MCP-AI编程打通WIKI知识库以及后续的一些思考
摘要
本文包含两部分内容,第一部分是MCP的开发配置,第二部分是MCP开发后的一些感悟,即AI 时代的数据存储与后端架构。
引言
使用了AI编程工具一年了,最直观的感觉就是AI编程的代码生成效果越来越好,想要代码生成效果好,除了模型本身的能力优秀外,一套明确清晰的AI编程规范和公司的完备知识库,以及正确的示例代码,对于AI编程效果的提升至关重要。
最近为了在AI编程时能方便获取WIKI上公司的开发规范、开发资源信息和相关的组件或插件的集成。就写了一个MCP demo 用于丰富开发时的上下文语义。方便进行编码,提高编码的便捷性和效率。
MCP简介
在 MCP 出现之前,每个 AI 应用(智能体)想要连接一个外部工具(比如数据库、地图 API、文件系统等),都需要进行一对一的定制开发。这就像在没有 USB 标准之前,每个设备都需要自己专属的充电器和连接线,非常繁琐且效率低下。
MCP 通过定义一套统一的“通信语言”和接口标准,让 AI 应用可以像“搭积木”一样,轻松、安全地调用各种外部能力,实现了“一次封装,处处可用”。
MCP 采用客户端-服务器(C-S)架构,主要包含三个核心角色:
简单来说,当你在 AI 助手中提出一个需要外部工具协助的请求时(比如“帮我查一下去中山陵的路线”),Host 会通过 Client 连接到提供地图服务的 MCP Server,获取信息后,再由大模型整合并生成最终回答给你。
一、MCP的开发
1.1 wikiMCP 配置
个人使用的编程工具是Trae, 配置好的自己写的 wiki MCP:
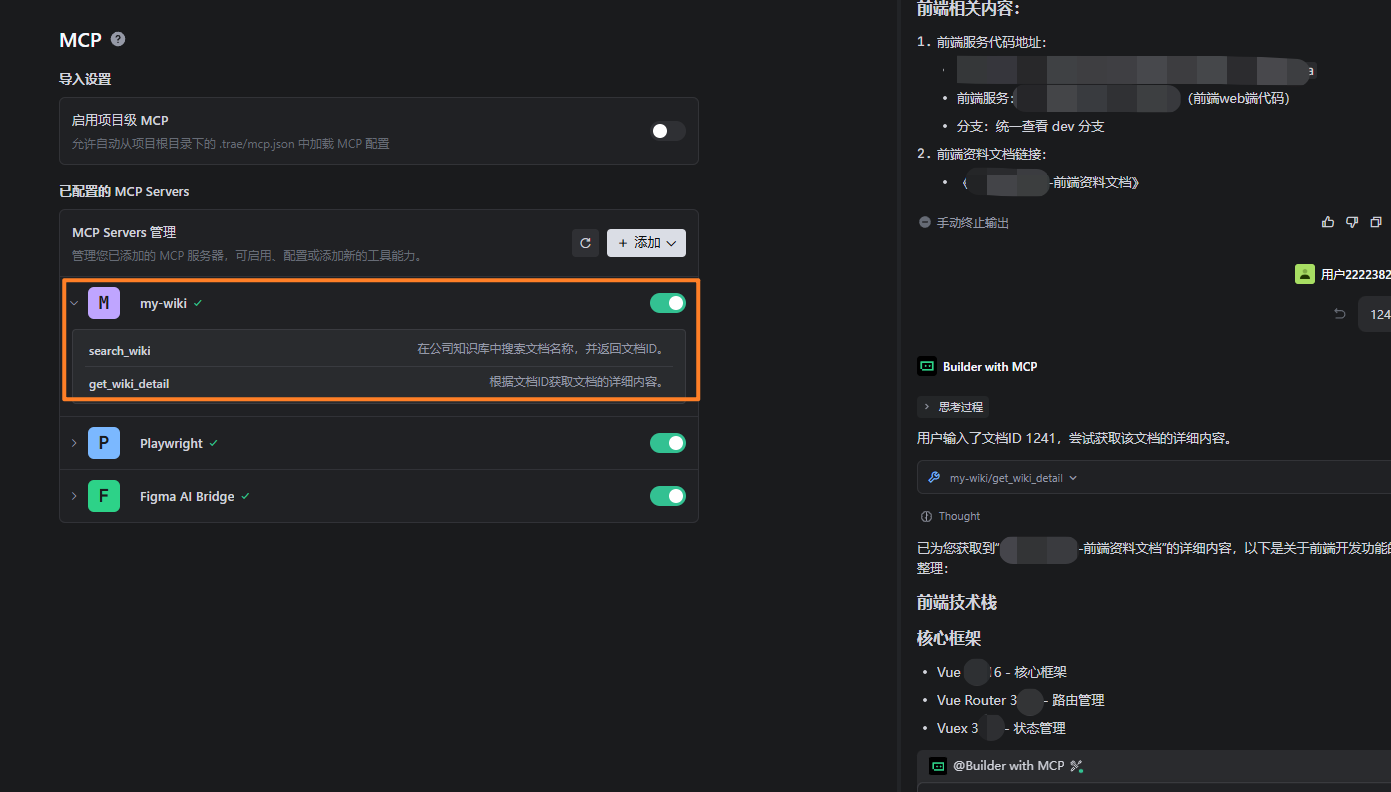
具体配置
{
"mcpServers": {
"my-wiki": {
"command": "python",
"args": [
"root/testwiki.py"
],
"env": {
"WIKI_TOKEN": "reyJhbGciOiJIUzUxMiJ9.eyJkZXB0TmFtZSI6Iuaxn-mTnOmbhuWboiIsInN5c0NvZGUiOm5"
}
}
}
}其中root/testwiki.py 提供了接口 供AI进行调用,访问wiki的数据库。
1.2 代码
testwiki.py部分代码
import os
from mcp.server.fastmcp import FastMCP
import httpx
# 1. 初始化 MCP 服务
mcp = FastMCP("MyCompanyWiki")
# --- 配置区域 ---
WIKI_BASE_URL = "https://wikix.xxxxx.com"
WIKI_API_TOKEN = os.getenv("WIKI_TOKEN")
if not WIKI_API_TOKEN:
raise ValueError("错误:找不到 WIKI_TOKEN 环境变量!")
# 2. 工具:搜索文档
@mcp.tool()
async def search_wiki(keywords: str) -> str:
"""
在公司知识库中搜索文档名称,并返回文档ID。
"""
headers = {
"accesstoken": WIKI_API_TOKEN,
"User-Agent": "MCP-Server/1.0"
}
data = {"keywords": keywords}
try:
async with httpx.AsyncClient(headers=headers, timeout=3000.0) as client:
response = await client.post(
f"{WIKI_BASE_URL}/xxx/news",
data = data
)
if response.status_code != 200:
return f"HTTP请求失败:{response.status_code}"
json_data = response.json()
# === 2. 获取数据 (关键修改) ===
# 根据你提供的 JSON,data 本身就是列表 [ {...}, {...} ]
results = json_data.get("data", [])
if not results:
return "没有找到相关文档。"
result_text = "**找到相关文档(请复制ID查询详细内容):**\n\n"
for item in results[:10]:
# 根据最新 JSON,ID字段是 pageId,标题是 pageTitle
doc_id = item.get('pageId', 'N/A')
title = item.get('pageTitle', '无标题')
result_text += f"**📄 {title}**\n`ID: {doc_id}`\n---\n"
return result_text
except Exception as e:
return f"搜索异常: {str(e)}"
# 4. 启动服务
if __name__ == "__main__":
mcp.run()1.3 使用效果
通过关键字 收索文档
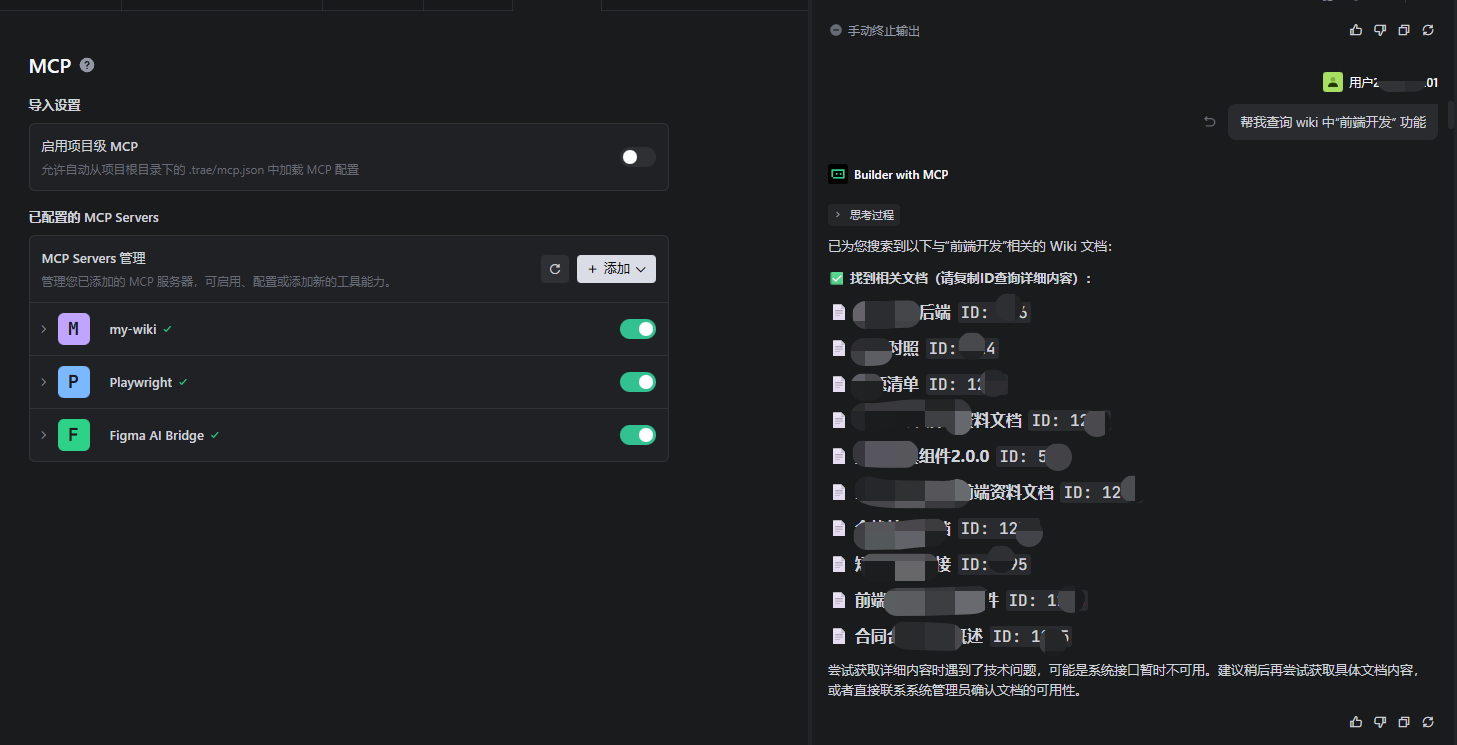
检索文档详情:
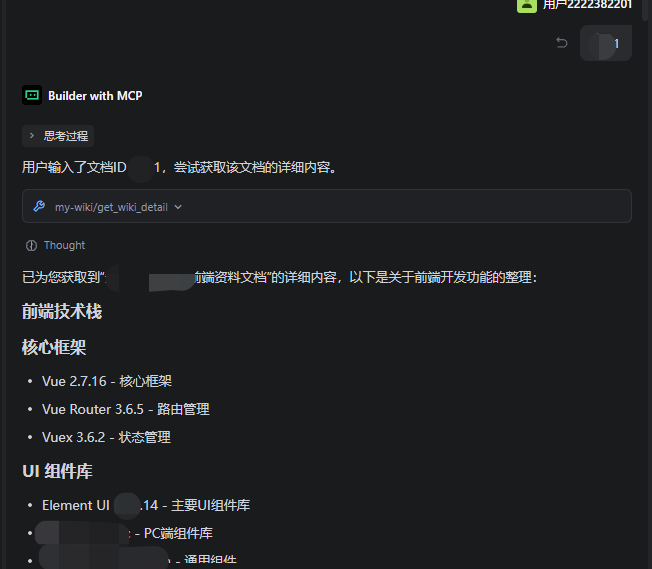
1.4 MCP 不同部署方式
启动一个 MCP 服务器的有效方式有多种。对比其他的MCP服务 标准化工具包和自己写的。部署模式:一个是使用现成的、由社区或官方维护的“标准工具包”,另一个是自己编写的“定制化服务”。
标准化工具包 (@executeautomation/...)
这种配置通常用于那些已经打包好、发布到公共仓库(如 npm)的通用工具。
{
"mcpServers": {
"Playwright": {
"command": "npx",
"args": [
"-y",
"@executeautomation/playwright-mcp-server"
],
"env": {}
}
}
}
command:npx- 这是一个 Node.js 的包执行工具。它的作用是从 npm 仓库临时下载并运行一个程序包,而无需你手动安装。
args:["-y", "@executeautomation/playwright-mcp-server"]-y:自动确认所有提示,实现无人值守安装和运行。@executeautomation/playwright-mcp-server:这是要运行的包的名称。这个包里包含了所有让 AI 能够操控浏览器的代码和逻辑。
- 特点:开箱即用。不需要关心它内部是如何实现的,只需要知道它能提供“浏览器自动化”这个能力。
自定义脚本 (root/testwiki.py)
这种配置就是你之前部署自己 Wiki 工具的方式,它指向一个你亲手编写的脚本文件。
{
"mcpServers": {
"my-wiki": {
"command": "python",
"args": [
"root/testwiki.py"
],
"env": {
"WIKI_TOKEN": "..."
}
}
}
}
command:python- 这告诉系统使用 Python 解释器来运行接下来的脚本。
args:["root/testwiki.py"]- 这是你要运行的 Python 脚本的路径。这个脚本里包含了你用
httpx等库编写的、专门用于和你的 Wiki API 通信的逻辑。
- 这是你要运行的 Python 脚本的路径。这个脚本里包含了你用
env:{"WIKI_TOKEN": "..."}- 这里设置了环境变量,比如访问令牌。这对于需要认证的自定义服务来说是必不可少的。
- 特点:高度定制。这个服务完全为你自己的业务逻辑服务,功能是独一无二的。 总结对比
| 特性 | 标准化工具包 (npx ...) |
自定义脚本 (python ...) |
|---|---|---|
| 来源 | 来自公共包管理器 (如 npm) | 来自你自己的代码文件 |
| 目的 | 提供通用的、标准化的能力 (如浏览器操作) | 提供特定的、个性化的业务能力 (如查询你的Wiki) |
| 灵活性 | 低,功能由包的作者决定 | 极高,你可以修改代码实现任何功能 |
| 开发成本 | 零,直接使用 | 高,需要自己编写和维护代码 |
| 类比 | 购买成品家具 | 自己动手做家具 |
当想使用别人已经做好的强大工具时,就用第一种;当想让自己的 AI 拥有独特的能力时,就用第二种。
二、AI 时代的数据存储与后端架构演进
开发配置完上面的wiki MCP工具后 ,对未来的开发方向也有写思考,特别是对于 后续数据的存储和处理,都会从现在的关系模式转变成为AI服务,怎样的AI数据底座,能最大发挥AI的作用。未来必定是AI的时代,就像十几年前的网购和云计算一样,颠覆整个社会。
未来架构图景:AI作为新的“中间层”
“后端提供接口供AI检索”的模式,正在演变成一个全新的三层架构:
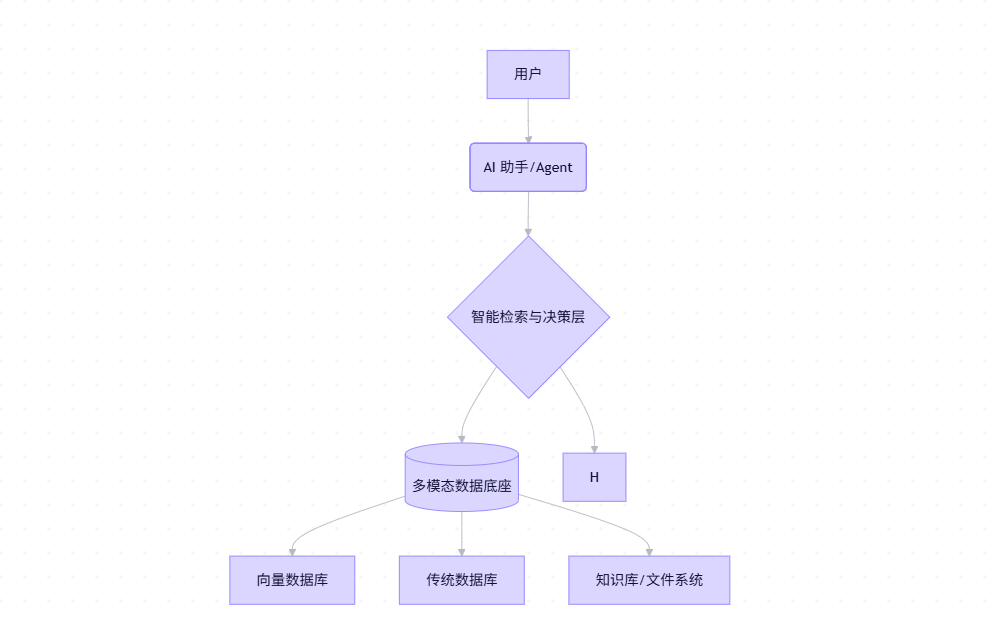
- 用户层:用户通过自然语言与AI助手交互,表达模糊的需求。
- AI代理层 (AI Agent):这是核心的“大脑”。它负责理解用户意图,并将其拆解为具体的任务。
- 数据层:这就是我们上面讨论的“AI友好型”数据底座。它包含了向量库、传统数据库和各种非结构化数据源。
核心洞察:从“人读”到“机读”的范式转移
随着 AI 的发展,数据存储和后端架构正在经历一场从**“面向人类阅读”向“面向 AI 理解”**的根本性转变。未来的核心交互模式将是:用户通过自然语言指挥 AI,AI 调用后端接口检索数据,经过推理分析后辅助用户决策。
数据结构设计的演变
传统的数据结构(如关系型数据库的行/列)主要为了方便人类浏览和简单的关键词匹配,而 AI 时代的存储设计更侧重于语义理解和多模态融合。
- 语义化存储(向量化)
- 传统方式:依赖关键词匹配(如搜索“汽车”只能找到包含这两个字的文档)。
- AI 方式:利用嵌入模型将文本、图像等非结构化数据转化为高维向量。在向量空间中,“汽车”和“轿车”的距离会非常近,从而实现基于含义而非字面的检索。
- 保留上下文与层级
- 在将长文档存入系统时,不能简单切碎,必须保留标题、章节等层级信息。这样 AI 在检索到片段时,才能结合上下文给出准确答案。
- 多模态融合
- 统一处理文本、PDF、图片、视频等多种格式,将其转化为 AI 可理解的统一数学表达。
️ 未来架构全景图:AI 作为新的“中间层”
传统的“前端-后端-数据库”三层架构正在演变为以 AI 为核心的智能架构。
- 用户层:通过自然语言表达模糊或复杂的需求。
- AI 代理层 (Agent):系统的“大脑”。负责理解意图、拆解任务、决定调用哪些工具或查询哪些数据。
- 数据底座层:
- 混合存储:结合了向量数据库(存语义)、传统数据库(存业务逻辑/元数据)和知识库(存非结构化文件)。
- 一体化趋势:现代架构倾向于使用支持 SQL、全文检索和向量搜索的一体化数据库,减少数据在不同系统间搬运的延迟。
️ 关键技术栈详解
为了实现上述架构,以下技术栈是当前及未来的核心支撑:
| 技术领域 | 核心技术/概念 | 作用与价值 |
|---|---|---|
| 数据存储 | 向量数据库 | 专门存储数据的“语义指纹”,实现毫秒级的相似性检索。 |
| 混合检索 | 结合关键词检索(精准匹配)和向量检索(语义匹配),提高准确率。 | |
| 核心编排 | RAG | 检索增强生成。先查资料再回答,解决大模型幻觉问题,确保数据时效性。 |
| 重排序 | 对初步检索结果进行二次精细筛选,把最相关的信息喂给 AI。 | |
| 后端升级 | 库内推理 | 将 AI 模型直接植入数据库内核,数据不出库即可完成分析,兼顾安全与性能。 |
| NL2SQL | 让 AI 自动将自然语言转换为 SQL 语句,直接操作传统业务库。 | |
| 连接标准 | MCP | 类似“USB 接口”的标准协议,统一了 AI 与外部数据源(文件、API)的连接方式。 |
总结
未来的后端开发核心竞争力,将从单纯的 API 编写,转移到如何构建高效、精准且安全的**“AI 数据底座”**。谁能更好地将私有数据转化为 AI 可理解的格式(向量+上下文),并提供标准化的调用接口(MCP/RAG),谁就能在未来的 AI 应用生态中占据主动。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)