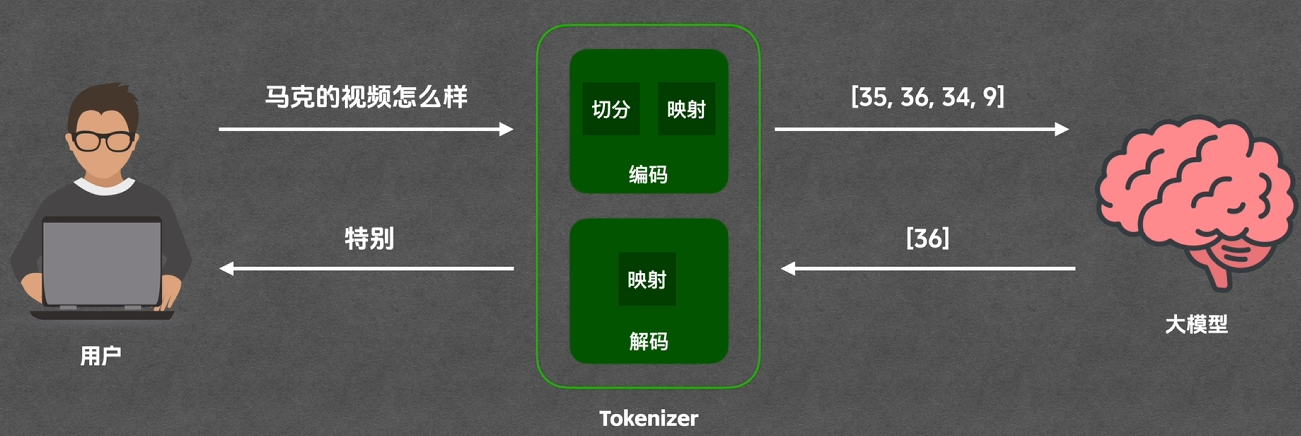
-
关键注意点:Token与“词”并非一对一关系,示例如下:
-
中文:“马克的技术工作坊”被切分为5个Token(“工作坊”拆分为“工作”“坊”),“程序员”拆分为“程序”“员”;
-
英文:常见单词(如hello、going)多为1个Token,但“helpful”拆分为“help”“ful”,特殊字符(如“go”)可能需多个Token表示(显示为问号,需通过Token ID识别)。
-
-
量化参考:平均1个Token≈0.75个英文单词,或1.5-2个中文字符;40万个Token≈60-80万个中文字符,或30万个英文单词。
-
补充说明:Token的切分规则由BPE算法训练生成,若需深入了解可参考相关专项视频。
3. Context(上下文)& Context Window(上下文窗口)
两者解决大模型“临时记忆”的问题,是实现多轮对话、复杂任务处理的基础,核心细节如下:
-
Context(上下文):指大模型每次处理任务时接收的所有信息总和,相当于大模型的“临时记忆体”,包含的内容有:用户当前提问、历史对话记录、模型正在输出的Token、工具列表、System Prompt等。
-
核心原理:大模型本身无真正“记忆”,仅能通过“接收历史对话+当前提问”的组合输入,实现“记住之前内容”的效果——背后程序会自动将整段对话历史与当前问题一同发送给模型。
-
Context Window(上下文窗口):指Context能容纳的最大Token数量,决定了模型一次能处理的信息规模。目前主流大模型的Context Window均达百万级:GPT-5.4为105万,Gerin A 3.1 Pro、Cloud Opens 4.6均为100万;100万个Token约对应150万个中文字符,可容纳《哈利波特》全集内容。

4. Prompt(提示词)
Prompt是大模型的“指令信号”,决定模型的输出方向与质量,核心细节如下:
-
核心定义:本质是给大模型的具体问题或指令,是模型启动运转的前提(无Prompt则模型无法输出内容),例如“帮我写一首诗”就是典型的Prompt。
-
Prompt的质量影响:模糊的Prompt(如“帮我写一首诗”)会导致模型输出不确定(可能是古诗、现代诗、打油诗);清晰具体的Prompt(如“帮我写一首五言绝句,主题是秋天的落叶,风格悲凉”)能让输出更贴合预期。
-
分类与区别:分为两类,功能互补:

-
User Prompt(用户提示词):由用户直接输入,用于告知模型具体任务(如“三加五等于几”);
-
System Prompt(系统提示词):由开发者在后台配置,用于定义模型的人设、做事规则(用户不可见,但持续影响模型行为),例如“你是耐心的数学老师,不直接给答案,仅引导学生思考”。

-
-
Prompt Engineering(提示词工程):专门研究如何优化Prompt,让模型更精准理解意图的领域。目前该领域热度下降,原因一是门槛低(本质是“把话说清楚”),二是大模型能力提升,即使Prompt模糊也能大致预判用户意图。
二、外部能力拓展(突破LLM原生局限,实现“感知外部世界”)
1. Tool(工具)
LLM的原生局限是“无法感知外部环境、无实时能力”,Tool的核心作用是弥补这一缺陷,核心细节如下:
-
核心本质:本质是可调用的外部函数,输入指定参数后,能输出明确结果(如天气查询、定位、计算等),相当于给大模型“外接手脚”。
-
完整调用流程:涉及4个角色(用户、平台、大模型、Tool),平台作为“传话筒”(本质是一段代码)串联全程,具体步骤:

-
用户向平台发送问题(如“今天上海天气怎么样”);
-
平台将问题+可用工具列表转发给大模型;
-
大模型分析需求,生成Tool调用指令(含工具名称、参数),发送给平台;

-
平台根据指令调用对应Tool,获取返回结果(如“上海晴天,15-25℃”);

-
平台将Tool结果转发给大模型,大模型将结果整理为自然语言,通过平台反馈给用户。
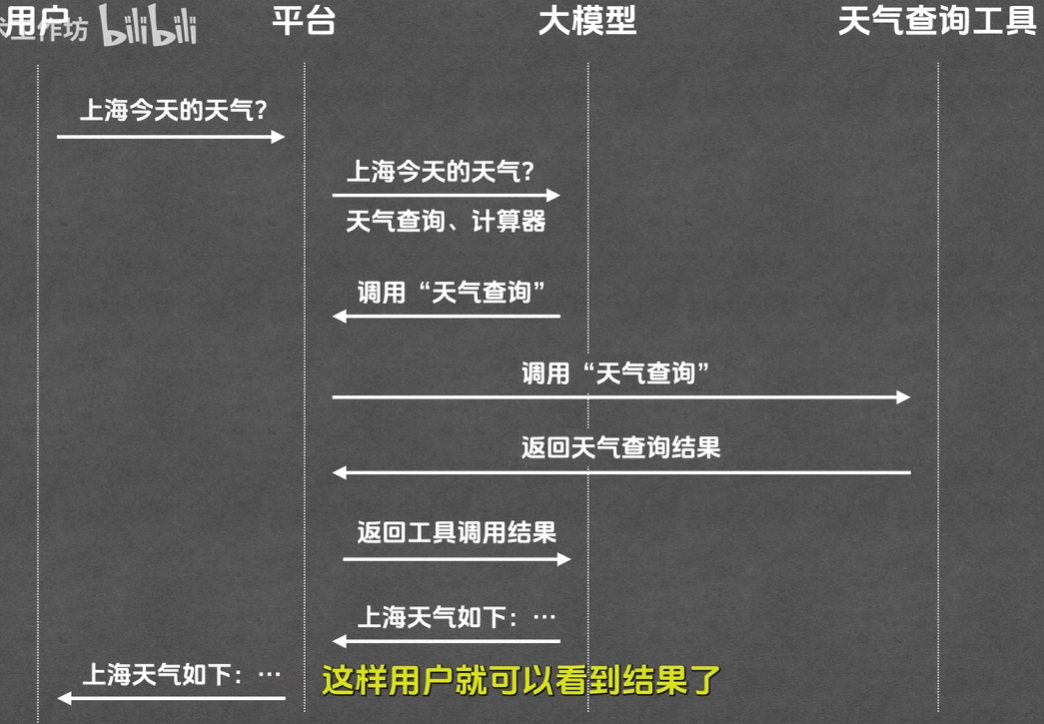
-
-
各角色职责:
-
大模型:负责“选择Tool+生成参数”和“归纳Tool结果”,无法直接调用Tool,仅能输出调用指令;
-
Tool:负责执行具体操作(如查询天气、定位),输出明确结果;
-
平台:负责串联流程,转发信息、执行Tool调用。
-

2. MCP(模型上下文协议,Model Context Protocol)
MCP是解决Tool接入“碎片化”问题的统一标准,核心细节如下:
-
诞生背景:不同大模型平台的Tool接入规范不同(如OpenAI、Anthropic、Google各有标准),导致同一个Tool需为不同平台编写多套接入代码,效率极低。
-
核心作用:制定统一的Tool接入标准,让Tool开发者仅需按MCP规范开发一次,即可在所有支持MCP的平台上使用,类比于“所有手机统一使用Type-C接口”,提升开发效率、降低适配成本。
-
通俗理解:无需记忆不同平台的接入规则,一套代码通用所有平台,本质是“Tool接入的统一约定”。
3. RAG(检索增强生成,Retrieval Augmented Generation)
RAG是解决“长文本处理、私有/实时知识查询”的核心技术,核心细节如下:
-
应用场景:当需基于长文本(如上千页产品手册)让模型回答问题时,直接将整本文本传入Context会超出Context Window限制,且成本过高,RAG可解决该问题。
-
核心原理:从长文本/知识库中,抽取与用户问题最匹配的几个片段,仅将这些片段传入大模型,让模型基于片段回答问题,既突破Context Window限制,又降低使用成本。
-
核心价值:让大模型无需“记住”所有长文本内容,仅需检索相关片段即可精准回答,提升长文本处理能力和回答准确性。
三、智能体与技能(高阶形态,实现“自主完成复杂任务”)
1. Agent(智能体)
Agent是LLM+Tool+MCP的高阶整合形态,核心是“自主规划、自主执行”,核心细节如下:

-
核心定义:能自主分析用户任务、规划执行步骤、多轮调用Tool,直至完成任务的系统,区别于“单次Tool调用”,具备一定的自主决策能力。
-
典型示例:用户需求“今天我这里天气怎么样?如果下雨,帮我查附近卖雨伞的店”,Agent的执行流程:
-
分析需求:需先获取用户位置→再查该位置天气→若下雨,查附近雨伞店;
-
调用定位Tool,获取用户经纬度;
-
调用天气Tool,根据经纬度查询天气(确认是否下雨);
-
若下雨,调用店铺Tool,根据经纬度查询附近雨伞店;
-
整合所有结果,输出自然语言回答。
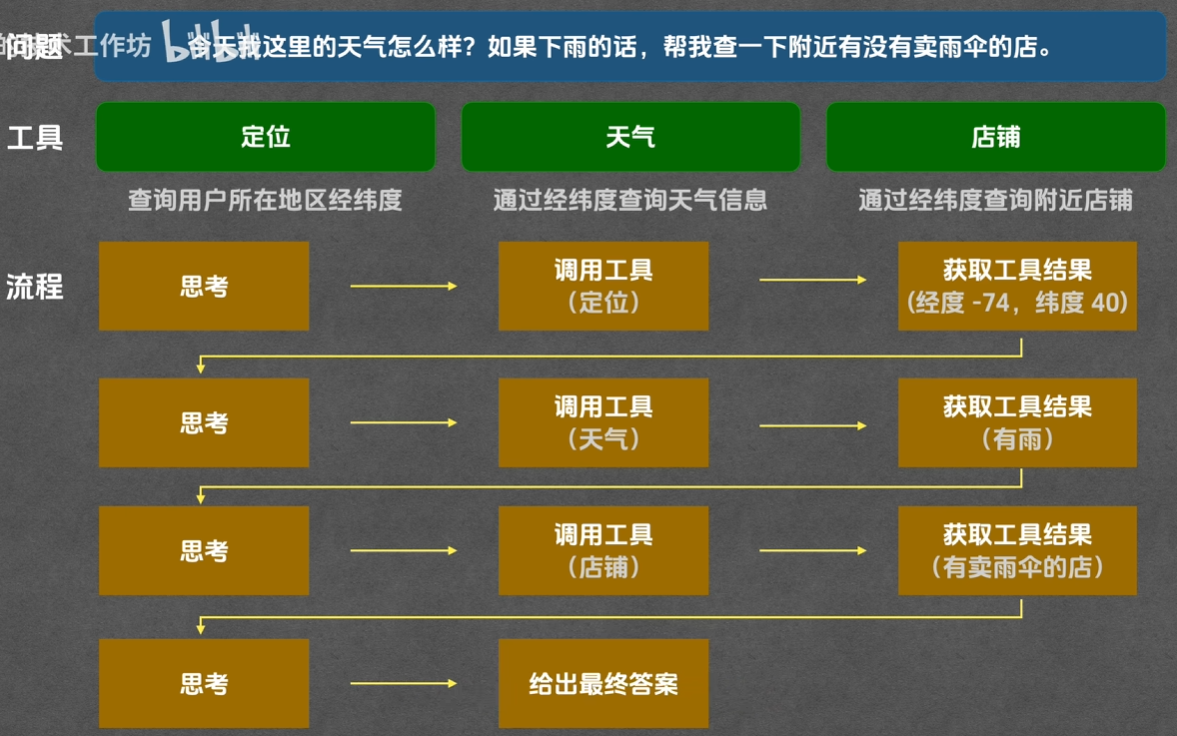
-
-
主流产品与构建模式:市面上主流Agent产品有Cloud Code、Code X、Gera、COI等;经典构建模式有React、Planning、Excuse等,可通过专项视频了解具体实现原理(如手写简化版Cloud Code)。

2. Agent Skill(智能体技能)
Agent Skill是解决Agent“输出不稳定、重复配置Prompt”的痛点,核心是“固化规则与流程”,核心细节如下:
-
核心本质:提前编写好、存入指定目录的说明文档(本质是Markdown文档,文件名固定为Skill.md),用于告知Agent做事的步骤、规则、输出格式,避免每次提问都重复输入复杂要求。
-
核心结构:分为两部分,格式可灵活调整(核心是说清规则):
-
元数据层:相当于“文档封面”,至少包含两个属性——Name(Skill名称,如“Go Out Checklist”,即出门清单)、Description(Skill描述,说明其用途);
-
指令层:核心内容,包含任务目标、执行步骤、判断规则、输出格式、示例等,例如出门清单Skill中,会明确“先调用定位Tool→再调用天气Tool→根据天气判断需带物品→按指定格式输出”。
-
-
存放规范(以Cloud Code为例):
-
在用户目录下的 /.clouds/skills 文件夹中,新建与agent skill名称一致的文件夹,如:我们的agent skill叫做go-out-checklist所以我们的文件夹也必须叫这个名字;
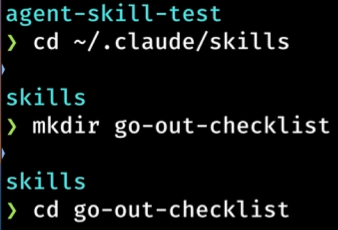
-
在该文件夹中,新建文件并命名为SKILL.md(SKILL大写,硬性规范,否则系统不识别);
-
将Skill内容粘贴到文件中,保存即可。
-
-
工作流程:Agent启动时,会读取所有Skill的元数据;当用户问题与某Skill的名称/描述相关时,Agent会读取该Skill的完整指令层,按指令执行任务(如出门清单Skill,用户提问“我要出门,该带什么”,Agent会按指令调用Tool、输出指定格式结果)。
-
高级功能:支持运行代码、引用资源,具备渐进式披露机制(按需加载内容),可节省Token;具体可参考专项视频了解细节。
四、核心术语辨析与技术发展趋势
1. 易混淆术语辨析(关键区分,避免误解)
-
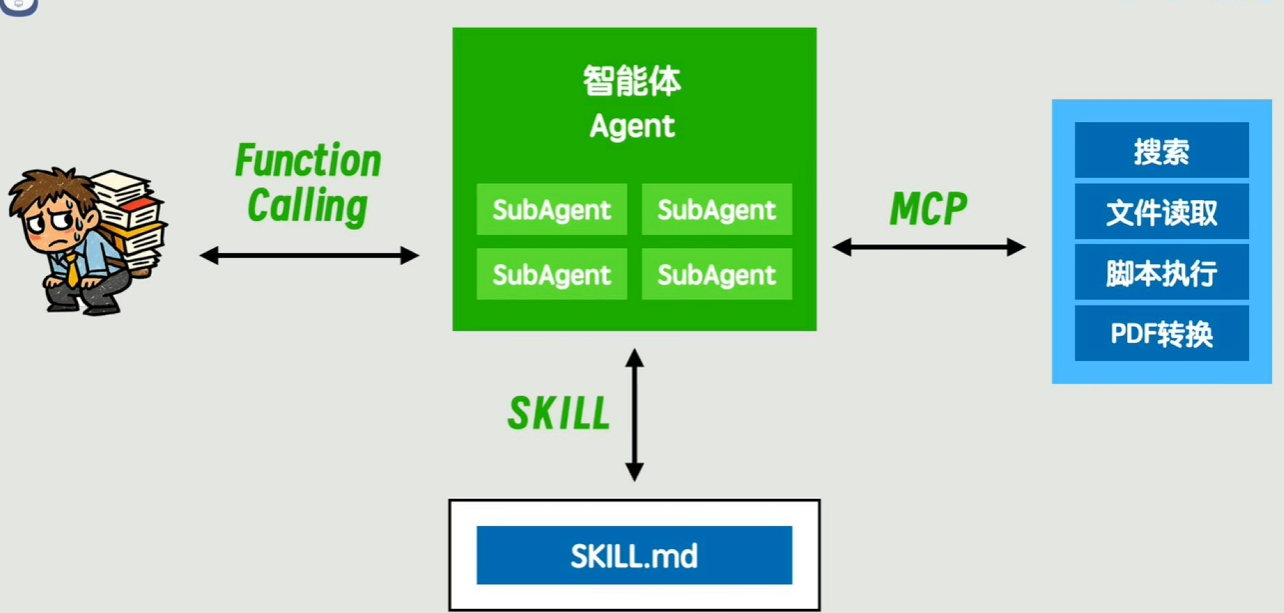
Function Calling vs MCP:两者无替代关系,不属于同一维度:
-
Function Calling:是Agent与LLM之间的“格式约定”,让LLM按固定格式(如JSON)输出Tool调用指令,方便Agent程序解析;
-
MCP:是Agent与Tool服务之间的“调用协议”,约定Tool的调用方式、参数格式、返回值规则,解决Tool接入统一问题。
-
-
Agent Skill vs MCP:两者无替代关系,不属于同一维度:
-
Agent Skill:本质是“Prompt加载器”,核心是固化任务规则,方便Agent重复执行同类任务,仅需一个Skill.md文件即可;
-
MCP:核心是“Tool接入标准”,解决Tool跨平台适配问题,与Skill的功能、用途完全不同。
-
-
Agent Skill与Langchain、Workflow的区别:三者均用于实现复杂任务,核心差异是“刚性与柔性”的不同,从刚性到柔性排序:
-
Langchain:纯编程实现,硬编码流程,稳定性强,但柔性差,难以适配小变化;
-
Workflow:低代码拖拽实现,比Launch In灵活,改造成本低,但不如Skill易用;
-
Agent Skill:由Agent自主控制流程,提前固化规则,兼顾灵活性与稳定性,无需编程,普通人可使用;
-
纯Agent:完全柔性,可自主调整流程、生成脚本,但稳定性差,易复杂化任务。

-
-
Subagent(文档2补充):用于处理复杂任务中的独立子任务,核心作用是“上下文隔离”——子Agent的上下文不保留在主Agent中,避免主Agent上下文过大,本质是“拆分任务、优化上下文管理”。
2. 技术本质与发展趋势
-
核心本质:所有AI术语(LLM、Token、Context、Tool、MCP、Agent、Skill等),本质都是“优化Prompt上下文、减少人类操作、降低使用门槛、节省Token”的中间产物,核心离不开LLM与Prompt的交互——要么是给LLM补充上下文信息(如RAG、Skill),要么是减少人类与LLM的直接沟通(如Agent、Tool)。
-
Agent的本质(文档2观点):Agent并非“具备真正智能”,而是“将固定流程交给程序、模糊逻辑交给LLM”,核心是“分流处理”,所有不需要智能的部分(如固定脚本、工具调用)由程序完成,需要语义识别、决策的部分由LLM完成,最终目的是节省人类时间。
-
当前痛点:Token成本过高,越强大的Agent,背后消耗的Token越多,这是当前制约Agent普及的关键因素。
-
未来趋势:
-
Token成本会逐渐降低,未来生产级大模型可部署在普通电脑上,Token将接近“免费”;
-
中间产物(MCP、Workflow等)会逐渐被淘汰,常用Tool会内化到Agent主程序中,Skill会成为主流(兼顾灵活与稳定);
-
最终趋向“极简易用的超级Agent”,打包所有常用功能,普通人无需配置(无需部署Skill、配置MCP、填写API Key),可直接使用,底层技术会被产品化封装,用户无需关注术语细节;
-
交互形式会更丰富(如连接社交软件、支持定时任务),让Agent从“电脑上的服务”变成“日常可用的助手”(如Cloud Bot的爆火,核心是提升了易用性)。
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)