OpenAI这次重写Agents SDK,把LangChain们的饭碗端了
说实话,看到OpenAI这次更新的内容,我的第一反应是:第三方Agent框架要睡不着觉了。
harness、沙盒、Manifest、七大供应商原生接入——OpenAI不是在做SDK升级,是在造Agent世界的地基。而且这块地基,正好盖在LangChain、CrewAI们原来的地盘上。
先说说原来那套SDK有多拉胯
2025年3月,OpenAI推出第一版Agents SDK。卖点很诱人:轻量、少抽象、几行Python就能跑。
听起来很美好对吧?但用起来你就会发现,这玩意儿本质上是给聊天机器人设计的。
问题是,现在的Agent早就不是聊两句话就完事了。跑几个小时、甚至跑几天几周的长任务,越来越常见。模型能力翻了好几倍,SDK还在原地踏步。
说白了就是:大模型已经能跑马拉松了,SDK还在给它配散步鞋。
开发者真正需要的是什么?是一套能让Agent检查文件、执行命令、写代码、跨步骤持续工作的基础设施。以前的方案要么太通用(模型无关框架,灵活但发挥不出前沿模型的能力),要么太封闭(托管API,简单但你控制不了Agent在哪跑、怎么跑)。
这次重写,就是要填这个坑。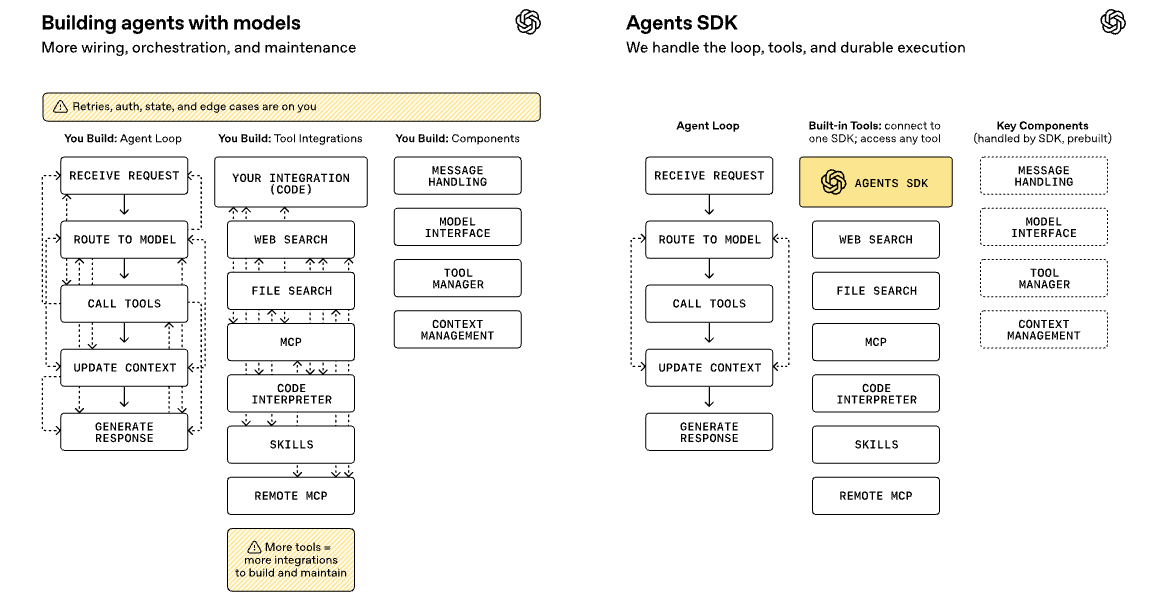
核心变化:harness和沙盒彻底分家
划重点:这次重写就干了两个大事。
第一,给模型装了个完整的运行框架——harness。
这玩意儿把一堆之前要自己东拼西凑的能力全打包了:配置化记忆、沙盒编排、文件系统工具、MCP工具调用、skills信息渐进披露、AGENTS.md自定义指令、shell执行代码、apply patch编辑文件……
熟悉Claude Code和Codex的同学肯定看出来了——这不就是Codex那一套吗?
没错。OpenAI把自家Codex过去一年踩过的坑、攒下的最佳实践,直接产品化了。说白了就是:我们内部跑了一年验证过的东西,现在开放给你们用。
第二,harness和compute彻底分离。
harness跑在你自己的可信环境里,管模型调用、审批、追踪。沙盒单独跑,专门干脏活:读写文件、跑命令、装依赖。
敲黑板:API key和敏感凭证不会进入沙盒环境。
沙盒里啥都没有,甚至连网都可以断开。模型生成的代码在沙盒里跑,但你的密钥、token全在harness侧。这不是修修补补,是整个架构思路的翻转。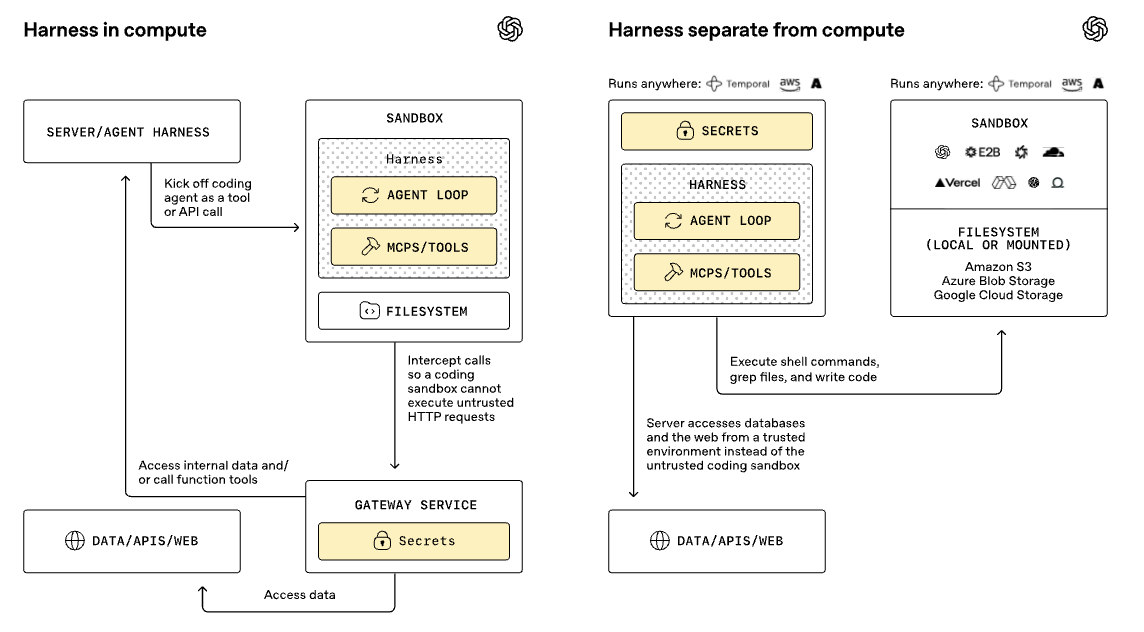
Manifest:一份配置清单,七大沙盒随便切
这可能是这次更新里最被低估的设计。
Blaxel、Cloudflare、Daytona、E2B、Modal、Runloop、Vercel——七家沙盒厂商同时被写进官方支持列表。
七家怎么能同时接入?因为OpenAI搞了个叫Manifest的东西。说白了就是一份配置清单:挂载什么文件、从哪拉数据、产物写到哪,全写在这份清单里。S3、GCS、Azure Blob、Cloudflare R2都支持。
关键是什么?Manifest和沙盒供应商解耦。
今天用E2B跑的Agent,明天想切Modal,改一行配置就行,代码不用动。哪家便宜用哪家,哪家离数据近用哪家。
这才是OpenAI真正狠的地方——不是自己造沙盒,而是把沙盒供应商变成自己生态里的"组件"。今天叫合作伙伴,明天可能就是生态下的一颗螺丝钉。
长跑Agent的两条命:掉线续命 + 分身作战
跑过长时间任务的都知道,最怕的就是跑到一半崩了。以前崩了就崩了,从头再来。
现在有了快照和状态恢复。沙盒容器挂了?没关系,SDK会在新容器里从上个检查点接着跑。
还有多沙盒并行。一个Agent可以同时用多个沙盒,子Agent各自跑在隔离环境里,互不干扰。需要的时候才启动沙盒,不需要就关掉。
Agent第一次有了"死了能复活"和"分身同时干活"的原生能力。
看看别人已经跑出来的成绩
说再多架构设计,不如看看实际效果。
Ramp用Modal跑了一支编码Agent大军,公司超过一半的PR都是Agent自己创建的。Stripe的AI Agent每周产出超过1000个PR。
FurtherAI更夸张——他们的Agent啃了一份900多页的保险理赔记录,提取成功率100%。做过保险行业数据处理的都知道这意味着什么。以前跑这种文档,跑到某一页崩掉是家常便饭。
Tomoro AI那边给了另一组数字:相同能力的Agent,新SDK需要的代码量少了6倍。
Box的开发者关系负责人更直接,传了份业务数据让Agent跑发票对账,第一轮就跑通了。原话是:“沙盒对跑agent生成的代码来说非常完美。”
血泪教训:这些曾经只有头部公司才能攒出来的基建,现在变成了SDK里开箱即用的默认配置。
# pip install "openai-agents>=0.14.0"
import asyncio
import tempfile
from pathlib import Path
from agents import Runner
from agents.run import RunConfig
from agents.sandbox import Manifest, SandboxAgent, SandboxRunConfig
from agents.sandbox.entries import LocalDir
from agents.sandbox.sandboxes import UnixLocalSandboxClient
async def main() -> None:
with tempfile.TemporaryDirectory() as tmp:
dataroom = Path(tmp) / "dataroom"
dataroom.mkdir()
(dataroom / "metrics.md").write_text(
"""# Annual metrics
| Year | Revenue | Operating income | Operating cash flow |
| --- | ---: | ---: | ---: |
| FY2025 | $124.3M | $18.6M | $24.1M |
| FY2024 | $98.7M | $12.4M | $17.9M |
""",
encoding="utf-8",
)
agent = SandboxAgent(
name="Dataroom Analyst",
model="gpt-5.4",
instructions="Answer using only files in data/. Cite source filenames.",
default_manifest=Manifest(entries={"data": LocalDir(src=dataroom)}),
)
result = await Runner.run(
agent,
"Compare FY2025 revenue, operating income, and operating cash flow with FY2024.",
run_config=RunConfig(
sandbox=SandboxRunConfig(client=UnixLocalSandboxClient()),
),
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
LangChain们,该想想出路了
说了这么多技术细节,该聊聊对行业的影响了。
LangChain、LangGraph、CrewAI、AutoGen这些框架,过去一年靠什么活着?靠补齐OpenAI原生SDK不够"生产可用"的那块空白。编排、记忆管理、护栏、追踪、多Agent协作——全是它们的主战场。
现在OpenAI一把把这些全接管了。
留给第三方框架的路很窄了:要么往上走,做垂直场景、做编排;要么往下走,做专用沙盒、做专用工具。中间那层地板,OpenAI自己踩实了。
我觉得最值得玩味的是"兼容所有沙盒服务商"这个定位。表面上是开放生态,实际上是在把沙盒供应商纳入OpenAI的生态位。今天叫合作伙伴,明天就是OpenAI生态里的"组件供应商"。
还不完美,但方向已经很明确了
坦白讲,这次更新也有短板。harness和沙盒的新能力只上了Python,TypeScript还得等。SDK版本号还停留在0.x.x。
但方向已经非常清晰了。
GPT-5.4带着原生computer use登场的时候,不少人说是"没有惊喜的例行升级"。现在回过头看,模型只是前半场,真正的杀招是给模型配上能跑起来的环境。
40天后,真正的惊喜今天才发。
参考资料:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)