【晓天衡宇·评测社区】QwenClaw评测榜单正式发布:12款顶流AI横评,谁才是龙虾的最佳搭档?
【榜单简介】
本榜单以 QwenClawBench 为核心评测基准,对12个主流大语言模型在真实世界智能体场景下的综合能力开展系统性评测。
QwenClawBench 是一个面向 OpenClaw 智能体的真实用户场景评测基准,最初在 Qwen3.6-Plus 的研发过程中作为内部基准构建,现已优化并开源。该基准聚焦实际生产力需求,核心特性如下:
1、8 大核心领域|覆盖 OpenClaw 高频使用场景
2、100道实战任务 | 精心选取自真实用户生产力场景
3、独立容器测评|支持任务环境隔离与大规模并行测评
4、仿真工作环境|配置独立工作目录,高度还原用户真实工作流
【榜单速览】
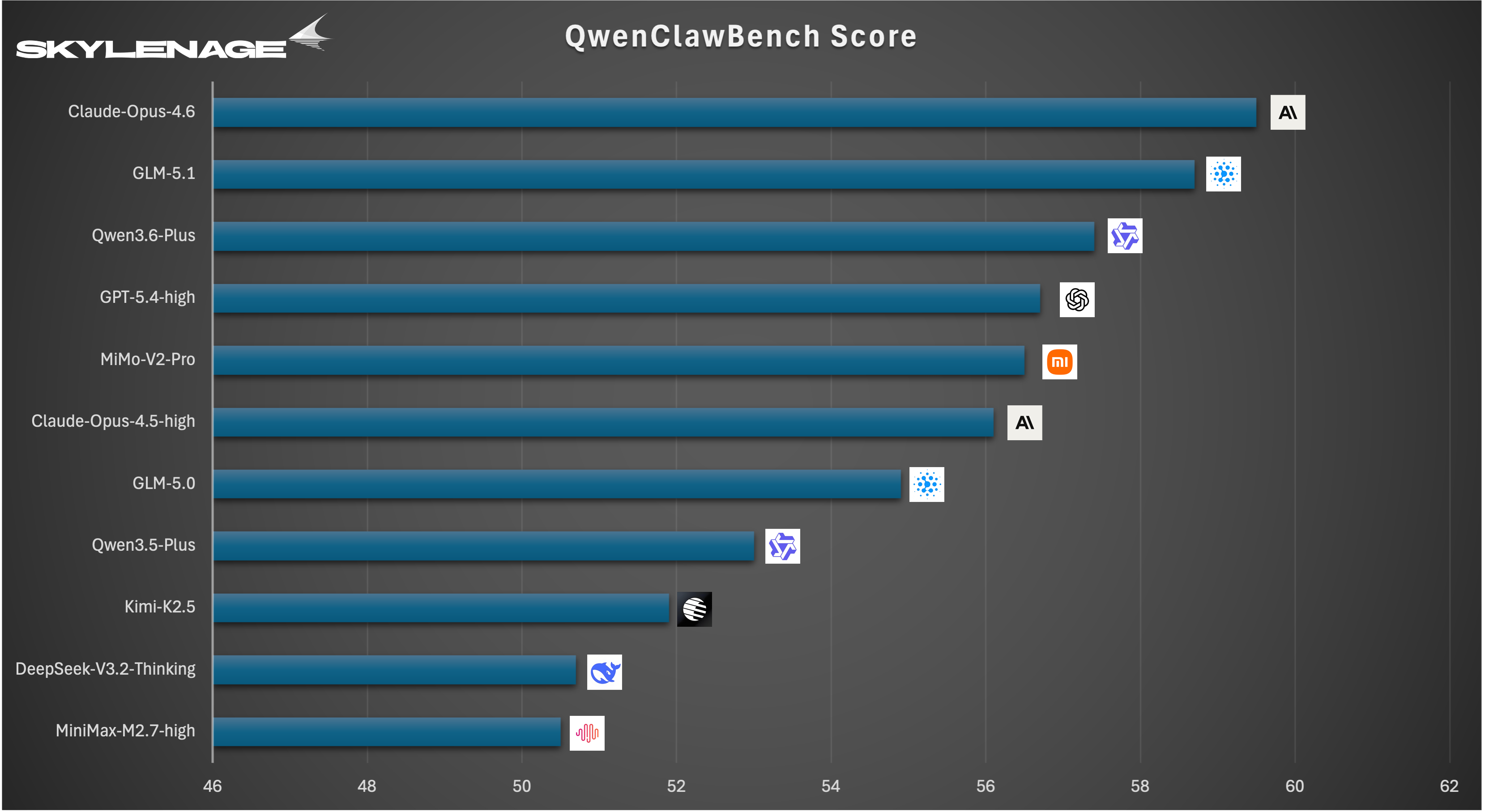
👉🏻查看完整排名以及细分维度的详细对比数据,请访问【晓天衡宇•评测社区】官方平台
完整榜单:https://skylenage-ai.github.io/QwenClawBench-Leaderboard
开源代码:https://github.com/SKYLENAGE-AI/QwenClawBench
数据集:https://huggingface.co/datasets/skylenage-ai/QwenClawBench
【评测集解读】
评测维度
QwenClawBench 在任务设计上注重真实性与复杂性,涵盖 8 个领域的 100 道任务。
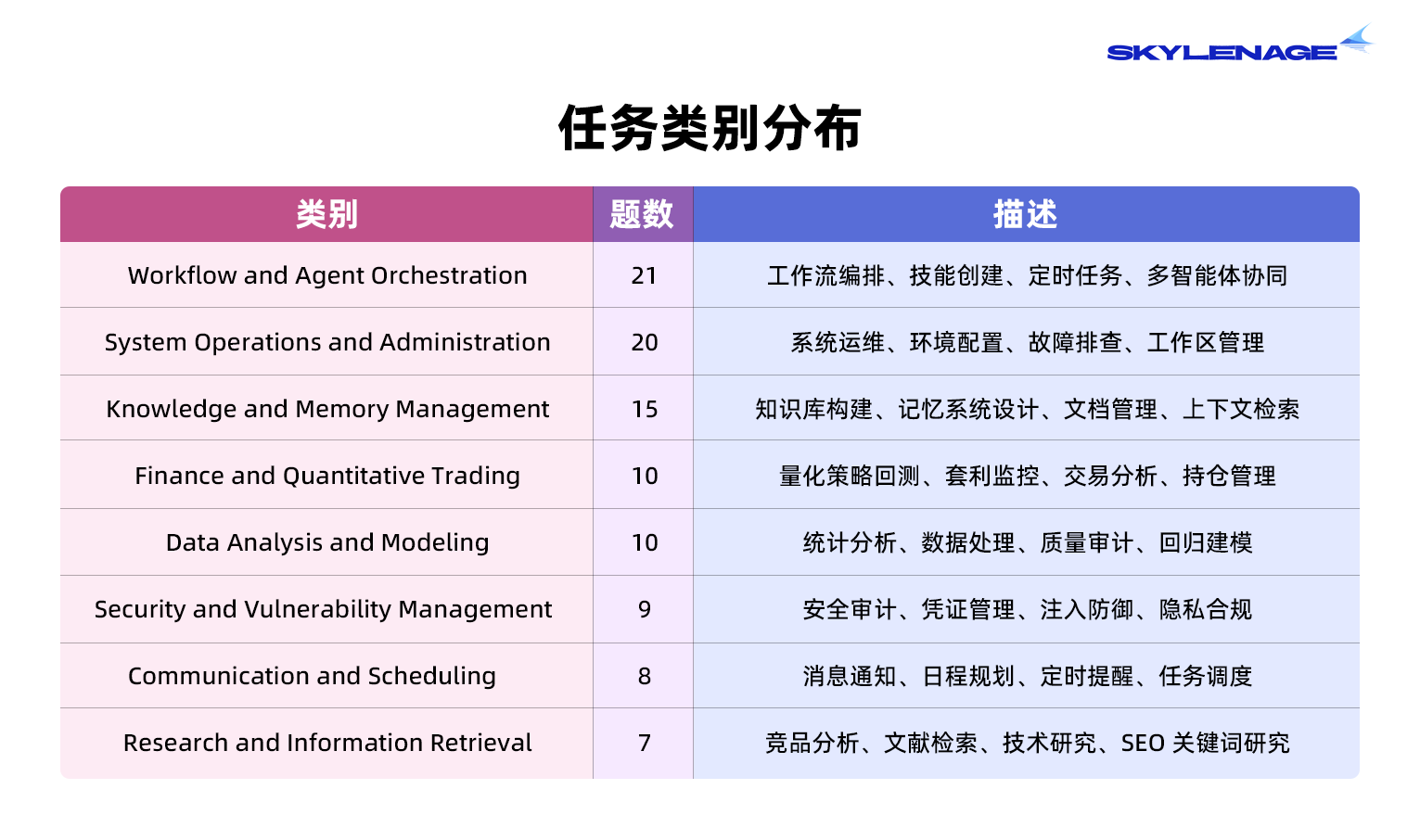
数据标准
每道任务是一个 Markdown 文件(data/tasks/task_*.md),包含 YAML Frontmatter 头部和结构化的正文分节。
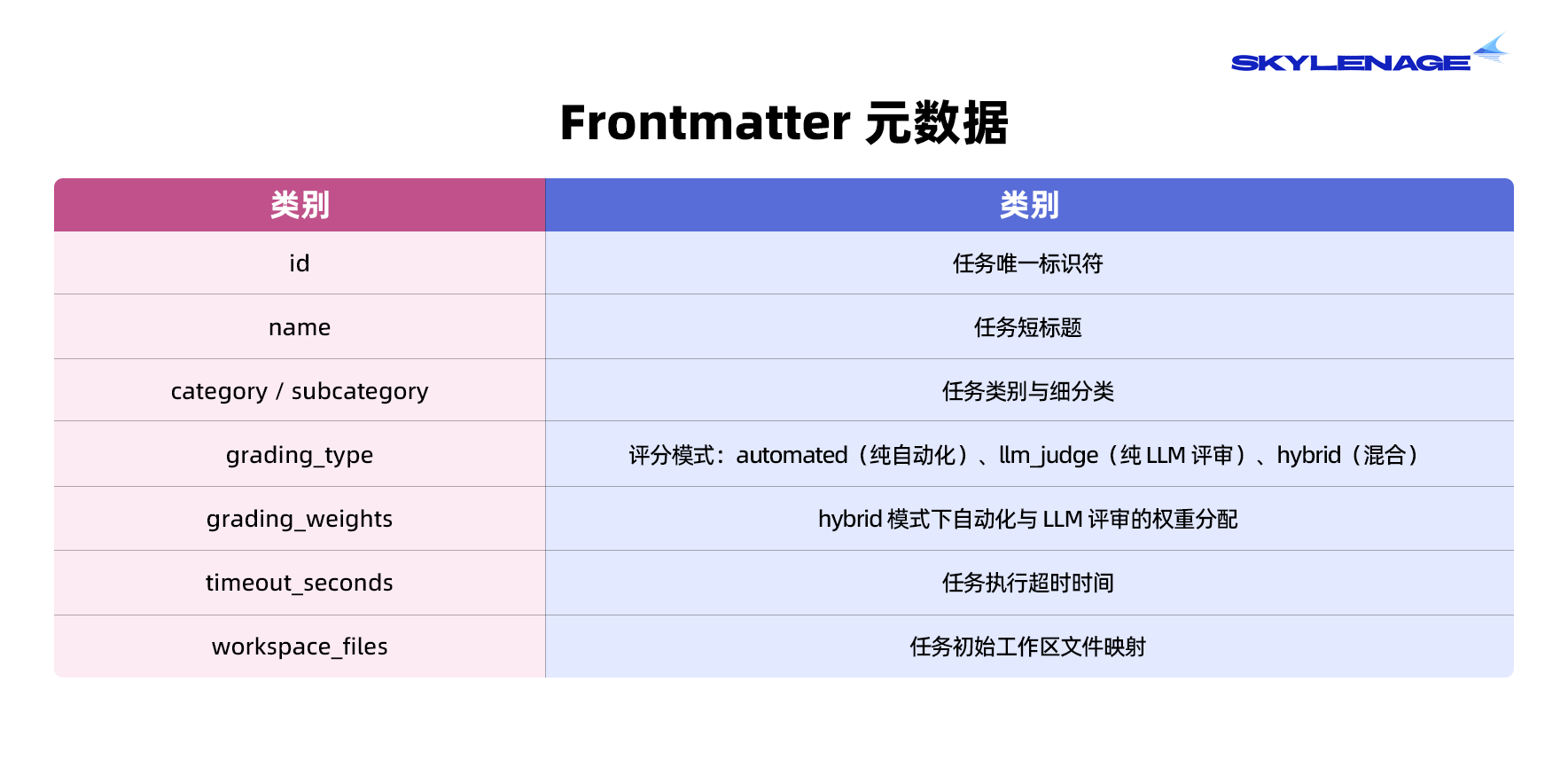

工作目录:
每道任务在 data/assets/<task_id>/ 下有一个对应目录,包含初始工作区文件(代码、配置、数据、日志等)。任务执行前,这些文件会被映射到 Docker 容器的工作区中。
【评分标准】
QwenClawBench 支持三种评分模式:automated、llm_judge 和 hybrid。
1、Automated(自动化评分):
任务定义中嵌入 Python 函数 grade(transcript, workspace_path),对智能体的交付物进行确定性的规则检查——验证输出文件、命令结果和工作区状态。最终分数为各检查维度的平均值。
2、LLM Judge(LLM 评审):
评审模型(默认 claude-opus-4.5)根据 rubric 对智能体的操作轨迹进行多维度评分,每个维度 0.0 到 1.0,最终加权平均。
3、Hybrid(混合评分):
两种方式独立运行后按 grading_weights 合并。两者设计上互补:自动化检查针对具体交付物做基于规则的基准核查,LLM 评审则评估智能体推理轨迹的质量与连贯性。
【榜单结论】
1. 模型能力评估的重心从“对话生成”转向“任务执行”
模型的核心价值不再仅由文本质量定义,而是取决于在真实环境中调用工具、操作资产并交付结果的能力。评测表明,缺乏环境交互与执行反馈的模型,难以胜任实际生产力场景。QwenClawBench 通过独立沙箱环境与仿真工作文件,将评估焦点从"说得对"转向"做得对",更贴近企业自动化需求。
2. 复杂生产力场景下,主流模型仍有明显提升空间
在 8 大核心领域的 100 道实战任务中,即便是头部模型,在复杂工作流编排与系统操作类任务上的表现仍存在波动。这说明当前模型在处理多约束、多步骤的真实业务逻辑时,稳定性与泛化能力仍需持续迭代。尤其在需要跨工具协同、状态保持的场景中,模型表现与理想落地水平之间仍有差距。
3. 长链条与多轮交互决定落地上限,评估体系亟待同步演进
任务复杂度提升后,误差累积与状态漂移问题显著放大,成为制约智能体可靠性的关键瓶颈。然而,现有评估多聚焦单轮输出质量,对长程规划、异常恢复、多轮对话一致性等维度的量化仍不成熟。构建更细粒度的动态评测机制,并引入跨任务记忆、长期目标分解等评估维度,是下一阶段基准演进的重要方向。
【了解更多】
QwenClawBench评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据:https://skylenage.net/sla/leaderboard
👇关注晓天衡宇•评测社区官方平台,获取更多大模型相关知识~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)