Hugging Face 模型微调训练(基于 BERT 的中文评价情感分析)
·
1. 模型微调的基本概念与流程
微调是指在预训练模型的基础上,通过进一步的训练来适应特定的下游任务。BERT 模型通过预训练来学习语言的通用模式,然后通过微调来适应特定任务,如情感分析、命名实体识别等。微调过程中,通常冻结 BERT 的预训练层,只训练与下游任务相关的层。本课件将介绍如何使用 BERT 模型进行情感分析任务的微调训练。


欠拟合和过拟合
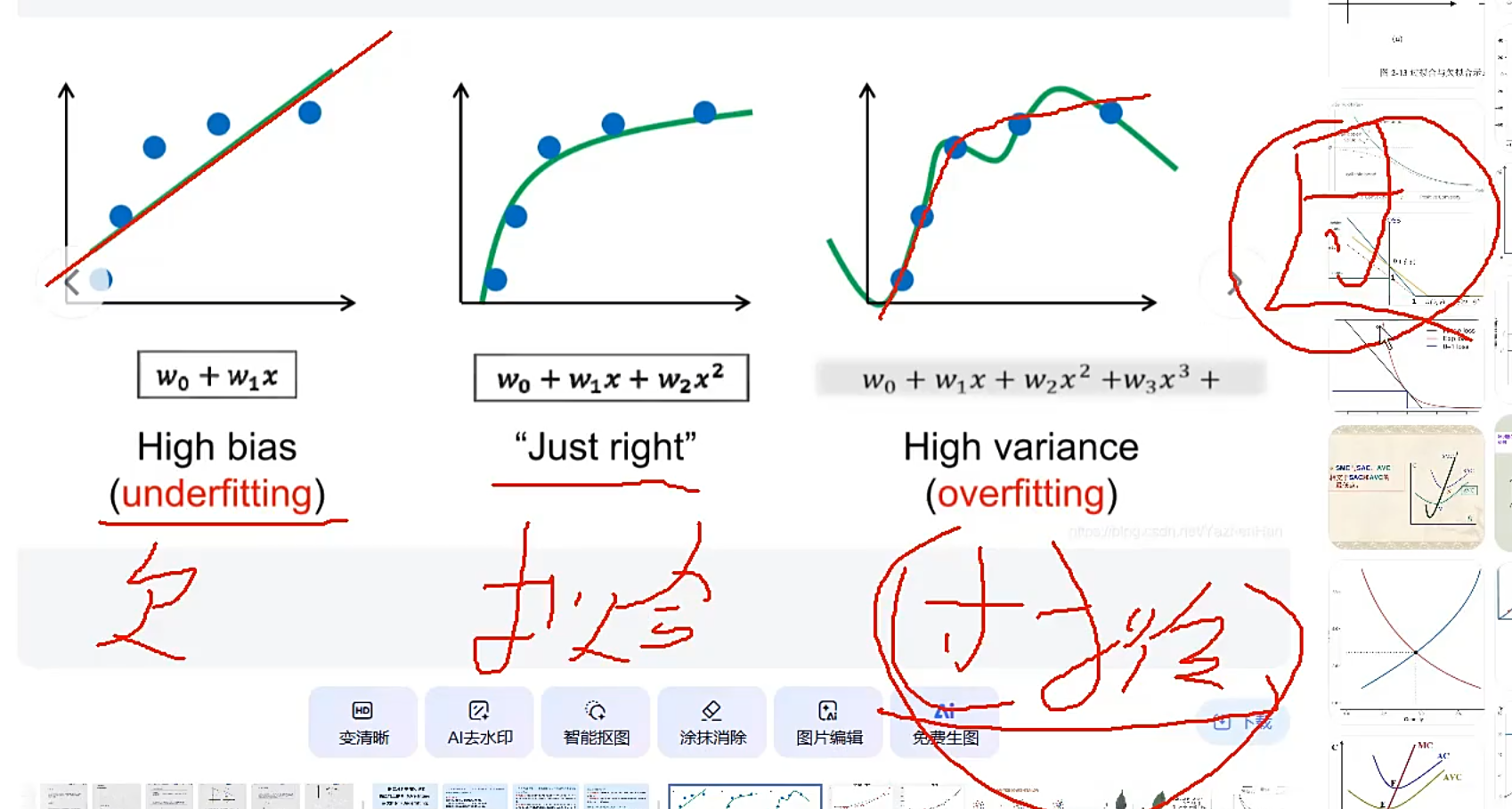
过拟合描述太细会丧失泛华性
判断模型是否过拟合或者欠拟合:通过损失来判断

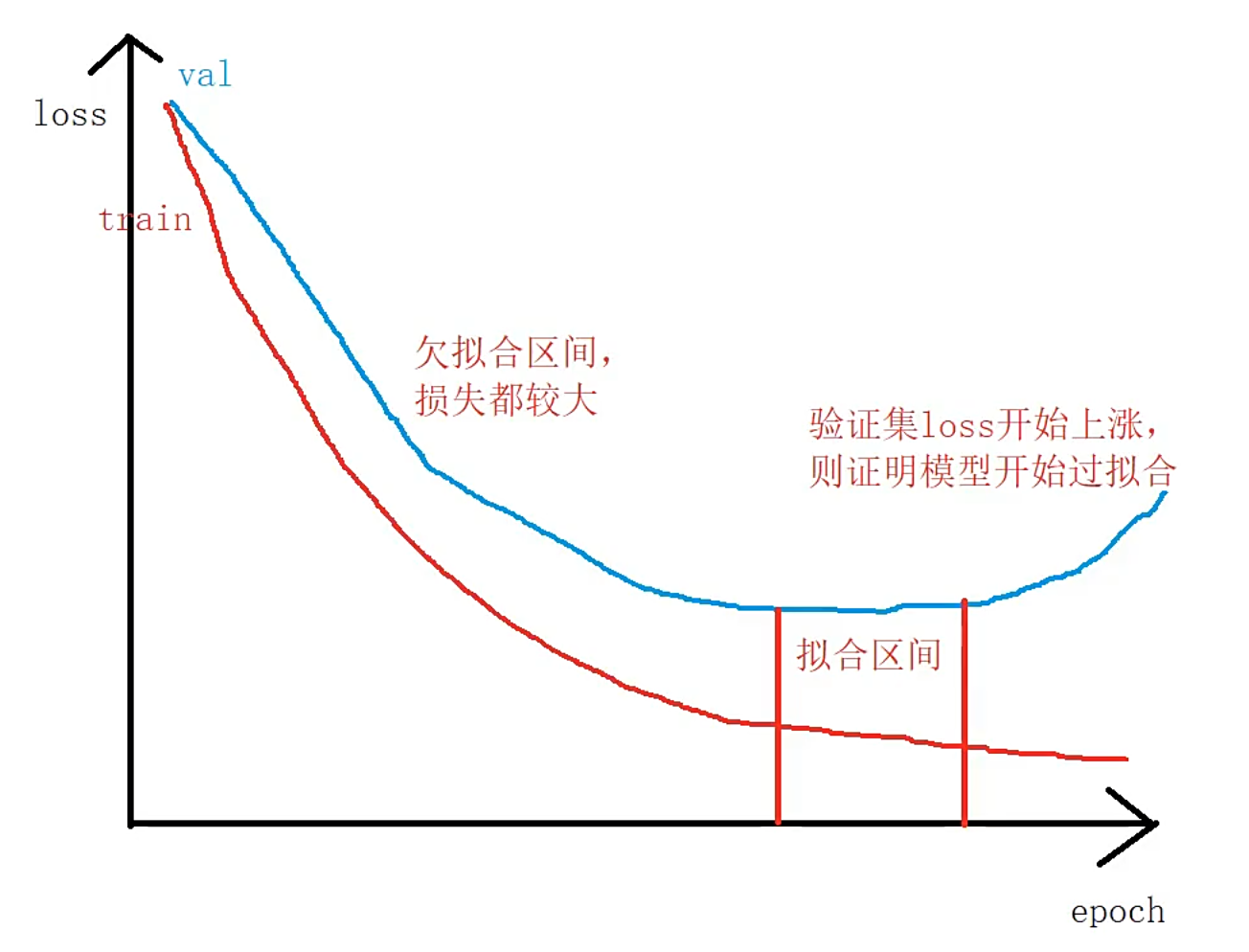
2. 加载数据集
情感分析任务的数据通常包括文本及其对应的情感标签。使用 Hugging Face 的 datasets 库可以轻松地加载和处理数据集。
from datasets import load_dataset
# 加载数据集
dataset = load_dataset('csv', data_files="data/ChnSentiCorp.csv")
# 查看数据集信息
print(dataset)
2.1 数据集格式
Hugging Face 的 datasets 库支持多种数据集格式,如 CSV、JSON、TFRecord 等。在本案例中,使用CSV 格式,CSV 文件应包含两列:一列是文本数据,另一列是情感标签。
2.2 数据集信息
加载数据集后,可以查看数据集的基本信息,如数据集大小、字段名称等。这有助于我们了解数据的分布情况,并在后续步骤中进行适当的处理。
3. 制作 Dataset
加载数据集后,需要对其进行处理以适应模型的输入格式。这包括数据清洗、格式转换等操作。、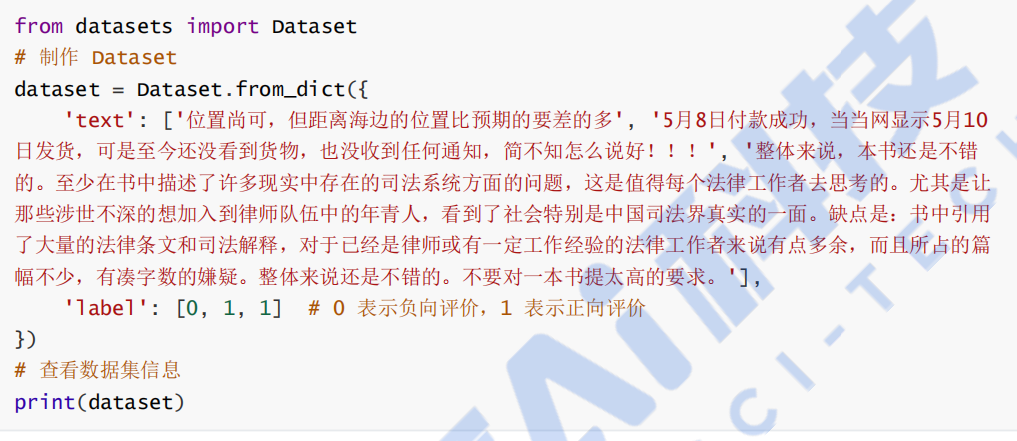
3.1 数据集字段
在制作 Dataset 时,需定义数据集的字段。在本案例中,定义了两个字段: text (文本)和
label (情感标签)。每个字段都需要与模型的输入和输出匹配。
3.2 数据集信息
制作 Dataset 后,可以通过 dataset.info 等方法查看其大小、字段名称等信息,以确保数据集的正确性和完整性。
4. vocab 字典操作
在微调 BERT 模型之前,需要将模型的词汇表(vocab)与数据集中的文本匹配。这一步骤确保输入的文本能够被正确转换为模型的输入格式。

4.1 词汇表(vocab)
BERT 模型使用词汇表(vocab)将文本转换为模型可以理解的输入格式。词汇表包含所有模型已知的单词及其对应的索引。确保数据集中的所有文本都能找到对应的词汇索引是至关重要的。
4.2 文本转换
使用 tokenizer 将文本分割成词汇表中的单词,并转换为相应的索引。此步骤需要确保文本长度、特殊字符处理等都与 BERT 模型的预训练设置相一致。
5. 下游任务模型设计
在微调 BERT 模型之前,需要设计一个适应情感分析任务的下游模型结构。通常包括一个或多个全连接层,用于将 BERT 输出的特征向量转换为分类结果。

5.1 模型结构
下游任务模型通常包括以下几个部分:
BERT 模型:用于生成文本的上下文特征向量。
Dropout 层:用于防止过拟合,通过随机丢弃一部分神经元来提高模型的泛化能力。
全连接层:用于将 BERT 的输出特征向量映射到具体的分类任务上。
5.2 模型初始化
使用 BertModel.from_pretrained() 方法加载预训练的 BERT 模型,同时也可以初始化自定义的全连接层。初始化时,需要根据下游任务的需求,定义合适的输出维度。
6. 自定义模型训练
模型设计完成后,进入训练阶段。通过数据加载器(DataLoader)高效地批量处理数据,并使用优化器更新模型参数。
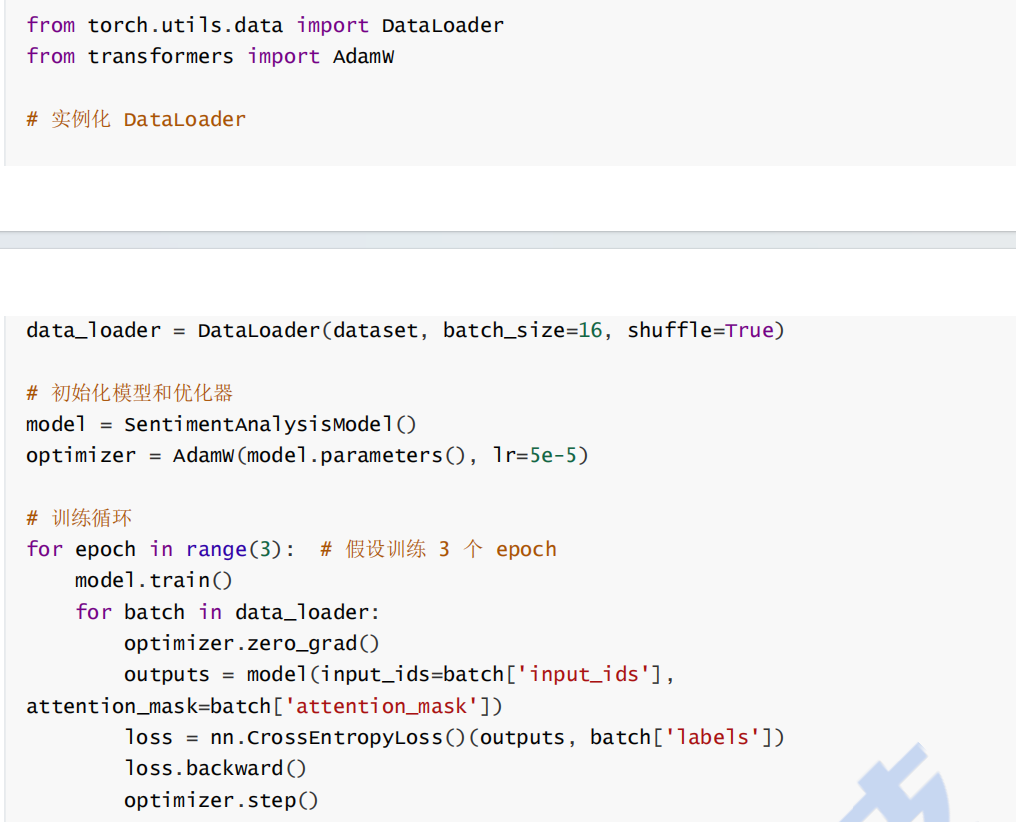
6.1 数据加载
使用 DataLoader 实现批量数据加载。 DataLoader 自动处理数据的批处理和随机打乱,确保训练的高效性和数据的多样性。
6.2 优化器
AdamW 是一种适用于 BERT 模型的优化器,结合了 Adam 和权重衰减的特点,能够有效地防止过拟合。
6.3 训练循环
训练循环包含前向传播(forward pass)、损失计算(loss calculation)、反向传播(backward
pass)、参数更新(parameter update)等步骤。每个 epoch 都会对整个数据集进行一次遍历,更新模型参数。通常训练过程中会跟踪损失值的变化,以判断模型的收敛情况。
7. 最终效果评估与测试
在模型训练完成后,需要评估其在测试集上的性能。通常使用准确率、精确率、召回率和 F1 分数等指标来衡量模型的效果。
7.1 准确率(Accuracy)
准确率是衡量分类模型整体性能的基本指标,计算公式为正确分类的样本数量除以总样本数量。
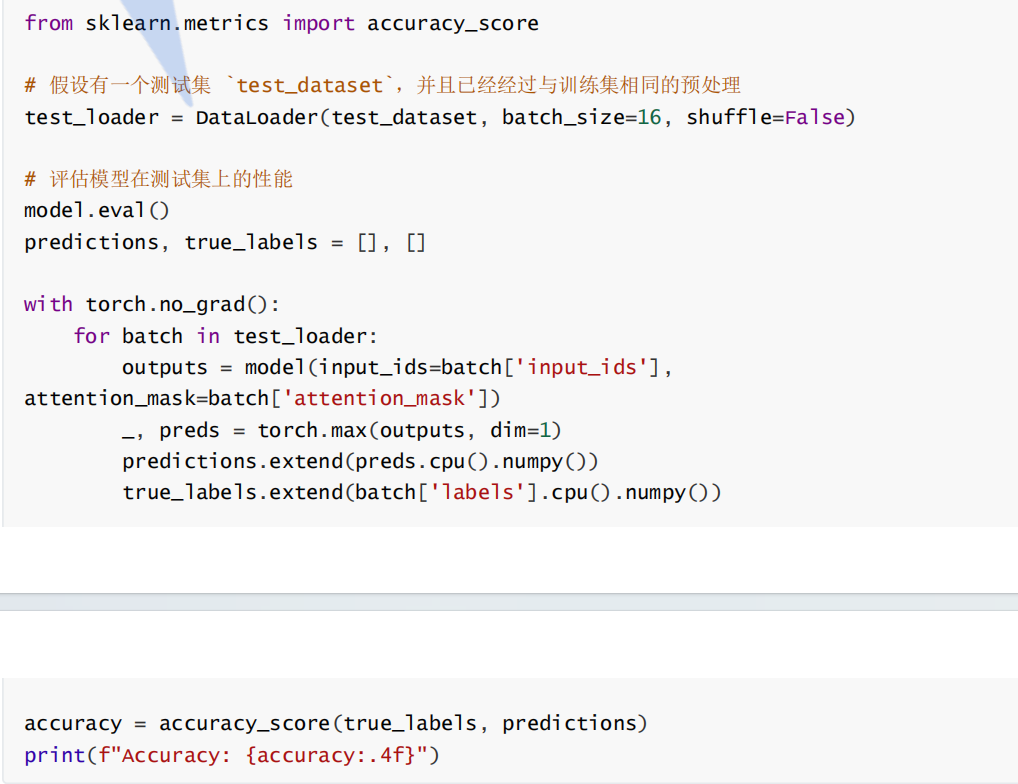
7.2 精确率、召回率和 F1 分数
精确率(Precision)和召回率(Recall)是分类模型的另两个重要指标,分别反映模型在正例预测上的精确性和召回能力。F1 分数是精确率和召回率的调和平均数,通常用于不均衡数据集的评估。

7.3 结果分析与模型优化
通过分析测试集上的结果,可以发现模型的强项和弱项。例如,如果 F1 分数较低,可能是由于数据集不平衡,导致模型在某些类别上表现不佳。通过调整超参数、改进数据预处理步骤,或使用更复杂的模型结构,可以进一步提高模型性能。
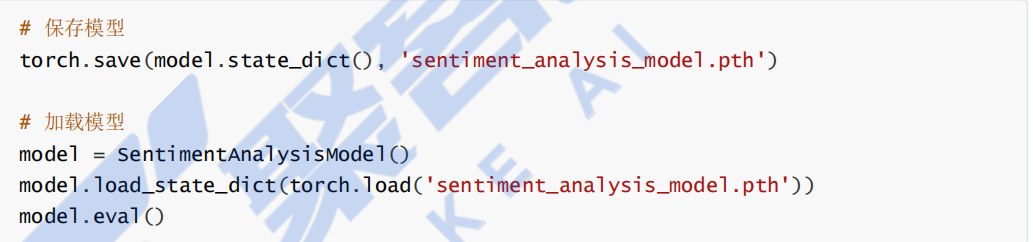
7.4 保存与加载模型
为了在未来使用训练好的模型,可以将其保存为文件,之后再加载进行推理或进一步的微调
我们详细介绍了如何使用 Hugging Face 的 BERT 模型进行中文评价情感分析的微调训
练。我们从加载数据集、制作 Dataset、词汇表操作、模型设计、自定义训练,到最后的效果评估与测试,逐步讲解了整个微调过程。通过本课程,你需要掌握使用预训练语言模型进行下游任务微调的基本流程,并能应用到实际的 NLP 项目中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)