以AI量化为生:24.回测存储与策略参数管理
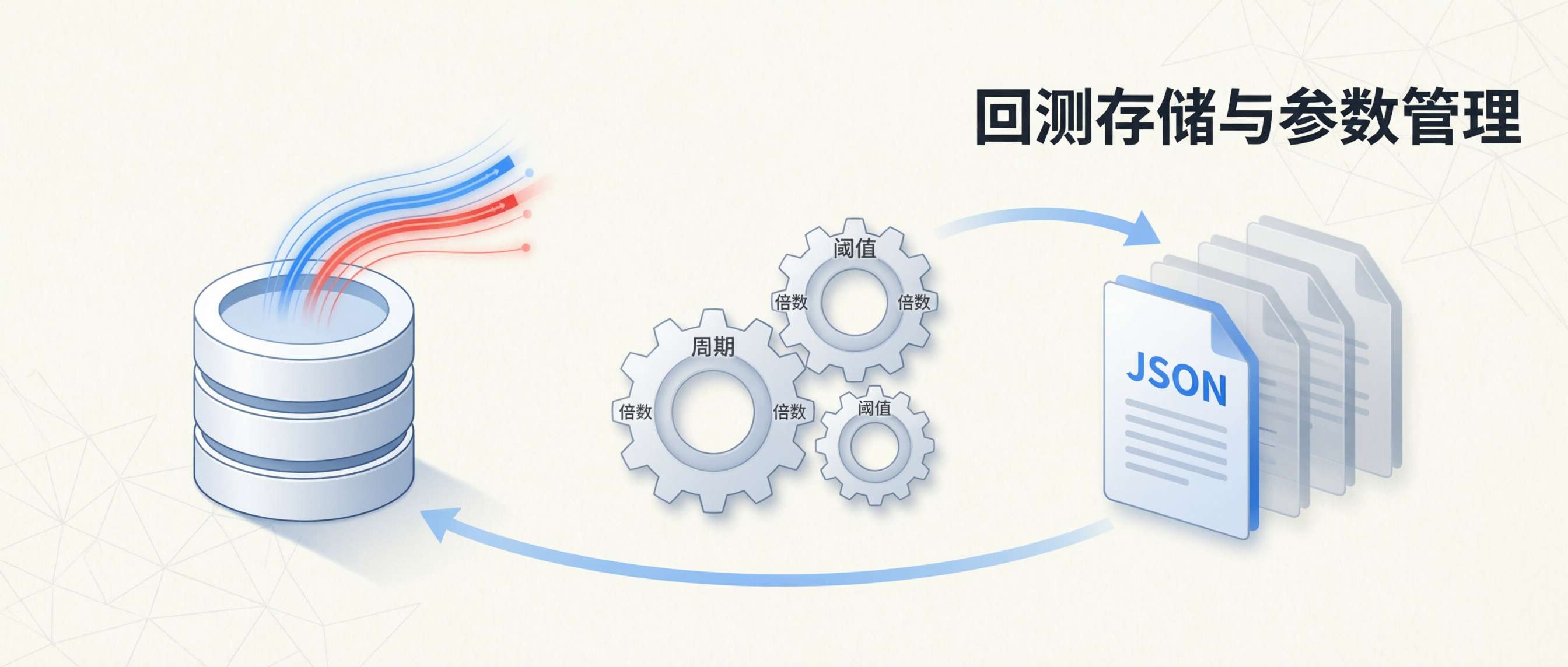
本文是《以AI量化为生》系列的第24篇。上一篇把「决策」交给了 AI,这一篇把「回测结果」和「参数」安顿好:用 MySQL 模型持久化回测成交与 AI 决策流水,用 JSON 管理按品种沉淀的最优参数,让批量回测、复盘和实盘加载形成闭环。
写在前面
第23篇讲完 AI 策略引擎,有读者在问了个很实在的问题:AI 每根 K 线怎么想、下了什么单,事后去哪查?批量优化出来的参数,下次打开回测界面还要不要重新填?
所以这一篇专门讲两块基础设施。一块管细粒度流水:每一笔成交、每一轮 AI 决策,都存进 MySQL,事后能按品种、按时间拉出来复盘。另一块管可复用的策略参数:每个品种一组最优参数,批量优化完直接写 JSON,实盘启动时自动加载,不用手动敲。
一条线解决AI模型回测「查得到」,一条线解决每个品种回测最优参数「不用重填」。
先说回测存储:成交一张表,决策一张表
回测引擎跑一次,会产出两类截然不同的数据。
第一类是成交记录:什么时间、什么品种、开多还是开空、价格多少、手续费多少、这笔平仓赚了还是亏了。这些是「钱」相关的硬数据,不管你是传统 CTA 策略还是 AI 策略,都会有。
第二类是AI 决策记录:这一轮 AI 看到了什么市场数据(用哈希指纹表示)、AI 回复了什么内容、这轮走了缓存还是重新调了模型、花了多少钱、延迟多少毫秒。这些是只有 AI 策略才有的「思考过程」数据。
为什么不能塞一张表?因为查询模式完全不一样。成交记录我关心的是「哪个品种赚了多少」「连亏了几笔」「手续费吃了多少利润」。AI 决策记录我关心的是「缓存命中率多少」「平均延迟多少」「这一轮 AI 的推理过程是什么」。硬塞一起,写的时候别扭,查的时候更别扭。
所以在 backtest_storage_models.py 里拆成了两个 ORM 模型。
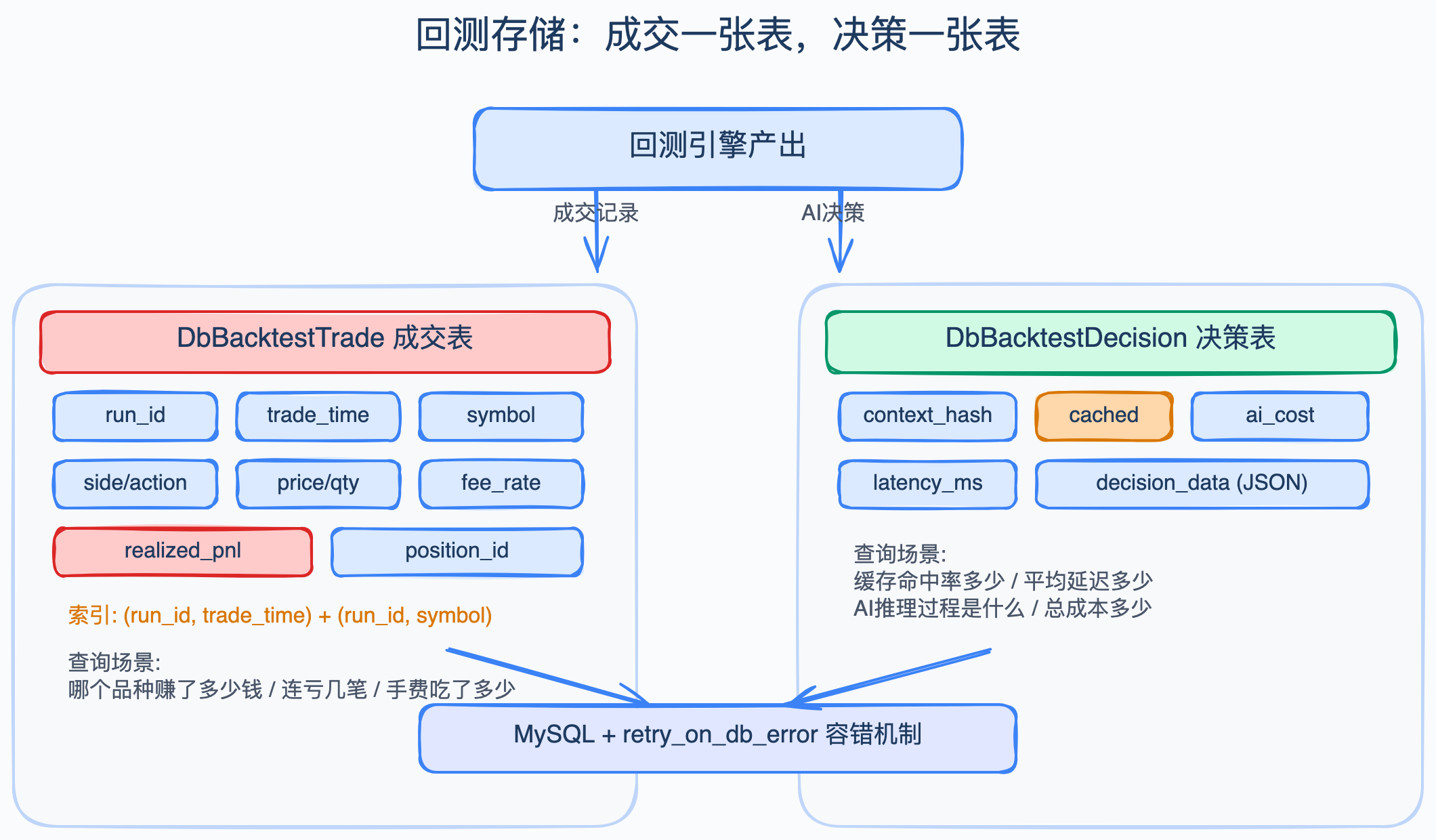
成交表:DbBacktestTrade
每笔成交一行数据。核心字段包括 run_id(同一次回测的标识)、trade_time(成交时间)、symbol(品种)、side(多空方向)、action(开仓/平仓/加仓/减仓)、quantity(手数)、price(价格),还有手续费——这里有个细节,手续费拆成了比例部分和固定部分两列,跟中国期货的双费率结构对应。
另外还有 realized_pnl(这笔的已实现盈亏)和 position_id(持仓标识,方便把开仓和平仓配对)。
索引做了两组复合索引:(run_id, trade_time) 和 (run_id, symbol)。按时间拉流水或者按品种筛选,都不会全表扫。
决策表:DbBacktestDecision
每轮 AI 决策一行数据。除了 run_id 和 decision_time 之外,有几个值得说的字段。
context_hash 是当前市场上下文的 SHA256 哈希。AI 回测跑一小时 K 线,很多相邻 K 线的市场状态几乎一样——技术指标没变、持仓没变、K 线也没怎么动。这种情况下上下文哈希相同,就没必要重新调模型,直接用缓存结果就行。cached 字段就标记这轮是不是走了缓存。
ai_cost 和 latency_ms 是成本监控用的。跑一次 AI 回测要花多少钱、平均每轮延迟多少,这两个字段能帮你做预算和性能分析。说实话,第一次跑完整回测的时候我吓了一跳——两百轮决策,API 费用比我想象的高不少。有这两个字段,至少心里有数。
decision_data 存 AI 返回的完整 JSON 决策内容,用文本格式。想看 AI 当时具体怎么想的,拉出来解析就行。
连接和容错
数据库连接这一层做了个兼容设计:优先走 vnpy_mysql 插件提供的 Base、engine、get_db_session,如果环境里没装这个插件,就回退到从 vnpy 的 SETTINGS 里读数据库配置自己拼连接串。本地开发只要 .env 里配好数据库,不用额外装插件。
所有写库操作都套了一层 retry_on_db_error 装饰器,专门处理 MySQL 的常见抖动:死锁(1213)、连接断开(2013)、服务消失(2006)、锁超时(1205)。重试之间用递增延迟,不是死等。批量回测连续写库的时候,偶尔抖一下不会导致整个任务挂掉。
首次部署跑一遍 create_backtest_tables() 建表就行。
不过话说回来,如果你只做传统 CTA 策略,从来不看逐笔明细,这套表可以先不建。它不是 vnpy 回测统计的替代品,而是给「要查账、要复现、要算 AI 成本」的场景准备的。一旦接上 AI 回测或者要把成交导出做二次分析,有 run_id 维度会省很多胶水代码。
再说参数管理:一个策略一个 JSON,按品种分区
回测存储解决的是「事后能查」,参数管理解决的是「下次能用」。
批量优化完参数之后,以前的流程是这样的:看一眼优化结果的夏普比率,觉得不错,手动把参数抄到回测界面或者策略配置里。品种多了就容易出错(我那个 RSI 敲成 7 的事故就是这么来的),换台电脑就更麻烦了。
所以做了个 StrategyParamManager,核心思路很简单:每个策略一个 JSON 文件,每个品种一组参数。
JSON 文件长什么样
所有参数文件放在 config/strategy_params/ 目录下,文件名就是策略名。比如卡尔曼均值回归策略对应 kalman_mean_reversion.json。
文件顶层有三个字段:strategy(策略名,方便人扫一眼知道是谁)、last_updated(文件级更新时间)、symbols(按品种分区的字典)。
每个品种下面拆成三块,这个设计是踩了坑之后才想明白的。
刚开始把参数和业绩指标混在一起存,策略加载的时候经常出问题——有的策略会把 sharpe_ratio 当成一个叫 sharpe_ratio 的策略参数,然后报错说找不到这个属性。后来才意识到,「能下单的参数」和「当时回测有多牛」是两回事,必须分开。
所以现在每个品种下面是三块:
params:纯策略参数,只有布林带周期、RSI 阈值、ATR 倍数这些真正给引擎用的东西performance:夏普、总盈亏、胜率等业绩快照,给人看的,策略不碰metadata:来源标记(比如batch_optimize_20260327)和更新时间
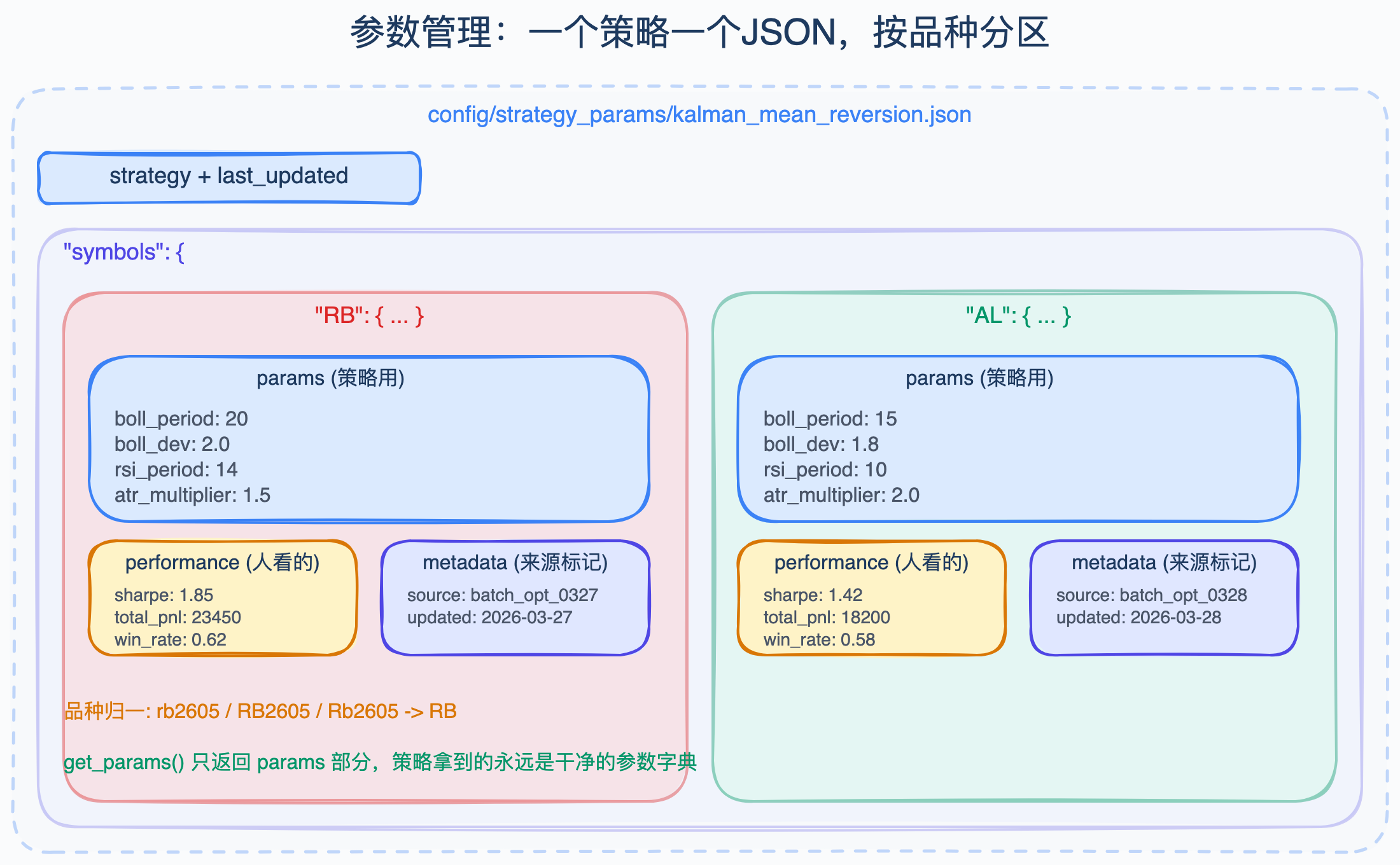
get_params 方法只返回 params 部分,策略类拿到的永远是干净的参数字典,不会混进业绩字段。
品种匹配:合约号自动归一
这里有个细节值得说说。
期货合约代码是带月份的,比如 rb2605.SHFE 表示 2026 年 5 月到期的螺纹钢。但最优参数是跟着品种走的,不跟着合约走——rb 的参数不会因为换月就变了。
所以管理器在匹配品种的时候,会先把 rb2605 这种完整合约用正则提取出字母段 rb,再转成大写 RB。symbols 字典里存的 key 是 RB,不管你传进来的是 rb2605、RB2605 还是 Rb2605,都能匹配到同一组参数。
还有一个大小写不一致的问题。刚开始团队里有人用小写 rb 当 key,有人用大写 RB,结果 JSON 里出现两条记录,各存各的,参数还不一样。后来加了个 _find_symbol_key 方法做大小写无关查找,读写时都会归并到同一个 key。不过还是建议在批量脚本里统一用大写字母段,减少 diff 噪音。
旧格式自动迁移
第一批参数文件用的是简单的平铺格式,顶层直接放 params。后来改成按品种分区的 symbols 格式之后,旧的配置文件就读不了了。
与其写个一次性迁移脚本让所有人跑一遍,不如在读取的时候自动处理。save_params 方法加载文件时会检查:如果顶层有 params 但没有 symbols,就自动把旧的平铺格式转成新的分区格式,下次保存就变成新格式了。用户完全无感。
参数怎么从文件跑到策略里
这块是整个参数管理的核心,也是从「优化完」到「实盘能用」的最后一公里。
自动加载机制
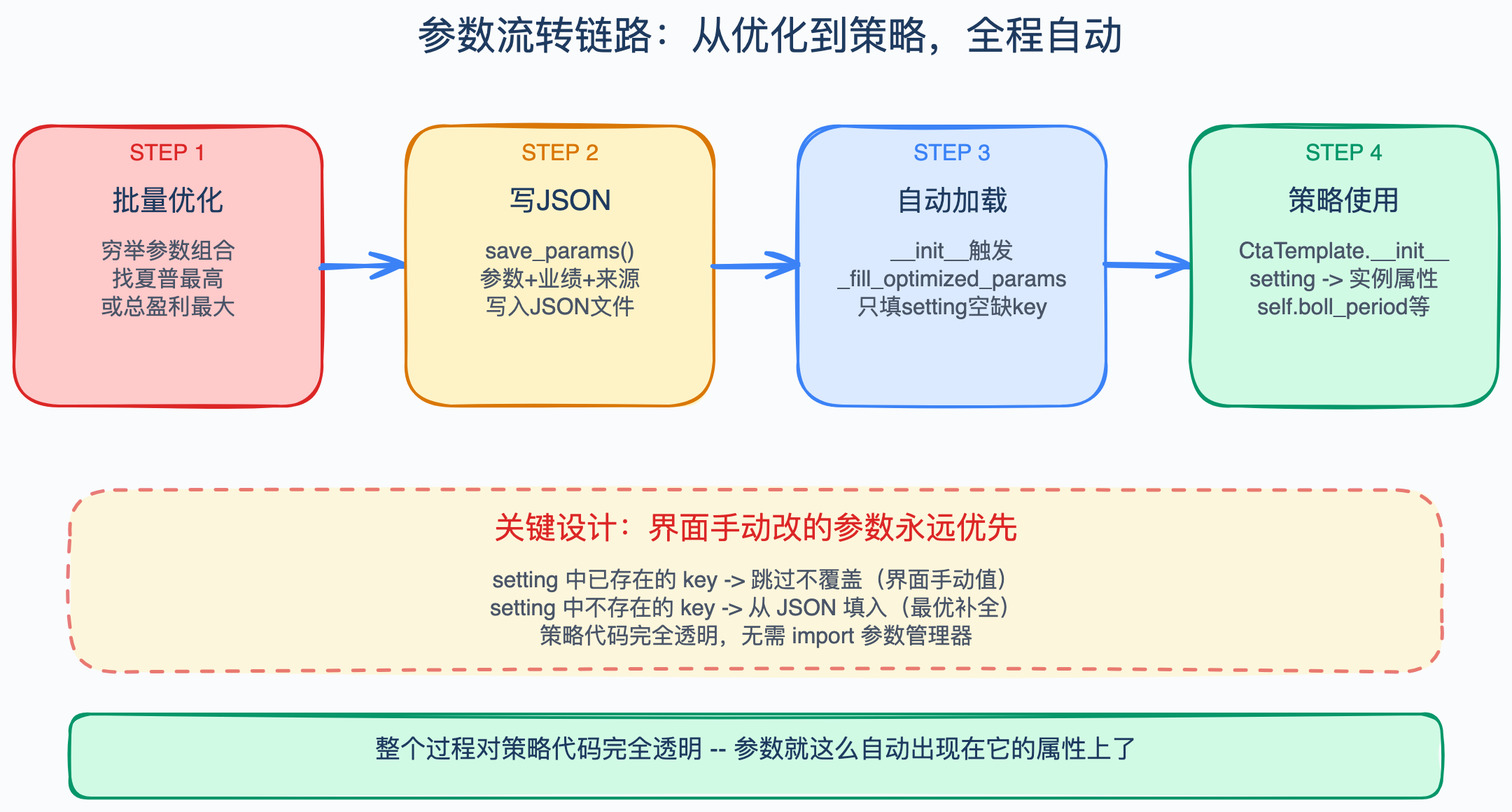
所有策略都继承自 BaseCtaStrategy,它在初始化的时候会做一件事:在调用 vnpy 的 CtaTemplate.__init__ 之前,先跑 _fill_optimized_params。
这个方法的逻辑是这样的:用当前策略的配置名和合约代码,去参数管理器里查有没有存过最优参数。如果有,就把这些参数填到 setting 字典里。
但这里有个关键设计:只有在 setting 里尚未出现的 key 才会填入。
什么意思?setting 是回测界面或实盘启动时传入的参数字典。如果你在界面上手动改了某个参数(比如把布林带周期从 20 改成了 15),那 setting 里就已经有这个 key 了。_fill_optimized_params 看到 key 已存在,就跳过不覆盖。
换句话说:界面手动改的参数永远优先,JSON 文件里存的是「缺省时的最优补全」。
这个优先级设计是吃过亏之后才想清楚的。有一次批量优化完 RB 的参数,夏普不错,写进了 JSON。结果第二天发现,另一个品种的参数也被覆盖了——因为那个品种我之前在界面上手动调过一组更好的参数,但 JSON 写入的时候没有尊重界面设置。加了优先级判断之后,手动调的永远不被覆盖,JSON 只补全没手动设过的参数。
完整的参数流转链路
把整个过程串起来看,数据流是这样的:
第一步:批量优化。用批量回测脚本(比如 batch_backtest_all_main_contracts.py)跑一组品种,对每个品种穷举参数组合,找到夏普最高或总盈利最大的一组。
第二步:写 JSON。优化脚本拿到最优参数后,调用 save_params,把参数、业绩指标和来源标记一起写进对应的 JSON 文件。RB 的最优参数写到 kalman_mean_reversion.json 的 symbols.RB 下面。
第三步:自动加载。启动回测或实盘时,BaseCtaStrategy.__init__ 触发 _fill_optimized_params,从 JSON 里读出 RB 的参数,填到 setting 字典中空缺的 key 里。
第四步:策略使用。vnpy 的 CtaTemplate.__init__ 把 setting 里的值设为策略实例的属性。策略代码里直接用 self.boll_period、self.rsi_oversold 这些属性,完全不知道这些值是从 JSON 自动加载的还是从界面手动填的。
整个过程对策略代码完全透明。策略不需要 import 参数管理器,不需要调任何读取方法,参数就这么自动出现在它的属性上了。
单例和线程安全
参数管理器通过 get_param_manager() 获取全局单例。整个应用周期内只有一个实例,不会重复创建。JSON 文件的读写是即时完成的(读一次、改内存、写回),没有后台线程或异步操作,所以在 vnpy 的单线程事件循环里是安全的。
写在最后
这一篇把「流水进库、参数进文件」拆清楚,其实就是在回答一个问题:量化系统里哪些东西要可追溯、哪些东西要可复用。
存储模型保证单次回测可复盘——哪笔赚了、哪笔亏了、AI 每轮想了什么、花了多少钱,拉 run_id 一查便知。参数管理器保证跨会话、跨品种的配置不丢——今天优化完的参数,明天、下周、换台电脑,启动策略自动带上。
先写到这,有问题欢迎留言交流。
本文是《以AI量化为生》系列文章的第24篇,ATMQuant量化交易系统已开源至GitHub:https://github.com/seasonstar/atmquant
本文内容仅供学习交流,不构成任何投资建议。交易有风险,投资需谨慎。
加入「量策堂·AI算法指标策略」
想系统性掌握策略研发、指标可视化与回测优化?加入我的知识星球,获得持续、体系化的成长支持:

往期文章回顾
《以AI量化为生》系列
《量化指标解码》系列
- 量化指标解码16:SMC聪明钱概念之订单块
- 量化指标解码15:Adaptive MACD Deluxe - 会自己调参的智能MACD
- 量化指标解码14:Supertrended RSI - RSI与趋势跟踪的完美融合

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)