大模型初探:从LLM到智能体,小白也能轻松入门并收藏!
本文深入浅出地介绍了大语言模型(LLM)的概念、训练过程(预训练与微调)及其应用场景,并详细解析了基于LLM的智能体(Agent)框架,包括记忆、规划、工具使用等关键环节。文章还重点阐述了RAG技术如何减少LLM的幻觉,提升其回答准确性,并探讨了提示词(Prompt)的编写与优化。整体内容旨在帮助初学者全面理解大模型技术,为实际应用打下坚实基础。
1、什么是智能体 (Agent)
一种基于LLM(LargeLanguage Model)的能够感知环境、做出决策并执行行动以实现特定目标的自主系统。与传统人工智能不同,Al Agent 模仿人类行为模式解决问题,通过独立思考和调用工具逐步完成给定目标,实现自主操作。
通用智能体平台
以Agent为核心技术驱动,构建通用智能体平台,通过在智能体感知、记忆、规划和执行各关键环节的能力攻关,以适应不断变化的实际业务和日常办公需求,提供更加个性化和精准的服务,并助力工程人员解放脑、解放手、想的更全、做的更准,共同推动了其在更多复杂场景下的应用。
2、什么是LLM (Large Language Model)
大语言模型是一类基于深度学习的人工智能模型,旨在处理和生成自然语言文本。通过训练于大规模文本数据,使得大语言模型能够理解并生成与人类语言相似的文本,执行各类自然语言处理任务。
LLM的训练及使用
LLM能够理解并生成与人类语言相似的文本,执行各类自然语言处理任务,具体可应用场景包括而不限于文本生成、机器翻译、摘要生成、对话系统、情感分析等。其具有强大的泛化能力、能够处理多种任务。
LLM的训练
LLM的训练过程分为预训练和微调两个阶段。
-
预训练阶段
模型在大规模未标注文本数据上进行自监督学习,学习通用的语言表示。
-
微调阶段
模型在特定任务的标注数据上进行有监督学习,调整模型参数以适应具体任务需求。
LLM的使用
一方面,对于直观的日常使用,用户输入问题(提示词,Prompt),大模型给出该问题的回答。
另一方面,对于基于LLM的AI应用编程,可通过以指定格式调用LLM的API,获取问题的答案。
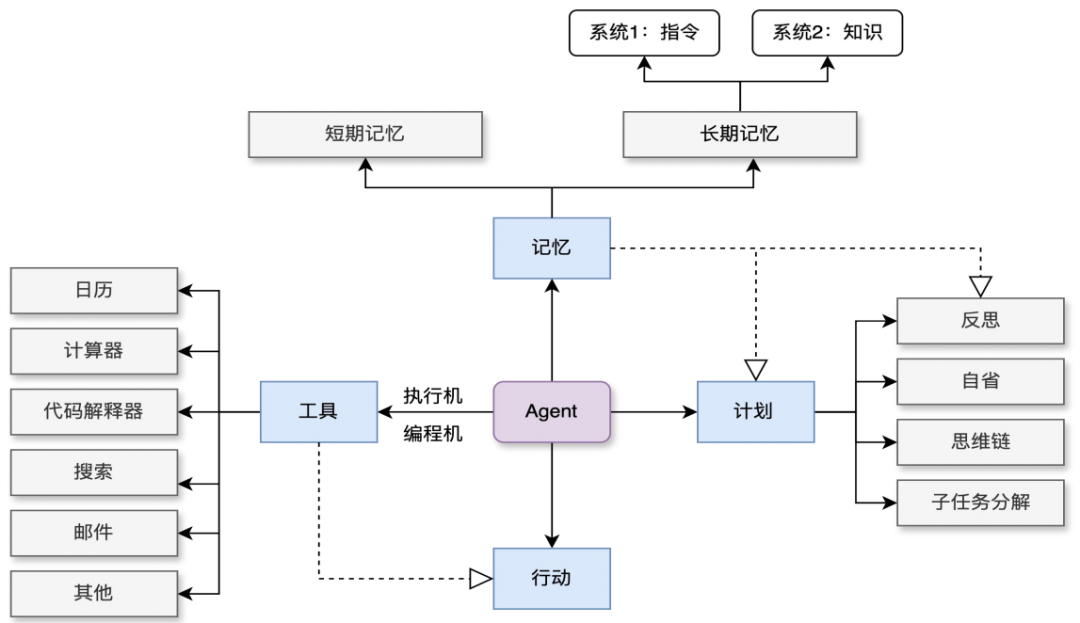
基于LLM的Agent框架
-
LLM:对标人类大脑,思考如何解决问题、给出怎样的回答。
-
记忆:长期记忆加短期记忆。即智能体使用的历史记录、系统数据,以及智能体执行过程中产生的各种中建信息。
-
规划技能:提示词编排、意图理解、任务分解、自我反思。
-
工具使用:智能体在执行任务中可能会使用到的各种工具接口。
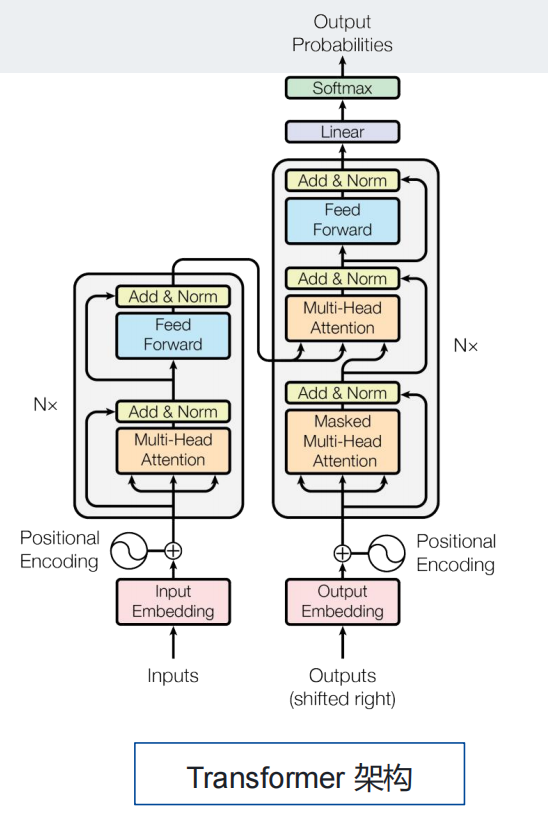
3、Transformer架构
LLM的核心技术架构是Transformer,这是一个基于自注意力机制的深度学习模型。Transformer架构的关键在于其能够并行处理序列数据,大大提高了模型的训练效率和性能
参数规模
LLM通常采用大规模神经网络,参数数量从数百万到数十亿不等,例如通义干问(Qwen-7B)具有70亿的参数规模训练数据需要高质量的、经过预处理的多模态数据。参数规模的增加使模型具有更强的学习和泛化能力,能够处理复杂的语言任务,但也带来了计算成本和资源需求的显著增加。
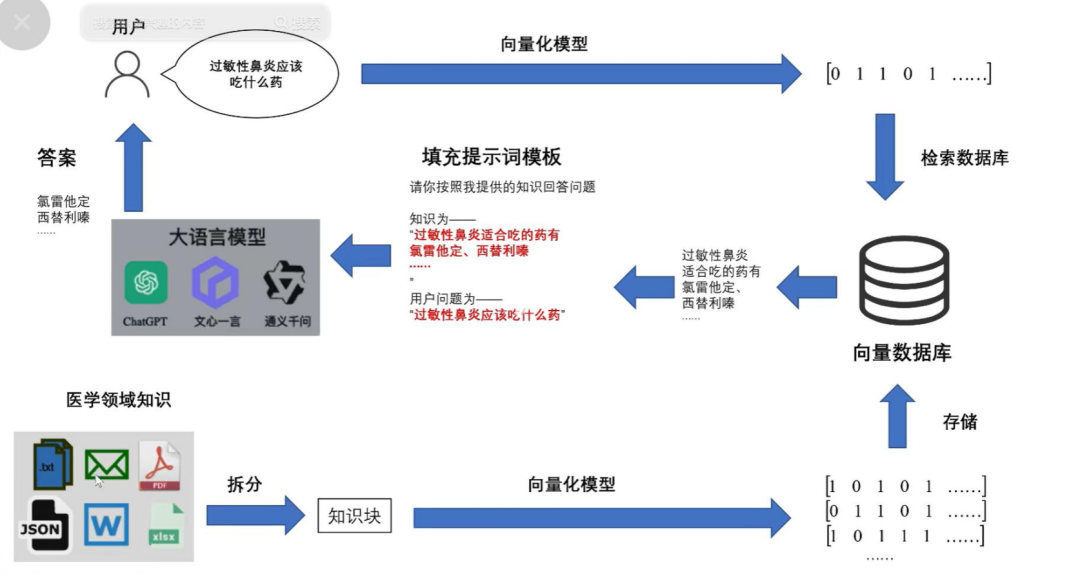
4、什么是RAG
LLM回答用户问题时,是基于训练LLM时使用的文本数据进行的。而面对未知知识的问题,它并不能正确回答而容易产生错误的结果,即大模型的幻觉。
什么是RAG
RAG(Retrieval-augmented Generation)是一种自然语言查询方法,通过一个检索信息组件从外部知识源获取附加信息,馈送到LLM prompt以更准确地回答所需的问题。通过额外的知识来增强LLM 以回答问题,用以减少 LLM产生幻觉的倾向。
利用RAG减少幻觉
基于RAG技术,可以通过构建一个知识库,让LLM能够在回答问题时以这个知识库为基础,具备回答知识库中的相关内容的能力。
RAG的优势
基于RAG技术创建的知识库,可以比较便利地增删改其中的文档,可以支持更频繁的更新。
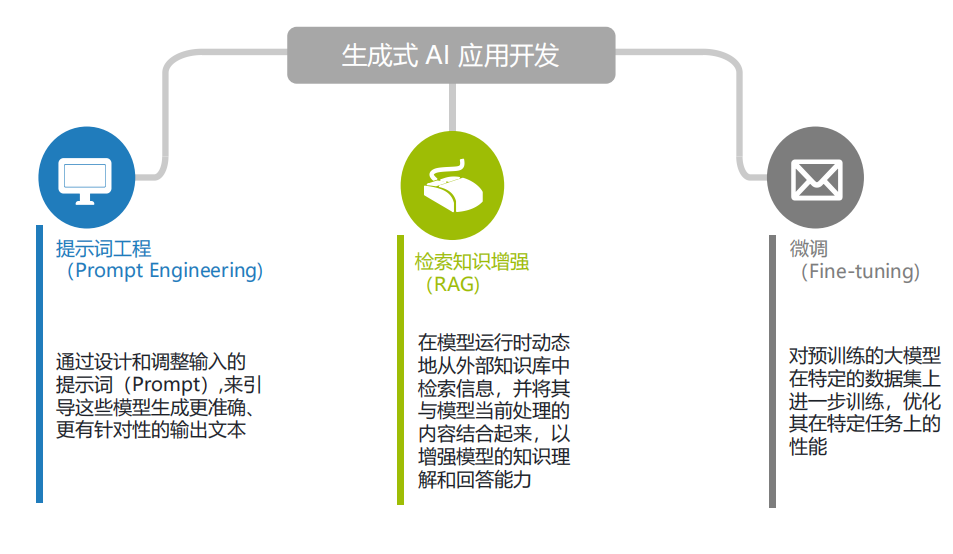
RAG的整体流程
RAG的整体流程分为两大步:
-
一是事先的索引丨(lndexing)也即是从私有文档构建知识库的过程;即为图蓝色虚线链路。
-
二是即时的查询(Querying)也即是针对已构建的知识库进行查询问答的过程。即为图红色虚线链路。先检索,然后生成。
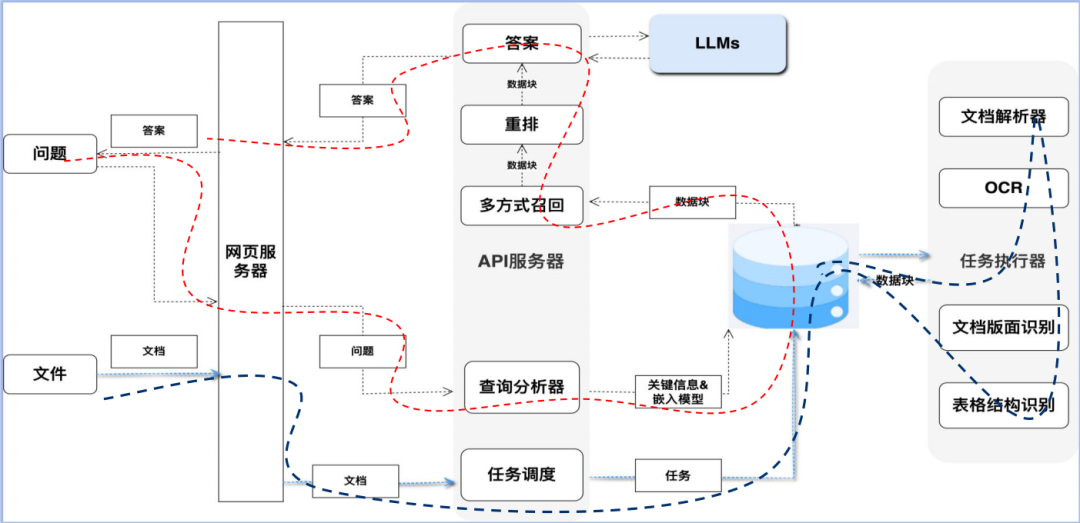
RAG的效果
-
一是赋予LLM回答私有知识库问题的能力,减弱幻觉;
-
二是提供了回答中引用的原文出处,提高检索效率,同时便于直接对比原文确保LLM回答的准确性在智能问答、文档摘要、数据整理等领域发挥重要作用
5、什么是提示词 (工程)
提示词(Prompt)是指向LLM提供输入以引导其生成特定输出的文本或指令。
提示词
提示词包括两类,系统提示词与用户提示词。用户提示词即为用户的问题;系统提示词为人工智能应用内置的指向LLM的一组初始指令或背景信息,用于指导LLM的行为方式和响应模式。
一般情况下,提示词更多的是指用户提示词、即用户发送给LLM的问题。
提示词对LLM的影响
在生成文本时,LLM会试图理解并根据其理解生成相应的响应LLM生成的回答的质量受用户提示词的影响,更完善的提示词能够让LLM更好地理解用户意图、给出更契合更完善的回答
如何优化提示词
在提出用户问题时候,应该清晰而具体地表达指令,提出具体的需求;如果对LLM的输出格式有要求,那么最好提供参考文本作为示例。
如何编写更好的提示词
更为完善的提示词基本组成部分:
- 指令:要求模型对文本的处理动作。
- 指令的对象:需要模型处理的文本。
- 示例:案例或思维模型提示。
- 输出要求:对于输出内容的内容和格式要求;
- 异常情况:对于模型无法执行,或指令信息缺失时的异常处理机制。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
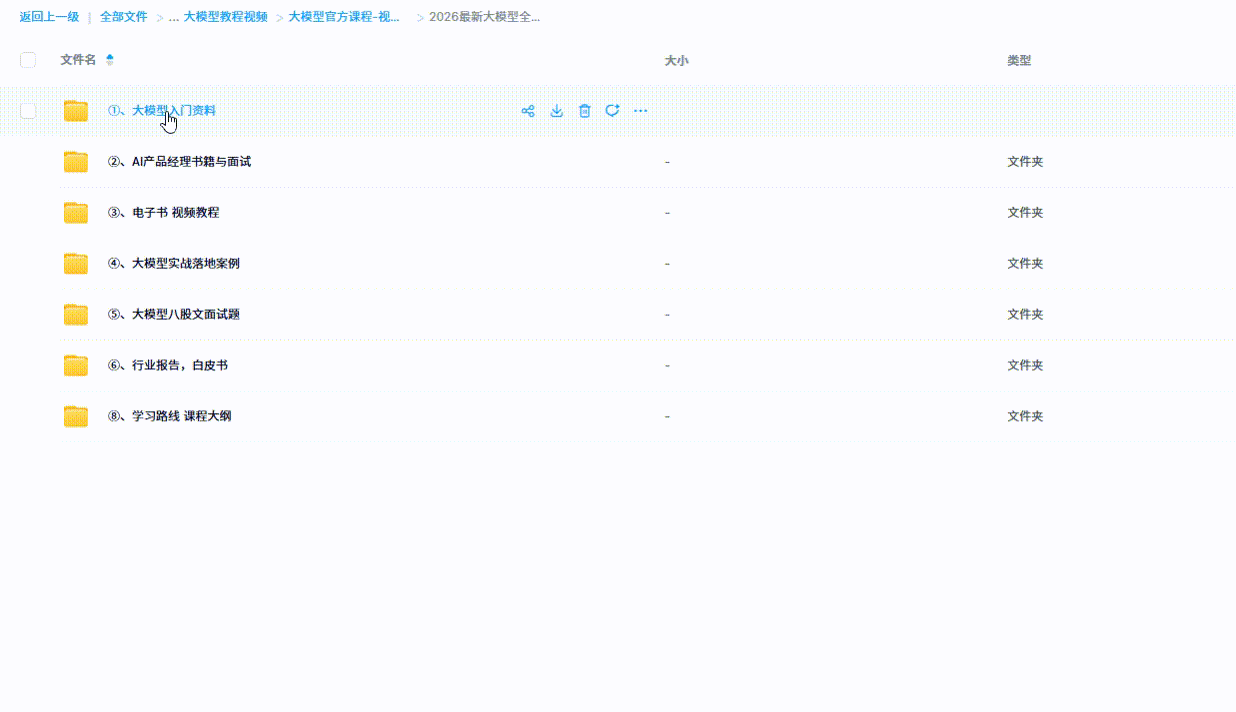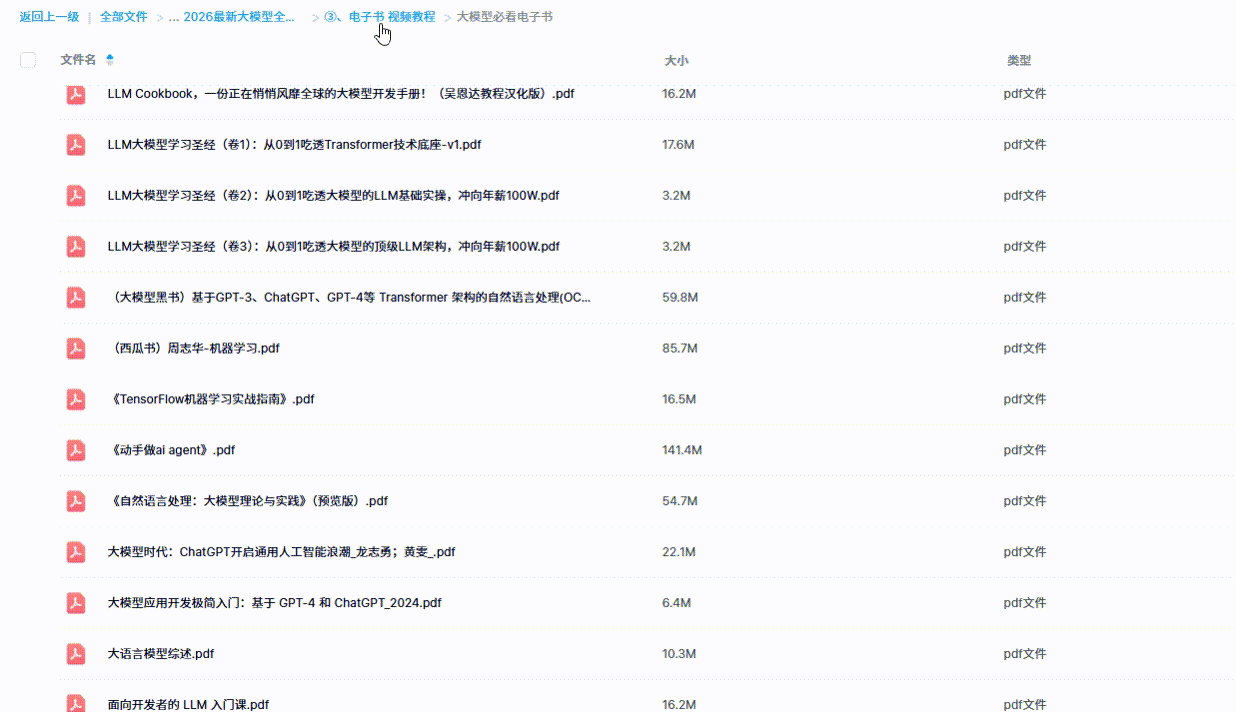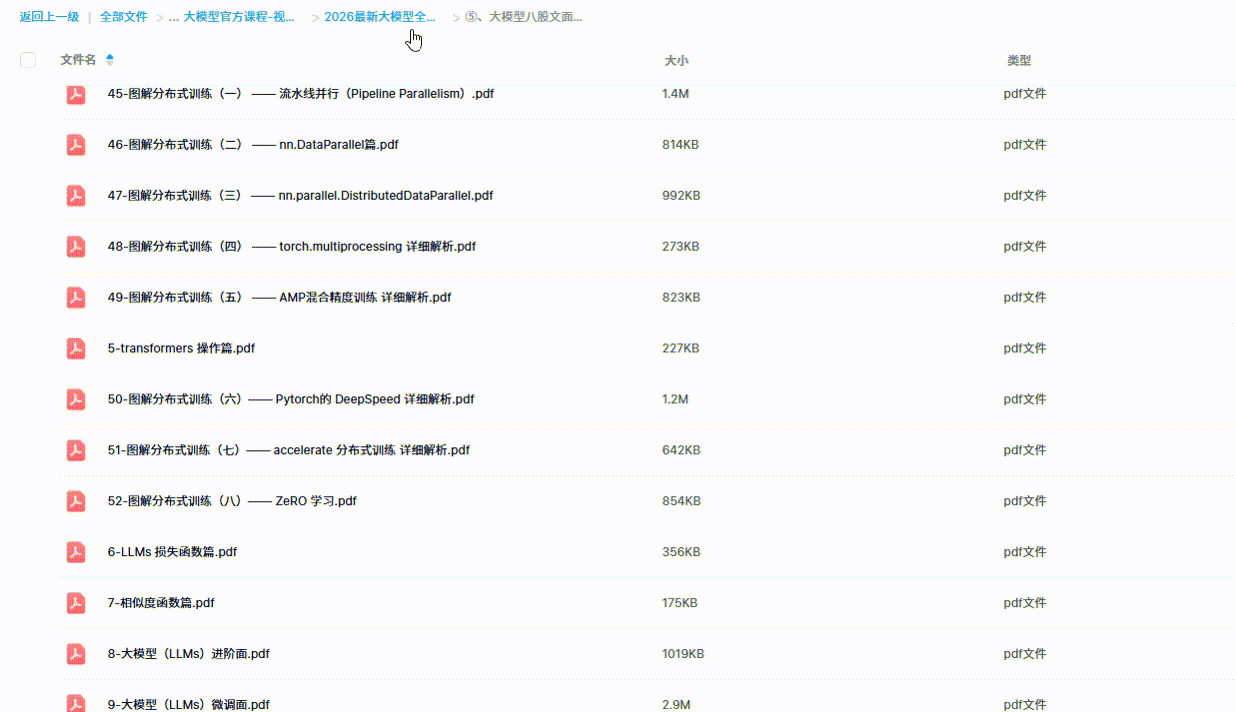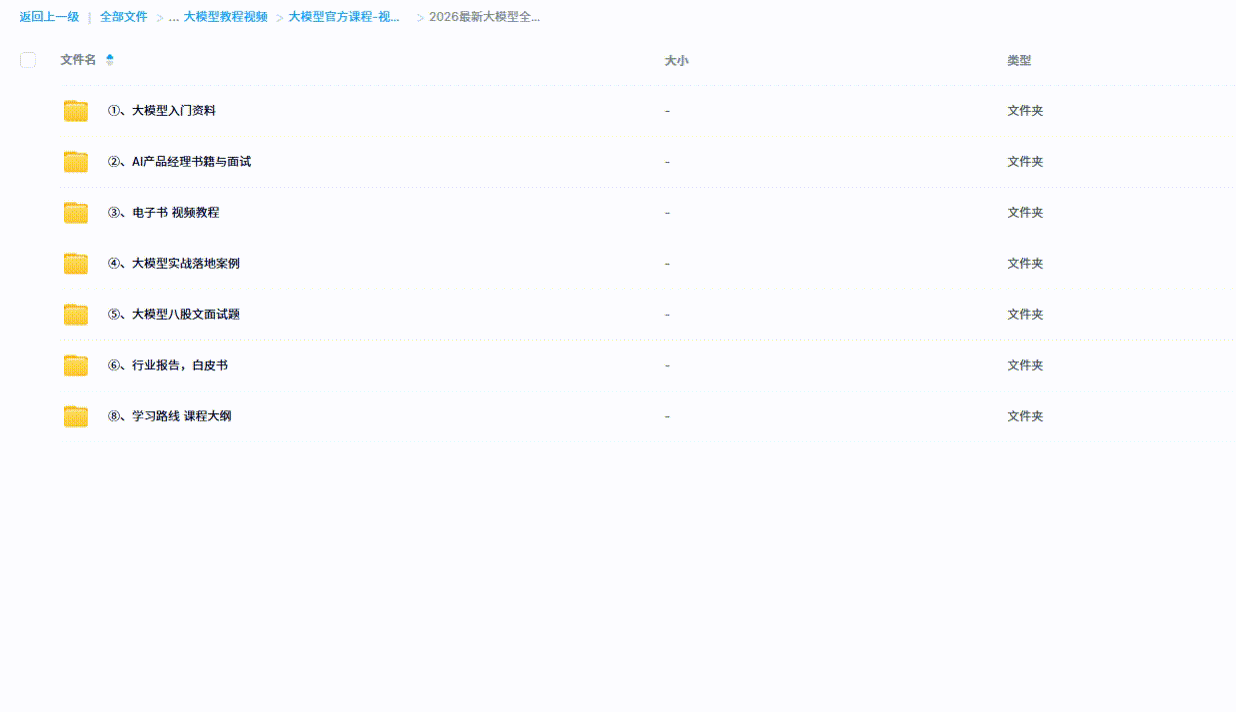
下面是我整理的大模型学习资源,希望能帮到你。
👇👇扫码免费领取全部内容👇👇
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献220条内容
已为社区贡献220条内容

所有评论(0)