从VLA到VLWA!清华&极佳发布统一大模型Vega,用自然语言指令重构驾驶决策
「面向自然语言指令的统一VLWA大模型」
目录
02 autoregressive与diffusion的统一融合
距离VLA模型成为自动驾驶领域的研究热点,不过一年多时间。
这段时间里,大家都在围绕“如何让模型更好地理解场景、生成合理轨迹”发力。
这些工作本质上都在延续一个核心逻辑——让模型模仿专家的驾驶行为,或者在预设的封闭指令集中做选择。
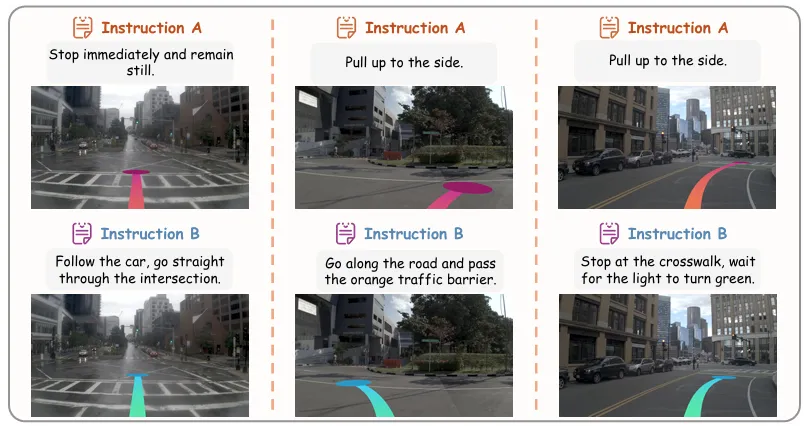
但实际驾驶场景里,用户的需求远不止“左转”“直行”这么简单。赶时间时可能想“超越前车赶上绿灯”,路过施工路段需要“避开橙色路障缓慢通过”,带老人孩子时会要求“保持平稳驾驶,避免急刹”。
这些开放域的自然语言指令,恰恰是现有VLA模型的短板——它们要么无法理解复杂意图,要么生成的轨迹与指令脱节。
这背后的核心矛盾其实被很多研究忽略了:自动驾驶不仅要“会开车”,还要“懂用户”。当大家都在卷生成器架构、堆数据规模时,清华联合极佳团队提出的Vega模型,把注意力拉回了这个更贴近实际应用的问题上:
如果让自动驾驶系统像人类司机一样,能听懂并执行自然语言指令,该怎么做?
Vega没有盲目跟风堆砌新模块,而是从数据集构建到模型架构进行了全链路重构,首次实现了“指令-轨迹-场景”的三位一体建模,为个性化自动驾驶提供了一套完整的解决方案。
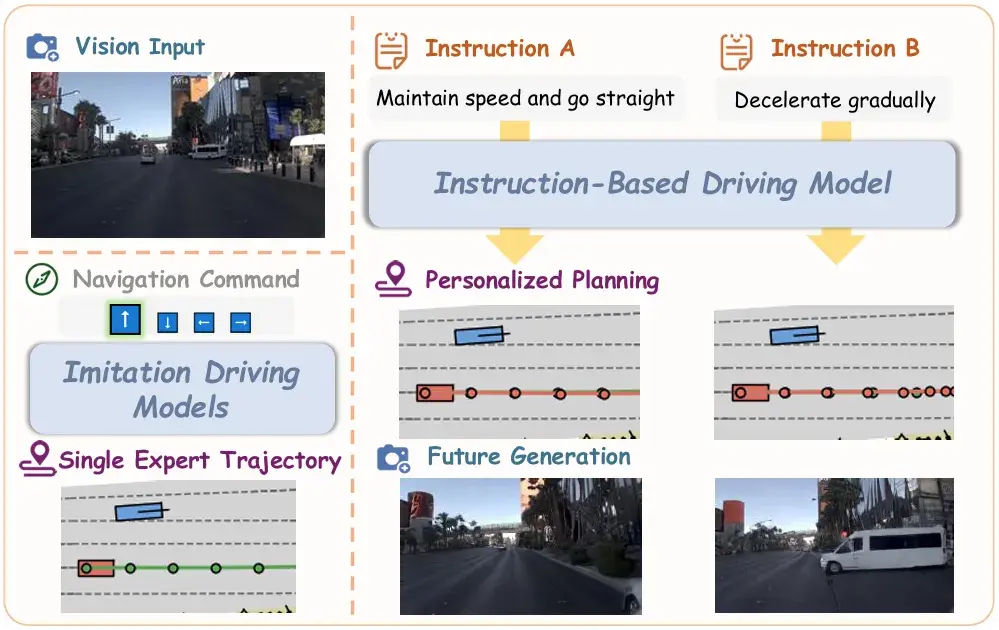
01 从"模仿驾驶"到"指令驾驶"的范式迁移
自动驾驶的本质,是让机器理解环境、响应意图并执行动作的闭环过程。传统模仿驾驶模型的核心逻辑,是基于历史观测和动作预测当前行为,其数学表达为:
这种模式下,模型只能复刻训练数据中的专家轨迹,缺乏对用户实时意图的响应能力。即使是新一代VLA模型,也仅能同时输出场景描述和动作预测,未能将语言指令作为核心决策依据。Vega的首要创新,是正式提出"指令驾驶"(Instructional Driving)概念,将用户语言指令纳入决策闭环,重构了自动驾驶的数学模型:
其中代表当前用户自然语言指令,这一改动看似简单,却从根本上改变了模型的优化目标——从"复刻专家行为"转向"理解并执行用户意图"。
要支撑这一范式迁移,高质量数据集是基础。团队构建了包含10万条场景数据的InstructScene数据集,基于NAVSIM仿真环境,通过"场景理解+指令生成"两阶段自动化标注流程:先用VLM模型分析历史观测与未来动作,生成场景描述;再结合规则化指令作为补充,最终形成"图像-指令-动作"三元组数据。这种标注方式既保证了指令的多样性,又通过规则约束确保了驾驶意图的准确性,为模型学习指令与动作的映射关系提供了关键支撑。
02 autoregressive与diffusion的统一融合
解决了"数据供给"问题后,如何弥合高维输入与低维输出的信息鸿沟成为关键。Vega提出的视觉-语言-世界-动作统一模型,核心在于通过联合建模未来图像生成(世界建模)与轨迹规划(动作生成),为模型提供密集的像素级监督信号,从而学习指令、动作与视觉结果之间的因果关系。
混合范式设计
模型创新性地采用"autoregressive+diffusion"混合架构:
- autoregressive流水线:负责处理视觉输入和语言指令的理解任务。视觉输入通过VAE编码器和SigLIP ViT编码器提取双重特征,语言指令则采用Qwen2.5分词器进行编码,两者通过联合注意力机制实现跨模态交互。
- diffusion流水线:承担未来图像生成和轨迹规划的生成任务。通过在噪声中逐步去噪,生成符合物理规律的未来场景图像和驾驶轨迹,避免了传统生成模型易出现的轨迹不合理问题。
这种设计的巧妙之处在于,将理解与生成任务解耦但又通过统一框架融合,既保证了对复杂指令的精准理解,又确保了生成结果的可行性与一致性。
这种设计的巧妙之处在于,将理解与生成任务解耦但又通过统一框架融合,既保证了对复杂指令的精准理解,又确保了生成结果的可行性与一致性。
多模态交互机制
为实现各模态间的高效信息流转,Vega采用了Mixture-of-Transformers(MoT)架构,为视觉理解、语言处理、图像生成和动作规划分别配置独立的Transformer模块,所有可训练参数均实现模态专用化。这种设计相比MoE(混合专家)仅在FFN层分离权重的方式,进一步提升了模型对不同模态任务的适配能力,收敛速度更快且模型容量更高。
在输入序列构建上,模型采用交错式排列:历史图像和动作在前,语言指令紧随其后,最后拼接带噪声的目标动作或未来图像。通过因果注意力掩码确保每个模块只能关注前文信息,既符合驾驶场景的时序逻辑,又避免了信息泄露。
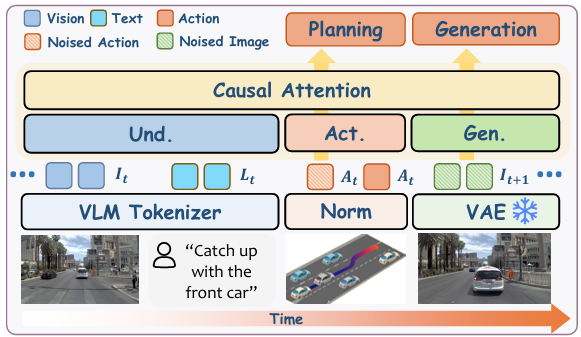
图| 统一视觉 - 语言 - 世界 - 动作模型框架图
训练与推理策略
训练阶段,模型优化联合损失函数,同时学习动作规划和未来图像生成:
其中 是动作损失(基于归一化相对动作的MSE),
是图像损失(基于VAE latent的MSE),通过平衡两项损失,确保动作与视觉结果的一致性。推理阶段,采用无分类器引导(CFG)策略,同时启用图像引导和文本引导,在生成轨迹时既考虑物理可行性,又严格遵循语言指令。这种双引导机制让模型在面对模糊指令时,能通过视觉上下文进行合理推断,例如在“靠近前车”指令下,会根据当前车距自动调整加速强度。
03 实验验证:性能与泛化能力的双重突破
在NAVSIM v1和v2两大基准测试中,Vega展现出了优异的综合性能:
- 在NAVSIM v2(含反应式交通流的高保真仿真)中,基础版本取得86.9的EPDMS分数,采用best-of-N策略后进一步提升至89.4,在行驶方向合规性、交通灯遵守率、车道保持和历史舒适度等关键指标上超越现有SOTA方法。
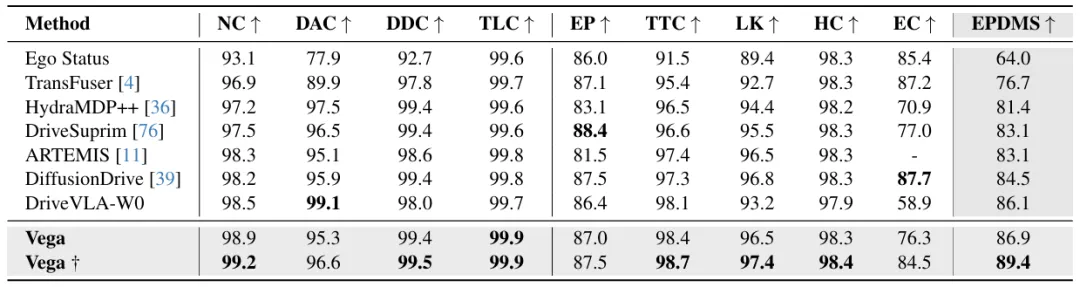
图| NAVSIM v2 基准与最先进方法的对比表
- 在NAVSIM v1中,仅使用单前置摄像头的Vega取得87.9的PDMS分数,与多相机+激光雷达的BEV-based方法性能相当,启用best-of-N策略后达到89.8,证明了模型在有限传感器配置下的高效感知与规划能力。
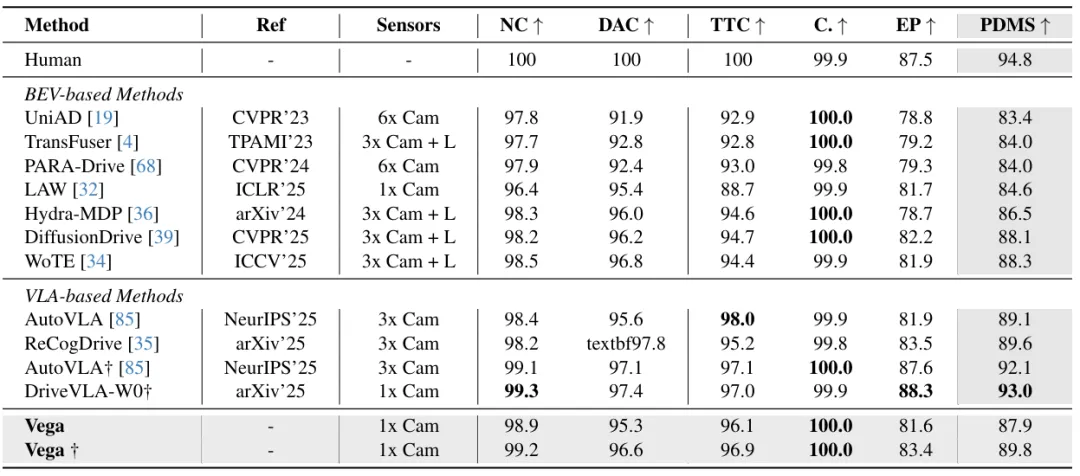
图| NAVSIM v1 基准与最先进方法的对比表
值得注意的是,消融实验验证了各核心模块的有效性:
- 未来图像生成任务的引入,使PDMS和EPDMS分数分别提升约10个百分点,证明了密集视觉监督对指令跟随能力的强化作用。
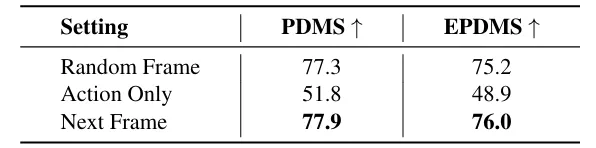
图| 未来图像预测的消融实验表
- 交错式图像-动作序列训练相比传统非交错式设计,收敛速度更快,最终损失更低,且序列长度越长效果越优,验证了时序交互建模的重要性。
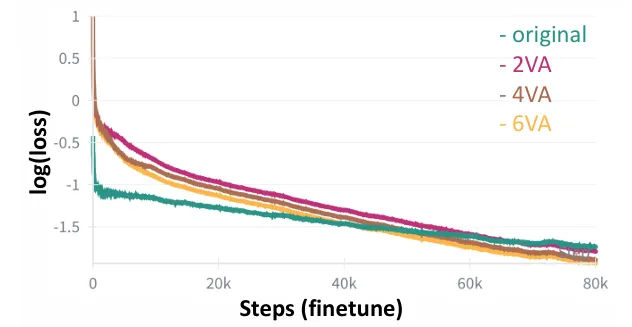
图| 交错式图像 - 动作序列的消融实验图
- 独立动作专家模块相比直接使用VLM或diffusion模块,在规划精度上实现显著提升,同时降低了计算成本,证明了模态专用化设计的合理性。
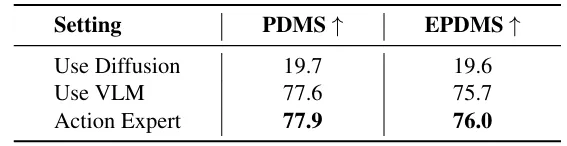
图| 动作专家的消融实验表
定性实验中,Vega在相同场景下能根据不同指令生成差异化轨迹:面对"立即加速追赶前车"和"保持稳定跟随前车"的指令,模型会分别调整加速策略;在路口场景中,"快速直行"和"减速避让行人"的指令会引导模型生成完全不同的路径规划,且对应的未来图像生成结果与动作高度一致,充分体现了模型对指令的精准理解与执行能力。
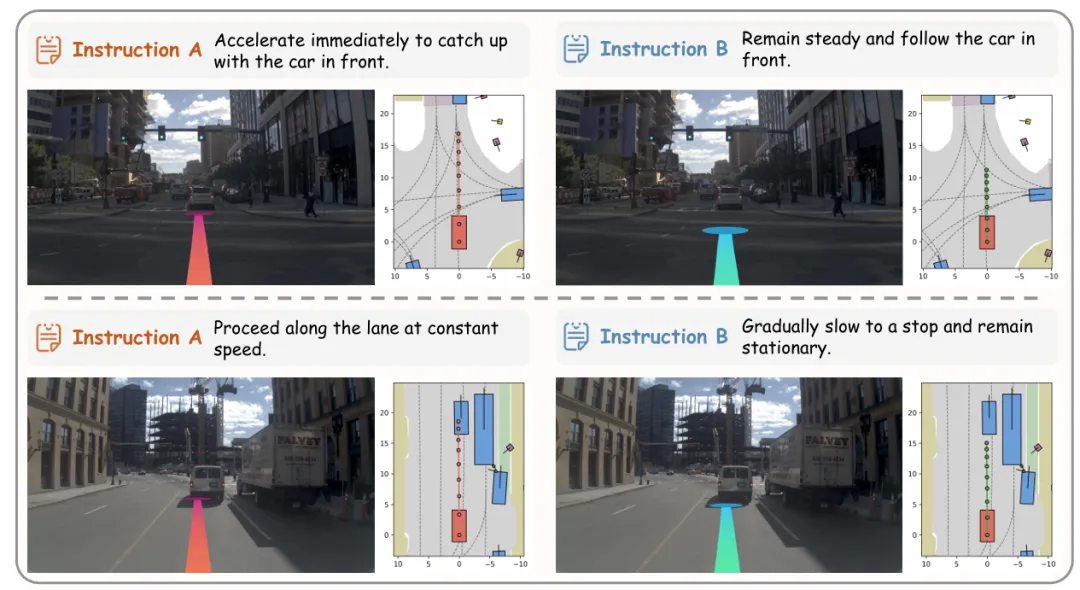
图| 基于指令的规划示例图
04 局限与行业启示
尽管Vega取得了显著突破,但仍存在一些待解决的问题:在NAVSIM v1基准上,其性能略低于部分专门优化风险规避策略的VLA模型,这与该基准的指标权重偏向保守驾驶有关;模型对极端天气或复杂交通参与者交互的指令响应能力,仍需真实道路数据的进一步验证;此外,diffusion生成过程的计算开销虽已优化,但在低算力硬件上的实时性仍有提升空间。
从行业视角来看,Vega的价值不仅在于提出了一个高性能的指令驱动驾驶模型,更在于构建了一套完整的技术范式:
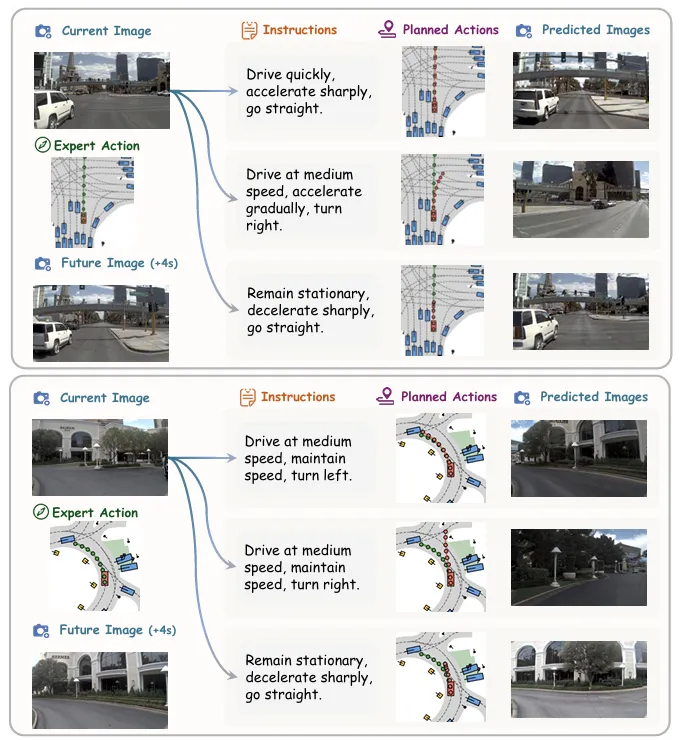
图| 基于指令和动作的未来图像生成图
- 数据层面,证明了通过VLM+规则的自动化标注方式,能够高效构建大规模指令驱动驾驶数据集,为后续研究提供了低成本的数据解决方案。
- 模型层面,验证了"理解+生成"双任务联合建模的有效性,为解决高维输入与低维输出的信息鸿沟提供了新思路,这种范式可迁移至机器人操作、智能导航等其他需要语言-视觉-动作联动的领域。
- 应用层面,首次实现了开放域自然语言指令的驾驶规划,让自动驾驶从"被动执行导航"向"主动响应需求"迈进,为个性化、智能化出行体验奠定了技术基础。
05 总结
Vega通过构建InstructScene数据集和统一的视觉-语言-世界-动作模型,成功突破了现有自动驾驶系统在指令跟随能力上的局限,证明了自然语言与视觉、动作的深度融合能够显著提升驾驶的个性化与智能化水平。其混合架构设计、多模态交互机制和联合训练策略,为后续相关研究提供了重要参考。
随着自动驾驶技术从"能开"向"开好"演进,用户对驾驶体验的个性化需求将日益凸显。Vega的探索表明,语言作为人类意图的最高效表达方式,将成为下一代自动驾驶系统的核心交互接口。未来,随着模型在真实场景数据上的持续优化、物理先验知识的融入以及计算效率的进一步提升,指令驱动的自动驾驶有望从实验室走向实际应用,真正实现"车随语动"的智能出行愿景。
Ref
论文标题:Vega: Learning to Drive with Natural Language Instructions
论文地址:https://arxiv.org/abs/2603.25741
项目地址:https://zuosc19.github.io/Vega

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)